基于时空多尺度网络的人流密度图估计、定位和跟踪方法与流程
本发明涉及目标计数、定位与跟踪领域,尤其涉及一种基于时空多尺度网络的人流密度图估计、定位和跟踪方法。
背景技术:
配备摄像机的无人机或通用无人机(uav)已广泛的应用在实际案例中,例如人群视频监控和公共安全控制。近年来,世界各地发生了许多大规模踩踏事件,导致许多人丧生,这使自动进行密度图估计、通过无人机人群计数和跟踪成为一项重要任务。这些任务最近引起了计算机视觉研究界的极大关注,尽管近几年取得了显著的进步,但是由于各种挑战的存在,例如视点和比例变化、背景混乱和小比例缩放等,这些算法在处理无人机捕获的视频序列方面仍有改进的空间。
由于缺乏公开可用的大型数据集,阻碍了对无人机的人群计数和跟踪算法的开发和评估。尽管近年来构建了许多用于人群计数的数据集,但这些数据集的大小和场景仍然有限。由于数据收集上的困难和基于无人机进行人群计数和跟踪方面的待解决问题,现有数据集大多仅通过监视摄像机拍摄的静止图像来进行人群计数。
迄今为止的现有数据集中,仅存在关于少数人群计数、密度图估计、人群定位或人群跟踪的数据集。例如,ucf-cc50[1]人群数据集由50张图像组成,其中包含64,000个带注释的人,其头部数量从94到4,543。shanghaitech[2]人群数据集包含1,198张图像,总共标记了330,165个人。最近发布的ucf-qnrf[3]人群数据集,包含了1,535张图像和125万个带注释的人的头部,但这些数据集的大小和场景仍然有限。
在人群计数和密度图估计方面,早期的人群计数方法大多数依靠滑动窗口检测器扫描静止图像或视频帧,以根据行人的手工外观特征来检测行人。但是,基于检测器的方法很容易受到拥挤场景中严重遮挡,比例尺和视点变化的影响。近来,一些方法将拥挤计数公式化为密度图的估计,例如,通过最小化正则化风险二次成本函数来推断密度估计;或使用多列cnn(卷积神经网络)网络估算人群密度图,该图通过每列cnn来学习不同头部尺寸的特征。尽管这些方法有了很好的改进,但它们捕获的尺度多样性受到列或分支数的限制。而对于视频中的人群计数,时空信息对于提高计数准确性至关重要,例如使用卷积lstm(长短期记忆网络)模型来完全捕获时空相关性以进行人群计数,但仍无法做到有效利用帧间的时间相干性以获得更好的性能。
技术实现要素:
本发明提供了一种基于时空多尺度网络的人流密度图估计、定位和跟踪方法,本发明提出的通过由计数分支、定位分支和跟踪分支三个分支组成的时空多尺度注意力网络(stanet),可同时解决密度图估计、定位和跟踪任务,在连续帧中聚合多尺度特征图以利用时间一致性,并将注意力模块应用到聚合的多尺度特征图上,以强制网络利用判别性时空特征来获得更好的性能。详见下文描述:
一种基于时空多尺度网络的人流密度图估计、定位和跟踪方法,所述方法包括:
构建由计数分支、定位分支和跟踪分支三个分支组成的时空多尺度注意力网络,所述网络用于同时解决密度图估计、定位和跟踪的多任务;
在连续帧中聚合多尺度特征图以更好地利用时间一致性,并将注意力模块应用到聚合的多尺度特征图上,以强制网络利用判别性时空特征来获得更好的性能;
该网络采用端到端的训练方式,总体损失函数由密度图损失、定位损失和关联损失三部分组成,并在密度图和定位图上使用相同的像素级别欧几里得损失。
其中,所述时空多尺度注意力网络包括:
使用vgg-16网络中的前四组卷积层作为主干以提取多尺度特征;并使用u-net样式架构融合多尺度特征进行人流密度图和定位图的预测;
合并第(t-τ)帧的多尺度特征,并串联第t帧和第(t-τ)帧的特征,其中τ用于确定时间相干性中两个帧之间的帧间隙;
在每个空间注意力模块之后,使用一个1×1卷积层来压缩通道数以提高效率,将网络的多尺度特征图连接起来,合并通道和空间注意力模块以及一个3×3卷积层,以预测最终的人流密度图和定位图;
使用一个3×3卷积层,利用连续帧中共享骨干网络的外观特征,将具有相同标识的目标进行关联。
进一步地,所述时空多尺度注意力网络将多比例尺的特征图按顺序组合在一起,使用组合特征图上的注意力模块来加强网络对判别性时空特征的关注;
利用非抑制和最小代价流关联算法对人的头部进行定位,生成视频序列中的人的运动轨迹。
其中,所述总体损失函数计算公式为:
其中,n是批次大小,
进一步地,所述密度损失lden为:
其中,w和h是地图的宽度和高度,
使用几何自适应高斯核来生成真实标注密度图φ(i,j,s),使用固定的高斯核k生成定位图,若存在两个高斯重叠,则采用取最大值处理。
其中,所述关联损失lass为:
其中,α是ds和dd之间的边距,idi,j∈m的每个目标都包含一个关联特征;
使用批处理硬三元组损失来训练关联人头,该损失对每个目标进行难正样本和难负样本的采样。
进一步地,所述方法还包括:
在每个视频帧的预测密度图上找到大于θ的局部峰值或最大密度值,确定人员的头部位置;
计算连续帧中不同头部对之间的欧几里得距离,并使用最小代价流来关联最接近的人以生成其轨迹。
其中,所述方法还包括:
构建基于无人机的视频人群计数数据集,该数据集提供了20,800个人的轨迹,并具有480万个人头注释和序列中的照明情况、海拔高度、对象密度,所述数据集用于针对密集人群中的密度图估计、定位和跟踪的方法测试。
所述方法使用跟踪评估协议来评估,每个跟踪器都需输出一系列带有置信分数和相应身份的定位点,根据检测到的平均置信度,对具有相同标识的检测位置组成的跟踪小片段进行排序,如果预测和真实tracklet之间的匹配比率大于阈值,则tracklet正确。
本发明提供的技术方案的有益效果是:
1、本发明设计了一个由计数分支、定位分支和跟踪分支三个分支组成的时空多尺度注意力网络来同时解决密度图估计、定位和跟踪任务,然后逐步将注意力模块应用到聚合的多尺度特征图上,以强制网络利用判别性时空特征来获得更好的性能;
2、本发明提出了一个基于无人机的大规模人群计数数据集,用于密集人群中的密度图估计,定位和跟踪,该数据集涵盖了各种场景,在数据类型和数量、注释质量和难度方面都大大超过了现有数据集;
3、本发明提出一个包括密度图损失、定位损失和关联损失多任务损失函数,从而使网络中的不同分支关注不同尺度的对象以完成更多任务。
附图说明
图1为整体网络结构示意图;
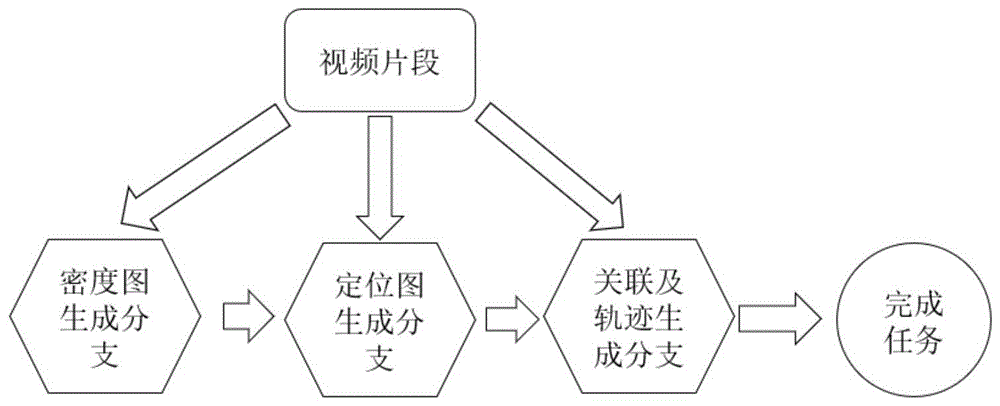
图2为一种基于时空多尺度网络的人流密度图估计、定位和跟踪方法的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
为了解决背景技术中存在的问题,本发明实施例提出了一种基于时空多尺度网络的人流密度图估计、定位和跟踪方法,其亮点设计了一个由计数分支、定位分支和跟踪分支三个分支组成的时空多尺度注意力网络,可同时解决密度图估计、定位和跟踪任务,采用具有多任务损失的端到端的训练方式,该多任务损失由密度图损失、定位损失和关联损失三项组成。
针对数据集的大小和涵盖的场景有限的问题,本发明提出了一个大型的基于无人机的视频人群计数数据集dronecrowd,该数据集提供了20,800个人的轨迹,并具有480万个人头注释和序列中的几个视频级属性。该数据集涵盖了各种场景,可用于针对密集人群中的密度图估计、定位和跟踪的方法测试。
针对解决视频中的人流密度图估计、定位和跟踪的问题,本方法在连续帧中聚合多尺度特征图以利用时间一致性,并将注意模块应用到聚合的多尺度特征图上,以强制网络利用判别性时空特征来获得更好的性能,解决密集人群中密度任意的人群密度、视角和飞行高度的无人机捕获的视频片段的密度图估计、定位和跟踪。
实施例1
本发明实施例提供了一种基于时空多尺度网络的人流密度图估计、定位和跟踪方法,该方法包括以下步骤:
101:本发明中的stanet方法使用vgg-16网络[4]中的前四组卷积层作为主干以提取多尺度特征;并使用u-net样式架构[5]融合多尺度特征进行人流密度图和定位图的预测;
同时,为了利用时间一致性,合并第(t-τ)帧的多尺度特征,并串联第t帧和第(t-τ)帧的特征,其中τ为一个预先确定的参数,该参数确定时间相干性中两个帧之间的帧间隙。在多尺度功能上应用空间注意力模块(本领域公知的技术术语,本发明实施例对此不做赘述),加强网络对判别性特征的关注。
102:在每个空间注意力模块之后,使用一个1×1卷积层来压缩通道数以提高效率,将网络的多尺度特征图连接起来,合并通道和空间注意力模块以及一个3×3卷积层,以预测最终的人流密度图和定位图;使用一个3×3卷积层,利用连续帧中共享骨干网络的外观特征,将具有相同标识的目标进行关联;
103:总体损失函数由密度图损失、定位损失和关联损失三部分组成,在多尺度密度图和定位图上使用相同的像素级别欧几里得损失,进而使网络中的不同分支关注不同尺度的对象以生成更准确的预测。
综上所述,本方法通过由计数分支、定位分支和跟踪分支三个分支组成的时空多尺度注意力网络(stanet),可同时解决密度图估计、定位和跟踪任务,在连续帧中聚合多尺度特征图以更好地利用时间一致性,并将注意力模块应用到聚合的多尺度特征图上,以强制网络利用判别性时空特征来获得更好的性能。
实施例2
下面结合具体的实例、计算公式对实施例1中的方案进行进一步地介绍,详见下文描述:
一、数据准备
本发明提出的dronecrowd视频数据集是通过安装在无人机上的摄像机(djiphantom4,phantom4pro和mavic)捕获的,涵盖了各种场景,dronecrowd数据集分为训练集和测试集,分别具有82和30个序列。
为了更好的分析算法的性能,定义了数据集的三个视频属性:照明情况影响对物体外观的观察,包括三种照明条件:阴天、晴天和夜晚;海拔高度是无人机的飞行高度,包括两个海拔高度:高(<70m)和低(>70m);密度指示每帧中的对象数量,包括两个密度级别,即拥挤(每个帧中的对象数大于150)和稀疏(每个帧中的对象数小于150)。
二、时空多尺度网络结构
本发明中的时空多尺度注意力网络(stanet),如图1所示,网络结构由计数分支、定位分支和跟踪分支三个分支组成的,可同时解决密度图估计、定位和跟踪任务。
时空多尺度注意力网络(stanet)将多比例尺的特征图按顺序组合在一起,同时使用组合特征图上的注意力模块来加强网络对判别性时空特征的关注。最后,利用非抑制和最小代价流关联算法[6]对人的头部进行定位,生成视频序列中的人的运动轨迹。
stanet方法的网络结构使用vgg-16网络[4]中的前四组卷积层作为主干,来提取对象的多尺度特征,并使用u-net样式架构[5]融合多尺度特征进行预测。同时,为了利用时间相干性,合并第(t-τ)帧的多尺度特征,并串联第t帧和第(t-τ)帧的特征,其中τ为一个预先确定的参数,该参数确定时间相干性中两个帧之间的帧间隙。在多尺度功能上应用空间注意力模块,加强网络对判别性特征的关注。在每个空间注意力模块之后,使用一个1×1卷积层来压缩通道数以提高效率。将网络的多尺度特征图连接起来,合并通道和空间注意模块以及一个3×3卷积层,以产生最终的人流密度图和定位图。基于归一化后的特征,利用连续帧中共享骨干的外观特征,使用一个3×3卷积层,将具有相同标识的目标进行关联。
三、评估指标和协议
为了计算图像中每个位置的每像素密度,进行密度图估计任务并同时保留有关人的分布的空间信息。本方法使用平均绝对误差(mae)和均方误差(mse)来评估性能,即
其中,k是视频片段的数量,ni是第i个视频的帧数。zi,j和
评估算法为每个测试图像输出一系列带有置信度分数的检测点,由置信度阈值确定的估计定位与使用贪婪算法的真实标注(ground-truth)定位相关,在各种距离阈值(像素为1,2,3,…,25)下计算平均精度(l-map),以评估定位结果。
人群追踪需要一种经过评估的算法来恢复视频序列中人物的轨迹。本方法使用跟踪评估协议来评估算法。每个跟踪器都需要输出一系列带有置信分数和相应身份的定位点,随后根据检测到的平均置信度,对具有相同标识的检测位置组成的跟踪小片段(tracklet)进行排序。如果预测和真实tracklet之间的匹配比率大于阈值,则认为tracklet正确。
四、损失函数
本方法的总体损失函数由密度图损失、定位损失和关联损失三部分组成,计算公式如下
其中,n是批次大小。
在多尺度密度图和定位图上使用相同的像素级别欧几里得损失,进而使网络中的不同分支注不同尺度的对象以生成更准确的预测。其中,密度损失lden计算为:
其中,w和h是地图的宽度和高度,
使用几何自适应高斯核方法来生成真实标注(ground-truth)密度图φ(i,j,s),随后使用固定的高斯核k生成定位图,如果出现两个高斯重叠的情况,则采用取最大值的方法处理。
使用批处理硬三元组损失来训练关联人头,该损失对每个目标进行hardpositives(难正样本,即训练过程中损失最高的正样本)和hardnegatives(难负样本,即训练过程中损失最高的负样本)的采样。关联损失lass计算公式为:
其中,α是ds和dd之间的边距,idi,j∈m的每个目标都包含一个关联特征。
五、模型的使用细节
1、数据扩充:由于计算资源有限,采取随机翻转并裁剪训练图像的策略以增加训练数据的多样性,对于大于1920×1080的图像,首先调整图像的大小,使其尺寸小于1920×1080。随后将其平均分为两个2个色块,最后使用划分后的4个色块进行训练。
2、模型优化:在公式(4)中将边距α设置为0.2,并且将预设权重设置为λden=1,λloc=0.0001和λass=10以达到平衡。
根据经验,将公式(3)中的预设权重设为ω={0.0125,0.125,0.5,0.5}。本方法中的高斯归一化方法用于在其他(反)卷积层中初始化参数,在训练中将批大小n设置为9,随后使用adam优化算法,在最初的10个周期内以10-6的学习速率训练网络,并在20个周期内以10-5的学习速率训练网络。
3、定位和跟踪:在获得每个帧的密度图之后,基于预设的阈值θ,使用非最大抑制方法定位每个帧中的人的头部,也就是说,在每个视频帧的预测密度图上找到大于θ的局部峰值或最大密度值,以确定人员的头部位置。然后计算连续帧中不同头部对之间的欧几里得距离,并使用最小代价流算法[6]来关联最接近的人(headpoints)以生成其轨迹。
本发明实施例具有以下三个关键创造点:
一、提出一个大型的基于无人机的视频人群计数数据集dronecrowd
技术效果:该数据集提供了20,800个人的轨迹,并具有480万个人头注释和序列中的几个视频级属性。该数据集涵盖了各种场景,可用于针对密集人群中的密度图估计、定位和跟踪的方法测试。
二、提出一个由计数分支、定位分支和跟踪分支三个分支组成的时空多尺度注意力网络
技术效果:该网络可同时解决密度图估计、定位和跟踪任务,增加了任务处理维度,提升了目标计数和追踪的实现效果
三、提出一个包括密度图损失、定位损失和关联损失多任务损失函数;
技术效果:在多尺度密度和定位图上使用相同的像素级欧几里得损失,从而使网络中的不同分支关注不同尺度的对象以完成更多任务。
综上所述,本方法通过由计数分支、定位分支和跟踪分支三个分支组成的时空多尺度注意力网络(stanet),可同时解决密度图估计、定位和跟踪任务,在连续帧中聚合多尺度特征图以利用时间一致性,并将注意模块应用到聚合的多尺度特征图上,以强制网络利用判别性时空特征以获得更好的性能。
实施例3
本发明实施例采用的实验结果1如表1所示,反映了stanet方法在公共数据集shanghaitecha、shanghaitechb、ucf-qnrf三个人群计数数据集上的表现,评估结果显示本方法达到了mae为107.6和mse为174.8,超过了大多数最先进的方法,表明本发明的方法可以生成更为可靠准确的密度图。
本发明实施例采用的实验结果2如表2所示,分别展示出了人群定位和跟踪任务在dronecrowd数据集上的评估结果,stanet方法对预测的定位图进行后处理并将目标定位。随后使用最小成本流算法来恢复人群轨迹。stanet方法在dronecrowd数据集上表现出色,与所有最佳测试集中的表现最佳的csrnet[7]方法相比,mae和mse结果分别提高了3.1和5.8,能够很好的完成人群定位和跟踪任务。
本发明实施例采用的实验结果3如表3所示。该结果展示了stanet方法的三个变体在dronecrowd数据集上的测试表现,三种方法即为stanet(w/oass),stanet(w/oloc)和stanet(w/oms),stanet(w/oass)为stanet中删除关联头部的方法。stanet(w/oloc)为stanet中删除定位头部的方法,stanet(w/oms)表示进一步消除预测中的多尺度特征的方法即仅使用vgg16中的前四组卷积层的方法。如表3所示,stanet取得了比其变体更好的结果,表明时间关联有助于提高鲁棒性,同时验证了定位头部、多尺度特征可以显著提高了密度图估计任务的性能。结果表明,关联和定位头以及多尺度表示对于人群跟踪至关重要。
表1
表2
表3
本发明实施例对各器件的型号除做特殊说明的以外,其他器件的型号不做限制,只要能完成上述功能的器件均可。
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
参考文献:
[1]haroonidrees,imransaleemi,codyseibert,andmubarakshah.multi-sourcemulti-scalecountinginextremelydensecrowdimages.incvpr,pages2547–2554,2013.
[2]yingyingzhang,desenzhou,siqinchen,shenghuagao,andyima.single-imagecrowdcountingviamulti-columnconvolutionalneuralnetwork.incvpr,pages589–597,2016.
[3]haroonidrees,muhmmadtayyab,kishanathrey,dongzhang,somayaal-m′aadeed,nasirm.rajpoot,andmubarakshah.compositionlossforcounting,densitymapestimationandlocalizationindensecrowds.ineccv,pages544–559,2018.
[4]karensimonyanandandrewzisserman.verydeepconvolutionalnetworksforlarge-scaleimagerecognition.corr,abs/1409.1556,2014.
[5]olafronneberger,philippfischer,andthomasbrox.u-net:convolutionalnetworksforbiomedicalimagesegmentation.inmiccai,pages234–241,2015
[6]hamedpirsiavash,devaramanan,andcharlessc.fowlkes.globally-optimalgreedyalgorithmsfortrackingavariablenumberofobjects.incvpr,pages1201–1208,2011
[7]yuhongli,xiaofanzhang,anddemingchen.csrnet:dilatedconvolutionalneuralnetworksforunderstandingthehighlycongestedscenes.incvpr,pages1091–1100,2018.
- 还没有人留言评论。精彩留言会获得点赞!