一种动态知识热点演化及趋势分析方法与流程
本发明涉及自然语言处理和信息提取领域,尤其涉及一种动态知识热点演化及趋势分析方法。
背景技术:
随着信息技术不断发展,大量的信息资源不断涌现,从科技文献、书籍到新闻、博客、网页等。面对海量信息,为了有效从爆炸式增长的电子文档中提取有用信息,亟需新的技术和工具帮助用户分析这些海量数据集,以帮助用户对目标学科领域进行快速评估和了解。
大量的语料库(如科技文献)文本都是具有时间属性的,一些特定的文本信息出现在某个特定的时间段中。文本可视化方法通过分析文本资源,提取关键信息,并将其以图形化方式展现出来,是信息可视化的重要分支之一。
目前,针对具有时间属性的文本的主题动态建模分析未能通过可视化方式有效的展示热点单词在时间序列上的动态演变,也不能通过热点单词查找到对应的文献元数据信息。因此,对用户收集的文献信息,需要一种能辅助用户快速了解目标领域,并根据热点单词精确查找对应文献元数据的方法。
技术实现要素:
本发明的目的在于提供一种动态知识热点演化及趋势分析方法。该方法通过时间变化对文本进行动态建模,捕捉主题随时间的动态演变,分析不同主题中的单词随时间的变化趋势,或预测和提取主题的潜在发展趋势,并能通过主题下的热点词定位到与其相关的文献信息。
本发明的目的通过以下的技术方案来实现:
本发明包括以下步骤:
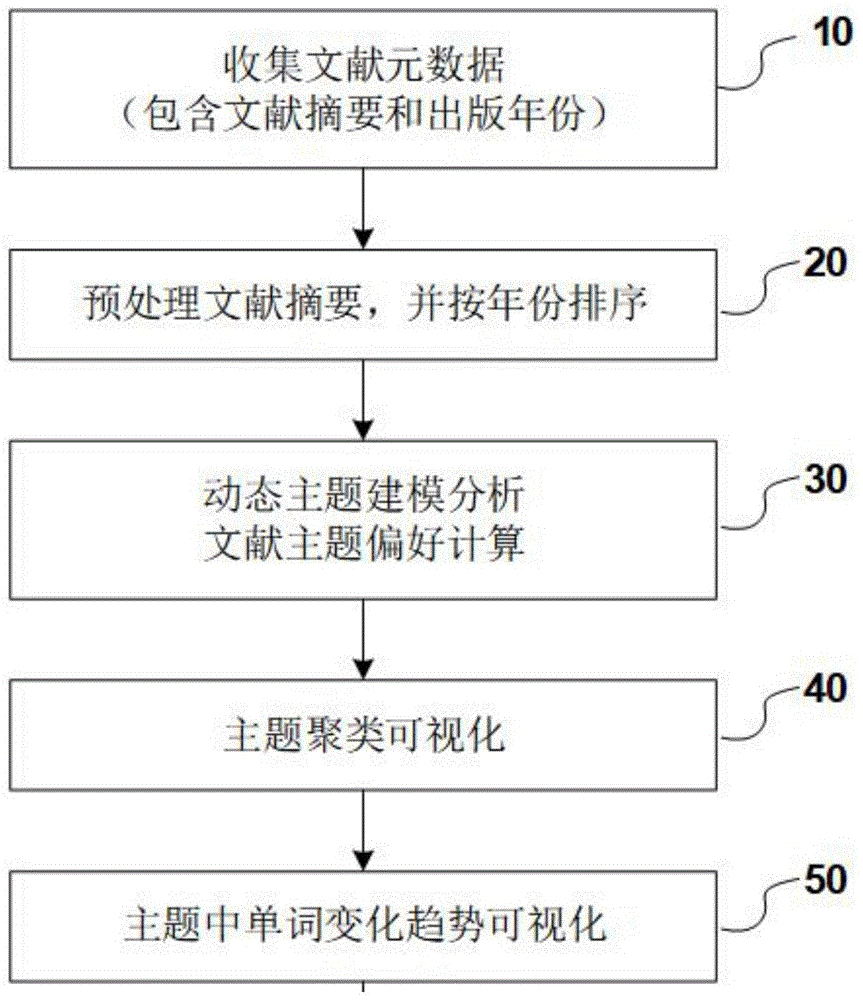
s10用户根据需求收集文献元数据,并输出或形成以制表符分隔且编码格式为utf-8的包含标题、摘要等字段的记录文件;
s20对导出的文献元数据进行预处理工作;
s30选取预处理后文献元数据的摘要和出版年份,进行潜在主题的动态建模分析及文献主题的偏好计算得到热点单词;
s40对所述热点单词的主题聚类进行可视化,显示与每个主题每个年份最相关的热点单词;
s50对主题中热点单词的变化趋势进行可视化:用户选取主题中感兴趣的单词,通过曲线图显示该单词在时间序列上的变化趋势;
进一步地,收集文献元数据主要包括标题、摘要、出版年份等字段,文件存储格式为制表符分隔、utf-8编码的csv或txt纯文本类型,数据集可以从webofscience核心数据库导出对应的格式,或者为符合格式要求的其他自定义数据集。
进一步地,所述预处理工作包括删除无效元数据、完成词干化、去停用词、清除无意义字符和识别短语步骤。
进一步地,所述主题建模分析采用变分推断来近似后验分布。该方法基于如下假设:
1)数据按时间片划分;
2)与时间片t相关联的主题从与时间片t-1相关联的主题演变而来;
3)每个时间片使用k分量主题模型对文档建模;
进一步地,所述热点单词的主题聚类进行可视化是对模型分析结果中热点单词的显示,按照主题分类显示各个时间片(如年份)的热点单词,单词按照模型分析结果的概率大小顺序显示。
进一步地,所述可视化方法具体步骤如下:
1)获取用户选择的热点单词;
2)基于接收到的第一交互指令,对所述主题动态建模分析结果中的热点单词信息进行附加图示计算,所述图示包括等值点;基于所述主题动态建模分析结果中的热点单词信息渲染获得对应的相位点值;
3)基于接收到的第二交互指令,在所述栅格图形上连接多个所述相位点渲染所述附加图示获得曲线趋势图形。
进一步地,所述主题动态建模分别以5、10、15、20、25不同的主题数量计算coherence值,以获得最佳的主题数量。
进一步地,所述主题动态建模中分析时间片t上的序列语料的生成过程如下:
1)根据βt|β(t-1)~n(β(t-1),δ2i)生成时间片t上的主题-词汇概率分布βt;
2)根据αt|α(t-1)~n(α(t-1),δ2i)生成时间片t上的先验主题先验分布αt;
3)对于时间片t上的每一篇文章d,根据η~n(αt,a2i)生成时间片t上的文档-主题概率分布η;
4)对于文档d中的每一个单词n,根据z~mult(π(η))生成词-主题分配标识向量z;根据w(t,d,n)~mult(π(βt,z))生成词w(t,d,n)。
进一步地,所述主题动态建模分析文献或所述偏好计算使用的近似变分后验公式为:
上述变分方法优化潜在变量(主题βt,k,混合比例θt,d和主题指标zt,d,n)上分布的参数。在{βk,1,...,βk,t}变分分布中,通过设置具有高斯“变分观测值”
与现有技术相比,本发明的一个或多个实施例可以具有如下优点:
本发明所提供的一种动态知识热点演化及趋势分析方法,通过时间变化对文本进行动态建模,可视化建模分析结果,分析不同主题中的单词随时间的变化趋势,或预测和提取主题的潜在发展趋势,以及帮助用户通过主题下的热点词定位到与其相关的文献信息,方便用户对目标学科领域进行快速评估和了解。
附图说明
图1是动态知识热点演化及趋势分析方法流程图;
图2是动态知识热点演化及趋势分析方法预处理流程图;
图3是动态知识热点演化及趋势分析方法主题动态建模分析时间片t上的序列语料的生成过程图;
图4是动态知识热点演化及趋势分析方法动态主题建模分析结果可视化图;
图5是动态知识热点演化及趋势分析方法热点单词变化趋势曲线图;
图6是动态知识热点演化及趋势分析方法查找文献元数据图;
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合实施例及附图对本发明作进一步详细的描述。
如图1所示,为动态知识热点演化及趋势分析方法,该方法包括:
步骤s10收集文献元数据;
用户根据自己需求收集文献元数据信息,元数据主要包括标题、摘要、出版年份等字段,文件存储格式为制表符分隔、utf-8编码的csv或txt纯文本类型,数据集可以是从webofscience核心数据库导出对应的格式,或者是符合格式要求的其他自定义数据集。
步骤s20预处理收集文献元数据;
如图2所示,该步骤完成对摘要和出版年份字段的数据预处理,以满足下一步对文本潜在主题的动态建模分析的格式要求。预处理需要完成删除无效元数据、完成词干化、去停用词、清除无意义字符、识别短语。
步骤s30主题动态建模分析;
该步骤是系统的核心分析步骤,完成系统的主要计算任务。
主题动态建模分析采用变分推断来近似后验分布。该方法基于如下假设:
1)数据按时间片划分,比如按年份;
2)与时间片t相关联的主题从与时间片t-1相关联的主题演变而来;
3)每个时间片使用k分量主题模型对文档建模;
时间片t上的序列语料的生成过程如下,如附图3所示:
1)根据βt|β(t-1)~n(β(t-1),δ2i)生成时间片t上的主题-词汇概率分布βt;
2)根据αt|α(t-1)~n(α(t-1),δ2i)生成时间片t上的先验主题先验分布αt;
3)对于时间片t上的每一篇文章d,根据η~n(αt,a2i)生成时间片t上的文档-主题概率分布η;
4)对于文档d中的每一个单词n,根据z~mult(π(η))生成词-主题分配标识向量z;根据w(t,d,n)~mult(π(βt,z))生成词w(t,d,n)。
因此,整个模型的近似变分后验公式为:
上述变分方法优化潜在变量(主题βt,k,混合比例θt,d和主题指标zt,d,n)上分布的参数。在{βk,1,...,βk,t}变分分布中,通过设置具有高斯“变分观测值”
本步骤的主题动态建模分析结果示例如下:
1)时间片序列,按年份划分,例如[2008,2009,2010]。
2)不同主题中,每个时间片序列与主题最相关单词及单词对应的概率,例如(因为实际热点单词太多,这里仅列出每个时间序列上的前3个热点单词):
{0:['0.0140231014*application+0.0138825359*stream+0.0123572007*datum','0.0140471977*application+0.0138904899*stream+0.0124764708*datum','0.0139453390*stream+0.0138278045*application+0.0128339716*datum',
1:['0.0125233824*video+0.0118972892*propose+0.0103776871*network','0.0128266652*video+0.0116539875*propose+0.0104339393*network','0.0132288953*video+0.0113926101*propose+0.0103314936*network'],
2:['0.0201108175*stream+0.0160505421*use+0.0143336972*compute','0.0204567699*stream+0.0159369303*use+0.0145109152*compute','0.0204072031*stream+0.0159959192*use+0.0144690685*compute'],
3:['0.0224408733*algorithm+0.0203485369*stream+0.0184875342*compute','0.0227468752*algorithm+0.0205000072*stream+0.0185545889*compute','0.0230975940*algorithm+0.0206288220*stream+0.0185272671*compute'],
4:['0.0209717427*use+0.0150956938*stream+0.0111105387*propose','0.0207826879*use+0.0151531082*stream+0.0112516701*propose','0.0203461357*use+0.0151239365*stream+0.0117703962*propose']
}
3)文档主题偏好,例如第20篇文档的主题分布为:
[1.17577895e-04,9.99529688e-01,1.17577895e-04,1.17577895e-04,1.17577895e-04]
可看出5个主题中,第20篇文档对1号主题更为偏好,依次统计出每篇文档的主题偏好并与文档元数据信息保存至表格中。
s40可视化热点单词主题聚类结果;
上一步主题动态建模分析返回的结果包括时间片序列、各个主题下每个时间片与主题最相关单词及单词对应的概率,本步骤根据分析结果中的热点单词,显示与每个主题每个年份最相关的前50个热点单词,如图4所示。
s50可视化主题中热点单词变化趋势;
如图5所示,用户选取主题中感兴趣的单词,根据主题动态建模分析返回结果的时间片序列、热点单词和对应概率信息,通过曲线图描绘热点单词在时间序列上的变化趋势。
如图6所示,用户选取主题中感兴趣的一个或多个单词,以及单词之间的关系(and、or两种),根据文献主题的偏好计算结果,查询所选主题下包含一个或多个单词关系对应的文献元数据。
主题动态建模分析获取元数据搜索请求,其中,所述元数据搜索请求中携带有搜索关键词;将所述搜索关键词与所述目标文献的检索关键词进行匹配;捕捉主题随时间的动态演变,通过动态建模得出所有文档的主题偏好,供用户通过主题下的热点单词定位文献信息曲线图的形式直观呈现主题中单词的变化趋势,当用户选取主题中感兴趣的一个或多个单词,以及单词之间的关系,找到对应的文献元数据。帮助用户了解或预测主题词的发展趋势,以及帮助用户通过主题下的热点词定位到与其相关的文献信息,方便用户对目标学科领域进行快速评估和了解。所述搜索关键词与所述目标文献的检索关键词匹配成功的情况下,返回所述目标文献的描述信息,其中,所述目标文献为与所述搜索关键词匹配的文献。
虽然本发明所揭露的实施方式如上,但所述的内容只是为了便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属技术领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式上及细节上作任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!