基于云计算的遥感大数据自动化处理方法与流程
本发明属于遥感大数据处理领域,具体涉及一种基于云计算的遥感大数据自动化处理方法。
背景技术:
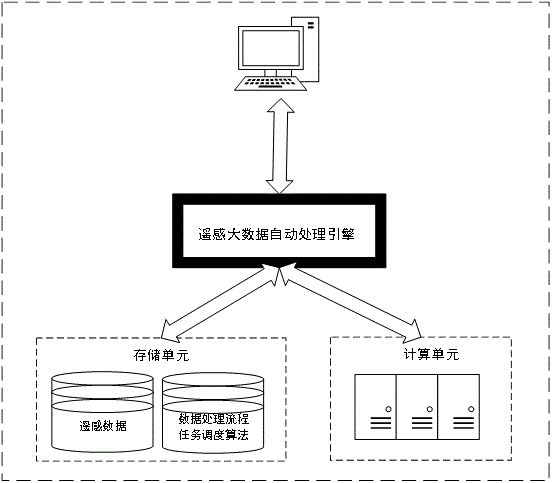
:遥感图像处理即对遥感图像进行一系列光学处理和数字图像处理以达到预期目的的技术,已被广泛应用于航海、气象、农业和资源等领域。伴随着遥感技术的不断发展,遥感图像分辨率逐步增加,其数据量呈爆炸式增长,这就产生了遥感大数据单机处理困难的问题,为了解决这一问题,越来越多的学者将遥感大数据处理与云计算相结合。云计算是一种商业计算模型,以云资源管理软件和虚拟化工具为基础,将cpu、存储器和gpu虚拟为方便管理应用的资源池,用户可以根据需求获取存储和计算服务。在网络带宽飞速发展的今天,特别是5g正式商用之后,用户可以利用个人的便携设备控制云端的服务器完成海量数据的处理和计算,从而降低设备的管理成本和维护成本。云计算框架在云平台的基础上可以实现海量数据存储和高效并行计算,在执行计算任务时可以将大量复杂的计算任务分发到众多节点,减少了任务处理时间,有效提高了海量数据的处理效率。然而,现有基于云计算平台处理遥感数据时,往往采用人工手动方法部署处理流程中的多个任务,费时费力且容易出错;同时,也未用调度算法对流程涉及的多个任务进行调度优化,效率较低。技术实现要素:本发明的目的在于提供一种基于云计算的遥感大数据自动化处理方法,利用自主设计的标准化接口,将遥感大数据处理的任务描述为流程,同时,使用任务调度算法对流程涉及的任务进行调度优化,不仅实现了遥感图像的云计算自动化处理,而且有效提高了数据处理效率。实现本发明目的的技术方案为:一种基于云计算的遥感大数据自动化处理方法,该方法通过处理系统实现,处理系统包括遥感大数据自动化处理引擎、存储单元和计算单元,所述方法包括如下步骤:步骤1,遥感大数据自动化处理引擎识别输入的遥感大数据处理请求,获知待处理遥感数据存储地址、遥感数据处理流程、资源-时间映射表、遥感数据处理流程所涉及数据处理任务的存储地址和数据处理任务调度算法的存储地址;步骤2,遥感大数据自动化处理引擎根据步骤1中获得的数据处理任务调度算法存储地址从存储单元获取数据处理任务调度算法,并将遥感数据处理流程、资源-时间映射表作为数据处理任务调度算法的输入,执行数据处理任务调度算法,得到数据处理任务调度结果;步骤3,遥感大数据自动化处理引擎根据步骤2中获得的调度结果在计算单元中部署计算环境;步骤4,遥感大数据自动化处理引擎根据步骤1中的遥感数据和数据处理任务的存储地址分别获取遥感数据和数据处理任务,并根据步骤2获得的任务调度结果在步骤3获得的计算环境中执行数据处理任务,得到遥感数据的处理结果。进一步的,步骤1具体是由客户端提交遥感大数据处理请求,引擎识别请求后获知待处理遥感数据存储地址、遥感数据处理流程、资源-时间映射表rdmt、遥感数据处理流程所涉及任务的存储地址和算法的存储地址并写入标准化接口文件。进一步的,所述标准化接口文件是通过标准化的方式描述方法各模块的输入输出,由标记语言实现。进一步的,步骤1所述的遥感数据处理流程是由遥感大数据算法处理中具有偏序关系的任务组合而成。进一步的,步骤1所述的资源-时间映射表描述了任务在不同计算分片和不同数据量下的执行时间。进一步的,步骤2中所述的遥感大数据自动化处理引擎根据标准化接口文件中的算法存储地址,从存储单元获取算法,将遥感数据处理流程、资源-时间映射表作为算法的输入,利用算法的寻优机制分析流程中任务之间和任务内部的并行关系,计算出调度结果,并将调度结果写入标准化接口文件。进一步的,调度结果包括:每个子任务所需的计算节点数量、计算节点序号、预估任务开始时间和任务完成时间。进一步的,步骤3所述的遥感大数据自动化处理引擎根据步骤2中获得的调度结果在计算单元中部署计算环境,具体为:遥感大数据自动化处理引擎根据标准化接口文件中的调度结果,向计算单元申请相应的计算资源,并通过计算环境自动化部署脚本进行计算环境的部署。进一步的,所述自动化部署脚本由程序设计语言实现;计算环境的部署过程为:准备功能完善的服务器系统,启动服务器集群,配置计算框架和存储框架文件,启动计算环境。进一步的,步骤4所述的遥感大数据自动化处理引擎根据标准化接口文件中的遥感数据和任务的存储地址分别获取遥感数据和数据处理任务,并根据步骤2获得的任务调度结果在步骤3获得的计算环境中执行任务,得到最终的数据处理结果。本发明与现有技术相比,具有以下显著优点:(1)相较于其他遥感大数据处理方法,本发明的方法将遥感大数据处理的多个任务描述为流程,并通过自动化处理引擎处理该流程,实现遥感大数据处理的自动化;(2)本发明使用任务调度算法,提高了流程的执行效率。(1)本发明相较于其他遥感大数据处理方法,设计了计算环境自动化部署引擎,提高了计算环境部署效率。(2)本发明利用任务调度优化算法的寻优机制预先评估计算过程中的资源分配与调度,提高了资源利用率和计算效率。(3)本发明使用标准化接口将各模块衔接在一起,提高了数据处理效率,实现了遥感大数据的自动化处理。附图说明图1是基于云计算的遥感大数据自动化处理系统示意图。图2是基于云计算的遥感大数据自动化处理方法流程图。图3是遥感图像变化检测任务流程图。图4是计算环境自动化部署流程图。图5是计算资源数量为8时三种调度算法的调度结果图。图6(a)和图6(b)是遥感图像变化检测结果对比图,其中图6(a)是地表实际情况图,图6(b)是检测结果图。具体实施方式为了实现遥感大数据自动化处理,提高云计算平台处理遥感大数据的效率,本发明提出一种基于云计算的遥感大数据自动化处理方法,不仅实现了遥感图像的云计算自动化处理,而且使用任务调度算法在保证遥感大数据处理流程效果的基础上,有效提高了数据处理效率。一种基于云计算的遥感大数据自动化处理方法,包括如下步骤:步骤(a),引擎识别输入的遥感大数据处理请求,获知待处理遥感数据存储地址、流程、资源-时间映射表rdmt、流程所涉及任务的存储地址和算法的存储地址。具体步骤为:客户端提交遥感大数据处理请求,引擎识别请求后获知待处理遥感数据存储地址、流程、资源-时间映射表rdmt、流程所涉及任务的存储地址和算法的存储地址并写入标准化接口文件。其中,标准化接口文件是通过标准化的方式描述了方法各模块的输入输出,由xml标记语言实现;存储地址为存储在存储单元中各种信息的链接地址,表现为类似“hdfs://10.10.10.100:8020/hadoop/sa/cs.xml”,引擎可以根据地址从存储单元中获取到所需要的数据或算法。遥感数据处理流程是由遥感大数据处理中具有偏序关系的任务组合而成。本发明使用有向无环图描述流程,图中的节点表示任务,图中的边表示任务的偏序关系。在标准化接口文件中,任务通过task字段表示,包含名称(name)、编号(id)、并行标记(flag)、备注(description)、输入(input)、输出(output)和资源-时长映射表(简称为rdmt),rdmt为描述了任务在不同计算分片和不同数据量下的执行时间。在标准化接口文件中,表示任务偏序关系的边通过字段edge表示,包含前序(pretask)和后继(suctask)。步骤(b),引擎根据步骤(a)中的存储地址从存储单元获取算法,并将流程、rdmt作为算法的输入,得到调度结果。具体步骤为:引擎根据标准化接口文件中的算法存储地址,从存储单元获取算法,将流程、rdmt作为算法的输入,利用算法的寻优机制分析流程中任务之间和任务内部的并行关系,计算出调度结果,并将调度结果写入标准化接口文件。其中调度结果包括以下内容:每个子任务所需的计算节点数量(comquantity)、计算节点序号(comnum)、预估任务开始时间(starttime)和任务完成时间(completetime)。步骤(c),引擎根据步骤(b)中获得的调度结果中的计算节点数量在计算单元中部署计算环境。具体步骤为:引擎根据标准化接口文件中的调度结果,向计算单元申请相应的计算资源,并通过计算环境自动化部署脚本进行计算环境的部署。其中,自动化部署脚本由shell脚本语言设计实现;部署具体过程包括:准备功能完善的服务器系统,启动服务器集群,配置计算框架和存储框架文件,启动计算环境。步骤(d),引擎根据步骤(a)中的遥感数据和任务的存储地址分别获取遥感数据和任务,并根据步骤(b)获得的任务调度结果在步骤(c)获得的计算环境中执行任务,得到遥感数据的处理结果。具体步骤为:引擎根据标准化接口文件中步骤(a)写入的遥感数据和任务的存储地址分别获取遥感数据和任务,并根据步骤(b)获得的任务调度结果在步骤(c)获得的计算环境中执行任务,得到最终的数据处理结果。下面通过实施例对本发明技术方案进行详细说明。实施例如图1、2所示,本发明的基于云计算的遥感大数据自动化处理方法具体实施方式以遥感图像变化检测请求,布谷鸟搜索任务调度算法(cuckoosearch,cs),centos系统,spark计算框架,计算资源数8,处理数据规模最大683mb为例,包括以下步骤:步骤(a),引擎识别输入的遥感图像变化检测请求,获知多时相遥感数据存储地址、遥感图像变化检测算法流程(以下简称“变化检测流程”)、资源-时间映射表rdmt、遥感图像变化检测流程所涉数据处理任务(以下简称“变化检测任务”)的存储地址和cs算法的存储地址,并写入标准化接口文件。文件包含了数据存储地址、变化检测流程、rdmt、变化检测任务存储地址和cs算法存储地址五个字段。步骤(b),引擎根据标准化接口文件中的cs算法存储地址“hdfs://10.10.10.100:8020/hadoop/sa/cs.xml”,从存储单元获取cs算法,将变化检测流程、rdmt作为cs算法的输入,利用cs算法的寻优机制分析变化检测流程中变化检测任务之间和变化检测任务内部的并行关系,计算出调度结果,并将调度结果写入标准化接口文件。cs算法输入为图3所示的变化检测流程和所有变化检测任务的rdmt,算法参数如表1所示:表1调度算法参数表不失一般性,以最短数据处理时间和最低服务器功耗为目标,进行多目标优化任务调度建模,得到的模型如式1,式2所示:(1)(2)上述公式分别为数据处理时间模型和服务器功耗模型。其中,表示第k个计算节点处理完所有任务后的完成时间,表示总时长,表示服务器计算整个任务流所产生的总能耗(焦耳/j),表示服务器单位时间内的动态功率(瓦特/w),表示服务器cpu利用率,表示服务器单位时间内的静态功率(瓦特/w),表示服务器单个虚拟机的空闲时间(秒/s);runtime表示服务器单个虚拟机处理任务的时长(秒)。在多目标任务调度中,结果一般为含有若干个pareto解的pareto解集,每个pareto解详细描述了每个变化检测任务所需的计算节点数量、计算节点序号、预估变化检测任务开始时间和变化检测任务完成时间。其数字模型可由式3表示:(3)其中,表示第j台计算节点计算任务i的开始时间,表示任务i的处理时间。遥感图像变化检测在计算资源数为8时的调度结果如图5所示,其中圆圈代表cs的调度结果,五角星和叉号分别代表粒子群算法和遗传算法的调度结果,其中一个cs算法的pareto解如表2所示:表2遥感图像变化检测分布式并行算法布谷鸟搜索调度pareto解步骤(c),引擎根据标准化接口文件中的调度结果,向计算单元申请相应的计算资源,随后通过计算环境自动化部署脚本,进行计算环境的准备与部署。如图4所示,自动化部署脚本具体实现过程为:1)获取计算节点ip。控制节点通过网络扫描嗅探包nmap扫描子网中启动完毕的计算节点,并筛除自身和调试节点;2)初始化ip映射文件。通过linuxsed指令编辑系统ip映射文件hosts,将计算虚拟机集群ip添加到文件中;3)控制节点计算框架配置。利用awk和linuxsed命令编辑控制节点的spark和hadoop配置文件;4)广播配置文件。通过shellscp指令结合expect自动交互工具包向各计算节点广播配置文件;5)配置ssh互信。计算集群需要各节点与其他节点互相免密通信,center节点首先与子节点进行ssh互信,后续使用ssh远程命令控制各子节点进行ssh公钥和私钥的广播;6)格式化hdfs。执行命令“%hadoop_home/bin/hadoopnamenode-format”,进行hdfs使用前的一些清除与准备工作;7)启动计算框架。分别执行hadoop和spark的start-all.sh启动计算集群。步骤(d),引擎根据标准化接口文件中写入的遥感数据和任务的存储地址分别获取遥感数据和任务,并根据步骤(b)获得的cs算法调度结果在步骤(c)获得的计算环境中执行任务,得到最终的数据处理结果。以k-means算法为例,标准化接口文件中的描述信息如表3所示:表3k-means算法描述表具体处理结果如图6(b)、表4和表5所示。与图6(a)的地表实际情况图对比,可发现,经过遥感大数据自动化处理方法获得的并行算法所得结果与“实际情况图”具有高度的相似性,这表明并行算法保持了较高的精度。比较表4和表5,可发现并行算法获取了较高的加速比。这表明,并行算法能在保持较高精度的前提下获得可观的加速比。表4不用并行度下的变化检测结果分片串行2481632总体精度0.957480.93940.93810.93760.93720.9367表5实验并行处理时间与加速比其中,image1、image2和image3为原始图像复制扩充而得,大小分别为:138mb、341mb、683mb。以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1