前端代码生成模型的生成方法和装置与流程
本申请实施例涉及计算机技术领域,具体涉及前端代码生成模型的生成方法和装置。
背景技术:
大多数面向用户的现代软件应用程序都是以图形用户界面(graphicaluserinterface,gui)为中心的,依赖有吸引力的用户界面(ui)和直观的用户体验(ux)来吸引客户,促进计算任务的有效完成,并吸引用户。
目前,深度学习成为近年来的研究热门。且越来越多的研究改变了大众日常生活,如:人脸识别,指纹解锁,推荐系统等等。在这诸多应用中,代码自动生成领域亦有不少成果,利用深度学习将gui转为编程代码的方法已由涉及。这个问题类似于图像描述(imagecaption),借由图像描述中相关的研究,设计一个模型,可以将gui直接转换为编程代码,是一个十分有意义的方向。
现有的用于训练代码生成模型的数据集存在数据量少,且数据集界面相对简单的问题,由此训练得到的模型往往难以应对实际界面的复杂情形。
现有方法主要采用encoder-deocder框架,使用卷积神经网络的输出特征图作为图像的语义编码,输入到递归循环网络中生成描述,但一般的卷积神经网络往往难以捕捉图像的细节如颜色、位置等。且由于中间语义向量的的长度限制,框架往往难以处理长序列的情况,一般的decoder仅使用循环神经网络作为解码器,在生成不同代码的时候关注的信息都是一致的,这也不符合代码生成的特性。
技术实现要素:
本申请实施例的目的在于提出了一种改进的前端代码生成模型的生成方法和装置,来解决以上背景技术部分提到的技术问题。
第一方面,本申请实施例提供了一种前端代码生成模型的生成方法,该方法包括:获取训练样本集合,其中,训练样本包括样本界面图像和样本前端代码;获取初始模型,其中,初始模型包括编码器和解码器,编码器包括视觉模型和语言模型;将样本界面图像输入视觉模型,得到图像特征;确定输入的样本界面图像对应的代码字符串序列,并将代码字符串序列输入语言模型的词嵌入层,得到词向量,以及将词向量输入语言模型的特征提取层,得到代码字符串序列的文本特征;将图像特征和文本特征作为解码器的输入,将与输入的样本界面图像对应的样本前端代码作为期望输出,训练初始模型,得到前端代码生成模型。
在一些实施例中,将图像特征和文本特征作为解码器的输入,包括:将图像特征和文本特征进行合并,得到合并特征;将合并特征作为解码器的输入。
在一些实施例中,解码器采用注意力机制进行解码,得到前端代码包括的代码字符串。
在一些实施例中,视觉模型采用包括se-net的卷积神经网络确定图像特征。
在一些实施例中,卷积神经网络采用卷积核大于等于2*2,且步长大于1的卷积层替代池化层。
在一些实施例中,语言模型和解码器采用gru网络进行编码和解码。
在一些实施例中,解码器采用beamsearch算法预测前端代码包括的代码字符串。
在一些实施例中,获取训练样本集合,包括:基于预设的元素种类和每个元素种类包括的元素样式,生成至少两个元素数据集合,其中,至少两个元素数据集合中的每个元素数据集合对应于一个元素种类;从至少两个元素数据集合中提取元素数据进行组合,得到样本前端代码;基于样本前端代码,生成样本界面图像。
第二方面,本申请实施例提供了一种前端代码生成方法,该方法包括:获取目标界面图像和初始代码字符串序列;执行如下预测步骤:将目标界面图像和初始代码字符串序列输入预先训练的前端代码生成模型,得到位于代码字符串序列之后的代码字符串;将所得到的代码字符串添加进初始代码字符串序列之后;确定所得到的代码字符串是否为结束标记;如果是,基于模型输出的代码字符串,生成目标界面图像的前端代码;如果确定所得到的代码字符串不是结束标记,基于最近一次添加代码字符串后的初始代码字符串序列,继续执行预测步骤。
第三方面,本申请实施例提供了一种前端代码生成模型的生成装置,该装置包括:第一获取模块,用于获取训练样本集合,其中,训练样本包括样本界面图像和样本前端代码;第二获取模块,用于获取初始模型,其中,初始模型包括编码器和解码器,编码器包括视觉模型和语言模型;第一生成模块,用于将样本界面图像输入视觉模型,得到图像特征;第二生成模块,用于确定输入的样本界面图像对应的代码字符串序列,并将代码字符串序列输入语言模型的词嵌入层,得到词向量,以及将词向量输入语言模型的特征提取层,得到代码字符串序列的文本特征;训练模块,用于将图像特征和文本特征作为解码器的输入,将与输入的样本界面图像对应的样本前端代码作为期望输出,训练初始模型,得到前端代码生成模型。
第四方面,本申请实施例提供了一种前端代码生成装置,该装置包括:第三获取模块,用于获取目标界面图像和初始代码字符串序列;预测模块,用于执行如下预测步骤:将目标界面图像和初始代码字符串序列输入预先训练的前端代码生成模型,得到位于代码字符串序列之后的代码字符串;将所得到的代码字符串添加进初始代码字符串序列之后;确定所得到的代码字符串是否为结束标记;如果是,基于模型输出的代码字符串,生成目标界面图像的前端代码;确定模块,用于如果确定所得到的代码字符串不是结束标记,基于最近一次添加代码字符串后的初始代码字符串序列,继续执行预测步骤。
第五方面,本申请实施例提供了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现如第一方面或第二方面中任一实现方式描述的方法。
第六方面,本申请实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第一方面或第二方面中任一实现方式描述的方法。
本申请实施例提供的前端代码生成模型的生成方法和装置、前端代码生成方法和装置,通过将词嵌入层引入编码器中的语言模型,可以更好地挖掘出代码中的文字之间的关联,使利用语言模型得到文本特征的准确性更高,从而进一步使训练得到的前端代码生成模型生成的前端代码的准确性更高。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本申请的其它特征、目的和优点将会变得更明显:
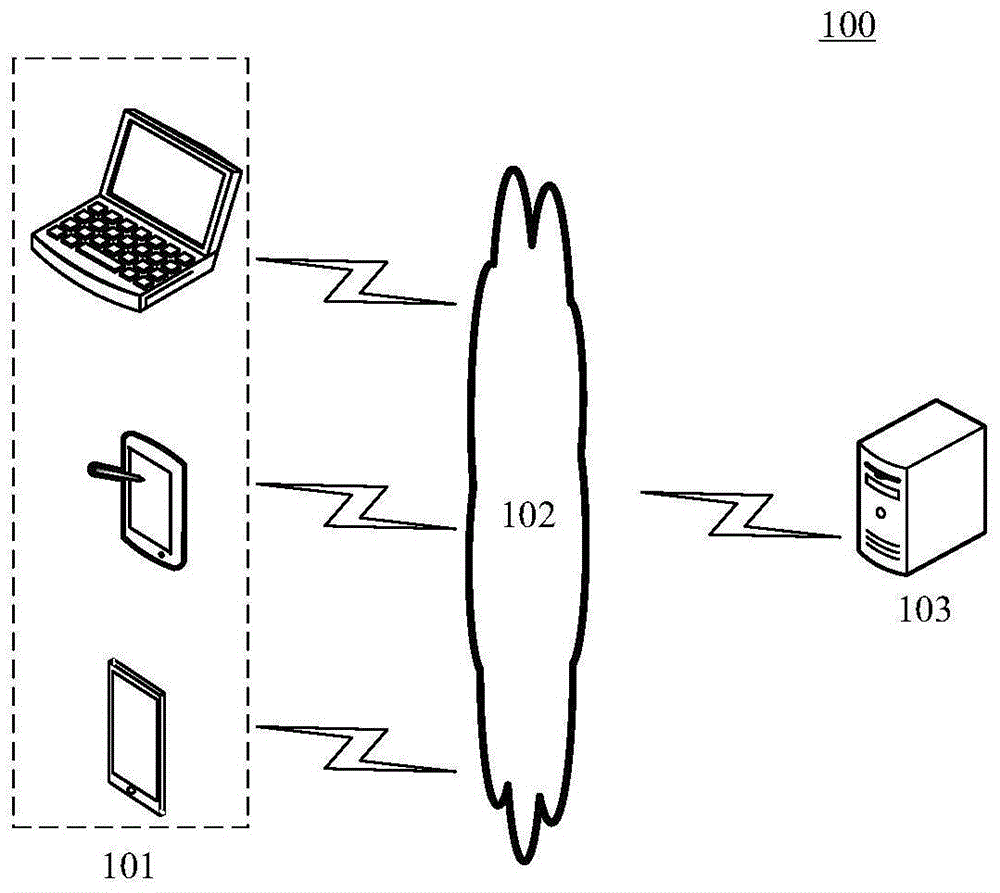
图1是本申请可以应用于其中的示例性系统架构图;
图2是根据本申请的前端代码生成模型的生成方法的一个实施例的流程图;
图3是根据本申请的前端代码生成模型的生成方法的生成合并特征的示例性示意图;
图4是根据本申请的前端代码生成模型的生成方法的se-net的示意图;
图5是根据本申请的前端代码生成模型的生成方法的又一个实施例的流程图;
图6是根据本申请的生成样本前端代码的一个示例性流程图;
图7是根据本申请的前端代码生成方法的一个实施例的流程图;
图8是根据本申请的前端代码生成模型的生成装置的一个实施例的结构示意图;
图9是根据本申请的前端代码生成装置的一个实施例的结构示意图;
图10是适于用来实现本申请实施例的电子设备的计算机系统的结构示意图。
具体实施方式
下面结合附图和实施例对本申请作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
图1示出了可以应用本申请实施例的前端代码生成模型的生成方法的示例性系统架构100。
如图1所示,系统架构100可以包括终端设备101,网络102和服务器103。网络102用以在终端设备101和服务器103之间提供通信链路的介质。网络102可以包括各种连接类型,例如有线、无线通信链路或者光纤电缆等等。
用户可以使用终端设备101通过网络102与服务器103交互,以接收或发送消息等。终端设备101上可以安装有各种通讯客户端应用,例如网页浏览器应用、搜索类应用、购物类应用、即时通信工具等。
终端设备101可以是各种电子设备,包括但不限于诸如移动电话、笔记本电脑、数字广播接收器、pda(个人数字助理)、pad(平板电脑)、pmp(便携式多媒体播放器)、车载终端(例如车载导航终端)等等的移动终端以及诸如数字tv、台式计算机等等的固定终端。
服务器103可以是提供各种服务的服务器,例如对终端设备101上显示的用户界面提供支持的后台服务器。后台服务器可以利用训练样本集合训练得到前端代码生成模型,或者接收终端设备101上传的界面图像,生成前端代码。
需要说明的是,本申请实施例所提供的前端代码生成模型的生成方法可以由终端设备101或服务器103执行,相应地,前端代码生成模型的生成装置可以设置于终端设备101或服务器103中。
应该理解,图1中的数据服务器、网络和主服务器的数目仅仅是示意性的。根据实现需要,可以具有任意数目的终端设备、网络和服务器。
继续参考图2,其示出了根据本申请的前端代码生成模型的生成方法的一个实施例的流程200。该方法包括以下步骤:
步骤201,获取训练样本集合。
在本实施例中,前端代码生成模型的生成方法的执行主体(例如图1所示的终端设备或服务器)可以从本地或从远程获取训练样本集合。其中,训练样本集合中的每个训练样本可以包括样本界面图像和样本前端代码。样本界面图像可以是向用户展示的包括各种元素(例如按钮、表格、栅格等)的图像。样本界面图像可以是人工绘制的,也可以是利用爬虫技术从网络上爬取的,还可以是根据设定的规则自动生成的。样本界面图像对应的样本前端代码可以是人工编写的,也可以是利用设定的规则自动生成的。
样本前端代码可以运行并生成对应的图形用户界面(graphicaluserinterface,gui)。图形用户界面与对应的界面图像一致。样本前端代码可以是利用各种编程语言得到的。例如dsl(领域特定语言,domain-specificlanguages)、html(超文本标记语言,hypertextmarkuplanguage)等。其中,dsl通常用于定义参数化规则和状态,以生成程序的结构。基于dsl的模型可以为公共代码语句(例如,控制流、注释和括号)创建不同的语法规则。与通用编程语言相比,dsl的语法大小通常较小,这使得它在代码生成任务中更有效,因此在前端代码生成任务中,通常采用dsl。
步骤202,获取初始模型。
在本实施例中,上述执行主体可以从本地或从远程获取初始模型。其中,初始模型包括编码器和解码器,编码器包括视觉模型和语言模型。视觉模型用于确定输入的界面图像的图像特征,语言模型用于确定输入的代码字符串序列的文本特征,解码器用于对图像特征和文本特征解码,得到前端代码。
视觉模型可以包括卷积神经网络(cnn,convolutionalneuralnetworks),卷积神经网络包括卷积层、池化层、全连接层等。语言模型可以包括各种序列模型,例如rnn(recurrentneuralnetwork,循环神经网络)、gru(gatedrecurrentunit)、lstm(longshort-termmemory,长短期记忆网络)等。
步骤203,将样本界面图像输入视觉模型,得到图像特征。
在本实施例中,上述执行主体可以将样本界面图像输入视觉模型,得到图像特征。通常,图像特征可以是特定维度(例如1024)的向量,用于表征图像中的各种特征(例如图像的形状、颜色、纹理等)。
步骤204,确定输入的样本界面图像对应的代码字符串序列,并将代码字符串序列输入语言模型的词嵌入层,得到词向量,以及将词向量输入语言模型的特征提取层,得到代码字符串序列的文本特征。
在本实施例中,上述执行主体可以首先确定输入的样本界面图像对应的代码字符串序列。其中,代码字符串序列可以是输入的样本界面图像对应的样本前端代码包括的部分文字组成的序列。例如,代码字符串包括的文字的数量可以设定为48。作为示例,样本前端代码如下:("","",…,<start>,str<2>,str<3>,…,<end>),其中,开始标记<start>之前填充了47个空格,在首次迭代时,输入的代码字符串序列为:("","",…,<start>)。以后每次迭代向后滑动一个字符串。
然后,上述执行主体可以将代码字符串序列输入语言模型的词嵌入(embedding)层,得到词向量。
其中,词嵌入层用于将字符串序列中的字符转换为特定维度的词向量,这些词向量可以用来表征字符串序列的句法结构。例如,词嵌入层可以包括wrod2vec模型,采用无监督训练方法将得到一个为m*n维的参数矩阵,其中m为字典大小,n为词向量的维度(例如50)。每个字符映射到参数矩阵的对应id(即第id行的数据)得到一个1*50的词向量。
本公开采用了词嵌入而不是独热(one-hot)的表示方式。相对独热方式来说词嵌入能够解决独热表示方法中词的表示过于独立且无法学习到句法结构的问题。
最后,上述执行主体可以以及将词向量输入语言模型的特征提取层,得到代码字符串序列的文本特征。
其中,特征提取层可以包括至少一层,例如包括两层含有128个单元的gru模型。得到的文本特征可以表征字符串序列的意义。
步骤205,将图像特征和文本特征作为解码器的输入,将与输入的样本界面图像对应的样本前端代码作为期望输出,训练初始模型,得到前端代码生成模型。
在本实施例中,上述执行主体可以将图像特征和文本特征作为解码器的输入,将与输入的样本界面图像对应的样本前端代码作为期望输出,训练初始模型,得到前端代码生成模型。
具体地,解码器用于预测当前的字符串序列之后的下一个字符串。每次迭代训练时,输出表征下一个字符的特征数据,该特征数据与样本前端代码中实际的字符串(即期望输出)进行比较,利用反向传播法和梯度下降法迭代优化初始模型的参数,在达到预设结束条件(例如损失函数的损失值收敛、训练次数达到预设次数等)的情况下,结束训练,得到前端代码生成模型。
在本实施例的一些可选的实现方式中,在将图像特征和文本特征作为解码器的输入时,可以执行如下步骤:
首先,将图像特征和文本特征进行合并,得到合并特征。
具体地,如图3所示,其中的数字128表示字符串序列中的每个字符的特征(即文本特征textfeature)的维度,数字1024表征图像特征(imagefeature)的维度,这里图像特征的数量重复了多次,与字符串序列的长度一致。经过合并(concatenate)后,得到合并特征(concatenatefeature)。
然后,将合并特征作为解码器的输入。
本实现方式通过将图像特征和文本特征进行合并输入解码器,可以使解码器更好地对文本和图像向结合进行代码字符的预测,提高了生成前端代码的准确性。
在本实施例的一些可选的实现方式中,解码器采用注意力机制进行解码,得到前端代码包括的代码字符串。
其中,注意力机制在图像描述领域被广泛使用。引入注意力机制一方面可以突破由固定语义向量带来的瓶颈,另一方面可以让解码器在解码的过程中对不同的输入有不同的权重。具体地,注意力机制可以通过如下式(1)-式(4)实现:
hen=[p,q](1)
score(hen,yt)=dot(hen,yt)(2)
attt=softmax(wa*score(hen,yt))(3)
ot=softmax([attt*yt,yt])(4)
其中,对于每个时间步t,处理过的界面图像和字符串序列经过编码分别得到图像特征p和文本特征q,由p和q合并得到合并特征hen,yt为当前时间步经由解码器之后得到的输出。这边使用的是点乘的方法得到hen和yt之间的相似度,并以此为依据得到权重。最终的结果参考了yt和经由加权的上下文,通过一个softmax层得到。
本实现方式通过引入注意力机制,首先,可以使文本特征完整表达输入的字符串序列的完整信息,降低信息被遗漏、稀释的可能性。其次,由于文本特征的长度是固定的,如果输入序列越长,文本特征的表达能力也就越弱,注意力机制可以通过加权的方式使针对性地将语义集中由序列中特定的字符片段表征,提高文本特征表达语义的准确性。
在本实施例的一些可选的实现方式中,视觉模型采用包括se-net的卷积神经网络确定图像特征。
通常,cnn的卷积操作,可以被理解为通过使用卷积在局部感受野上将空间上和特征通道维度(channel-wise)上的信息进行聚合。相对于从空间角度上为卷积网络增加更多信息,比如将多尺度信息嵌入到inception结构中等。se-net可以理解为从特征通道角度为卷积网络增加额外的信息以提升网络性能。
图4为se-net的示意图,x为给定的特征通道为c′的输入,ftr表示经过一系列的卷积操作,得到特征通道为c的u,后边的步骤就是se-net的核心,即squeeze操作和excitation操作。
输入u先经过一个squeeze操作。
如公式(5)所示,其中zc表示得到的描述器的第c个元素,uc表示输入u的第c个通道。fsq是通过对输入u的c个特征通道上的每个h*w的空间特征进行压缩(这边使用的是globalpooling)得到一个具备全局感受野空间信息的实数,由此得到一个1*1*c大小的描述器(descriptor)。
之后,根据得到的描述器z进行excitation操作。
s=fex(z,w)=σ(g(z,w))=σ(w2*δ(w1z))(6)
如公式(6)所示,其中σ表示sigmoid函数操作,δ表示relu线性激活函数操作,w1是大小设置为c/r的待求全连接层参数,w2是大小设置为c的待求全连接层参数。fex类似于gru和lstm中用到的门控的机制。先让z先通过一个全连接层将其缩放为原本的1/r,通过一个relu激活函数后再通过一个全连接层将其放大到原本的大小,经过sigmoid得到一个0-1归一化的权重s。之所以需要先缩小再恢复是为了更好的拟合特征通道之间的非线性关联,r一般取16。
最后,根据得到的权重s对输入u做一个rescaling操作得到最终的输出o。
o=fscale(s,u)=s*u(7)
如公式(7)所示,其中fscale相当于对每个特征通道的空间特征用归一化的权重s进行加权。
本实现方式通过使用se-net,可以从特征通道角度为卷积网络增加额外的信息,提升网络性能,进一步提高模型生成前端代码的准确性。
在本实施例的一些可选的实现方式中,卷积神经网络采用卷积核大于等于2*2,且步长大于1的卷积层替代池化层。
通常,cnn中可以包括最大池化层。最大池化层用于缩小输出的维度以减小数据量、加快运算并一定程度防止过拟合。池化层除了以上的作用之外,还有一个作用就是其具有一定的平移不变性(invariance),但也正因为如此,它很可能会损失掉一些信息,例如颜色、位置信息和全局特征信息。相对于平移不变性,在本公开中,这些颜色、位置等信息的重要性远远超出与平移不变性。因此,本公开采用了步长大于1(例如步长为2),卷积核大于等于2*2(例如等于2*2)大小的卷积层来替代最大池化层,能够在缩小数据大小的同时将有用的信息更好的保留下来,从而有助于提高生成的图像特征的表达能力。
在本实施例的一些可选的实现方式中,语言模型和解码器采用gru网络进行编码和解码。
其中,gru不使用cell状态,而是直接用隐藏状态传递记忆,由此得以有更少的训练参数,能够让模型得到更快的迭代,从而有助于提高模型训练的效率。
在本实施例的一些可选的实现方式中,解码器采用beamsearch算法预测前端代码包括的代码字符串。
具体地,在得到训练好的模型之后,在推理的过程中,首先,输入界面图像和一个只包含<start>标签的dsl文件,由此进行一次推理得到下一个字符的概率分布,选择一个字符(记为o1)将其写入到输出文件中,再将填充过的(<start>,o1)与界面图像输入模型进行下一轮的推理,这样逐步进行,直到得到的标签是<end>标签或者达到设定的终止条件(比如最大长度等)。在得到第一个预测字符串的分布概率时,选择哪一个字符作为输出是需要思考的问题,目标是找出一个最好的输出序列,如下式所示:
采用beamsearch,每次得到字符的概率分布时,从中挑选至少两个字符(即宽度大于等于2),从而可以在预测代码字符时,可以保留更多的预测可能性,从而避免预测错一个字符串就导致整体预测偏离实际的情况,从而有助于提高预测前端代码中的字符串的准确性。
本申请的上述实施例提供的方法,通过将词嵌入层引入编码器中的语言模型,可以更好地挖掘出代码中的文字之间的关联,使利用语言模型得到文本特征的准确性更高,从而进一步使训练得到的前端代码生成模型生成的前端代码的准确性更高。
进一步参考图5,其示出了根据本申请的前端代码生成模型的生成方法的又一个实施例的流程。在图2对应实施例的基础上,步骤201可以包括以下步骤:
步骤2011,基于预设的元素种类和每个元素种类包括的元素样式,生成至少两个元素数据集合。
在本实施例中,上述执行主体可以基于预设的元素种类和每个元素种类包括的元素样式,生成至少两个元素数据集合。其中,至少两个元素数据集合中的每个元素数据集合对应于一个元素种类。元素数据集合中的元素数据可以表示一个特定样式的元素,根据元素数据,可以在界面上生成一种元素。
作为示例,元素种类可以包括按钮、栅格、输入框等种类,针对按钮,其元素样式可以包括红、绿、橘、蓝和默认四种样式。
具体地,可以利用预先编写的生成函数,生成各种元素数据。该生成函数可以根据输入的元素数据的数量和样式,自动生成元素数据。需要说明的是,生成函数的实现方法(例如穷举生成全排列的方法)是目前的公知技术,这里不再赘述。
步骤2012,从至少两个元素数据集合中提取元素数据进行组合,得到样本前端代码。
在本实施例中,上述执行主体可以从至少两个元素数据集合中提取元素数据进行组合,得到样本前端代码。其中,组合得到的样本前端代码可以生成包括各种元素的界面。
步骤2013,基于样本前端代码,生成样本界面图像。
在本实施例中,上述执行主体可以基于样本前端代码,生成样本界面图像。其中,样本前端代码可以在设定的运行环境中运行,生成相应的用户界面,可以对该用户界面截图,得到样本界面图像。
作为示例,如图6所示,其示出了生成样本前端代码的一个示例性流程图。其中,nvbar为导航栏、row为栅格,form为表格。max为提前设置好的元素数据总量,num为元素数据的计数值,rand为随机生成的(0,1)区间的数值。图6描述了训练样本集合的生成过程,先用步骤501描述的方法生成各个元素数据集合。然后随机选择一个nvbar,随后再随机挑选一个form或者是row进行组合便得到一个dsl数据,再经转换为html后利用模拟浏览器技术生成gui,对gui进行截图,由此便得到一个数据对(即样本界面图像和对应的样本前端代码dsl)。
本申请的图5对应实施例提供的方法,通过生成训练样本集合,可以避免通过爬虫技术爬取的数据造成的元素分辨不清、结构复杂、包含动态界面等问题,使生成的训练样本集合更加合理,易于训练,有助于提高训练模型的效率,以及提高训练得到的模型的代码生成效果。
继续参考图7,其示出了根据本申请的前端代码生成方法的一个实施例的流程700。该方法包括以下步骤:
步骤701,获取目标界面图像和初始代码字符串序列。
在本实施例中,前端代码生成模型的生成方法的执行主体(例如图1所示的终端设备或服务器)可以从本地或从远程获取目标界面图像和初始代码字符串序列。其中,目标界面图像为待利用其生成前端代码的图像,可以是人工绘制的图像,也可以是截取的图像。初始代码字符串序列可以是自动生成的,例如,初始代码字符串序列可以为:("","",…,<start>),其中<start>为代码的起始标记,在其前面添加了47个空格,以后每次迭代向后滑动一个字符串。
在步骤701之后,执行如下预测步骤(包括步骤702-步骤704)。
步骤702,将目标界面图像和初始代码字符串序列输入预先训练的前端代码生成模型,得到位于代码字符串序列之后的代码字符串。
在本实施例中,上述执行主体可以将目标界面图像和初始代码字符串序列输入预先训练的前端代码生成模型,得到位于代码字符串序列之后的代码字符串。其中,前端代码生成模型为利用上述图2对应实施例描述的方法预先训练得到的。关于前端代码生成模型的结构,可以参考图2对应实施例,这里不再赘述。
作为示例,假设初始代码字符串序列为("","",…,<start>),则模型输出字符串str<2>。
步骤703,将所得到的代码字符串添加进初始代码字符串序列之后。
在本实施例中,上述执行主体可以将所得到的代码字符串添加进初始代码字符串序列之后。继续上述示例,将str<2>添加到<start>之后,得到新的代码字符串序列为("","",…,<sttrt>,str<2>)。其中,<start>之前包括46个空格,这样,每次添加新的代码字符串后,新的初始代码字符串总保持48个字符串。
步骤704,确定所得到的代码字符串是否为结束标记。
在本实施例中,上述执行主体可以确定所得到的代码字符串是否为结束标记,如果是,执行步骤705,否则执行步骤706。作为示例,当模型输出的代码字符串为结束标记<end>时,表示预测结束。
步骤705,基于模型输出的代码字符串,生成目标界面图像的前端代码。
在本实施例中,上述执行主体可以基于模型输出的代码字符串,生成目标界面图像的前端代码。作为示例,在每次得到代码字符串后,将代码字符串加入预设的dsl文件中,则得到最终的dsl文件包括:(<start>,str<2>,str<3>,…,<end>)。
步骤706,基于最近一次添加代码字符串后的初始代码字符串序列,继续执行预测步骤。
在本实施例中,上述执行主体可以基于最近一次添加代码字符串后的初始代码字符串序列,继续执行预测步骤,即重新执行步骤702。
本申请的图7对应实施例提供的方法,通过使用图2对应实施例描述的前端代码生成模型,可以将界面图像转换为前端代码,从而利用了前端代码生成模型的结构,提高了生成前端代码的效率和准确性,有助于降低因手工调整代码造成的人力成本。
进一步参考图8,作为对上述各图所示方法的实现,本申请提供了一种前端代码生成模型的生成装置的一个实施例,该装置实施例与图2所示的方法实施例相对应,该装置具体可以应用于各种电子设备中。
如图8所示,本实施例的前端代码生成模型的生成装置800包括:第一获取模块801,用于获取训练样本集合,其中,训练样本包括样本界面图像和样本前端代码;第二获取模块802,用于获取初始模型,其中,初始模型包括编码器和解码器,编码器包括视觉模型和语言模型;第一生成模块803,用于将样本界面图像输入视觉模型,得到图像特征;第二生成模块804,用于确定输入的样本界面图像对应的代码字符串序列,并将代码字符串序列输入语言模型的词嵌入层,得到词向量,以及将词向量输入语言模型的特征提取层,得到代码字符串序列的文本特征;训练模块805,用于将图像特征和文本特征作为解码器的输入,将与输入的样本界面图像对应的样本前端代码作为期望输出,训练初始模型,得到前端代码生成模型。
在本实施例中,第一获取模块801可以从本地或从远程获取训练样本集合。其中,训练样本集合中的每个训练样本可以包括样本界面图像和样本前端代码。样本界面图像可以是向用户展示的包括各种元素(例如按钮、表格、栅格等)的图像。样本界面图像可以是人工绘制的,也可以是利用爬虫技术从网络上爬取的,还可以是根据设定的规则自动生成的。样本界面图像对应的样本前端代码可以是人工编写的,也可以是利用设定的规则自动生成的。
样本前端代码可以运行并生成对应的图形用户界面。图形用户界面与对应的界面图像一致。样本前端代码可以是利用各种编程语言得到的。例如dsl、html等。
在本实施例中,第二获取模块802从本地或从远程获取初始模型。其中,初始模型包括编码器和解码器,编码器包括视觉模型和语言模型。视觉模型用于确定输入的界面图像的图像特征,语言模型用于确定输入的代码字符串序列的文本特征,解码器用于对图像特征和文本特征解码,得到前端代码。
视觉模型可以包括卷积神经网络,卷积神经网络包括卷积层、池化层、全连接层等。语言模型可以包括各种序列模型,例如rnn、gru、lstm等。
在本实施例中,第一生成模块803可以将样本界面图像输入视觉模型,得到图像特征。通常,图像特征可以是特定维度(例如1024)的向量,用于表征图像中的各种特征(例如图像的形状、颜色、纹理等)。
在本实施例中,第二生成模块804可以首先确定输入的样本界面图像对应的代码字符串序列。其中,代码字符串序列可以是输入的样本界面图像对应的样本前端代码包括的部分文字组成的序列。例如,代码字符串包括的文字的数量可以设定为48。作为示例,样本前端代码如下:("","",…,<start>,str<2>,str<3>,…,<end>),其中,开始标记<start>之前填充了47个空格,在首次迭代时,输入的代码字符串序列为:("","",…,<start>)。以后每次迭代向后滑动一个字符串。
然后,上述第二生成模块804可以将代码字符串序列输入语言模型的词嵌入(embedding)层,得到词向量。
其中,词嵌入层用于将字符串序列中的字符转换为特定维度的词向量,这些词向量可以用来表征字符串序列的句法结构。例如,词嵌入层可以包括wrod2vec模型,采用无监督训练方法将得到一个为m*n维的参数矩阵,其中m为字典大小,n为词向量的维度(例如50)。每个字符映射到参数矩阵的对应id(即第id行的数据)得到一个1*50的词向量。
本公开采用了词嵌入而不是独热(one-hot)的表示方式。相对独热方式来说词嵌入能够解决独热表示方法中词的表示过于独立且无法学习到句法结构的问题。
最后,上述第二生成模块804可以以及将词向量输入语言模型的特征提取层,得到代码字符串序列的文本特征。
其中,特征提取层可以包括至少一层,例如包括两层含有128个单元的gru模型。得到的文本特征可以表征字符串序列的意义。
在本实施例中,训练模块805可以将图像特征和文本特征作为解码器的输入,将与输入的样本界面图像对应的样本前端代码作为期望输出,训练初始模型,得到前端代码生成模型。
具体地,解码器用于预测当前的字符串序列之后的下一个字符串。每次迭代训练时,输出表征下一个字符的特征数据,该特征数据与样本前端代码中实际的字符串(即期望输出)进行比较,利用反向传播法和梯度下降法迭代优化初始模型的参数,在达到预设结束条件(例如损失函数的损失值收敛、训练次数达到预设次数等)的情况下,结束训练,得到前端代码生成模型。
在本实施例的一些可选的实现方式中,训练模块可以包括:合并单元(图中未示出),用于将图像特征和文本特征进行合并,得到合并特征;输入单元(图中未示出),用于将合并特征作为解码器的输入。
在本实施例的一些可选的实现方式中,解码器采用注意力机制进行解码,得到前端代码包括的代码字符串。
在本实施例的一些可选的实现方式中,视觉模型采用包括se-net的卷积神经网络确定图像特征。
在本实施例的一些可选的实现方式中,卷积神经网络采用卷积核大于等于2*2,且步长大于1的卷积层替代池化层。
在本实施例的一些可选的实现方式中,语言模型和解码器采用gru网络进行编码和解码。
在本实施例的一些可选的实现方式中,解码器采用beamsearch算法预测前端代码包括的代码字符串。
在本实施例的一些可选的实现方式中,第一获取模块可以包括:第三生成单元(图中未示出),用于基于预设的元素种类和每个元素种类包括的元素样式,生成至少两个元素数据集合,其中,至少两个元素数据集合中的每个元素数据集合对应于一个元素种类;组合单元(图中未示出),用于从至少两个元素数据集合中提取元素数据进行组合,得到样本前端代码;第四生成单元(图中未示出),用于基于样本前端代码,生成样本界面图像。
本申请的上述实施例提供的装置,通过将词嵌入层引入编码器中的语言模型,可以更好地挖掘出代码中的文字之间的关联,使利用语言模型得到文本特征的准确性更高,从而进一步使训练得到的前端代码生成模型生成的前端代码的准确性更高。
进一步参考图9,作为对上述各图所示方法的实现,本申请提供了一种前端代码生成装置的一个实施例,该装置实施例与图7所示的方法实施例相对应,该装置具体可以应用于各种电子设备中。
如图9所示,本实施例的前端代码生成装置900包括:第三获取模块901,用于获取目标界面图像和初始代码字符串序列;预测模块902,用于执行如下预测步骤:将目标界面图像和初始代码字符串序列输入预先训练的前端代码生成模型,得到位于代码字符串序列之后的代码字符串;将所得到的代码字符串添加进初始代码字符串序列之后;确定所得到的代码字符串是否为结束标记;如果是,基于模型输出的代码字符串,生成目标界面图像的前端代码;确定模块903,用于如果确定所得到的代码字符串不是结束标记,基于最近一次添加代码字符串后的初始代码字符串序列,继续执行预测步骤。
在本实施例中,第三获取模块901可以从本地或从远程获取目标界面图像和初始代码字符串序列。其中,目标界面图像为待利用其生成前端代码的图像,可以是人工绘制的图像,也可以是截取的图像。初始代码字符串序列可以是自动生成的,例如,初始代码字符串序列可以为:("","",…,<start>),其中<start>为代码的起始标记,在其前面添加了47个空格,以后每次迭代向后滑动一个字符串。
在本实施例中,预测模块902可以将目标界面图像和初始代码字符串序列输入预先训练的前端代码生成模型,得到位于代码字符串序列之后的代码字符串。其中,前端代码生成模型为利用上述图2对应实施例描述的方法预先训练得到的。关于前端代码生成模型的结构,可以参考图2对应实施例,这里不再赘述。
作为示例,假设初始代码字符串序列为("","",…,<start>),则模型输出字符串str<2>。
然后,将所得到的代码字符串添加进初始代码字符串序列之后。继续上述示例,将str<2>添加到<start>之后,得到新的代码字符串序列为("","",…,<start>,str<2>)。其中,<start>之前包括46个空格,这样,每次添加新的代码字符串后,新的初始代码字符串总保持48个字符串。
再然后,可以确定所得到的代码字符串是否为结束标记,如果是,基于模型输出的代码字符串,生成目标界面图像的前端代码。作为示例,在每次得到代码字符串后,将代码字符串加入预设的dsl文件中,则得到最终的dsl文件包括:(<start>,str<2>,str<3>,…,<end>)。
在本实施例中,确定模块903可以基于最近一次添加代码字符串后的初始代码字符串序列,继续执行预测步骤。
本申请的上述实施例提供的装置,通过使用图2对应实施例描述的前端代码生成模型,可以将界面图像转换为前端代码,从而利用了前端代码生成模型的结构,提高了生成前端代码的效率和准确性,有助于降低因手工调整代码造成的人力成本。
下面参考图10,其示出了适于用来实现本申请实施例的电子设备的计算机系统1000的结构示意图。图10示出的电子设备仅仅是一个示例,不应对本申请实施例的功能和使用范围带来任何限制。
如图10所示,计算机系统1000包括中央处理单元(cpu)1001,其可以根据存储在只读存储器(rom)1002中的程序或者从存储部分1008加载到随机访问存储器(ram)1003中的程序而执行各种适当的动作和处理。在ram1003中,还存储有系统1000操作所需的各种程序和数据。cpu1001、rom1002以及ram1003通过总线1004彼此相连。输入/输出(i/o)接口1005也连接至总线1004。
以下部件连接至i/o接口1005:包括键盘、鼠标等的输入部分1006;包括诸如液晶显示器(lcd)等以及扬声器等的输出部分1007;包括硬盘等的存储部分1008;以及包括诸如lan卡、调制解调器等的网络接口卡的通信部分1009。通信部分1009经由诸如因特网的网络执行通信处理。驱动器1010也根据需要连接至i/o接口1005。可拆卸介质1011,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器1010上,以便于从其上读出的计算机程序根据需要被安装入存储部分1008。
特别地,根据本公开的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的实施例包括一种计算机程序产品,其包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分1009从网络上被下载和安装,和/或从可拆卸介质1011被安装。在该计算机程序被中央处理单元(cpu)1001执行时,执行本申请的方法中限定的上述功能。
需要说明的是,本申请所述的计算机可读存储介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本申请中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本申请中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读存储介质,该计算机可读存储介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读存储介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
可以以一种或多种程序设计语言或其组合来编写用于执行本申请的操作的计算机程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如java、smalltalk、c++,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络——包括局域网(lan)或广域网(wan)—连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。
附图中的流程图和框图,图示了按照本申请各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,该模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
描述于本申请实施例中所涉及到的模块可以通过软件的方式实现,也可以通过硬件的方式来实现。所描述的模块也可以设置在处理器中,例如,可以描述为:一种处理器包括第一获取模块、第二获取模块、第一生成模块、第二生成模块和训练模块。其中,这些模块的名称在某种情况下并不构成对该单元本身的限定,例如,第一获取模块还可以被描述为“用于获取训练样本集合的模块”。
作为另一方面,本申请还提供了一种计算机可读存储介质,该计算机可读存储介质可以是上述实施例中描述的电子设备中所包含的;也可以是单独存在,而未装配入该电子设备中。上述计算机可读存储介质承载有一个或者多个程序,当上述一个或者多个程序被该电子设备执行时,使得该电子设备:获取训练样本集合,其中,训练样本包括样本界面图像和样本前端代码;获取初始模型,其中,初始模型包括编码器和解码器,编码器包括视觉模型和语言模型;将样本界面图像输入视觉模型,得到图像特征;确定输入的样本界面图像对应的代码字符串序列,并将代码字符串序列输入语言模型的词嵌入层,得到词向量,以及将词向量输入语言模型的特征提取层,得到代码字符串序列的文本特征;将图像特征和文本特征作为解码器的输入,将与输入的样本界面图像对应的样本前端代码作为期望输出,训练初始模型,得到前端代码生成模型。
此外,当上述一个或者多个程序被该电子设备执行时,还可以使得该电子设备:获取目标界面图像和初始代码字符串序列;执行如下预测步骤:将目标界面图像和初始代码字符串序列输入预先训练的前端代码生成模型,得到位于代码字符串序列之后的代码字符串;将所得到的代码字符串添加进初始代码字符串序列之后;确定所得到的代码字符串是否为结束标记;如果是,基于模型输出的代码字符串,生成目标界面图像的前端代码;如果确定所得到的代码字符串不是结束标记,基于最近一次添加代码字符串后的初始代码字符串序列,继续执行预测步骤。
以上描述仅为本申请的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本申请中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离上述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本申请中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!