一种基于改进随机森林的比特币地址分类方法与流程
本发明属于数据挖掘和机器学习技术领域,特别是涉及一种基于改进随机森林的比特币地址分类方法。
背景技术:
随着数字货币市场的不断发展,比特币作为数字货币中的典型代表,应用越来越广泛。比特币地址是用户参与服务的唯一身份标识,但是由于比特币本身具有匿名性特点,这也为诸如洗钱等非法活动提供了便利。在这种情况下,为了更好地了解比特币的用途,通过比特币地址来说明用户交易行为显得至关重要,但比特币的匿名性却为此带来了挑战,因此如何在系统中快速对一个比特币地址进行分类,即利用较少的统计特征,从而判断该地址是被非法用户所有还是属于正常交易地址,是解决比特币市场难于监管的一个重要方法。
目前,比特币地址的分类方法包括以下几种:
交易图分析法:目前最常用的比特币地址分类方法就是交易图分析法,常见的一种构图方法是将交易视为图的点集,图的边表示两笔交易间经过某一地址所流通的比特币数量,利用历史交易记录,从而能够构建出整个交易图,从交易图中能够提取比特币地址的一系列统计特征,利用常用的机器学习分类算法就能以较高的准确率对地址进行分类,一般情况下交易图越完善,即越接近实际所有的交易,分类的准确率会越高,通常准确率都在90%以上,实际上不同的研究者出于不同的目的会选择不一样的构图方式,但无疑最终都会形成一张超大的图。
启发式地址聚类法:启发式地址聚类在一定程度上也能够识别一个比特币地址,该方法基于一个经典的假设:在同一笔交易中,所有的输入地址都是由一个用户所掌握的。由于比特币系统协议会在交易的过程中自动生成找零地址,用于接收交易中的找零资金,因此进一步的地址聚类方法会将找零地址与输入地址折叠成一个更大的交易实体,只要其中的一个地址类别暴露就可以对该交易实体所有的地址进行识别。
机器学习分类方法:目前一部分研究人员着力于直接从交易历史记录中提取相关地址的统计特征,区别于交易图分析法大大减少了构图工作量,利用经典的机器学习分类方法也能够以较高的准确率对地址进行识别,通常准确率在80%以上。
但现有的交易图分析法收集数据方法过于繁复,需要先利用比特币历史交易记录根据自己定义的构图规则形成一张图,再从中提取特征,往往不同的研究者构图的方法各不相同,但无疑最终都会形成一张超大的图,同时现有的多分类方法中对于地址提取的特征较多,使数据收集的难度过大,耗费时间过长,这为快速分类一个比特币地址制造了难度。
现有的基于启发式的地址聚类方法存在两个缺陷:一是该方法只针对特定类型交易地址有效,如多个交易输入可以被聚成一类,但是对于单一输入的交易,当该输入地址在未来交易记录中从未出现过时,将无法归类到任何一类。二是基于找零地址的启发式聚类方法由于受到比特币协议的变化,如找零地址使用比特币钱包自动生成的新地址或用户指定的新地址,因此该方法不能完全聚类出交易输入用户控制的地址群。
现有的机器学习分类方法对于从交易历史记录中提取什么特征,提取多少特征尚未形成一致观点,因此不同的研究人员会提取到不同数量和不同种类的特征,事实上这种盲选特征会造成实际特征中有很多的冗余特征,增加了学习器的训练开销,无法为一个需要分类的地址的特征提取提供参考。
技术实现要素:
为了解决上述问题,本发明的目的在于提供了一种基于改进随机森林的比特币地址分类方法。
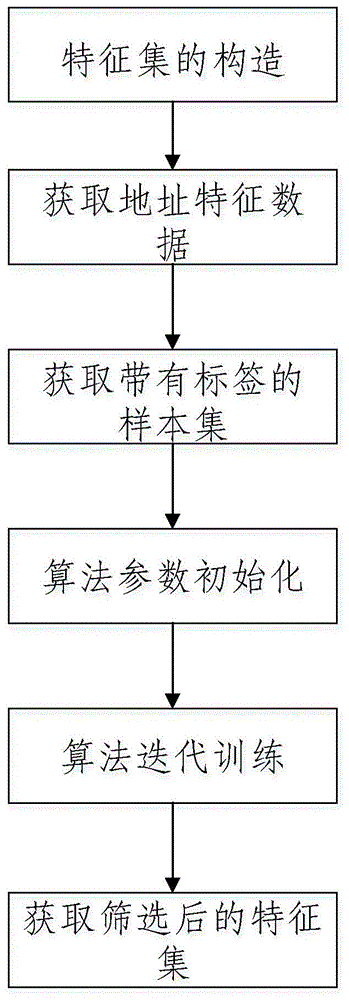
为了达到上述目的,本发明提供的基于改进随机森林的比特币地址分类方法包括按顺序进行的下列步骤:
s1:从区块链的历史交易记录中提取地址原始特征并添加到现有机器学习分类方法所使用的特征集中,构建一个更大的特征集;
s2:解析原始区块数据而获得比特币地址,并从上述构建的特征集中提取出与地址相关的统计特征信息而构成数据集,所获得数据集的大小与操作者选取的时间段以及在这个时间段交易数量的多少有关;
s3:利用爬虫技术,为上述数据集打上标签,从而获得带有标签的样本集,并根据需要将地址分为多个不同的类别;
s4:初始化学习器的参数,包括随机森林参数基分类器数量l、利用特征分裂节点时候选特征子集的数量l,以及算法准确率变化阈值δ;
s5:初始化学习器中的重要特征集
s6:用上述带有标签的样本集迭代上述初始化后的学习器,直到算法准确率变化范围超过算法准确率变化阈值δ;
s7:获取重要特征集
s8:在实际应用中,对于任一需要分类的地址,只需从比特币交易记录中提取出少量的关键特征,然后将这些关键特征输入到上述已训练好的学习器中,学习器的输出即为该比特币地址的交易类型分类。
在s1中,所述的从区块链的历史交易记录中提取地址原始特征并添加到现有机器学习分类方法所使用的特征集中,构建一个更大的特征集的具体方法如下:
s101:设定如下用于提取地址原始特征的规则:地址存活时间单位为天,存活时间不足24小时视为1天,其余情况下存活天数向下取整;对于存在自找零交易,即给定地址同时出现在交易的输入和输出中,将其视为对应于该地址的输出交易;为了保留原始信息同时降低提取特征的困难,将比特币交易的数量单位设定为btc;
s102:按照上述规则,从区块链的历史交易记录中提取包括截至目前为止地址存活时间在内的地址原始特征;
s103:对上述地址原始特征进行线性组合。
在s6中,所述的用上述带有标签的样本集迭代上述初始化后的学习器,直到算法准确率变化范围超过算法准确率变化阈值δ的具体方法如下:
s601:利用上述带有标签的样本集迭代训练学习器,并将该轮训练时学习器的分类准确率加入到算法准确率集合
s602:计算在该轮训练中每一个特征j的全局权重
s603:将所有特征按照权重大小进行降序排列,并将前
s604:更新重要特征集
s605:判断算法准确率集合
s606:执行s601,利用上述更新后的特征向量
在s602中,所述的计算在该轮训练中每一个特征j的全局权重
s60201:每一个基分类器在分裂节点i的时候,先根据以下公式计算该分裂节点的信息熵:
其中p(c)表示在该分裂节点地址类别为c的概率;
s60202:根据上述信息熵计算分裂节点i的特征候选子集中每一个特征j的分裂评分,计算公式如下:
其中v表示按照特征j分裂节点后子节点的数量,节点的分裂按分裂评分
s60203:利用上述分裂评分计算每个特征j在每一个基分类器ζ中的局部权重:
其中n_node表示基分类器ζ中非叶子节点的数量;
s60204:利用袋外数据算出每一个基分类器ζ的分类准确率,进而按下式计算出每一个基分类器ζ的权重:
其中accζ表示基分类器ζ的分类准确率;
s60205:基于上述局部权重和基分类器的权重计算出每个特征j在整个随机森林中的全局权重:
在s604中,所述的更新重要特征集
s60401:计算不重要特征集
s60402:将不重要特征集
s60403:如果不重要特征集
s60404:将更新后的不重要特征集
本发明提供的基于改进随机森林的比特币地址分类方法具有如下有益效果:(1)从比特币市场监管角度将判断用户是否参与非法交易问题转变成比特币地址分类问题,有助于完善市场监管;(2)本发明直接通过区块链的历史交易记录获取样本集,而不需要先去形成一张超大的交易图,再从图中提取特征,这样就大大降低了数据的收集难度;(3)基于改进随机森林的比特币地址分类方法能够以84%左右的准确率对比特币地址进行分类,仅仅只需要很少的统计特征;(4)地址分类方法不仅能很好的对地址进行分类,同时对构建的大量统计特征进行去冗余,当学习器完成最终的训练之后,就能获得最终需要提取的关键特征,这对于一个需要进行识别的地址而言,既减少了数据收集时间,也降低了地址识别的时间开销。
附图说明
图1为本发明提供的基于改进随机森林的比特币地址分类方法流程图。
图2为本发明提供的获取带有标签的数据集流程图。
图3为本发明提供的算法迭代训练过程流程图。
图4为本发明提供的计算每个特征的全局权重流程图。
图5为本发明提供的特征集和特征向量更新过程流程图。
具体实施方式
下面结合附图和具体实施例对本发明提供的基于改进随机森林的比特币地址分类进行详细说明。
如图1—图5所示,本发明提供的基于改进随机森林的比特币地址分类方法包括按顺序进行的下列步骤:
s1:从区块链的历史交易记录中提取地址原始特征并添加到现有机器学习分类方法所使用的特征集中,构建一个更大的特征集;
具体方法如下:
s101:设定如下用于提取地址原始特征的规则:地址存活时间单位为天,存活时间不足24小时视为1天,其余情况下存活天数向下取整;对于存在自找零交易,即给定地址同时出现在交易的输入和输出中,将其视为对应于该地址的输出交易;为了保留原始信息同时降低提取特征的困难,将比特币交易的数量单位设定为btc;
s102:按照上述规则,从区块链的历史交易记录中提取包括截至目前为止地址存活时间在内的地址原始特征;
s103:对上述地址原始特征进行线性组合,以进一步丰富统计特征,如该地址每天转出多少btc。
s2:解析原始区块数据而获得比特币地址,并从上述构建的特征集中提取出与地址相关的统计特征信息而构成数据集,所获得数据集的大小与操作者选取的时间段以及在这个时间段交易数量的多少有关;
s3:利用爬虫技术,为上述数据集打上标签,从而获得带有标签的样本集,并根据需要将地址分为多个不同的类别;
s4:初始化学习器的参数,包括随机森林参数基分类器数量l、利用特征分裂节点时候选特征子集的数量l,以及算法准确率变化阈值δ;
s5:初始化学习器中的重要特征集
s6:用上述带有标签的样本集迭代上述初始化后的学习器,直到算法准确率变化范围超过算法准确率变化阈值δ;
具体方法如下:
s601:利用上述带有标签的样本集迭代训练学习器,并将该轮训练时学习器的分类准确率加入到算法准确率集合
s602:计算在该轮训练中每一个特征j的全局权重
s603:将所有特征按照权重大小进行降序排列,并将前
s604:更新重要特征集
s605:判断算法准确率集合
s606:执行s601,利用上述更新后的特征向量
在s602中,所述的计算在该轮训练中每一个特征j的全局权重
s60201:每一个基分类器在分裂节点i的时候,先根据以下公式计算该分裂节点的信息熵:
其中p(c)表示在该分裂节点地址类别为c的概率;
s60202:根据上述信息熵计算分裂节点i的特征候选子集中每一个特征j的分裂评分,计算公式如下:
其中v表示按照特征j分裂节点后子节点的数量,节点的分裂按分裂评分
s60203:利用上述分裂评分计算每个特征j在每一个基分类器ζ中的局部权重:
其中n_node表示基分类器ζ中非叶子节点的数量;
s60204:利用袋外数据算出每一个基分类器ζ的分类准确率,进而按下式计算出每一个基分类器ζ的权重:
其中accζ表示基分类器ζ的分类准确率;
s60205:基于上述局部权重和基分类器的权重计算出每个特征j在整个随机森林中的全局权重:
在s604中,所述的更新重要特征集
s60401:计算不重要特征集
s50402:将不重要特征集
s60403:如果不重要特征集
s60404:将更新后的不重要特征集
s7:获取重要特征集
s8:在实际应用中,对于任一需要分类的地址,只需从比特币交易记录中提取出少量的关键特征,然后将这些关键特征输入到上述已训练好的学习器中,学习器的输出即为该比特币地址的交易类型分类。
- 还没有人留言评论。精彩留言会获得点赞!