一种基于遗传粒子群算法的NURBS曲线拟合方法与流程
本发明涉及nurbs曲线拟合,具体涉及一种基于遗传粒子群算法的nurbs曲线拟合方法。
背景技术:
现代工程设计中经常需要从测量的数据点中获取最合适的曲线或曲面表达,但是这些数据点往往由于各种因素的影响存在误差,所以待求的曲线或曲面不必严格的经过每一个数据点,可以用拟合的方法逼近数据点。由于nurbs曲线具有较好的逼近能力以及局部修改、投影不变等优秀的数学性质,可以非常灵活地表示各类曲线的形状。因此,在测试数据处理、逆向工程和图像处理等工程领域中,nurbs曲线拟合技术得到了广泛的应用。
nurbs曲线描述自由曲线面时相比于nc代码,节省了存储空间;能够最大限度的减小轮廓误差,有效保证刀路的长度和连续性,尽可能地恢复到设计时的理想形状,因此拥有nurbs曲线解析或拟合的数控系统可以满足更多样化的加工需求。目前国外很多先进的数控公司如fanuc、siemens等都有成熟规范的nurbs曲线拟合、规划与插补方法但这些技术处于保密状态,并不对用户开放。
我国是一个制造业大国,为了贯彻落实中国“制造强国”的战略,需要对当前发展现状有基本的认识,也需要有突破当前困境的决心。现阶段我国高端数控系统大多仍然依赖进口,国产数控系统在样条曲线解析、生成以及规划和插补方面仍多有欠缺。为了从根本上解决这些问题,需要开发具有完整nurbs曲线轨
迹生成和规划功能的技术。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于遗传粒子群算法的nurbs曲线拟合方法,将数据点带有法向约束的nurbs曲线拟合问题转化为基于遗传粒子群算法的无约束最优化问题,将节点向量自由化,自适应寻找最优节点向量,最终产生满足法向约束条件的最优逼近曲线。
为实现上述发明目的,本发明的技术方案具体如下:
一种基于遗传粒子群算法的nurbs曲线拟合方法,包括以下步骤:
s1:输入待拟合数据di及其对应法向;
s2:数据点参数化,以及建立有效的适应度函数;
s3:设置遗传粒子群算法的相关参数,包括种群规模pop,终止条件(最大迭代次数maxgen);
s4:初始化粒子位置及速度,这里每一个粒子代表一个节点向量;
s5:根据粒子的位置,通过最小二乘法计算控制顶点,计算每个粒子的适应度值;
s6:对每个粒子,比较其当前位置和它经历过的最好位置pbest,如果当前位置更好,则更新个体极值pbest;
s7:对每个粒子,比较其当前位置和群体中所有粒子所经历过的最好位置gbest,如果这个粒子的位置更好,则更新全局极值gbest;
s8:更新粒子的位置和速度;
s9:对子代中的优秀个体进行交叉和变异操作,得到新的子代个体;
s10:判断迭代终止的条件,如果满足条件,则输出最优节点向量和控制顶点并计算重构曲线,否则转到步骤s5。
进一步地,所述步骤s1中,数据拟合的数学模型如下:
一条p次b样条曲线可以表示为:
其中,p表示b样条次数,{pi},i=0,1,...,n是曲线的控制顶点,ni,p(u)表示p次b样条在节点向量u上的基函数,其定义由deboor-cox递推公式给出:
由于上式中可能出现分子、分母同时为0的情况,因此规定
给定m+1个数据点q0,q1,…,qm,在p≥1的前提下,让逼近曲线经过首末两点需要满足的条件是:
q0=c(0),qm=c(1)
对其余m-1个离散数据点qk,k=1,...,m-1进行最小二乘拟合,确保曲线误差最小即下式最小:
该公式是最小二乘法近似拟合曲线的数学模型,这条曲线并不是精确地通过所有数据点,为了求解这条近似曲线,令
构造函数并推导如下:
函数f是一个关于变量p1,...,pn-1的标量函数,为了得到f的最小值,需要对其求偏导:
令偏导数为0,可得:
当l=1,2,...,n-1时,上式成立,可得线性方程组:
ntr=(ntn)p
为了保证方程有且仅有唯一的最小二乘解,对矩阵n求moore-penrose广义逆;对于带法向约束的问题,只需在原有模型的基础上添加法向约束条件如下:
其中di表示数据点对应的参数值,法向约束的几何意义为参数化后的数据点在曲线上的切线矢量与对应的法向约束矢量li垂直。
进一步地,所述步骤s2中,数据点的参数化方式为向心参数化。
进一步地,所述步骤s4中,粒子的初始化方式为随机初始化。
进一步地,所述步骤s6中,粒子通过跟踪两个信息来更新自己:一个是粒子本身所找到的最优解,叫做个体极值点(用pbest表示);另一个是整个种群目前找到的最优解,称为全局极值点(用gbest表示);粒子i的信息可以用d维向量表示,位置表示为xi=(xi1,xi2,…,xid)t,速度为vi=(vi1,vi2,…,vid)t。
进一步地,所述步骤s8中,粒子的位置和速度更新方式为:
其中,ω是惯性权重;
进一步地,所述步骤s9中,交叉方式为均匀交叉,变异方式为高斯变异。
与现有技术相比,本发明的有益效果:
1、本发明提供的基于遗传粒子群算法的nurbs曲线拟合方法通过罚函数的方法将带法向约束的非线性优化问题转化为无约束最优化问题,建立了一个与数据点和法向同时相关的适应度函数,然后利用遗传粒子群算法自适应的调节节点向量,迭代进化直至找到最优的节点向量。
2、本发明的方法生成的拟合曲线在逼近数据点的同时,亦能够满足数据点处的法向约束条件。
3、本发明通过对节点向量的自适应调整,实现了数据点的精确拟合,提高了nurbs曲线拟合的准确性和可靠性。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明。
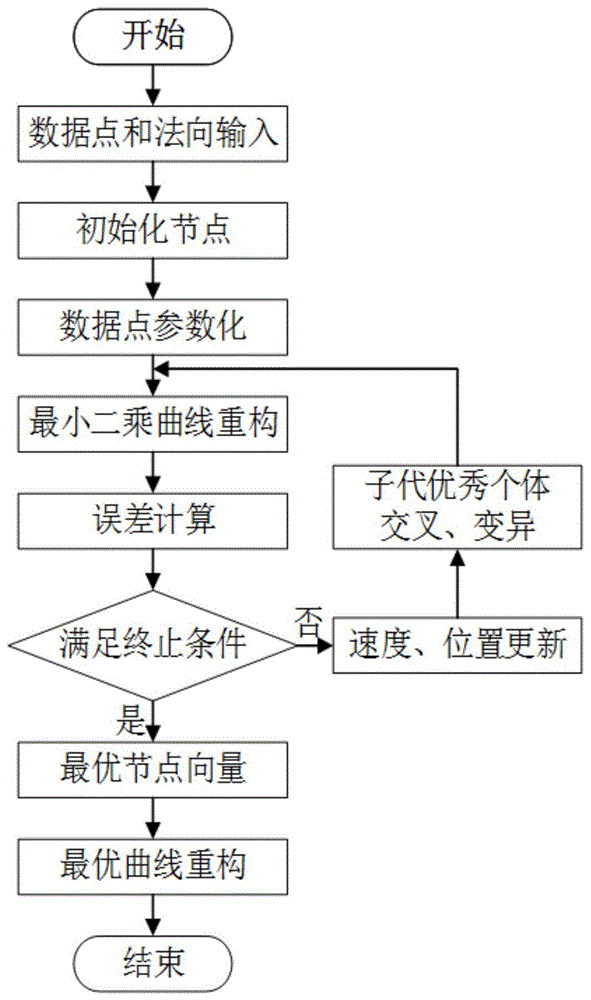
图1是本发明实施例中的nurbs曲线拟合方法的流程图;
图2是本发明实施例中的基于遗传粒子群算法的nurbs曲线拟合方法对未知曲面的测量数据点进行曲线拟合的效果图。
图3是本发明实施例中的基于遗传粒子群算法的nurbs曲线拟合方法对未知曲面的测量数据点进行曲线拟合的效果图。
图4是本发明实施例中的基于遗传粒子群算法的nurbs曲线拟合方法对未知曲面的测量数据点进行曲线拟合的效果图。
图5是本发明实施例中的基于遗传粒子群算法的nurbs曲线拟合方法对未知曲面的测量数据点进行曲线拟合的效果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供了一种基于遗传粒子群算法的nurbs曲线拟合方法,该方法流程图如图1所示,包括以下步骤:
步骤1:输入待拟合数据di及其对应法向。
步骤2:数据点参数化,以及建立有效的适应度函数;
步骤3:设置遗传粒子群算法的相关参数,包括种群规模pop,终止条件(最大迭代次数maxgen);
步骤4:初始化粒子位置及速度,这里每一个粒子代表一个节点向量;
步骤5:根据粒子的位置,通过最小二乘法计算控制顶点,计算每个粒子的适应度值;
步骤6:对每个粒子,比较其当前位置和它经历过的最好位置pbest,如果当前位置更好,则更新个体极值pbest;
步骤7:对每个粒子,比较其当前位置和群体中所有粒子所经历过的最好位置gbest,如果这个粒子的位置更好,则更新全局极值gbest;
步骤8:更新粒子的位置和速度;
步骤9:对子代中的优秀个体进行交叉和变异操作,得到新的子代个体;
步骤10:判断迭代终止的条件,如果满足条件,则输出最优节点向量和控制顶点并计算重构曲线,否则转到步骤s5。
进一步,所述步骤1中,数据拟合的数学模型如下:
一条p次b样条曲线可以表示为:
其中,p表示b样条次数,{pi},i=0,1,...,n是曲线的控制顶点,ni,p(u)表示p次b样条在节点向量u上的基函数,其定义由deboor-cox递推公式给出:
由于公式中可能出现分子、分母同时为0的情况,因此规定
给定m+1个数据点q0,q1,…,qm,在p≥1的前提下,让逼近曲线经过首末两点需要满足的条件是:
q0=c(0),qm=c(1)
对其余m-1个离散数据点qk,k=1,...,m-1进行最小二乘拟合,确保曲线误差最小即下式最小:
该公式是最小二乘法近似拟合曲线的数学模型,这条曲线并不是精确地通过所有数据点,为了求解这条近似曲线,令
构造函数并推导如下:
函数f是一个关于变量p1,...,pn-1的标量函数,为了得到f的最小值,需要对其求偏导:
令偏导数为0,可得:
当l=1,2,...,n-1时,上式成立,可得线性方程组:
ntr=(ntn)p
为了保证方程有且仅有唯一的最小二乘解,对矩阵n求moore-penrose广义逆;对于带法向约束的问题,只需在原有模型的基础上添加法向约束条件如下:
其中di表示数据点对应的参数值,法向约束的几何意义为参数化后的数据点在曲线上的切线矢量与对应的法向约束矢量li垂直。
进一步,所述步骤2中,数据点的参数化方式为向心参数化。
进一步,所述步骤4中,粒子的初始化方式为随机初始化。
进一步,所述步骤6中,粒子通过跟踪两个信息来更新自己:一个是粒子本身所找到的最优解,叫做个体极值点(用pbest表示);另一个是整个种群目前找到的最优解,称为全局极值点(用gbest表示);粒子i的信息可以用d维向量表示,位置表示为xi=(xi1,xi2,…,xid)t,速度为vi=(vi1,vi2,…,vid)t。
进一步,所述步骤8中,粒子的位置和速度更新方式为:
其中,ω是惯性权重;
进一步,所述步骤9中,交叉方式为均匀交叉,变异方式为高斯变异。
实施例1:
以参数曲线
实施例2:
以参数曲线
实施例3:
以参数曲线
实施例4:
以参数曲线
最后所应说明的是,以上具体实施方式仅用以说明本发明的技术方案而非限制,尽管参照实例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!