一种基于多特征与多分类器的鲜茶叶分类方法与流程
本发明涉及图像分类领域,尤其涉及一种基于多特征与多分类器的鲜茶叶分类方法。
背景技术:
近年来,随着采茶人工成本不断增加以及采茶工人力紧缺,为了降低生产成本,提高生产效率,越来越多的茶场开始采用机械采茶。但是机采茶中参杂叶梗等杂物,同时无法按照生产加工需求采集特定等级的鲜叶,各个等级鲜叶(如单芽、一芽一叶、一芽二叶、一芽三叶)混合在一起,大大降低了茶叶的质量,导致只能作为低价茶生产销售,这成为了制约机械采茶发展与推广的主要原因。
目前存在一些基于物理方式的茶叶分级方法,如振动筛选式茶叶分级机,在将茶叶从输送端向输出端振动前进的过程中使不同等级茶叶在重力作用下通过分选装置不同孔径落在下方的接料器上实现鲜叶分级,准确率在70%左右;茶叶风选机通过吹风将不同轻重的鲜叶区分开来,较轻的芽叶抛落距离较远,较重的芽叶抛落距离较近,准确率在70%左右。可见通过物理方式对鲜叶进行分级准确率低、误差大。另外基于光电传感器的茶叶色选机可在茶叶加工后有效分离杂质、叶梗等物质,准确在90%以上,但只能剔除杂质,依然无法进行有效分级。
随着计算机技术的高速发展,基于计算机视觉的图像分类技术应用于各个领域。目前,国内外有一些利用计算机视觉对于植物叶片进行分类的研究取得了较好的效果。例如董红霞等结合形状与纹理特征利用bp前馈神经网络对6种叶片300个样本叶片进行分类,准确率达98.4%;郑一力[8]等针对植物叶片数据库属于小样本数据库的特点,提出了一种基于迁移学习的卷积神经网络植物叶片图像识别方法,利用预训练alexnet、inceptionv3模型对icl数据库的识别率达95.31%和95.40%;turkoglu等为了增加同一物种叶片间的相似率,将叶片分割成两部分和四部分后提取纹理特征、颜色特征、灰度共生矩阵以及傅里叶描述子,再结合极限学习机进行叶片识别,在flavia叶片数据集准确率达99.10%。
而利用计算机视觉技术对茶叶进行分类的研究与应用较少,主要分为两个方面的研究:一是对加工后的茶叶分离杂质以及分级,例如高达睿等基于颜色和形状特征利用bp神经网络对三种不同等级的六安瓜片进行分类,准确率达90%以上;吴正敏等基于形态特征采用随机森林法判定特征权重并结合支持向量机进行分类,准确率为93.8%;宋彦等提出了一种基于形状特征直方图结合支持向量机的茶叶等级识别方法,准确率为95.71%。二是对采摘的鲜叶进行分类,如常春等选择茶叶图像的6个几何特征和2个纹理特征做为茶叶的分类特征,利用bp神经网络构建分类模型,准确率达90%以上,但其未对一芽二叶与一芽三叶进行区分;高震宇等设计了一套鲜茶叶智能分选系统,搭建了7层结构的卷积神经网络识别模型,其对单芽、一芽一叶、一芽二叶、一芽三叶的分类准确率为92.25%;吴正敏等利用凸包面积、凸包周长、长轴长度、短轴长度等形态特征结合bp神经网络对绿茶进行分类,准确率在90%以上,也未对一芽二叶与一芽三叶进行区分。
技术实现要素:
有鉴于此,本方法在提取鲜茶叶几何特征与纹理特征并结合支持向量机进行鲜茶叶分类的基础上,提出了一种基于茶叶特殊角点及其距离矩阵的分类方法,并通过结果融合得出分类结果,为鲜茶叶分类研究提供了新的方法。
本发明提供了一种基于多特征与多分类器的鲜茶叶分类方法,包括以下:
s101:获取茶叶图像,作为训练数据集;
s102:对茶叶图像进行预处理,得到预处理后的茶叶图像;
s103:对预处理后的茶叶图像进行几何特征提取,得到预处理后的茶叶图像的5个相对几何特征和7个hu不变矩相对几何特征;
对预处理后的茶叶图像进行轮廓提取,得到茶叶轮廓,并根据茶叶轮廓进行多边形拟合,得到拟合的多边形;
s104:对茶叶图像的灰度图进行纹理特征提取,得到茶叶图像的1个纹理特征;
对拟合的多边形进行角点检测,根据角点检测得到的特殊角点数量,并结合茶叶样本数据统计,得到茶叶类别及茶叶类别对应的分类概率;
s105:利用12个相对几何特征和1个纹理特征训练svm分类器,得到基于svm的鲜茶叶分类模型;
对所述特殊角点进行距离矩阵度量,得到特殊角点序列的距离矩阵特征库;
对待预测茶叶图像进行角点检测,并根据待预测样本的特殊角点进行距离矩阵度量,得到待预测样本的距离矩阵;
根据待预测茶叶图像的距离矩阵与所述特殊角点序列的距离矩阵特征库,计算距离矩阵相似度;
s106:利用所述基于svm的鲜茶叶分类模型对待预测茶叶图像进行分类预测,得到基于相对几何特征、纹理特征以及svm的茶叶各类别分类概率;
根据待预测茶叶图像的特殊角点数量和距离矩阵相似度对待预测茶叶图像进行分类预测,得到基于特殊角点以及距离矩阵相似度的茶叶各类别分类概率;
s107:将基于相对几何特征、纹理特征以及svm的茶叶各类别分类概率和基于特殊角点以及距离矩阵的茶叶各类别分类概率进行基于knn的结果融合,得到待预测茶叶图像最终分类结果。
进一步地,步骤s102中,对茶叶图像进行预处理,得到预处理后的茶叶图像,具体为:将茶叶图像进行灰度变换,得到灰度图像;对灰度图像进行高斯滤波,得到滤波去噪后的图像;采用大津算法对滤波去噪后的图像进行处理,得到预处理后的茶叶图像,即二值化图像。
进一步地,步骤s103中,5个相对几何特征包括矩形度、圆形度、球形度、偏心率和周长凹凸比,计算公式分别式(1)、(2)、(3)、(4)和(5)所示:
式(1)中,a为叶片面积,amer为最小外接矩形面积;式(2)中a为叶片面积,p为叶片周长;式(3)中,rmic为叶片最大内切圆半径,rmcc为叶片最小外接圆半径;式(4)中,a为叶片长轴,b为叶片短轴;式(5)中,p为叶片周长,pch为叶片凸包周长。
进一步地,步骤s103中,所述7个hu不变矩相对几何特征,具体由二阶归一化中心矩和三阶归一化中心矩构造得到,分别为h1-h7,计算公式如式(6)、(7)、(8)、(9)、(10)、(11)和(12)所示:
h1=η20+η02(6)
h2=(η20-3η02)2+4η112(7)
h3=(η30-3η12)2+(3η21-η03)2(8)
h4=(η30+η12)2+(η21+η03)2(9)
h5=(η30-3η12)(η30+η12)[(η30+η12)2-3(η21+η03)2](10)
+(3η21-η03)(η21+η03)[3(η30+η12)2-(η21+η03)2]
h6=(η20-η02)[(η30+η12)2-(η21+η03)2]+4η11(η30+η12)(η21+η03)(11)
h7=(3η21-η03)(η30+η12)[(η30+η12)2-3(η03+η21)2](12)
-(η30-3η21)(η21+η03)[3(η12+η30)2-(η03+η21)2]
式(6)、(7)、(8)、(9)、(10)、(11)和(12)中,
进一步地,步骤s104中,对茶叶图像的灰度图进行纹理特征提取,具体过程为:
s201:采用gamma校正法对茶叶图像的灰度图进行颜色空间归一化,降低图像局部阴影和光照变化造成的影响,得到校正后的茶叶图像;
s202:将校正后的茶叶图像分为若干个块,每个块由若干个细胞组成;每个细胞大小为n×n个像素;每个块为m×m个细胞;
s203:计算每个细胞内各像素点的梯度,并统计每个细胞各像素点梯度方向直方图,得到每个细胞的描述子;
s204:将每个细胞的描述子串联,得到每个块的hog描述子,同时对每个块内的梯度强度进行归一化;
s205:将校正后茶叶图像的所有快的hog描述子串联,得到校正后茶叶图像的hog特征,即茶叶图像的1个纹理特征。
进一步地,步骤s105中,利用12个相对几何特征和1个纹理特征训练svm分类器,得到基于svm的鲜茶叶分类模型,具体为:采用不同的惩罚系数、不同的核函数及核函数对应的参数,通过基于网格搜索和交叉验证的方式,进行参数寻优,确定svm鲜茶叶分类模型的最佳惩罚系数和核函数;所述不同的核函数包括:线性核函数、多项式核函数和径向基核函数;所述核函数对应的参数包括核参数gamma和最高次幂数degree。
进一步地,步骤s103中,对预处理后的茶叶图像进行轮廓提取,得到茶叶轮廓,并根据茶叶轮廓进行多边形拟合,得到拟合的多边形,具体为:所述轮廓提取,采用opencv的findcontours方法;所述多边形拟合,采用opencv的douglas-peucker算法。
进一步地,步骤s104中,对拟合的多边形进行角点检测,根据角点检测得到的特殊角点数量,所述特殊角点的判别方法具体为:拟合的多边形中,满足如式(13)条件的多边形的角p所对应的的角点即为特殊角点:
∠p≤a(0°≤a≤180°)(13)
式(13)中,∠p为角p的角度,a为预先设置的角度阈值。
步骤s105中,对所述特殊角点进行距离矩阵度量,并进行距离矩阵相似度计算,具体为:距离矩阵如式(14)所示:
式(14)中,di,j表示特殊角点序列中第i个点与第j个点间的欧式距离,
所述距离矩阵相似度如式(15)所示:
式(15)中,s表示距离矩阵相似度,da表示待预测茶叶图像的距离矩阵,dn表示特殊角点序列的距离矩阵特征库中对应的距离矩阵,为已知值。
本发明提供的技术方案带来的有益效果是:提高了茶叶分类的准确率。
附图说明
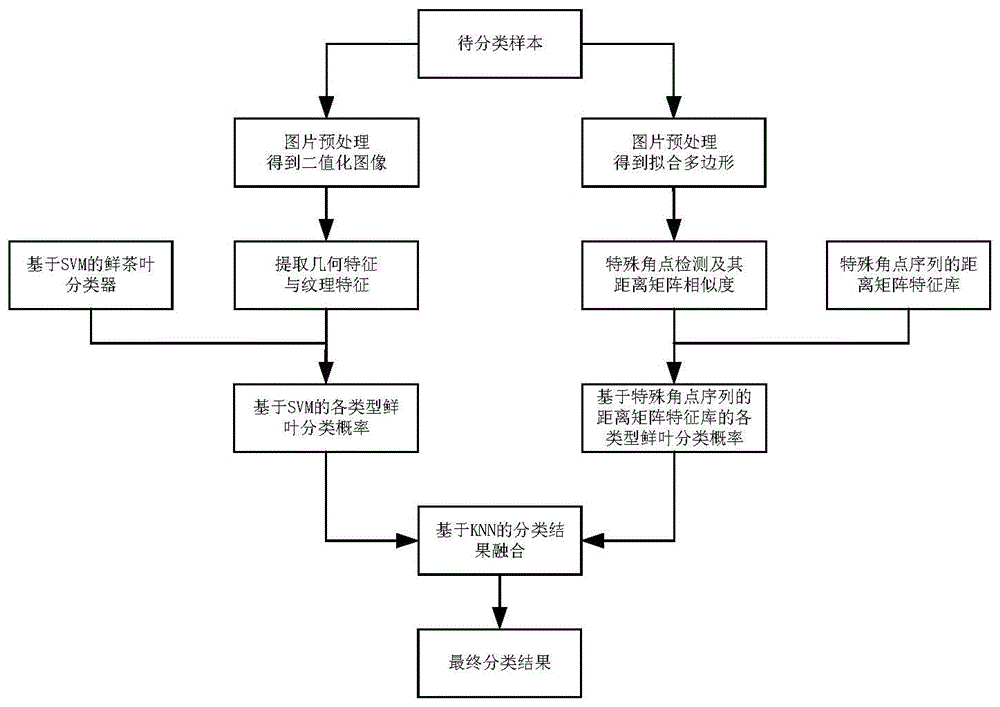
图1是本发明一种基于多特征与多分类器的鲜茶叶分类方法的流程图;
图2是本发明图像预处理效果示意图;
图3是本发明实施例中基于svm分类器的线性核函数下惩罚系数c与分类准确率;
图4是本发明基于svm分类器的不同类型核函数最高分类准确率折线图;
图5是本发明中茶叶多边形拟合过程示意图;
图6是本发明实施例中角度a的取值与特殊角点总数n的关系图;
图7是本发明基于特殊角点及距离矩阵相似度的鲜茶叶分类流程图;
图8是本发明基于knn融合中距离计算公式与k的选取关系示意图;
图9是本发明数据集中鲜茶叶类别示意图;
图10是本发明实施例中基于svm的分类模型的分类结果混淆矩阵示意图;
图11是本发明实施例中svm+基于特殊角点及其距离矩阵分类模型的分类结果混淆矩阵示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地描述。
请参考图1,本发明的实施例提供了一种基于多特征与多分类器的鲜茶叶分类方法,包括以下:
s101:获取茶叶图像,作为训练数据集;所述训练数据集包括多类茶叶图像,每一类茶叶图像包括多个茶叶图像;
s102:对茶叶图像进行预处理,得到预处理后的茶叶图像;
s103:对预处理后的茶叶图像进行几何特征提取,得到预处理后的茶叶图像的5个相对几何特征和7个hu不变矩相对几何特征;
对预处理后的茶叶图像进行轮廓提取,得到茶叶轮廓,并根据茶叶轮廓进行多边形拟合,得到拟合的多边形;
s104:对茶叶图像的灰度图进行纹理特征提取,得到茶叶图像的1个纹理特征;
对拟合的多边形进行角点检测,根据角点检测得到的特殊角点数量,并结合茶叶样本数据统计,得到茶叶类别及茶叶类别对应的分类概率;
s105:利用12个相对几何特征和1个纹理特征训练svm分类器,得到基于svm的鲜茶叶分类模型;
对所述特殊角点进行距离矩阵度量,得到特殊角点序列的距离矩阵特征库;
对待预测茶叶图像进行角点检测,并根据待预测样本的特殊角点进行距离矩阵度量,得到待预测样本的距离矩阵;
根据待预测茶叶图像的距离矩阵与所述特殊角点序列的距离矩阵特征库,计算距离矩阵相似度;
s106:利用所述基于svm的鲜茶叶分类模型对待预测茶叶图像进行分类预测,得到基于相对几何特征、纹理特征以及svm的茶叶各类别分类概率;
根据待预测茶叶图像的特殊角点数量和距离矩阵相似度对待预测茶叶图像进行分类预测,得到基于特殊角点以及距离矩阵相似度的茶叶各类别分类概率;
s107:将基于相对几何特征、纹理特征以及svm的茶叶各类别分类概率和基于特殊角点以及距离矩阵的茶叶各类别分类概率进行基于knn的结果融合,得到待预测茶叶图像最终分类结果。
请参考图2,图2是本方法的图像预处理效果图;
步骤s102中,对茶叶图像进行预处理,得到预处理后的茶叶图像,具体为:将茶叶图像进行灰度变换,得到灰度图像;对灰度图像进行高斯滤波,得到滤波去噪后的图像;采用大津算法对滤波去噪后的图像进行处理,得到预处理后的茶叶图像,即二值化图像。
步骤s103中,对预处理后的茶叶图像进行几何特征提取,得到预处理后的茶叶图像的5个相对几何特征和7个hu不变矩相对几何特征。
其中,基于图像预处理得到的二值化图像,提取矩形度、圆形度、球形度、偏心率与周长凹凸比5个相对几何特征,计算公式如表1所示。
表1相对几何特征计算公式
基于图像预处理得到的二值化图像,提取7个hu不变矩相对几何特征,
具体由二阶归一化中心矩和三阶归一化中心矩构造得到,分别为h1-h7,计算公式如式(6)、(7)、(8)、(9)、(10)、(11)和(12)所示:
h1=η20+η02(6)
h2=(η20-3η02)2+4η112(7)
h3=(η30-3η12)2+(3η21-η03)2(8)
h4=(η30+η12)2+(η21+η03)2(9)
h5=(η30-3η12)(η30+η12)[(η30+η12)2-3(η21+η03)2](10)
+(3η21-η03)(η21+η03)[3(η30+η12)2-(η21+η03)2]
h6=(η20-η02)[(η30+η12)2-(η21+η03)2]+4η11(η30+η12)(η21+η03)(11)
h7=(3η21-η03)(η30+η12)[(η30+η12)2-3(η03+η21)2](12)
-(η30-3η21)(η21+η03)[3(η12+η30)2-(η03+η21)2]
式(6)、(7)、(8)、(9)、(10)、(11)和(12)中,
步骤s104中对茶叶图像的灰度图进行纹理特征提取,得到茶叶图像的1个纹理特征,具体为:
基于图像预处理得到的灰度图像利用方向梯度直方图。首先采用gamma校正法对输入图像进行颜色空间的归一化,可调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;将图像划分为若干个块(block),每个块由若干个细胞(cell)组成,本方法设置细胞大小为8×8像素,每个块大小为4×4个细胞;然后计算细胞中各像素点的梯度的或边缘的方向直方图,统计每个细胞的梯度方向直方图得到每个细胞的描述子,然后将细胞的特征向量串联得到块的hog特征,同时对块内的梯度强度进行归一化;最后将图像内的所有块的hog特征描述串联起来得到该图像的hog特征,即为供图像分类使用的茶叶纹理特征。
步骤s106中,基于12个相对几何特征和1个纹理特征,利用所述基于svm的鲜茶叶分类模型对茶叶图像进行分类预测,得到基于相对几何特征、纹理特征以及svm的茶叶各类别分类概率。
本实施例中,对惩罚系数c、不同核函数(线性核函数、多项式核函数、径向基核函数)及核函数对应的参数(核参数gamma、最高次幂次数degree)通过基于网格搜索和交叉验证的方式进行参数寻优,对于鲜茶叶分类确定最佳组合为:核函数kernel=线性核函数,惩罚系数c=0.25,线性核函数下惩罚系数c与分类准确率的关系如图3所示,各核函数最高分类准确率如图4所示。图4中,当kernel=多项式核函数时,c=0.8,gamma=1.67,degree=5;当kernel=线性核函数时,c=0.25;当kernel=径向基核函数时,c=3,gamma=0.25;
请参考图5,图5是本发明实施例中,茶叶多边形拟合过程示意图;以一芽二叶样本为例,基于图像预处理阶段得到的二值化图像,利用opencv的findcontours方法进行轮廓提取,然后利用douglas-peucker算法对茶叶轮廓进行多边形拟合,设置逼近精度为轮廓周长乘0.02,并对得到的拟合多边形进行颜色填充。
对于得到的拟合多边形,检测其特殊角点个数,此处对特殊角点的定义为:拟合多边形中任意一个满足下述条件的角p所对应的角点
∠p≤a(0°≤a≤180°)
其中∠p为角p的角度。
首先设置a=90°,对1755张分为四类(单芽、一芽一叶、一芽二叶、一芽三叶)的鲜茶叶样本进行特殊角点检测与数量统计,发现各样本检测到的特殊角点数量分布在1~8之间,大部分分布在2~5之间。其中,450个单芽样本中检测到2个特殊角点的有424(记为n1)个,432个一芽一叶样本中检测到3个特殊角点的有355(记为n2)个,441个一芽二叶样本中检测到4个特殊角点的有291(记为n3)个,432个一芽三叶样本中检测到5个特殊角点的有222(记为n4)个,n1、n2、n3、n4的总数为1292(记为n)个,这与对样本拟合多边形的直接观察结果相符。当a改变时,总数n会随之变化。当a的取值使得n最大时,a即为特殊角点条件的最佳取值。通过对a各个取值的实验,当a=100°时n值最大,即特殊角点为拟合多边形中≤100°的角所应的点。角度a的取值与总数n的关系如图6所示。
当特殊角点满足∠p≤100°时对样本进行特殊角点检测与统计,各特殊角点数量(1~8)与茶叶类别(单芽、一芽一叶、一芽二叶、一芽三叶)的对应值组成一个8×4的矩阵,对矩阵每一行进行归一化处理,即可得到各特殊角点数量对应的各个分类概率。以数据集中1755个样本为例,结果如表1所示。
表1各特殊角点数量对应的各个分类概率
通过对表1数据的分析,对于特殊角点数量在3~5之间的样本,虽然大部分检测到3个特殊角点的样本是一芽一叶,但仍有部分样本是其他类别。同样,检测到4个特殊角点的样本中除了一芽二叶还存在其他类别,检测到5个特殊角点的样本中除了一芽三叶也存在其他类别。为了降低对分类准确率的影响,使用特殊角点序列的距离矩阵的相似度进行再次比较。
步骤s105中,对所述特殊角点进行距离矩阵度量,并进行距离矩阵相似度计算,具体为:距离矩阵如式(14)所示:
式(14)中,di,j表示特殊角点序列中第i个点与第j个点间的欧式距离,
所述距离矩阵相似度如式(15)所示:
式(15)中,s表示距离矩阵相似度,da表示待预测茶叶图像的距离矩阵,dn表示特殊角点序列的距离矩阵特征库中对应的距离矩阵,为已知值。
请参考图7,图7是本发明基于特殊角点及距离矩阵相似度的鲜茶叶分类流程图;对于待预测茶叶图像,首先检测其特殊角点数量(记为count),若
1)1≤count<2或6≤count≤8,则将表1中特殊角点个数为count的行的四个值作为四个类别的分类概率;
2)2≤count≤5,则计算待预测茶叶图像特殊角点序列的距离矩阵,并与特殊角点序列的距离矩阵特征库中对应的矩阵计算相似度,即count=2时,与d0计算相似度,count=3时,与d1计算相似度,count=4时,与d2计算相似度,count=5时,与d3计算相似度。当相似度s大于一定阈值t时,将表1中特殊角点个数为count的行的四个值作为四个类别的分类概率,否则,四个类别的分类概率都记为0。其中阈值t基于网格搜索与交叉验证方法得出,相似度阈值如表2所示。
表2距离矩阵相似度阈值
注:t0为与d0计算相似度的阈值,t1为与d1计算相似度的阈值,t2为与d2计算相似度的阈值,t3为与d3计算相似度的阈值。
count=0或count>8,四个类别的分类概率都记为0。
基于几何特征和纹理特征以及svm分类器的各类别分类概率与基于特殊角点及其距离矩阵的各类别分类概率结果进行结果融合,通过融合后的各分类概率得出最终分类结果。
knn是数据挖掘分类技术中的常用方法,他的思想是样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。影响knn分类效果的有两个重要因素:一是距离计算公式的选取,二是参数k的选取。本发明分别对欧式距离与曼哈顿距离以及不同的k值进行实验,得出使用曼哈顿距离计算公式并且设置k=30时效果最好,结果如图8所示。
为了更好地对本发明所提方法进行验证,本发明实验采用自建数据集,共采集龙井茶鲜叶图片1973张,分为四类如图9所示,其中单芽502张、一芽一叶488张、一芽二叶494张、一芽三叶489张。
为验证基于多特征与多分类器的鲜茶叶分类模型的有效性,分别对svm鲜茶叶分类模型、基于特殊角点及其距离矩阵的鲜茶叶分类模型以及基于knn结果融合的鲜茶叶分类模型进行分类实验。使用python及sklearn库实现分类模型,同时利用十折交叉验证法,将数据集中1950个样本分为10份,轮流将其中9份作为训练集,1份作为测试集,进行实验,实验结果如表3所示。其中svm分类模型和svm+基于特殊角点及其距离矩阵分类模型的分类结果混淆矩阵如图10、11所示。
表3不同分类模型的分类准确率
从表3数据可知,本研究提出的基于多特征与多分类器的鲜茶叶分类模型比单独使用svm模型进行分类准确率高,提升3.16%。另外,准确率有明显提高,现有方法主利用茶叶绝对几何特征进行分类,虽然对三分类(单芽、一芽一叶、一芽多叶)分类效果较好,但是对于本方法所述四分类结果较差,不易区分一芽二叶与一芽三叶。从图10和图11的混淆矩阵可知,基于多特征与多分类器的鲜茶叶分类模型对各个类别的分类准确率均有提高,其中对于一芽一叶与一芽二叶分类准确率提高较为明显。
本发明实施的有益效果是:提高了茶叶分类的准确率。
在不冲突的情况下,本文中上述实施例及实施例中的特征可以相互结合。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!