车辆数据的处理方法、装置及存储介质与流程
本发明涉及车辆数据处理技术领域,尤其涉及一种车辆数据的处理方法、装置及存储介质。
背景技术:
现代车辆越来越多地采用电子装置控制,如发动机的定时和注油控制、加速和刹车控制及复杂的抗锁定刹车系统等。这些控制需要检测及交换大量数据,can(controllerareanetwork,控制器局域网络)总线由于实时性好及成本低等特点被广泛应用于车辆中进行can数据传输。
在车辆的车载后装应用场景中,很多终端设备需要采集并分析处理车辆的can数据,例如后装液晶仪表系统需要采集车辆的can数据,并分析出发动机转速、水温、油量、开关门、常见告警等数据后在仪表上显示;第三方环视系统需要采集车辆的can数据,并分析出车辆的方向盘轨迹数据后叠加到视频图像上,辅助司机驾驶。现有技术中在需要获取不同车辆的can数据中的某一数据时,通常采用的是统一的文本,根据文本中定义的该数据对应的位置参数直接从can数据中截取需要的数据。这种处理方式只适合获取少量数据的情况,当获取数据量较大或更换车辆时,需要在文本中定义大量参数甚至重新定义参数,导致代码改动量大,因此通用性较差。
技术实现要素:
本发明的主要目的在于提供一种车辆数据的处理方法、装置及存储介质,旨在解决现有技术中can数据的处理方式通用性差的技术问题。
为实现上述目的,本发明提供一种车辆数据的处理方法,所述方法包括以下步骤:
接收待取数据的获取指令;
根据所述获取指令获取车辆的车型名称及can数据,并根据所述车型名称获取对应的xml文件;
根据所述xml文件对所述can数据进行解析,获得所述待取数据。
优选地,所述根据所述xml文件对所述can数据进行解析,获得所述待取数据的步骤,包括:
从所述can数据中获取第一标识符的值,在所述xml文件中查找是否有与所述第一标识符的值相同的第一子节点;
在有与所述第一标识符的值相同的第一子节点时,获取与所述第一标识符的值相同的第一子节点对应的第二子节点的节点信息;
根据所述第二子节点的节点信息从所述can数据中获得所述待取数据。
优选地,所述根据所述第二子节点的节点信息从所述can数据中获得所述待取数据的步骤,包括:
判断所述节点信息中是否存在匹配条件;
在存在所述匹配条件时,判断所述can数据是否满足所述匹配条件;
在所述can数据满足所述匹配条件时,根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息从所述can数据中获得所述待取数据。
优选地,所述在所述can数据满足所述匹配条件时,根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息从所述can数据中获得所述待取数据的步骤,包括:
在所述can数据满足所述匹配条件时,判断所述第二子节点是否存在孙节点;
在所述第二子节点存在孙节点时,获取所述孙节点与所述第二子节点的关联信息;
根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息及所述关联信息从所述can数据中获得所述待取数据。
优选地,所述根据所述车型名称获取对应的xml文件的步骤之前,所述方法还包括:
获取所述车型名称对应的can数据的字节序;
根据所述字节序及所述车型名称创建所述xml文件的全局信息节点;
获取所述待取数据对应的第二标识符的值;
根据所述第二标识符的值及预设解析规则创建所述xml文件的分类信息节点。
优选地,所述根据所述第二标识符的值及预设解析规则创建所述xml文件的分类信息节点的步骤,包括:
将所述第二标识符的值写入所述分类信息节点的第一子节点;
将所述预设解析规则写入所述分类信息节点的第二子节点。
优选地,所述预设解析规则包括数据类型、数据起始位及数据长度。
优选地,所述将所述预设解析规则写入所述分类信息节点的第二子节点的步骤之前,所述方法还包括:
判断所述待取数据对应的有效信息的数量;
在所述有效信息的数量为1时,执行所述将所述预设解析规则写入所述分类信息节点的第二子节点的步骤;
在所述有效信息的数量大于1时,执行将所述预设解析规则写入所述分类信息节点的第二子节点及所述第二子节点的孙节点的步骤。
此外,为实现上述目的,本发明还提供一种车辆数据的处理装置,所述车辆数据的处理装置包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的车辆数据的处理程序,所述车辆数据的处理程序配置为实现所述的车辆数据的处理方法的步骤。
此外,为实现上述目的,本发明还提供一种存储介质,所述存储介质上存储有车辆数据的处理程序,所述车辆数据的处理程序被处理器执行时实现所述的车辆数据的处理方法的步骤。
本发明通过接收待取数据的获取指令;根据获取指令获取车辆的车型名称及can数据,并根据车型名称获取对应的xml文件;根据xml文件对can数据进行解析,获得待取数据。其中,通过为不同车型名称的车辆定义不同的xml文件,在接收到待取数据的获取指令,并采集到车辆的can数据后,可以根据车辆对应的xml文件对can数据进行解析,进而从can数据中截取待取数据供第三方设备使用。当待取数据量较大或车辆更换时,只需要在对应的xml文件中增加配置项或更换其他xml文件即可,代码改动量小,可以适配不同车型名称的车辆,提高了方案的通用性。
附图说明
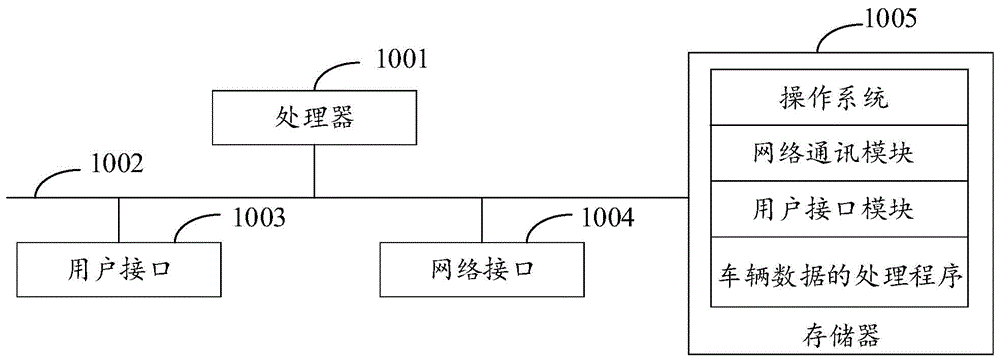
图1是本发明实施例方案涉及的硬件运行环境的车辆数据的处理装置结构示意图;
图2为本发明车辆数据的处理方法一实施例的流程示意图;
图3为本发明车辆数据的处理方法另一实施例的流程示意图;
图4为本发明车辆数据的处理方法又一实施例的流程示意图;
图5为本发明车辆数据的处理系统一实施例的功能模块图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参照图1,图1为本发明实施例方案涉及的硬件运行环境的车辆数据的处理装置结构示意图。
如图1所示,该车辆数据的处理装置可以包括:处理器1001,例如cpu,通信总线1002、用户接口1003,网络接口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1005可以是高速ram存储器,也可以是稳定的存储器(non-volatilememory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图1中示出的结构并不构成对车辆数据的处理装置的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图1所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及车辆数据的处理程序。
在图1所示的车辆数据的处理装置中,网络接口1004主要用于与外部网络进行数据通信;用户接口1003主要用于接收用户的输入指令;所述车辆数据的处理装置通过处理器1001调用存储器1005中存储的车辆数据的处理程序,并执行以下操作:
接收待取数据的获取指令;
根据所述获取指令获取车辆的车型名称及can数据,并根据所述车型名称获取对应的xml文件;
根据所述xml文件对所述can数据进行解析,获得所述待取数据。
进一步地,处理器1001可以调用存储器1005中存储的车辆数据的处理程序,还执行以下操作:
从所述can数据中获取第一标识符的值,在所述xml文件中查找是否有与所述第一标识符的值相同的第一子节点;
在有与所述第一标识符的值相同的第一子节点时,获取与所述第一标识符的值相同的第一子节点对应的第二子节点的节点信息;
根据所述第二子节点的节点信息从所述can数据中获得所述待取数据。
进一步地,处理器1001可以调用存储器1005中存储的车辆数据的处理程序,还执行以下操作:
判断所述节点信息中是否存在匹配条件;
在存在所述匹配条件时,判断所述can数据是否满足所述匹配条件;
在所述can数据满足所述匹配条件时,根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息从所述can数据中获得所述待取数据。
进一步地,处理器1001可以调用存储器1005中存储的车辆数据的处理程序,还执行以下操作:
在所述can数据满足所述匹配条件时,判断所述第二子节点是否存在孙节点;
在所述第二子节点存在孙节点时,获取所述孙节点与所述第二子节点的关联信息;
根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息及所述关联信息从所述can数据中获得所述待取数据。
进一步地,处理器1001可以调用存储器1005中存储的车辆数据的处理程序,还执行以下操作:
获取所述车型名称对应的can数据的字节序;
根据所述字节序及所述车型名称创建所述xml文件的全局信息节点;
获取所述待取数据对应的第二标识符的值;
根据所述第二标识符的值及预设解析规则创建所述xml文件的分类信息节点。
进一步地,处理器1001可以调用存储器1005中存储的车辆数据的处理程序,还执行以下操作:
将所述第二标识符的值写入所述分类信息节点的第一子节点;
将所述预设解析规则写入所述分类信息节点的第二子节点。
进一步地,处理器1001可以调用存储器1005中存储的车辆数据的处理程序,还执行以下操作:
判断所述待取数据对应的有效信息的数量;
在所述有效信息的数量为1时,执行所述将所述预设解析规则写入所述分类信息节点的第二子节点的步骤;
在所述有效信息的数量大于1时,执行将所述预设解析规则写入所述分类信息节点的第二子节点及所述第二子节点的孙节点的步骤。
本实施例通过接收待取数据的获取指令;根据获取指令获取车辆的车型名称及can数据,并根据车型名称获取对应的xml文件;根据xml文件对can数据进行解析,获得待取数据。其中,通过为不同车型名称的车辆定义不同的xml文件,在接收到待取数据的获取指令,并采集到车辆的can数据后,可以根据车辆对应的xml文件对can数据进行解析,进而从can数据中截取待取数据供第三方设备使用。当待取数据量较大或车辆更换时,只需要在对应的xml文件中增加配置项或更换其他xml文件即可,代码改动量小,可以适配不同车型名称的车辆,提高了方案的通用性。
基于上述硬件结构,提出本发明车辆数据的处理方法实施例。
参照图2,图2为本发明车辆数据的处理方法一实施例的流程示意图。
在第一实施例中,所述车辆数据的处理方法包括以下步骤:
s10:接收待取数据的获取指令;
应当理解的是,待取数据指用户需要的数据,可以是发动机转速、水温、油量、开关门、常见告警、方向盘轨迹等数据中的一个或多个数据。
s20:根据所述获取指令获取车辆的车型名称及can数据,并根据所述车型名称获取对应的xml文件;
可以理解的是,车型名称指车辆车型的名称,如迈腾b8、高尔夫7等;can数据指车辆经can总线传输的数据,包括但不限于发动机转速、水温、油量、开关门、常见告警等数据。待取数据可以是can数据中的一个有效信息数据,也可以是can数据中多个有效信息的集合,本实施例对此不加以限制。
根据所述获取指令获取车辆的车型名称及can数据,可以是在接收到获取指令时,获取工程师根据经验输入的车型名称,通过can数据采集模块对车辆的can总线上的数据进行采集后获取,当然也可以通过其他方式获取,本实施例对此不加以限制。
应当理解的是,由于不同车型名称的车辆,can数据中的参数定义可能是不同的,因此,可以为不同车型名称的车辆分别建立xml(extensiblemarkuplanguage,可扩展标记语言)文件,如为迈腾b8车型的车辆建立maitengb8.xml文件、为高尔夫7车型的车辆建立gaoerfu7.xml文件。当需要处理不同车型名称的can数据时,只需要根据车型名称加载对应的xml文件即可。
s30:根据所述xml文件对所述can数据进行解析,获得所述待取数据。
需要说明的是,根据xml文件中的预设解析规则不同,对can数据进行解析的过程也并不相同,例如,当xml文件的预设解析规则中仅包括数据类型、数据起始位及数据长度等信息时,可以根据这些信息从can数据的相应位置中截取待取数据,当预设解析规则中还包括匹配条件时,则需要满足匹配条件后才能截取待取数据。
本实施例通过接收待取数据的获取指令;根据获取指令获取车辆的车型名称及can数据,并根据车型名称获取对应的xml文件;根据xml文件对can数据进行解析,获得待取数据。其中,通过为不同车型名称的车辆定义不同的xml文件,在接收到待取数据的获取指令,并采集到车辆的can数据后,可以根据车辆对应的xml文件对can数据进行解析,进而从can数据中截取待取数据供第三方设备使用。当待取数据量较大或车辆更换时,只需要在对应的xml文件中增加配置项或更换其他xml文件即可,代码改动量小,可以适配不同车型名称的车辆,提高了方案的通用性。
进一步地,如图3所示,基于一实施例提出本发明车辆数据的处理方法另一实施例,在本实施例中,步骤s30包括以下步骤:
s31:从所述can数据中获取第一标识符的值,在所述xml文件中查找是否有与所述第一标识符的值相同的第一子节点;
应当理解的是,第一标识符指can数据的标识符,每一条can数据都有唯一的标识符,标识符的值通常为can数据的前四个字节。
作为一实施例,第一子节点可以为xml文件中的headid节点,一个xml文件中可以有一个或多个headid节点。在收到一条can数据后,可以先获取can数据的前四个字节的第一标识符的值,将第一标识符的值与headid节点中的值进行循环比较,当有与第一标识符的值相同的headid节点时,执行步骤s32,否则比较下一个headid节点。
s32:在有与所述第一标识符的值相同的第一子节点时,获取与所述第一标识符的值相同的第一子节点对应的第二子节点的节点信息;
作为一实施例,第二子节点可以为xml文件中的section节点,一个xml文件中同样可以有一个或多个section节点,每个section节点代表can数据矩阵中的一项,程序可以通过section节点的name属性对不同的section节点进行区分。
section节点的节点信息可以包括数据类型、数据起始位及数据长度,当然还可以包括匹配条件。其中,数据类型可以有三种:num、enum和rawdata,num表示上报的数据类型为数字,enum表示枚举类型,rawdata表示原始数据类型;匹配条件指can数据匹配第二子节点(如section节点)的条件,可以用condition节点表示。
s33:根据所述第二子节点的节点信息从所述can数据中获得所述待取数据。
需要说明的是,在获得待取数据的过程中,还可以判断所述节点信息中是否存在匹配条件;在存在所述匹配条件时,判断所述can数据是否满足所述匹配条件;在所述can数据满足所述匹配条件时,根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息从所述can数据中获得所述待取数据。
可理解的是,在第二子节点的节点信息中没有匹配条件时,可以直接根据节点信息从can数据中获得待取数据。
作为一实施例,当xml文件中存在与can数据的第一标识符的值相同的headid节点时,遍历该headid节点对应的section节点,如果section节点中有匹配条件,则判断条件是否满足,如果条件满足,则根据section节点中指定的数据类型、数据起始位、数据长度等信息截取can消息中指定位置的内容,经过一定转换后,传送给下一个模块进行处理(如ui进程显示、mcu点灯等)。如果section节点中不存在匹配条件,则只要数据类型、数据起始位、数据长度等信息满足要求即可上报待取数据。
进一步地,在所述can数据满足所述匹配条件时,判断所述第二子节点是否存在孙节点;在所述第二子节点存在孙节点时,获取所述孙节点与所述第二子节点的关联信息;根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息及所述关联信息从所述can数据中获得所述待取数据。
需要说明的是,当待取数据是can数据中多个有效信息的集合时,xml文件中需要为section节点设置多个子节点,以下为了区分,用extrasection节点表示。xml文件中可以将第一个有效信息的数据类型、数据起始位、数据长度等信息存放在section节点中;剩下的有效信息的数据类型、数据起始位、数据长度等信息存放在extrasection节点中。同时,通过section节点和extrasection节点的关联信息(以下简称op属性)确定最终上报的待取数据。
其中,op属性合法类型有:"+"、"-"、"*"、"/"、"and"、"both"。"+","-","*","/"分别是加、减、乘、除,"and"只判断条件,不上报extrasection节点数据;"both"既判断条件,也上报extrasection数据。op属性为"+","-","*","/"时,表示上报的信息为section节点中截取的信息与extrasection节点中截取的信息经过加、减、乘、除操作之后的结果值。
本实施例通过在xml文件中设置匹配条件、第一子节点、第二子节点、孙节点和op属性,根据匹配条件和op属性等信息对xml文件进行解析,并从第二子节点和/或孙节点中截取信息作为待取数据,充分考虑到了待取数据的不同特性,不仅提高了数据获取的全面性,还提高了数据截取的准确率。
进一步地,如图4所示,基于一实施例提出本发明车辆数据的处理方法又一实施例,在本实施例中,在步骤根据所述车型名称获取对应的xml文件之前,还需要创建车辆的车型名称对应的xml文件,具体包括以下步骤:
s40:获取所述车型名称对应的can数据的字节序;
可以理解的是,字节序,指字节在电脑中存放时的序列与输入或输出时的序列是先到的在前还是后到的在前,通常可以分为大端字节序和小端字节序。
s50:根据所述字节序及所述车型名称创建所述xml文件的全局信息节点;
作为一实施例,可以在xml文件的全局信息节点中写入字节序和车型名称,当然还可以写入车辆的出厂年份等其他信息。
s60:获取所述待取数据对应的第二标识符的值;
s70:根据所述第二标识符的值及预设解析规则创建所述xml文件的分类信息节点。
应当理解的是,第二标识符指每一条待取数据对应的标识符,预设解析规则可以包括数据类型、数据起始位及数据长度,当然还可以包括匹配条件。
具体地,可以将所述第二标识符的值写入所述分类信息节点的第一子节点;将所述预设解析规则写入所述分类信息节点的第二子节点。
其中,第一子节点为headid节点,第二子节点为section节点。
作为一实施例,xml文件的组织方法如下:
其中,byteorder节点表示车型名称对应的can数据的字节序,le表示小端、be表示大端;cartype节点的name属性表示车型名称;cartype节点的year属性表示车辆的出厂年份。
每个车型有多个分类信息节点(以下称canid节点),每个canid节点对应唯一的帧id,即headid节点携带的值。每个canid节点可以有一或多个section节点,每个section节点代表can矩阵中的一项,程序通过section节点的name属性来区分不同的section节点。
需要说明的是,在xml文件组织时,由于待取数据可能是can数据中多个有效信息的集合,因此需要判断所述待取数据对应的有效信息的数量;在所述有效信息的数量为1时,执行所述将所述预设解析规则写入所述分类信息节点的第二子节点的步骤;在所述有效信息的数量大于1时,执行将所述预设解析规则写入所述分类信息节点的第二子节点及所述第二子节点的孙节点的步骤。
其中,第二节点的孙节点为extrasection节点。
具体地,当有效信息的数量为1时,可以将有效信息的数据类型、数据起始位、数据长度等信息全部存放在section节点中;当有效信息的数量大于1时,可以将第一个有效信息的数据类型、数据起始位、数据长度等信息存放在section节点中;剩下的有效信息的数据类型、数据起始位、数据长度等信息存放在extrasection节点中。并设置section节点和extrasection节点的op属性。
作为一实施例,section节点组织方法如下例一所示:
例1
在例1中,condition指示section节点的匹配条件。其中type属性指示条件数据的组织形式,可支持hexstream等格式,hexstream表示数据组织形式为16进制字节流。condition的子节点有availablebitbegin节点、availablebitlength节点和hexstream节点。上述section节点的匹配条件是只有当can数据中前2个字节为0x3a0e或4a0e时,才算是匹配了这个section节点。
availablebitbegin指示数据开始bit位、availablebitlength指示数据长度bit位,上述section节点表示上报从第24bit开始的8bit数据。lengthbitbegin指示长度字段开始bit位、lengthbitlength指示长度字段长度bit位、valuestartbit指示实际数据开始bit位。
作为另一实施例,section节点组织方法如下例2所示:
例2
例2中的section节点表示待取数据的实际数据开始位为第40bit,数据长度通过读取从第32bit开始的8bit值来获取。
作为又一实施例,section节点组织方法如下例3所示:
例3
其中availablebitbegin和lengthbitbegin的值可以为绝对值,也可以为相对值,当为相对值时,会使用prev关键字,上述例3中section节点表示歌曲名称在歌词片段的后面24bit(3bytes)。
另外,section节点中的数据类型(type属性)可以有三种:num、enum和rawdata,num表示上报的数据类型为数字,enum表示枚举类型,rawdata表示原始数据类型。
当section节点中type="num"时,此类型的section节点可能会有range子节点,如例4所示:
例4
例4中表示当第28bit开始的4bit数据,如果数据范围为0到9,则上报获取到的值,当不在此范围时,根据outrangedefault属性,会上报0。
range子节点也可以不存在,这时表示没有范围限定,任何值都会上报。
num类型的section节点可能会有valuetype子节点,valuetype子节点表示上报的数字的类型,valuetype有三种类型值:uint,int,float,默认是uint类型,即unsignedint;没有valuetype子节点时表示默认,为unsignedint。
当section节点中type="num"时,num类型的section节点可能会有simpleop子节点,如例5所示:
例5
例5表示上报数据类型之前,需要先做计算,先取第24bit开始的12bit数据,然后乘3,计算出的值上报到ui显示。simpleop的type属性表示计算类型,可选值有:"+","-","*","/","cacand","cacor",分别表示加、减、乘、除、与、或。
当section节点中type="enum"时,此类型的section节点必须有enums子节点,如例6所示:
例6
其中enums子节点的每个enum定义一个枚举值,当指定范围的值与对应enum的值匹配时,会上报enum的id属性值。例6中section节点表示:当上报的帧id与headid值匹配,且第28bit长度为1bit的值为0时,上报0;第28bit长度为1bit的值为1时,上报1。
enum的id属性值有一个特殊值:useread,即根据读取到的值上报,如例7所示:
例7
例7中section节点表示:当收到的can数据第40bit开始的8bit数据在1~30之间时,上报这个数字;当数据在31~127之间时,上报30。
enum的值有个一个特殊值:other,如例8所示:
例8
例8中表示除0\4\0xc以外的其他值,上报枚举值2。
当section节点中type="rawdata"时,表示直接上报availablebitbegin和availablebitlength范围指定的字符串。
通过上述方式组织好xml文件以后,获取can数据,将can数据的第一标识符的值与xml文件中的headid节点的值比较,如果相同,则获取headid节点对应的section节点的节点信息,当节点信息中有匹配条件时,则判断can数据是否满足匹配条件,若满足,则根据section节点中指定的数据类型、数据起始位、数据长度等信息截取can数据中指定位置的内容,经过一定转换后,传送给下一个模块进行处理。如果section节点中没有匹配条件,则只要数据类型、数据起始位和数据长度等信息满足要求即可将其作为待取数据上报。
本实施例通过获取所述车型名称对应的can数据的字节序;根据所述字节序及所述车型名称创建所述xml文件的全局信息节点;获取所述待取数据对应的第二标识符的值;根据所述第二标识符的值及预设解析规则创建所述xml文件的分类信息节点实现了xml文件的组织,通用性强且灵活性高。根据上述方法组织的xml文件不仅可以实现不同品牌不同车型的can数据的解析,还可以在待取数据量较大时,减少代码的修改量。
本发明进一步提供一种车辆数据的处理系统。
参照图5,图5为本发明车辆数据的处理系统一实施例的功能模块图。
本实施例中,所述车辆数据的处理系统包括:
指令获取模块10,用于接收待取数据的获取指令;
应当理解的是,待取数据指用户需要的数据,可以是发动机转速、水温、油量、开关门、常见告警、方向盘轨迹等数据中的一个或多个数据。
文件获取模块20,用于根据所述获取指令获取车辆的车型名称及can数据,并根据所述车型名称获取对应的xml文件;
可以理解的是,车型名称指车辆车型的名称,如迈腾b8、高尔夫7等;can数据指车辆经can总线传输的数据,包括但不限于发动机转速、水温、油量、开关门、常见告警等数据。待取数据可以是can数据中的一个有效信息数据,也可以是can数据中多个有效信息的集合,本实施例对此不加以限制。
根据所述获取指令获取车辆的车型名称及can数据,可以是在接收到获取指令时,获取工程师根据经验输入的车型名称,通过can数据采集模块对车辆的can总线上的数据进行采集后获取,当然也可以通过其他方式获取,本实施例对此不加以限制。
应当理解的是,由于不同车型名称的车辆,can数据中的参数定义可能是不同的,因此,可以为不同车型名称的车辆分别建立xml文件,如为迈腾b8车型的车辆建立maitengb8.xml文件、为高尔夫7车型的车辆建立gaoerfu7.xml文件。当需要处理不同车型名称的can数据时,只需要根据车型名称加载对应的xml文件即可。
数据解析模块30,用于根据所述xml文件对所述can数据进行解析,获得所述待取数据。
需要说明的是,根据xml文件中的预设解析规则不同,对can数据进行解析的过程也并不相同,例如,当xml文件的预设解析规则中仅包括数据类型、数据起始位及数据长度等信息时,可以根据这些信息从can数据的相应位置中截取待取数据,当预设解析规则中还包括匹配条件时,则需要满足匹配条件后才能截取待取数据。
其中,所述数据解析模块30还包括:
节点查找子模块,用于从所述can数据中获取第一标识符的值,在所述xml文件中查找是否有与所述第一标识符的值相同的第一子节点;
节点信息获取子模块,用于在有与所述第一标识符的值相同的第一子节点时,获取与所述第一标识符的值相同的第一子节点对应的第二子节点的节点信息;
数据获取子模块,用于根据所述第二子节点的节点信息从所述can数据中获得所述待取数据。
其中,所述数据获取子模块还包括:
匹配条件查找单元,用于判断所述节点信息中是否存在匹配条件;
匹配条件判断单元,用于在存在所述匹配条件时,判断所述can数据是否满足所述匹配条件;
待取数据获取单元,用于在所述can数据满足所述匹配条件时,根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息从所述can数据中获得所述待取数据。
其中,所述待取数据获取单元,包括:
孙节点判断子单元,用于在所述can数据满足所述匹配条件时,判断所述第二子节点是否存在孙节点;
关联信息获取子单元,用于在所述第二子节点存在孙节点时,获取所述孙节点与所述第二子节点的关联信息;
待取数据获取子单元,用于根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息及所述关联信息从所述can数据中获得所述待取数据。
进一步地,所述车辆数据的处理系统还包括:
字节序获取模块,用于获取所述车型名称对应的can数据的字节序;
第一节点创建模块,用于根据所述字节序及所述车型名称创建所述xml文件的全局信息节点;
标识信息获取模块,用于获取所述待取数据对应的第二标识符的值;
第二节点创建模块,用于根据所述第二标识符的值及预设解析规则创建所述xml文件的分类信息节点。
所述第二节点创建模块,包括:
第一子节点创建子模块,用于将所述第二标识符的值写入所述分类信息节点的第一子节点;
第二子节点创建子模块,用于将所述预设解析规则写入所述分类信息节点的第二子节点。
所述第二节点创建模块,还包括:
有效信息判断子模块,用于判断所述待取数据对应的有效信息的数量;
第二子节点创建子模块,还用于在所述有效信息的数量为1时,执行所述将所述预设解析规则写入所述分类信息节点的第二子节点的步骤;
第二子节点创建子模块,还用于在所述有效信息的数量大于1时,执行将所述预设解析规则写入所述分类信息节点的第二子节点及所述第二子节点的孙节点的步骤。
本实施例通过接收待取数据的获取指令;根据获取指令获取车辆的车型名称及can数据,并根据车型名称获取对应的xml文件;根据xml文件对can数据进行解析,获得待取数据。其中,通过为不同车型名称的车辆定义不同的xml文件,在接收到待取数据的获取指令,并采集到车辆的can数据后,可以根据车辆对应的xml文件对can数据进行解析,进而从can数据中截取待取数据供第三方设备使用。当待取数据量较大或车辆更换时,只需要在对应的xml文件中增加配置项或更换其他xml文件即可,代码改动量小,可以适配不同车型名称的车辆,提高了方案的通用性。
此外,本发明实施例还提出一种存储介质,所述存储介质上存储有车辆数据的处理程序,所述车辆数据的处理程序被处理器执行时实现如下操作:
接收待取数据的获取指令;
根据所述获取指令获取车辆的车型名称及can数据,并根据所述车型名称获取对应的xml文件;
根据所述xml文件对所述can数据进行解析,获得所述待取数据。
进一步地,所述车辆数据的处理程序被处理器执行时还实现如下操作:
从所述can数据中获取第一标识符的值,在所述xml文件中查找是否有与所述第一标识符的值相同的第一子节点;
在有与所述第一标识符的值相同的第一子节点时,获取与所述第一标识符的值相同的第一子节点对应的第二子节点的节点信息;
根据所述第二子节点的节点信息从所述can数据中获得所述待取数据。
进一步地,所述车辆数据的处理程序被处理器执行时还实现如下操作:
判断所述节点信息中是否存在匹配条件;
在存在所述匹配条件时,判断所述can数据是否满足所述匹配条件;
在所述can数据满足所述匹配条件时,根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息从所述can数据中获得所述待取数据。
进一步地,所述车辆数据的处理程序被处理器执行时还实现如下操作:
在所述can数据满足所述匹配条件时,判断所述第二子节点是否存在孙节点;
在所述第二子节点存在孙节点时,获取所述孙节点与所述第二子节点的关联信息;
根据所述第二子节点的节点信息中除所述匹配条件之外的其他信息及所述关联信息从所述can数据中获得所述待取数据。
进一步地,所述车辆数据的处理程序被处理器执行时还实现如下操作:
获取所述车型名称对应的can数据的字节序;
根据所述字节序及所述车型名称创建所述xml文件的全局信息节点;
获取所述待取数据对应的第二标识符的值;
根据所述第二标识符的值及预设解析规则创建所述xml文件的分类信息节点。
进一步地,所述车辆数据的处理程序被处理器执行时还实现如下操作:
将所述第二标识符的值写入所述分类信息节点的第一子节点;
将所述预设解析规则写入所述分类信息节点的第二子节点。
进一步地,所述车辆数据的处理程序被处理器执行时还实现如下操作:
判断所述待取数据对应的有效信息的数量;
在所述有效信息的数量为1时,执行所述将所述预设解析规则写入所述分类信息节点的第二子节点的步骤;
在所述有效信息的数量大于1时,执行将所述预设解析规则写入所述分类信息节点的第二子节点及所述第二子节点的孙节点的步骤。
本发明计算机可读存储介质的具体实施例与上述车辆数据的处理方法各实施例基本相同,在此不作赘述。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!