一种基于图正则光流注意力网络的动物计数方法与流程
本发明涉及目标计数领域,尤其涉及一种基于图正则光流注意力网络的动物计数方法。
背景技术:
人工智能(ai)的世界正在迅速崛起,目前在农业和野生动植物保护等领域中得到了广泛应用。例如,可以使用配备了摄像头的无人机来检测农作物疾病、识别农作物成熟状况,并监视动物行迹;此外,无人机也非常适合用来跟踪动物行动轨迹和进行群体计数,其特定视角可以避免观察视图中高密度群体中个体之间相互遮挡的问题。尽管近年来无人机在目标计数领域取得了很大进展,但由于目标运动模糊、尺度变化多样、正样本稀疏和目标物体微小等问题,对无人机捕获的信息中的动物进行计数仍然具有挑战性。
目前,基于无人机的动物计数算法的开发仍然缺乏公开可用的大规模基准和数据集。尽管已有数个蝙蝠和企鹅的动物计数数据集,但这些数据集的大小和涵盖的场景仍然有限。在农业和野生动植物保护的应用中,尺度变化、物体微小、视野和高度的变化等问题,同样使目前的数据集的使用有一定的挑战。
一般而言,群体计数方法可分为基于检测的方法,基于回归的方法和基于密度的方法:基于检测的方法的总体框架是利用基于手工特征的滑动窗口检测器来检测目标的位置,但其很难在拥挤的微小物体和高遮挡场景中进行检测;由于深度学习的出色表现,各种方法都偏向将拥挤计数问题通过神经网络进行密度图估计,如利用cnn(卷积神经网络)模型来处理人群密度的变化;视频计数的众多方法中,针对时空信息的处理对提高计数准确性至关重要,如基于卷积lstm(长短期记忆网络)模型以完全捕获时空相关性以进行人群计数。
与基于图像的计数任务相比,基于视频的动物计数既有机遇也有挑战。首先,与人和车辆相比,动物分布稀疏,在复杂场景中不同高度和视角的比例尺变化很大。在动物计数任务中,光学流的准确性直接影响聚合特征的有效性。一般的方法是使用预先训练的光流估计网络提取光流,然后在网络训练过程中固定光流网络,但该方法不适合特定的数据集,也可能影响光学流估计的准确性。
技术实现要素:
本发明提供了一种基于图正则光流注意力网络的动物计数方法,本发明提出了一个大型的基于无人机的视频动物计数数据集animaldrone,提出了图正则化流注意力网络来处理动物计数,它使用基于翘曲损失在线训练光流网络,同时应用图正则化器来维护多个邻域帧之间的时间一致性,在聚合特征图上使用注意力模块来强制网络将注意力集中在针对不同尺度的特征判别上,从而提升了目标计数效果,详见下文描述:
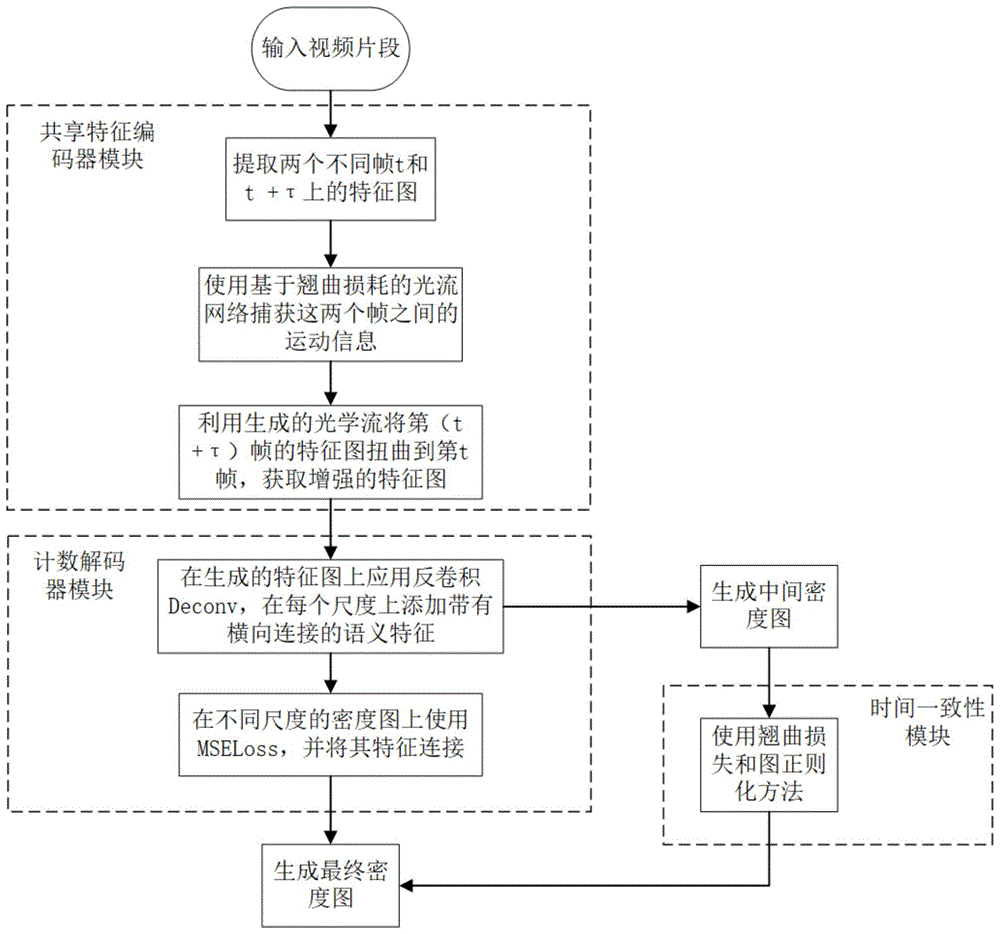
一种基于图正则光流注意力网络的动物计数方法,所述图正则光流注意力网络由共享特征编码器、计数解码器和时间一致性组成,所述方法包括:
所述共享特征编码器用于提取t帧和t+τ帧上的特征图,使用基于翘曲损失的在线光流网络捕获两帧之间的运动信息;利用生成的光学流将第t+τ帧的特征图扭曲到第t帧;通过所述时间一致性模块对得到的特征图使用翘曲损失计算,获得特征图与原始特征编码器之间的误差;
所述计数解码器模块将反卷积deconv逐步应用于光流翘曲生成的特征图,从而产生不同尺度的特征图。在每个尺度上添加带有横向连接的语义特征,然后应用1×1卷积层以获得中间密度图,并在每个尺度的密度图上使用mseloss(均方损失)函数;
将添加语义特征后的每个尺度的特征进行融合,在进行特征融合时采用多粒度损失函数减少误差的产生。最后,使用1×1卷积层生成最终密度图,并在最终密度图中通过所述时间一致性模块使用图正则化以进一步增强时间关系。
其中,所述基于翘曲损失的在线光流网络具体为:
根据图像帧it、it+τ生成双向光流ft→t+τ、ft+τ→t,同时将其送至共享特征编码器中以获得特征图st、st+τ;通过生成ft→t+τ、ft+τ→t,将st、st+τ扭曲到s't、s't+τ;
在任务中为每个框架设置标签,利用所示公式应用翘曲损失:
其中,sij为第i帧到第j帧的特征图,fij为第i帧到第j帧的光流,warp函数用于计算网络中的翘曲损失。
进一步地,所述多粒度损失函数包括:像素级别的密度损失和区域级别的计数损失,密度损失衡量的是所估计的密度图与地面真实密度图之间的密度差;计数损失衡量的是不同区域中动物数量的相对差异;
多粒度损失的计算公式如下:
其中,n是批次大小,w和h分别是密度图的宽度和高度;m(n)(i,j)和
其中,所述使用图正则化以进一步增强时间关系具体为:
令g={v,ε}表示由k帧构成的邻域图,
其中,mi代表第i帧的密度图,k是batch中的帧数,mj代表第j帧的密度图,aij使用rbf-kernel计算,即
其中,
进一步地,所述方法还包括:构建基于无人机的视频动物计数数据集,该数据集由53,644帧以及超过400万个对象注释组成。
本发明提供的技术方案的有益效果是:
1、本发明提出了一个图正则化光流注意力网络来处理动物计数,能够实现光流网络的在线训练,并加入图正则化处理,在聚合特征图上使用注意力模块来强制网络将注意力集中在不同尺度对象的判别特征上;
2、本发明提出了一个大型的基于无人机的视频动物计数数据集animaldrone,该数据集由53,644帧以及超过400万个对象注释组成。数据集的场景涵盖了不同的场景,动物种类多样,可用于多种目标计数方法的测试。
附图说明
图1为一种基于图正则光流注意力网络的动物计数方法的流程图;
图2为整体网络结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面对本发明实施方式作进一步地详细描述。
为了解决背景技术中存在的问题,本发明实施例提出了一个基于图正则光流注意力网络(gfan)的动物计数方法。与采用预先计算的光流的现有作品相比,本方法可通过在线训练光流网络提升目标计数效果。此外,该方法采用多粒度方案以生成不同尺度的判别特征,同时应用图正则化器来维护多个邻域帧之间的时间一致性,将注意力模块逐渐应用于聚合的特征图上,以强制网络利用判别性特征以获得更好的性能。
针对数据集的大小和涵盖的场景有限的问题,本发明提出了一个大型的基于无人机的视频动物计数数据集animaldrone,该数据集由53,644帧以及超过400万个对象注释组成。数据集的场景涵盖了不同的场景,动物种类多样,可用于多种目标计数方法的测试。
针对动物聚集导致整个图像的密度不均匀的问题,本发明构造了一个新的多粒度损失函数,在本发明中的动物计数方法更专注于高密度区域的计数的情况下,该函数能够更加关注低密度区域以减少动物的计数误差。
实施例1
本发明实施例提供了一种基于图正则光流注意力网络的动物计数方法,参见图1,该方法包括以下步骤:
101:图正则化流注意力网络(gfan)由三部分组成:共享特征编码器模块,计数解码器模块和时间一致性模块,网络结构示意图如图2所示。
其中,共享特征编码器模块使用vgg-16网络[1]中的前四组卷积层作为主干,以提取两个不同帧t和t+τ上的特征图(featuremap),然后使用基于翘曲损失的在线光流网络来捕获这两个帧之间的运动信息。为了获得增强的特征图,利用生成的光学流将第(t+τ)帧的特征图扭曲到第t帧,参数τ确定两个帧之间的时间距离。通过时间一致性模块对得到的特征图使用翘曲损失计算,获得特征图与原始特征编码器之间的误差。
102:计数解码器模块将反卷积deconv逐步应用于光流翘曲生成的特征图,从而产生不同尺度的特征图。在每个尺度上添加带有横向连接的语义特征,然后应用1×1卷积层以获得中间密度图,并在每个尺度的密度图上使用mseloss(均方损失)函数。
103:将102中添加语义特征后的每个尺度的特征进行融合,在进行特征融合时采用多粒度损失函数减少误差的产生。最后,使用1×1卷积层生成最终密度图,并在最终密度图中通过时间一致性模块使用图正则化以进一步增强时间关系。
其中,上下文中所述的特征图为:网络中卷积层的输出结果;语义特征为:网络的高层特征;判别性特征为:融合多个卷积层中不同尺度的特征而得到更具有判别性的特征。该些术语均为本领域技术人员所公知的技术术语,本发明实施例对此不做赘述。
综上所述,本方法中的图正则光流注意力网络gfan使用基于翘曲损失的在线光流网络,从而增强了计数功能。利用多尺度特征图聚合和关注机制来应对尺度变化,以融合不同尺度的特征得到更具有判别性的特征,并提出了一种多粒度损失函数来测量高密度损失和低密度损失。同时,应用图正则化器来维护多个邻域帧之间的时间一致性。最后,将注意力模块逐渐应用于聚合的特征图上,以强制网络利用判别性特征来获得更好的性能。
实施例2
下面结合具体的实例、计算公式对实施例1中的方案进行进一步地介绍,详见下文描述:
一、数据准备
本发明训练时采用本方法中由无人机收集的基于视频的大型动物计数数据集animaldrone,该数据集由两个子集组成,即animaldrone-parta和animaldrone-partb,数据集的场景涵盖了不同的场景,动物种类多样。经过数据修剪和注释数据后,animaldrone-parta包括训练集和测试集在内包含18,940张图像和2,008,570个带注释的对象,animaldrone-partb包括训练片段和测试片段在内的103个视频片段,共计34704个帧和2040598个带注释的对象。可用于多种目标计数方法的测试
二、基于翘曲损失的在线光流网络
由于考虑时间相干性,本方法首先根据图像帧it、it+τ生成双向光流ft→t+τ、ft+τ→t,同时将其送至共享特征编码器网络中以获得特征图st、st+τ。通过生成ft→t+τ、ft+τ→t,将st、st+τ扭曲到s't、s't+τ。s't、st和st+τ、s't+τ之间的偏移是由于光学流不准确所致。
在任务中为每个框架设置标签。利用下面所示公式应用翘曲损失:
其中,sij为第i帧到第j帧的特征图,fij为第i帧到第j帧的光流,warp函数用于计算网络中的翘曲损失,该公式可训练光流网络以获得更好的光流。
三、多粒度损失函数
本方法的损失函数包括:像素级别的密度损失和区域级别的计数损失两类。像素级别的损失衡量的是所估计的密度图与地面真实密度图之间的密度差。区域损失衡量的是不同区域中动物数量的相对差异。
多粒度损失的计算公式如下:
其中,n是批次大小,w和h分别是密度图的宽度和高度。m(n)(i,j)和
四、时间图正则化
本方法通过在线训练的光流网络,提取运动信息并考虑时间相干性。使用最小批处理(mini-batch)sgd来更新网络参数。相邻的k帧放入一个mini-batch中,批大小因而设置为k。根据流形假设,原始特征空间中k个帧的关系应保留在投影密度图空间中。
令g={v,ε}表示由k帧构成的邻域图,其中
其中,mi代表第i帧的密度图,k是batch中的帧数,mj代表第j帧的密度图。aij使用rbf-kernel计算,即
其中,
在这里给出gfan模型的损失函数,即:
l=lc+lw+lm+lg(5)
其中,lc是用于多尺度密度图估计的mseloss函数,lw,lm和lg分别是翘曲损耗,多粒度损耗和图正则化器。可以使用大规模视频片段以端到端的方式训练gfan。
本发明实施例具有以下三个关键创造点:
一、提出由无人机收集的基于视频的大型动物计数数据集animaldrone;
技术效果:数据集由无人机摄像机捕获的视频片段构成,共有53,644个帧,其中包含超过400万个对象注释和如密度,高度和视图等多个属性,可用于农业和野生动植物保护。
二、提出基于翘曲损失的在线光流网络;
技术效果:可以实现在线训练光流网络,在数据集中缺少光学流标记的情况下,可以提高光学流评估网络的性能,从而增强了计数功能。
三、提出维护多个邻域帧之间的时间一致性的时间图正则化器
技术效果:应用图正则化来维护多个邻域帧之间的时间一致性,将注意力模块逐渐应用于聚合的特征图上,以强制网络利用判别性特征来获得更好的性能。
综上所述,本方法中的图正则光流注意力网络gfan使用基于翘曲损失的在线光流网络,从而增强了计数功能。利用多尺度特征图聚合和关注机制来应对尺度变化,以融合不同尺度的特征得到更具有判别性的特征,并提出了一种多粒度损失函数来测量高密度损失和低密度损失。同时,应用图正则化器来维护多个邻域帧之间的时间一致性。最后,将注意力模块逐渐应用于聚合的特征图上,以强制网络利用判别性特征来获得更好的性能。
实施例3
本发明实施例采用的实验结果1如表1所示。该结果展示了多种最新方法的在animaldrone两部分a、b的数据集上的计数评估结果,评估方法包括mcnn[2],mscnn[3],csrnet[4]等方法以及本发明中的方法。所有的计数方法都在训练集中进行训练,并在测试集中进行评估。结果表明,本发明所使用方法可以在不同的情况下生成更准确的密度图,相比其他方法获得更好的表现。实验结果反映出本发明所用的方法优于现有方法。
本发明实施例采用的实验结果2如表2所示。该结果展示了gfan的三个变体,即gfan-w/o-graph,gfan-w/o-warp和gfan-w/o-cnt对整个animaldrone数据集测试的评估结果,以便更好的获得本发明中网络中每个模块的影响。gfan的所有变体都在训练集中进行训练,并在测试集中以相同的参数设置和输入大小对其进行评估。gfan的三个变体分别为:gfan-w/o-graph为不带图形正则化模块的gfan的变体;gfan-w/o-warp为消除了gfan-w/o-graph的弯曲损耗并固定了光流网络的变体;gfan-w/o-cnt表示从gfan-w/o-warp中消除区域计数损失的变体。从结果上看本方法中的gfan在数据集parta和partb上均胜过其三个变体。
表1
表2
本发明实施例对各器件的型号除做特殊说明的以外,其他器件的型号不做限制,只要能完成上述功能的器件均可。
本领域技术人员可以理解附图只是一个优选实施例的示意图,上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
参考文献:
[1]karensimonyanandandrewzisserman.verydeepconvolutionalnetworksforlarge-scaleimagerecognition.corr,abs/1409.1556,2014.
[2]zhang,y.,zhou,d.,chen,s.,gao,s.,ma,y.:single-imagecrowdcountingviamulti-columnconvolutionalneuralnetwork.in:cvpr.pp.589–597(2016)
[3]zeng,l.,xu,x.,cai,b.,qiu,s.,zhang,t.:multi-scaleconvolutionalneuralnetworksforcrowdcounting.in:icip.pp.465–469(2017)
[4]li,y.,zhang,x.,chen,d.:csrnet:dilatedconvolutionalneuralnetworksforunderstandingthehighlycongestedscenes.in:cvpr.pp.1091–1100(2018)
- 还没有人留言评论。精彩留言会获得点赞!