一种基于分层数据筛选的跨项目软件缺陷预测方法与流程
本发明属于软件工程领域,具体涉及一种基于分层数据筛选的跨项目软件缺陷预测方法
背景技术:
软件缺陷产生于开发人员的编码过程,软件需求理解不正确、软件开发过程不合理或开发人员的经验不足,均有可能引入软件缺陷。含有缺陷的软件在部署后可能会产生意料之外的结果或行为,严重时会给企业造成巨大的经济损失,甚至是威胁人们的生命安全。在软件开发的生命周期中,检测出软件缺陷的时间越晚,缺陷修复的代价越大。尤其是在软件部署后,检测和修复缺陷的代价将成指数级增加。因此企业设置专门的测试部门或质量保证部门花费大量的人力物力借助软件测试或者代码审查等方法希望能在软件部署前能够找到软件中潜在的错误程序模块。
软件缺陷预测是一种可行方法,根据软件历史开发数据以及已发现的缺陷,借助机器学习等方法来预测出软件项目内的潜在缺陷程序模块。软件缺陷预测是当前软件测试领域和机器学习紧密结合的一个研究热点,目的是希望能够在项目开发的早期阶段预测出某些模块中是否含有缺陷,从而合理地分配测试资源,最大化资源利用率。
目前大部分的研究都关注项目内缺陷预测问题(withinprojectdefectprediction,wpdp),也就是选择同一项目的部分数据集作为训练数据,剩下的部分作为测试数据来构建模型。通常构建一个性能较好的缺陷预测模型需要大量的训练实例,而现实中收集并且标注足够多的训练数据相当困难。一方面一些新开发的软件项目只含有很少的训练数据,同时也没有历史数据作为训练数据,另一方面标记数据需要耗费大量的人力物力且这个过程容易出错。最重要的一点是使用此种方法构建的模型难以在其他项目上进行缺陷预测,即此种模型不具备普适性。
针对此实际问题有学者提出了跨项目缺陷预测(crossprojectdefectprediction,cpdp),即从其他软件项目中选择合适的数据集作为训练数据来训练缺陷预测模型,然后用于预测目标项目是否含有缺陷。一种简单的跨项目缺陷预测方案是直接使用其他的软件项目的缺陷数据来为目标项目构建缺陷预测模型,但由于不同的软件项目的特征并不相同,例如项目的应用领域、采用的开发流程、使用的编程语言以及开发人员的经验等等,所以源项目和目标项目的数据集存在很大的度量元分布差异,难以满足传统缺陷预测模型的独立同分布假设,因此如何从源项目中迁移出与目标项目相关的知识,减小源项目与目标项目的数据分布差异性成为研究人员的热点。
技术实现要素:
本发明目的:针对现有技术的的不足,对其中训练数据集的选择方法进行了改进,提出了一种基于分层数据筛选的跨项目软件缺陷预测方法,该方法有效降低了源项目和目标项目之间的数据分布差异性。
技术方案:一种基于分层数据筛选的跨项目软件缺陷预测方法,包括以下步骤:
步骤1:从软件缺陷数据集中选择训练集(源项目集)和测试集(目标项目集),并且对所有项目集数据进行log变换;
步骤2:提取所有项目属性的分布特征向量和项目分布向量,计算源项目与目标项目之间的相似度,选择与目标项目最相似的k个源项目集得到候选源项目集;
步骤3:合并k个候选源项目集,计算源项目中所有实例与目标项目实例相关程度,选择与目标项目中实例相关程度最高的h个实例得到候选实例集;
步骤4:使用候选实例集训练朴素贝叶斯模型;
步骤5:使用测试数据集测试预测模型;
步骤6:对提出的方法进行显著性检验,看该方法是否明显区别于其他方法。
进一步的,所述步骤1中训练集(源项目集)没有与测试集(目标项目)属同一项目的数据。
进一步的,所述步骤1中采用式(1)对所有项目集数据进行log变换:
y=ln(1+x)(1)
式(1)中x表示变换前的项目内各个属性数据,y表示变换后的数据。如原数据存在0值,则变换后数据值为1。
进一步的,所述步骤2中提取项目属性分布特征向量
dj={mean(fj),median(fj),skew(fj),kurt(fj)};项目分布向量v={d1,d2...dm}。
其中dj表示表示一个软件项目中所有n个实例的第j个度量属性的分布特征,v表示一个项目中所有n个实例的所有m个度量属性的分布特征。
进一步的,所述步骤2中采用式(2)计算源项目与目标项目之间的相似度:
式(2)中dsi表示源项目中属性分布特征向量,dti表示目标项目中属性分布特征向量,依据计算结果选出k个相似度最高的候选源项目。
进一步的所述步骤3中采用式(3)计算源项目中所有实例与目标项目中实例之间的相关程度:
式(3)中cov(x,y)为实例x与实例y的协方差,var[x]为实例x的方差,var[y]为实例y的方差。
进一步的,所述步骤5中采用式(4)对测试数据进行预测:
式(4)中x=(x1,x2...,xn),y∈{0,1},0表示该软件模块不存在缺陷,1则相反,表示软件模块中有缺陷。最终的预测结果为一个条件概率值,若p(1|x)>p(0|x),则认为该模块有缺陷。
进一步的,所述步骤6中采用wilcoxcon符号秩检验对方法进行显著性检验。
附图说明
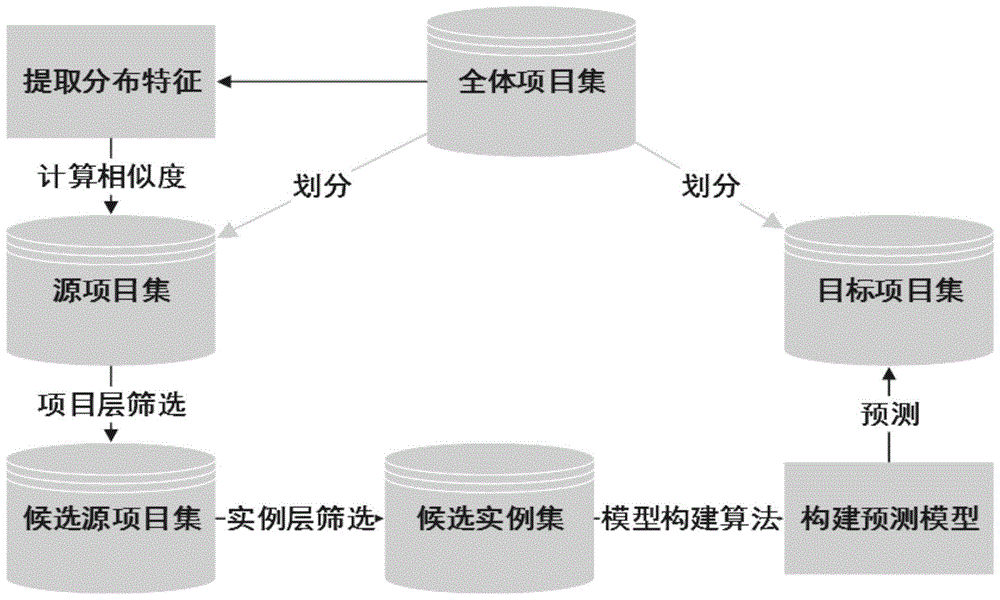
图1是本发明所设计的基于分层数据筛选的跨项目软件缺陷预测方法的流程示意图。
图2是本发明所设计的基于分层数据筛选的跨项目软件缺陷预测方法的具体实验步骤。
图3是本发明所设计的基于分层数据筛选的跨项目软件缺陷预测方法步骤一中的属性分布特征向量图。
具体实施
现结合附图和实例进一步阐述本发明的技术方案
如图1所示,本发明的一种基于分层数据筛选的跨项目软件缺陷预测方法,该方法采用分层筛选的策略实现了模型所需的训练数据的选择,有效解决了跨项目软件缺陷预测方法中项目之间以及实例之间的差异性降低缺陷预测性能的问题。该方法将训练数据的筛选过程分为项目层筛选和实例层筛选,首先从其他数据集中按照最近邻算法选出与目标项目数据分布最接近的候选项目集,其次在候选项目集中按照相关程度高低选出与目标项目中实例相似度较高的训练实例集,最后使用训练实例集结合朴素贝叶斯算法训练出缺陷预测模型。使用该模型在promise数据集上进行缺陷预测,该方法有效降低了跨项目的训练数据和目标数据的分布差异。
实施实例
本例的跨项目软件缺陷预测方法,用于构建高性能的软件缺陷预测模型,并对目标软件项目进行缺陷预测,如图1所示,实际应用中包括以下步骤:步骤1:从软件缺陷数据集中选择训练集(源项目集)和测试集(目标项目),并且采用式(1)对所有项目集数据进行log变换,然后进入步骤2提取如图3所示的所有项目属性的分布特征向量和项目分布向量;如图2所示目标项目和所选的候选源项目不存在同一个模块的数据,以promise数据集为例,如果ant-1.3作为目标项目,那么ant项目的其他版本不能作为候选源项目数据集。
表1promise实验数据集
表1promise实验数据集
该数据集是由jureczko和madeyski收集。该数据集来自10个不同开源项目(例如ant、log4j、lucene、poi等)的多个版本。每个项目中实例的特征包括20种不同的度量元和一个缺陷数量标记,这20种度量元均关注的是代码复杂度,其中包括由chidamber和kemerer提出的ck度量元。这些度量元综合考虑了面向对象程序固有的封装、继承、多态等特性。由于实验关注的是缺陷的分类问题,即有缺陷和无缺陷问题,因此对于数据集中的缺陷数量标记,需要把项目中缺陷数量大于0的实例标记为有缺陷标签y,缺陷数量为0的实例标记为无缺陷标签n。表中project表示软件项目名称,numberofmodules表示软件向项目的模块数,numberofdefects表示该模块存在的缺陷数,defect-prone%表示缺陷比。
采用式(2)计算源项目与目标项目之间的相似度:
如图2所示以ant-1.3作为目标项目,我们在所有项目里去除ant项目的所有版本,将剩余的项目和ant-1.3采用式(1)作log变换后,采用式(2)计算从camel项目到xerces项目的所有版本与ant-1.3项目的相似度d。我们将相似度d排序,取前k个,我们得到jedit-4.2,synapse-1.0等等几个候选源项目。
进入步骤3:我们合并上面选出的jedit-4.2,stnpse-1.0等k个源项目,然后采用式(3)计算目标项目即ant-1.3中的每个实例与合并后的源项目集中的实例的相关程度p。
采用式(3)计算时,其中x即为目标项目中的一个实例,y即为源项目集中的一个实例,y和x依次在实例间轮换。计算完后对p进行排序,我们选择p值最小的h个实例构成训练集。
进入步骤4:我们使用上面得到的实例集作为训练集训练朴素贝叶斯模型,接着使用朴素贝叶斯模型对ant-1.3模块的数据进行预测。预测过程实际则为采用式(4)计算条件概率p(1|x)和p(0|x)的过程:
式(4)中y∈{0,1},0表示该软件模块不存在缺陷,1则相反,表示软件模块中有缺陷。x是目标项目即ant-1.3中的每一个实例,xi是实例的每一个属性,对该实例进行预测,即计算两个条件概率值p(1|x)和p(0|x),若计算的结果p(1|x)>p(0|x),则认为该模块有缺陷,反之,则无缺陷。
- 还没有人留言评论。精彩留言会获得点赞!