物体的位姿信息确定方法、装置、终端及存储介质与流程
本申请涉及智能汽车技术领域,特别涉及一种物体的位姿信息确定方法、装置及存储介质。
背景技术:
随着计算机技术的发展,汽车已经成为人们不可或缺的交通工具,且汽车越来越智能化。其中,摄像头为实现汽车智能化的重要传感器,智能汽车可以通过摄像头采集车身周围的环境信息,并通过相关处理检测周围物体信息。为了对智能汽车进行智能化控制,通常还需要确定物体的位姿信息。
目前,智能汽车能够通过弹幕视觉对物体的位姿信息进行估算,该操作包括:通过单目摄像头对汽车周围的环境进行图像采集,得到环境图像,对采集到的环境图像进行预处理后,提取预处理后的环境图像的特征点信息;然后对单目摄像头进行动态标定,通过标定结果估算物体的位姿信息,并将估算的位姿信息传输给汽车的电子控制单元,以确定汽车的驱动轨迹。
但是,由于通过上述方式对物体进行位姿信息的估算时,算法虽然较为简单,但是对位姿信息仅仅是进行估算,导致确定的位姿信息降低较差,进而导致对智能汽车的控制不够精确。
技术实现要素:
本申请提供了一种物体的位姿信息确定方法、装置及存储介质,可以解决相关技术中位姿信息确定精度差的问题。所述技术方案如下:
一方面,提供了一种物体的位姿信息确定方法,所述方法包括:
获取智能汽车所处环境的环境深度图;
通过特征点提取模型,从所述环境深度图中获取多个感兴趣区域roi特征点图;
通过位姿估计网络模型,对所述多个roi特征点图进行处理,得到目标物体的位姿信息,所述目标物体为所述环境深度图中的任一物体。
在一些实施例中,所述获取智能汽车所处环境的环境深度图,包括:
通过所述智能汽车安装的单目摄像头采集当前所处环境的环境图像;
对所述环境图像进行预处理;
将预处理后的环境图像进行深度渲染处理,得到所述环境深度图。
在一些实施例中,所述通过特征点提取模型,从所述环境深度图中获取多个感兴趣区域roi特征点图,包括:
将所述环境深度图转换为三通道图像;
通过所述特征点提取模型中的骨干网络和第一残差模块对所述三通道图像进行处理,得到多个场景特征点图;
获取参考模板的多个模板特征点图,所述多个模板特征点图为通过所述特征点提取模型中的第二残差模块对参考模板进行处理后得到,所述多个场景特征点图与所述多个模板特征点图一一对应;
将所述多个场景特征点图与所述多个模板特征点图按照对应通道进行级联,得到多个roi特征点图。
在一些实施例中,所述将所述多个场景特征点图与所述多个模板特征点图按照对应通道进行级联之前,还包括:
通过包括第一数量滤波器的卷积层对所述多个场景特征点图进行裁剪,得到多个裁剪后的场景特征点图;
通过包括第二数量滤波器的卷积层和激活函数对所述多个裁剪后的场景特征点图进行描述符提取,得到对应的多个场景描述符。
在一些实施例中,所述通过位姿估计网络模型,对所述多个roi特征点图进行处理,得到目标物体的位姿信息,包括:
对目标roi特征点图通过所述位姿估计网络模型中的特性比较网络模型分别进行mask预测处理和位姿预测处理,得到所述目标物体的多个预测mask和多个预测位姿,所述目标roi特征点图为多个roi特征点图中包括所述目标物体的特征点图;
从所述多个roi特征点图中确定针对所述目标物体的正模板特征图和负模板特征图;
根据所述目标roi特征点图,以及所述目标物体的正模板特征图、负模板特征图、多个预测mask和多个预测位姿,确定所述目标物体的位姿信息。
在一些实施例中,所述从所述多个roi特征点图中确定针对所述目标物体的正模板特征图和负模板特征图,包括:
获取所述多个roi特征点图的特征描述符;
根据所述多个roi特征点图的特征描述符,将所述多个roi特征点图进行分类,得到多类特征点图;
确定所述参考特征点图中所述目标物体与单目摄像头之间的位姿距离,所述参考特征点图为包括所述目标物体的一类特征点图中的任一特征点图;
当所述位姿距离大于距离模板时,确定所述参考特征点图为所述负模板特征图;
当所述位姿距离小于或等于距离模板时,确定所述参考特征点图为所述正模板特征图。
在一些实施例中,所述根据所述目标roi特征点图,以及所述目标物体的正模板特征图、负模板特征图、多个预测mask和多个预测位姿,确定所述目标物体的位姿信息,包括:
对所述目标roi特征点图进行均匀采样,得到目标roi区域;
根据所述目标roi区域中采样点的坐标,确定所述目标roi区域的特征向量;
根据所述目标roi区域的特征向量,确定所述目标roi区域中目标物体分别距离所述目标物体的正模板特征图和负模板特征图的特征距离;
通过特征距离最近的特征模板图,对所述目标roi区域进行mask分割,得到目标roi区域中所述目标物体的目标mask;
通过所述多个预测mask和所述多个预测位姿对所述目标mask进行匹配处理,得到所述目标物体的位姿信息。
另一方面,提供了一种物体的位姿信息确定装置,所述装置包括:
第一获取模块,用于获取智能汽车所处环境的环境深度图;
第二获取模块,用于通过特征点提取模型,从所述环境深度图中获取多个感兴趣区域roi特征点图;
处理模块,用于通过位姿估计网络模型,对所述多个roi特征点图进行处理,得到目标物体的位姿信息,所述目标物体为所述环境深度图中的任一物体。
在一些实施例中,所述第一获取模块包括:
采集子模块,用于通过所述智能汽车安装的单目摄像头采集当前所处环境的环境图像;
预处理子模块,用于对所述环境图像进行预处理;
渲染子模块,用于将预处理后的环境图像进行深度渲染处理,得到所述环境深度图。
在一些实施例中,所述第二获取模块包括:
转换子模块,用于将所述环境深度图转换为三通道图像;
第一处理子模块,用于通过所述特征点提取模型中的骨干网络和第一残差模块对所述三通道图像进行处理,得到多个场景特征点图;
获取子模块,用于获取参考模板的多个模板特征点图,所述多个模板特征点图为通过所述特征点提取模型中的第二残差模块对参考模板进行处理后得到,所述多个场景特征点图与所述多个模板特征点图一一对应;
级联子模块,用于将所述多个场景特征点图与所述多个模板特征点图按照对应通道进行级联,得到多个roi特征点图。
在一些实施例中,所述第二获取模块还包括:
裁剪子模块,用于通过包括第一数量滤波器的卷积层对所述多个场景特征点图进行裁剪,得到多个裁剪后的场景特征点图;
提取子模块,用于通过包括第二数量滤波器的卷积层和激活函数对所述多个裁剪后的场景特征点图进行描述符提取,得到对应的多个场景描述符。
在一些实施例中,所述处理模块包括:
第二处理子模块,用于对目标roi特征点图通过所述位姿估计网络模型中的特性比较网络模型分别进行mask预测处理和位姿预测处理,得到所述目标物体的多个预测mask和多个预测位姿,所述目标roi特征点图为多个roi特征点图中包括所述目标物体的特征点图;
第一确定子模块,用于从所述多个roi特征点图中确定针对所述目标物体的正模板特征图和负模板特征图;
第二确定子模块,用于根据所述目标roi特征点图,以及所述目标物体的正模板特征图、负模板特征图、多个预测mask和多个预测位姿,确定所述目标物体的位姿信息。
在一些实施例中,所述第一确定子模块用于:
获取所述多个roi特征点图的特征描述符;
根据所述多个roi特征点图的特征描述符,将所述多个roi特征点图进行分类,得到多类特征点图;
确定所述参考特征点图中所述目标物体与单目摄像头之间的位姿距离,所述参考特征点图为包括所述目标物体的一类特征点图中的任一特征点图;
当所述位姿距离大于距离模板时,确定所述参考特征点图为所述负模板特征图;
当所述位姿距离小于或等于距离模板时,确定所述参考特征点图为所述正模板特征图。
在一些实施例中,所述第二确定子模块用于:
对所述目标roi特征点图进行均匀采样,得到目标roi区域;
根据所述目标roi区域中采样点的坐标,确定所述目标roi区域的特征向量;
根据所述目标roi区域的特征向量,确定所述目标roi区域中目标物体分别距离所述目标物体的正模板特征图和负模板特征图的特征距离;
通过特征距离最近的特征模板图,对所述目标roi区域进行mask分割,得到目标roi区域中所述目标物体的目标mask;
通过所述多个预测mask和所述多个预测位姿对所述目标mask进行匹配处理,得到所述目标物体的位姿信息。
另一方面,提供了一种智能汽车,所述智能汽车包括存储器和处理器,所述存储器用于存放计算机程序,所述处理器用于执行所述存储器上所存放的计算机程序,以实现上述所述的物体的位姿信息确定方法的步骤。
另一方面,提供了一种计算机可读存储介质,所述存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现上述所述物体的位姿信息确定方法的步骤。
另一方面,提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述所述的物体的位姿信息确定方法的步骤。
本申请提供的技术方案至少可以带来以下有益效果:
在本申请中,能够获取当前所处环境的深度图,并通过特征点提取模型和位姿估计网络模型对环境深度图进行处理,即可确定目标物体的位姿信息,无需将当前所处场景的背景与物体进行分割,降低了位姿信息确定的复杂度,提高了位姿信息确定的精确度。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本申请实施例提供的一种物体的位姿信息确定方法的流程图;
图2是本申请实施例提供的另一种物体的位姿信息确定方法的流程图;
图3是本申请实施例提供的一种物体的位姿信息确定装置的结构示意图;
图4是本申请实施例提供的一种第一获取模块的结构示意图;
图5是本申请实施例提供的一种第二获取模块的结构示意图;
图6是本申请实施例提供的另一种第二获取模块的结构示意图;
图7是本申请实施例提供的一种处理模块的结构示意图;
图8是本申请实施例提供的一种智能汽车的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。
在对本申请实施例提供的物体的位姿信息确定方法进行详细的解释说明之前,先对本申请实施例提供的应用场景进行介绍。
随着人工智能技术的发展,智能驾驶汽车也随之较为普及,在智能驾驶汽车的应用领域摄像头是一个广为应用的传感器。例如在全景影响系统中,使用四个摄像头能够采集车身周围的环境信息,通过特征提取和语义分割等技术,应用卷积神经网络cnn、深度神经网络dnn等方法,可以由视觉系统检测周围物体信息,例如检测车身周围的车辆、立柱、路墩、行人等。在aeb(autonomousemergencybraking,自动紧急刹车)功能中,摄像头在一定的fov视场角内采集道路车辆或者行人的信息,以便在适当的时机给用户提示报警或者自主刹停车辆,确保车辆行驶的安全性能。为了提供对物体位姿的检测,通常是摄像头和毫米波雷达结合的方法,但是,通过摄像头和毫米波雷达结合的方式进行位姿信息的估算时,仅仅是进行估算,导致确定的位姿信息降低较差,进而导致对智能汽车的控制不够精确。
就这样的应用场景,本申请实施例提供了一种能够提高确定位姿信息的准确性的物体的位姿信息确定方法。
接下来将结合附图对本申请实施例提供的物体的位姿信息确定方法进行详细的解释说明。
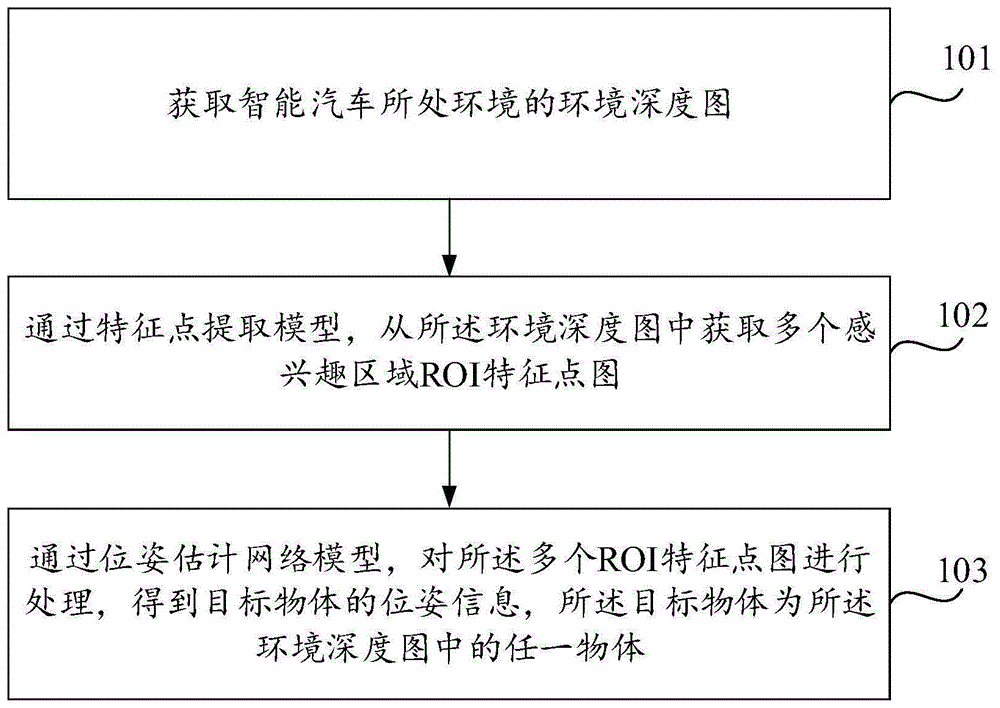
图1是本申请实施例提供的一种物体的位姿信息确定方法的流程图,该方法应用于智能汽车中。请参考图1,该方法包括如下步骤。
步骤101:获取智能汽车所处环境的环境深度图。
步骤102:通过特征点提取模型,从所述环境深度图中获取多个感兴趣区域roi特征点图。
步骤103:通过位姿估计网络模型,对所述多个roi特征点图进行处理,得到目标物体的位姿信息,所述目标物体为所述环境深度图中的任一物体。
在本申请中,能够获取当前所处环境的深度图,并通过特征点提取模型和位姿估计网络模型对环境深度图进行处理,即可确定目标物体的位姿信息,无需将当前所处场景的背景与物体进行分割,降低了位姿信息确定的复杂度,提高了位姿信息确定的精确度。
在一些实施例中,获取智能汽车所处环境的环境深度图,包括:
通过所述智能汽车安装的单目摄像头采集当前所处环境的环境图像;
对所述环境图像进行预处理;
将预处理后的环境图像进行深度渲染处理,得到所述环境深度图。
在一些实施例中,通过特征点提取模型,从所述环境深度图中获取多个感兴趣区域roi特征点图,包括:
将所述环境深度图转换为三通道图像;
通过所述特征点提取模型中的骨干网络和第一残差模块对所述三通道图像进行处理,得到多个场景特征点图;
获取参考模板的多个模板特征点图,所述多个模板特征点图为通过所述特征点提取模型中的第二残差模块对参考模板进行处理后得到,所述多个场景特征点图与所述多个模板特征点图一一对应;
将所述多个场景特征点图与所述多个模板特征点图按照对应通道进行级联,得到多个roi特征点图。
在一些实施例中,将所述多个场景特征点图与所述多个模板特征点图按照对应通道进行级联之前,还包括:
通过包括第一数量滤波器的卷积层对所述多个场景特征点图进行裁剪,得到多个裁剪后的场景特征点图;
通过包括第二数量滤波器的卷积层和激活函数对所述多个裁剪后的场景特征点图进行描述符提取,得到对应的多个场景描述符。
在一些实施例中,通过位姿估计网络模型,对所述多个roi特征点图进行处理,得到目标物体的位姿信息,包括:
对目标roi特征点图通过所述位姿估计网络模型中的特性比较网络模型分别进行mask预测处理和位姿预测处理,得到所述目标物体的多个预测mask和多个预测位姿,所述目标roi特征点图为多个roi特征点图中包括所述目标物体的特征点图;
从所述多个roi特征点图中确定针对所述目标物体的正模板特征图和负模板特征图;
根据所述目标roi特征点图,以及所述目标物体的正模板特征图、负模板特征图、多个预测mask和多个预测位姿,确定所述目标物体的位姿信息。
在一些实施例中,从所述多个roi特征点图中确定针对所述目标物体的正模板特征图和负模板特征图,包括:
获取所述多个roi特征点图的特征描述符;
根据所述多个roi特征点图的特征描述符,将所述多个roi特征点图进行分类,得到多类特征点图;
确定所述参考特征点图中所述目标物体与单目摄像头之间的位姿距离,所述参考特征点图为包括所述目标物体的一类特征点图中的任一特征点图;
当所述位姿距离大于距离模板时,确定所述参考特征点图为所述负模板特征图;
当所述位姿距离小于或等于距离模板时,确定所述参考特征点图为所述正模板特征图。
在一些实施例中,根据所述目标roi特征点图,以及所述目标物体的正模板特征图、负模板特征图、多个预测mask和多个预测位姿,确定所述目标物体的位姿信息,包括:
对所述目标roi特征点图进行均匀采样,得到目标roi区域;
根据所述目标roi区域中采样点的坐标,确定所述目标roi区域的特征向量;
根据所述目标roi区域的特征向量,确定所述目标roi区域中目标物体分别距离所述目标物体的正模板特征图和负模板特征图的特征距离;
通过特征距离最近的特征模板图,对所述目标roi区域进行mask分割,得到目标roi区域中所述目标物体的目标mask;
通过所述多个预测mask和所述多个预测位姿对所述目标mask进行匹配处理,得到所述目标物体的位姿信息。
上述所有可选技术方案,均可按照任意结合形成本申请的可选实施例,本申请实施例对此不再一一赘述。
图2为本申请实施例提供的一种物体的位姿信息确定方法的流程图,参见图2,该方法包括如下步骤。
步骤201:智能汽车获取所处环境的环境深度图。
由于深度图像是指将从图像采集器到场景中各点的距离作为像素值的图像,能够直接反映景物可见表面的几何形状。因此,为了确定物体的位姿信息,智能汽车能够获取所处环境的环境深度图。
作为一种示例,智能汽车获取所处环境的环境深度图的操作至少包括:通过智能汽车安装的单目摄像头采集当前所处环境的环境图像;对环境图像进行预处理;将预处理后的环境图像进行深度渲染处理,得到该环境深度图。
作为一种示例,智能汽车能够对环境图像进行滤波、平滑等预处理,然后对预处理后的环境图像进行多维度训练,加强深度图谱分析,渲染噪声深度图,从而得到环境深度图。
需要说明的是,智能汽车的单目摄像头采集到当前所处环境的环境图像后,能够将该环境图像发送至ecu(electroniccontrolunit,电子控制单元),智能汽车的ecu能够对对环境图像进行预处理,并将预处理后的环境图像进行深度渲染处理,得到该环境深度图
在一些实施例中,智能汽车能够在实现自动驾驶、自动泊车等功能时,获取所处环境的环境深度图。
步骤202:智能汽车通过特征点提取模型,从环境深度图中获取多个感兴趣区域roi特征点图。
作为一种示例,智能汽车通过特征点提取模型,从环境深度图中获取多个roi(regionofinterest,感兴趣区域)特征点图的操作至少包括:将环境深度图转换为三通道图像;通过特征点提取模型中的骨干网络和第一残差模块对三通道图像进行处理,得到多个场景特征点图;获取参考模板的多个模板特征点图,该多个模板特征点图为通过特征点提取模型中的第二残差模块对参考模板进行处理后得到,该多个场景特征点图与该多个模板特征点图一一对应;将该多个场景特征点图与多个模板特征点图按照对应通道进行级联,得到多个roi特征点图。
由于环境深度图为单通道图像,而进行特征点提取时,通常使用rgb或者rccb等三通道彩色图像作为原始输入数据,因此,需要将深度图像转换为三通道图像作为输入。
需要说明的是,特征点提取模型为事先设置的用于提取特征点的模型,且该特征点提取模型中能够使用imagenet函数训练的权重进行数据初始化。
还需要说明的是,第一残差模块和第二残差模块的结构相同,且在本申请实施例中能够通过第二残差模块事先训练参考模板,得到多个模板特征点图。
在一些实施例中,为了降低复杂度,通常还可以对多个场景特征点图进行降维处理。也即是,智能汽车在将多个场景特征点图与多个模板特征点图按照对应通道进行级联之前,还能够通过包括第一数量滤波器的卷积层对多个场景特征点图进行裁剪,得到多个裁剪后的场景特征点图;通过包括第二数量滤波器的卷积层和激活函数对该多个裁剪后的场景特征点图进行描述符提取,得到对应的多个场景描述符。
同理,为了使多个模板特征点图与多个场景特征点图实现一一对应关系,智能汽车能够事先通过包括第一数量滤波器的卷积层对多个模板特征点图进行裁剪,得到多个裁剪后的模板特征点图,并通过包括第二数量滤波器的卷积层和激活函数对该多个裁剪后的模板特征点图进行描述符提取,得到对应的多个模板描述符。
需要说明的是,该第一数量和第二数量均能够通过需求事先设置,比如,该第一数量为256,第二数量为256等等。也即是,在本申请实施例中,能够通过附加的具有256个滤波器的3*3卷积层减小特征点图的尺寸。该激活函数能够为elu函数,该elu函数包括sigmoid函数和relu函数。
在一些实施例中,通过256个滤波器的3x3卷积层对多个场景特征点图进行裁剪,得到多个裁剪后的场景特征点图的操作是指针对该任一场景特征点图,该场景特征点图对应像素与卷积滤波之和。也即是,首先对该场景特征点图的边缘进行填充,比如,填充数据0;然后将卷积滤波器划过整幅场景特征点图,并确定该场景特征点图中每个像素点的滤波结果,每个滤波器会滑动卷积上一层的特征点图,得到该场景特征点图对应的裁剪后的场景特征点图。
需要说明的是,由于多个场景特征点图和多个模板特征点图均能够通过256个滤波器的3*3卷积层进行处理,因此,将该多个场景特征点图与多个模板特征点图按照对应通道进行级联,得到多个roi特征点图后,该多个roi特征点图中每个roi特征点图输出的维度为14*14*512。
步骤203:智能汽车通过位姿估计网络模型,对多个roi特征点图进行处理,得到目标物体的位姿信息,该目标物体为环境深度图中的任一物体。
需要说明的是,该位姿估计网络模型用于确定物体的位姿信息。
作为一种示例,智能汽车通过位姿估计网络模型,对多个roi特征点图进行处理,得到目标物体的位姿信息的操作至少包括:对目标roi特征点图通过位姿估计网络模型中的特性比较网络模型分别进行mask预测处理和位姿预测处理,得到目标物体的多个预测mask和多个预测位姿,该目标roi特征点图为多个roi特征点图中包括该目标物体的特征点图;从该多个roi特征点图中确定针对目标物体的正模板特征图和负模板特征图;根据目标roi特征点图,以及该目标物体的正模板特征图、负模板特征图、多个预测mask和多个预测位姿,确定该目标物体的位姿信息。
在一些实施例中,智能汽车能够通过包括第三数量滤波器的卷积层和一个包括elu函数中的sigmoid函数的单通道输出1*1卷积层来表示预测mask。通过特性比较网络模型中的全连接层的最后一个层使用双曲线正切作为激活函数,得到预测位姿,该预测位姿为四元数据的位姿差信息。
作为一种示例,智能汽车从多个roi特征点图中确定针对目标物体的正模板特征图和负模板特征图的操作至少包括:获取多个roi特征点图的特征描述符;根据多个roi特征点图的特征描述符,将多个roi特征点图进行分类,得到多类特征点图;确定参考特征点图中目标物体与单目摄像头之间的位姿距离,该参考特征点图为包括目标物体的一类特征点图中的任一特征点图;当位姿距离大于距离模板时,确定参考特征点图为负模板特征图;当位姿距离小于或等于距离模板时,确定参考特征点图为正模板特征图。
由上述可知,智能汽车能够通过包括第二数量滤波器的卷积层和激活函数对该多个裁剪后的模板特征点图进行描述符提取,得到对应的多个模板描述符,并通过包括第二数量滤波器的卷积层和激活函数对该多个裁剪后的模板特征点图进行描述符提取,得到对应的多个模板描述符,且对个roi特征点图是多个场景特征点图与多个模板特征点图按照对应通道进行级联得到,因此,可以将该多个场景描述符或多个模板描述符确定为多个roi特征点图的特征描述符。
由于特征描述符用于描述对应的roi特征点图中物品的属性,因此,能够通过特征描述符将多个roi特征点图进行分类,得到多类特征点图。
需要说明的是,智能汽车不仅能够通过位姿距离获取负模板特征图,也可以将特征描述符与目标物体不同类的roi特征点图确定为负模板特征图。也即是,负模板特征图能够有一半来自同类别的roi特征点图,一半来自不同类别的roi特征点图。另外,正模板特征图能够从同一类roi特征点图中相似度最高的n个模板中确定得到。
作为一种示例,智能汽车根据目标roi特征点图,以及目标物体的正模板特征图、负模板特征图、多个预测mask和多个预测位姿,确定目标物体的位姿信息的操作至少包括:对目标roi特征点图进行均匀采样,得到目标roi区域;根据目标roi区域中采样点的坐标,确定目标roi区域的特征向量;根据目标roi区域的特征向量,确定目标roi区域中目标物体分别距离目标物体的正模板特征图和负模板特征图的特征距离;通过特征距离最近的特征模板图,对目标roi区域进行mask分割,得到目标roi区域中目标物体的目标mask;通过多个预测mask和多个预测位姿对目标mask进行匹配处理,得到目标物体的位姿信息。
作为一种示例,智能汽车能够通过kd-tree搜索在流形学习中映射的欧式空间中找到近邻的正模板特征图和负模板特征图,并确定特征距离。
在一些实施例中,为了降低复杂度,智能汽车能够事先消除冗余的预测mask。也即是,智能汽车能够采用非极大值抑制算法将多个预测mask中重叠的预测mask进行合并。
在本申请实施例中,智能汽车能够获取当前所处环境的深度图,并通过特征点提取模型和位姿估计网络模型对环境深度图进行处理,即可确定目标物体的位姿信息,也即是,通过事先设置的模板进行近邻匹配,使用特征点图来预测mask和与预测位姿,无需将当前所处场景的背景与物体进行分割,降低了位姿信息确定的复杂度,提高了位姿信息确定的精确度。
在对本申请实施例提供的物体的位姿信息确定方法进行解释说明之后,接下来,对本申请实施例提供的物体的位姿信息确定装置进行介绍。
图3是本申请实施例提供的一种物体的位姿信息确定装置的结构示意图,该物体的位姿信息确定装置可以由软件、硬件或者两者的结合实现成为智能汽车的部分或者全部。请参考图3,该装置包括:第一获取模块301、第二获取模块302和处理模块303。
第一获取模块301,用于获取智能汽车所处环境的环境深度图;
第二获取模块302,用于通过特征点提取模型,从所述环境深度图中获取多个感兴趣区域roi特征点图;
处理模块303,用于通过位姿估计网络模型,对所述多个roi特征点图进行处理,得到目标物体的位姿信息,所述目标物体为所述环境深度图中的任一物体。
在一些实施例中,参见图4,所述第一获取模块301包括:
采集子模块3011,用于通过所述智能汽车安装的单目摄像头采集当前所处环境的环境图像;
预处理子模块3012,用于对所述环境图像进行预处理;
渲染子模块3013,用于将预处理后的环境图像进行深度渲染处理,得到所述环境深度图。
在一些实施例中,参见图5,所述第二获取模块302包括:
转换子模块3021,用于将所述环境深度图转换为三通道图像;
第一处理子模块3022,用于通过所述特征点提取模型中的骨干网络和第一残差模块对所述三通道图像进行处理,得到多个场景特征点图;
获取子模块3023,用于获取参考模板的多个模板特征点图,所述多个模板特征点图为通过所述特征点提取模型中的第二残差模块对参考模板进行处理后得到,所述多个场景特征点图与所述多个模板特征点图一一对应;
级联子模块3024,用于将所述多个场景特征点图与所述多个模板特征点图按照对应通道进行级联,得到多个roi特征点图。
在一些实施例中,参见图6,所述第二获取模块302还包括:
裁剪子模块3025,用于通过包括第一数量滤波器的卷积层对所述多个场景特征点图进行裁剪,得到多个裁剪后的场景特征点图;
提取子模块3026,用于通过包括第二数量滤波器的卷积层和激活函数对所述多个裁剪后的场景特征点图进行描述符提取,得到对应的多个场景描述符。
在一些实施例中,参见图7,所述处理模块303包括:
第二处理子模块3031,用于对目标roi特征点图通过所述位姿估计网络模型中的特性比较网络模型分别进行mask预测处理和位姿预测处理,得到所述目标物体的多个预测mask和多个预测位姿,所述目标roi特征点图为多个roi特征点图中包括所述目标物体的特征点图;
第一确定子模块3032,用于从所述多个roi特征点图中确定针对所述目标物体的正模板特征图和负模板特征图;
第二确定子模块3033,用于根据所述目标roi特征点图,以及所述目标物体的正模板特征图、负模板特征图、多个预测mask和多个预测位姿,确定所述目标物体的位姿信息。
在一些实施例中,所述第一确定子模块3032用于:
获取所述多个roi特征点图的特征描述符;
根据所述多个roi特征点图的特征描述符,将所述多个roi特征点图进行分类,得到多类特征点图;
确定所述参考特征点图中所述目标物体与单目摄像头之间的位姿距离,所述参考特征点图为包括所述目标物体的一类特征点图中的任一特征点图;
当所述位姿距离大于距离模板时,确定所述参考特征点图为所述负模板特征图;
当所述位姿距离小于或等于距离模板时,确定所述参考特征点图为所述正模板特征图。
在一些实施例中,所述第二确定子模块3033用于:
对所述目标roi特征点图进行均匀采样,得到目标roi区域;
根据所述目标roi区域中采样点的坐标,确定所述目标roi区域的特征向量;
根据所述目标roi区域的特征向量,确定所述目标roi区域中目标物体分别距离所述目标物体的正模板特征图和负模板特征图的特征距离;
通过特征距离最近的特征模板图,对所述目标roi区域进行mask分割,得到目标roi区域中所述目标物体的目标mask;
通过所述多个预测mask和所述多个预测位姿对所述目标mask进行匹配处理,得到所述目标物体的位姿信息。
在本申请实施例中,智能汽车能够获取当前所处环境的深度图,并通过特征点提取模型和位姿估计网络模型对环境深度图进行处理,即可确定目标物体的位姿信息,也即是,通过事先设置的模板进行近邻匹配,使用特征点图来预测mask和与预测位姿,无需将当前所处场景的背景与物体进行分割,降低了位姿信息确定的复杂度,提高了位姿信息确定的精确度。
需要说明的是:上述实施例提供的物体的位姿信息确定装置在确定物体的位姿信息时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的物体的位姿信息确定装置与物体的位姿信息确定方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
图8是本申请实施例提供的一种智能汽车800的结构框图。通常,智能汽车800包括有:处理器801和存储器802。
处理器801可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器801可以采用dsp(digitalsignalprocessing,数字信号处理)、fpga(field-programmablegatearray,现场可编程门阵列)、pla(programmablelogicarray,可编程逻辑阵列)中的至少一种硬件形式来实现。处理器801也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称cpu(centralprocessingunit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。在一些实施例中,处理器801可以在集成有gpu(graphicsprocessingunit,图像处理器),gpu用于负责显示屏所需要显示的内容的渲染和绘制。一些实施例中,处理器801还可以包括ai(artificialintelligence,人工智能)处理器,该ai处理器用于处理有关机器学习的计算操作。
存储器802可以包括一个或多个计算机可读存储介质,该计算机可读存储介质可以是非暂态的。存储器802还可包括高速随机存取存储器,以及非易失性存储器,比如一个或多个磁盘存储设备、闪存存储设备。在一些实施例中,存储器802中的非暂态的计算机可读存储介质用于存储至少一个指令,该至少一个指令用于被处理器801所执行以实现本申请中方法实施例提供的物体的位姿信息确定方法。
在一些实施例中,智能汽车800还可选包括有:外围设备接口803和至少一个外围设备。处理器801、存储器802和外围设备接口803之间可以通过总线或信号线相连。各个外围设备可以通过总线、信号线或电路板与外围设备接口803相连。具体地,外围设备包括:射频电路804、显示屏805、摄像头组件806、音频电路807、定位组件808和电源809中的至少一种。
外围设备接口803可被用于将i/o(input/output,输入/输出)相关的至少一个外围设备连接到处理器801和存储器802。在一些实施例中,处理器801、存储器802和外围设备接口803被集成在同一芯片或电路板上;在一些其他实施例中,处理器801、存储器802和外围设备接口803中的任意一个或两个可以在单独的芯片或电路板上实现,本实施例对此不加以限定。
射频电路804用于接收和发射rf(radiofrequency,射频)信号,也称电磁信号。射频电路804通过电磁信号与通信网络以及其他通信设备进行通信。射频电路804将电信号转换为电磁信号进行发送,或者,将接收到的电磁信号转换为电信号。可选地,射频电路804包括:天线系统、rf收发器、一个或多个放大器、调谐器、振荡器、数字信号处理器、编解码芯片组、用户身份模块卡等等。射频电路804可以通过至少一种无线通信协议来与其它终端进行通信。该无线通信协议包括但不限于:万维网、城域网、内联网、各代移动通信网络(2g、3g、4g及5g)、无线局域网和/或wifi(wirelessfidelity,无线保真)网络。在一些实施例中,射频电路804还可以包括nfc(nearfieldcommunication,近距离无线通信)有关的电路,本申请对此不加以限定。
显示屏805用于显示ui(userinterface,用户界面)。该ui可以包括图形、文本、图标、视频及其它们的任意组合。当显示屏805是触摸显示屏时,显示屏805还具有采集在显示屏805的表面或表面上方的触摸信号的能力。该触摸信号可以作为控制信号输入至处理器801进行处理。此时,显示屏805还可以用于提供虚拟按钮和/或虚拟键盘,也称软按钮和/或软键盘。在一些实施例中,显示屏805可以为一个,设置智能汽车800的前面板;在另一些实施例中,显示屏805可以为至少两个,分别设置在智能汽车800的不同表面或呈折叠设计;在再一些实施例中,显示屏805可以是柔性显示屏,设置在智能汽车800的弯曲表面上或折叠面上。甚至,显示屏805还可以设置成非矩形的不规则图形,也即异形屏。显示屏805可以采用lcd(liquidcrystaldisplay,液晶显示屏)、oled(organiclight-emittingdiode,有机发光二极管)等材质制备。
摄像头组件806用于采集图像或视频。可选地,摄像头组件806包括主摄像头、景深摄像头、广角摄像头、长焦摄像头中的任意一种,以实现主摄像头和景深摄像头融合实现背景虚化功能、主摄像头和广角摄像头融合实现全景拍摄以及vr(virtualreality,虚拟现实)拍摄功能或者其它融合拍摄功能。在一些实施例中,摄像头组件806还可以包括闪光灯。闪光灯可以是单色温闪光灯,也可以是双色温闪光灯。双色温闪光灯是指暖光闪光灯和冷光闪光灯的组合,可以用于不同色温下的光线补偿。
音频电路807可以包括麦克风和扬声器。麦克风用于采集用户及环境的声波,并将声波转换为电信号输入至处理器801进行处理,或者输入至射频电路804以实现语音通信。出于立体声采集或降噪的目的,麦克风可以为多个,分别设置在智能汽车800的不同部位。麦克风还可以是阵列麦克风或全向采集型麦克风。扬声器则用于将来自处理器801或射频电路804的电信号转换为声波。扬声器可以是传统的薄膜扬声器,也可以是压电陶瓷扬声器。当扬声器是压电陶瓷扬声器时,不仅可以将电信号转换为人类可听见的声波,也可以将电信号转换为人类听不见的声波以进行测距等用途。在一些实施例中,音频电路807还可以包括耳机插孔。
定位组件808用于定位智能汽车800的当前地理位置,以实现导航或lbs(locationbasedservice,基于位置的服务)。定位组件808可以是基于美国的gps(globalpositioningsystem,全球定位系统)、中国的北斗系统或俄罗斯的伽利略系统的定位组件。
电源809用于为智能汽车800中的各个组件进行供电。电源809可以是交流电、直流电、一次性电池或可充电电池。当电源809包括可充电电池时,该可充电电池可以是有线充电电池或无线充电电池。有线充电电池是通过有线线路充电的电池,无线充电电池是通过无线线圈充电的电池。该可充电电池还可以用于支持快充技术。
在一些实施例中,智能汽车800还包括有一个或多个传感器810。
本领域技术人员可以理解,图8中示出的结构并不构成对智能汽车800的限定,可以包括比图示更多或更少的组件,或者组合某些组件,或者采用不同的组件布置。
在一些实施例中,还提供了一种计算机可读存储介质,该存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现上述实施例中物体的位姿信息确定方法的步骤。例如,所述计算机可读存储介质可以是rom(read-onlymemory,只读存储器)、ram(randomaccessmemory,随机存取存储器)、cd-rom、磁带、软盘和光数据存储设备等。
值得注意的是,本申请提到的计算机可读存储介质可以为非易失性存储介质,换句话说,可以是非瞬时性存储介质。
应当理解的是,实现上述实施例的全部或部分步骤可以通过软件、硬件、固件或者其任意结合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。所述计算机指令可以存储在上述计算机可读存储介质中。
也即是,在一些实施例中,还提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述所述的物体的位姿信息确定方法的步骤。
以上所述为本申请提供的实施例,并不用以限制本申请,凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!