基于双向长短期记忆神经网络的共享单车流量预测方法与流程
本发明属于机器学习研究领域,具体涉及一种基于双向长短期记忆神经网络的共享单车流量预测方法。
背景技术:
近年来,共享单车产业迅速繁荣,街头巷尾出现了越来越多的共享单车,解决了人们短距离出行的需要。然而,为了抢夺市场份额,企业激进投放大量共享单车,但又疲于进行运维管理,产生了乱停乱放的情况,为城市管制带来了许多新的问题。近年来,深度学习方法越来越多地应用于交通工程的不同领域的研究。除了出行需求预测之外,深度学习方法还被广泛运用于短期交通流量预测和交通速度预测的研究。本文旨在运用深度学习的手段结合两年的共享单车租赁情况的历史数据,对未来共享单车的流量进行预测,用以限制市场上的单车量,达成共享单车的适宜投放。
技术实现要素:
本发明的目的在于提供一种基于双向长短期记忆神经网络的共享单车流量预测方法,对未来共享单车的流量进行预测,用以限制市场上的单车量,达成共享单车的适宜投放。
为实现上述目的,本发明的技术方案是:一种基于双向长短期记忆神经网络的共享单车流量预测方法,包括如下步骤:
步骤s1、采集共享单车租赁量数据,并对共享单车租赁量数据进行可视化分析,挖掘出对共享单车租赁量影响的属性;
步骤s2、依据步骤s1挖掘出的对共享单车租赁量影响的属性,对原始数据的哑变量和冗余变量进行处理,并进行归一化操作;
步骤s3、依据步骤s2处理后的数据,构建blstm预测模型,预测未来时间段的共享单车流量数据。
在本发明一实施例中,步骤s1中,共享单车租赁量数据是以小时为单位进行统计的共享单车租赁量数据。
在本发明一实施例中,步骤s1中,对共享单车租赁量数据进行可视化分析,挖掘出对共享单车租赁量影响的属性的实现方式为:使用pandas库中的函数导入共享单车租赁量数据,而后通过matplotlib库中的plot函数绘制共享单车租赁量和各个属性的关系图,从而挖掘出对共享单车租赁量影响的属性。
在本发明一实施例中,根据步骤s1的可视化分析的结果,对影响共享单车租赁量的属性进行处理,所述步骤s2具体实现方式为:首先采用dropna函数对缺失数据进行清洗,而后运用get_dummies进行哑变量处理,然后使用concat将原数据与处理完的数据进行拼接,再而使用drop删除原数据中的哑变量以及冗余变量,最后采用归一化函数将处理后的数据进行归一化处理转换成无量纲数据。
在本发明一实施例中,步骤s3中,所述blstm预测模型为时间步长为12的blstm预测模型,将步骤s2处理后得到的数据集以8:2的比例划分为训练集和测试集,将训练集中过去十二个小时的数据作为一个输入,预测一个输出,以此类推,每次将时间向后平移一个小时,按照此规律扩充训练集用以训练时间步长为12的blstm预测模型,而后,将测试集中的过去十二个小时的数据作为输入,预测未来一个小时的共享单车流量数据。
在本发明一实施例中,步骤s3中,预测未来时间段的共享单车流量数据时需对blstm预测模型预测的结果进行反归一化处理。
在本发明一实施例中,步骤s3之后,利用平均绝对误差、平均绝对百分比误差、均方根误差、皮尔逊相关系数对预测结果进行评估。
相较于现有技术,本发明具有以下有益效果:本发明方法能够对未来共享单车的流量进行预测,用以限制市场上的单车量,达成共享单车的适宜投放。
附图说明
图1浮点型数据散点图。
图2枚举型数据直方图。
图3blstm网络结构图。
图4模型实现流程图。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
本发明提供了一种基于双向长短期记忆神经网络的共享单车流量预测方法,包括如下步骤:
步骤s1、采集共享单车租赁量数据,并对共享单车租赁量数据进行可视化分析,挖掘出对共享单车租赁量影响的属性;
步骤s2、依据步骤s1挖掘出的对共享单车租赁量影响的属性,对原始数据的哑变量和冗余变量进行处理,并进行归一化操作;
步骤s3、依据步骤s2处理后的数据,构建blstm预测模型,预测未来时间段的共享单车流量数据。
以下为本发明的具体实现过程。
本发明是一种基于双向长短期记忆神经网络的共享单车流量预测方法。
具体包含以下设计过程:
(1)对原始数据进行探索并分析影响共享单车使用量的各种属性。对原始数据中的哑变量和冗余变量等进行处理,并进行归一化操作,为建模进行数据准备。
(2)对双向长短期记忆(bi-directionallongshort-termmemory,blstm)预测模型进行研究,在此基础上设计并实现了blstm预测模型。为了验证模型的性能,选取人工神经网络(artificialneuralnetwork,ann),循环神经网络(recurrentneuralnetwork,rnn)以及长短期记忆(longshort-termmemory,lstm)网络作为对比模型。
(3)利用平均绝对误差(meanabsoluteerror,mae)、平均绝对百分比误差(meanabsolutepercenterror,mape)、均方根误差(rootmeansquarederror,rmse)和皮尔逊相关系数(pearson)评价函数来检验模型的性能并对预测结果进行误差分析。
以下为具体技术方案:
1、可视化分析:
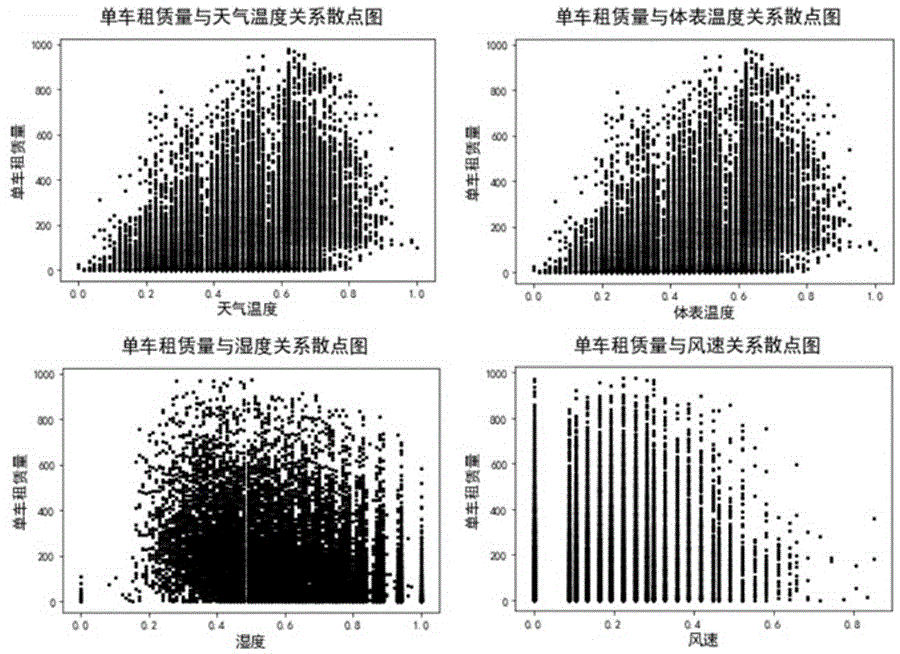
原始数据是从uci机器学习库中获取的数据集bikesharingdatasetdataset。其中具有两份数据,一份是以天为单位进行统计的共享单车租赁量数据,一份是以小时为单位进行统计的共享单车租赁量数据。实验使用的数据为以小时为单位进行统计的数据。本发明使用pandas库中的函数导入数据,该数据的数据类型存在着整型,浮点型以及枚举型。本发明使用matplotlib库中的plot函数绘制租赁量和各个属性的关系图,对数据进行可视化分析,从而挖掘出各属性对租赁量的影响程度。如图1所示,在天气温度、体表温度、湿度散点图中,边缘处存在稀疏点,但全部数据点大都聚集于某个界限中;在风速散点图中可以看出,风速越大,单车租赁量越少。如图2所示,季节直方图显示共享单车租赁数量在秋天时最多;天气类别直方图体现了人们更愿意在天气晴朗的时候租借共享单车;从月份直方图可以看出4-9月共享单车租赁数量较多;小时直方图显示下午时间段共享单车租赁人数相对较多,凌晨共享单车租赁人数最少,而人们在上班高峰时间段的单车租赁量达到最高。
2、数据预处理:
根据可视化分析的结果,对各个影响共享单车租赁量的属性进行处理。本发明采用dropna函数对缺失数据进行清洗,即一条记录如有缺失属性,则删除整条记录,运用get_dummies进行哑变量处理,然后使用concat将原数据与处理完的数据进行拼接,最后使用drop删除原本数据中的哑变量属性以及对于训练不起任何作用的变量。将预处理后得到的60个属性都作为特征属性,将共享单车租赁量作为目标属性。由于租赁量、临时用户数、注册用户数等属性取值范围从零到几百不等,为了提高模型的精度且加快收敛速度,本发明采用归一化函数,将数据装换成无量纲数据,压缩到0到1之间。归一化函数公式如下。
其中,x表示原始数据,min、max分别表示此属性数据中的最小值和最大值,x*表示归一化之后的无量纲数据。
3、blstm神经网络的设计:
作为一种时间循环神经网络,lstm适宜对时间序列内间隙和延误相应比较大的事项进行预测和处理。lstm中存在一个鉴定信息是否有效的“处理器”,叫做cell。一个cell中包含输入门、遗忘门和输出门。lstm得到一个信息后,按照规则判定其有效与否,契合算法认证的将被保留,不相合的将经过遗忘门丢弃。
(1)细胞状态(ct)
ct表示t时刻的记忆内容,用来存储关键内容。细胞状态是lstm的核心,如同传送带一般贯通整个细胞,只存在少量的分支,保障信息不变地穿过整个网络。
(2)遗忘门
首先确定细胞状态应该遗忘哪些内容,这一步操作是利用遗忘门的sigmoid单元实现的。遗忘门操纵忘记上个时刻细胞状态ct-1的信息,运用sigmoid激活函数,以上个时刻的隐藏状态ht-1和本时刻的xt作为输入,输出一个0~1之间的向量表示ct-1中需要留下和遗忘的信息量。
ft=σ(wf·[ht-1,xt]+bf)
(3)输入门
其次确定细胞状态应该增添哪些新的内容。输入门对此刻的输入进行处理,然后决断需要更新的内容,最后进行细胞状态的更新。此操作分为两个步骤,首先通过含有sigmoid层的输入门确定细胞状态需要增添哪些新信息,然后把新信息变换为进入细胞状态所需的形式。其次运用tanh函数形成新的候选细胞信息
it=σ(wi·[ht-1,xt]+bi)
通过遗忘门和输入门,把旧的细胞信息ct-1更新成新的细胞信息ct。更新的准则就是利用遗忘门决定丢弃一些旧细胞内容,利用输入门决定添加一部分候选细胞内容
(4)输出门
最后考虑细胞状态保留的内容决定细胞的哪些状态特征作为输出,即有取舍地输出细胞状态保留的信息。首先通过输出门的sigmoid层判断需要输出的内容,其次再经过tanh层处理细胞状态的内容获得一个值处在-1~1之间的向量,把它们相乘以获得最后的输出。
ot=σ(wo·[ht-1,xt]+bo)
其中,ft表示遗忘门的值,it表示输入门的值,ot表示输出门的值,w为随机初始化权重矩阵,b为偏差矢量矩阵,σ表示sigmoid函数,
图3所示为blstm网络结构,输出层联结着向前隐藏层和向后隐藏层,其中含有共享权值w1-w6。在输入序列的所有时间步长可用的问题中,blstm在输入序列上训练两个而不是一个lstm。输入序列中的第一个是原样的,第二个是输入序列的反转副本。这可以为网络提供额外的上下文,进行更快、更充分的学习。
在向前隐藏层由时刻1到时刻t正向算一次,获得各个时刻向前隐藏层的输出并将其保存。在向后隐藏层从时刻t到时刻1反向算一次,获取各个时刻向后隐含层的输出并保留。最终于各个时刻将向前隐藏层和向后隐藏层的对应时刻输出的结果相结合从而计算出最后的输出,数学公式表示为:
ht=f(w1xt+w2ht-1)
h′t=f(w3xt+w5h′t+1)
ot=g(w4ht+w6h′t)
其中,ht为t-1时刻隐藏层的正向输出,h′t为t+1时刻隐藏层的反向输出,ot为t时刻最终的输出,f为嵌套lstm单元函数,g为relu函数,w1-w6为对应的权重矩阵。
4、blstm模型参数的设计:
在构建blstm预测模型时,首先构建嵌套lstm神经单元,然后在嵌套lstm单元基础上构建双向嵌套lstm神经网络。
(1)输入层设置:由于特征属性数量为60,设置输入的形状为(t,60),t为时间步长。
(2)输出层设置:输出层采用全连接的层,由于目标属性数量为1,设置输出维度为1。
(3)隐藏层设置:利用双向层包装lstm隐藏层,构造两个隐藏层的副本,一个为原本的输入序列,另一个为输入序列反转后的副本,然后连接lstm的输出。设置两层blstm层,每层的神经元个数都为120。
(4)激活函数设置:常用的激活函数有sigmoid和tanh函数,然而这两个函数在两端的导数值为零,会导致梯度消失的现象。于是本发明采用relu函数作为网络的激活函数,其计算公式如下:
relu=max(0,x)
相比于sigmoid和tanh函数,relu函数形式更加简单,当x取值低于0的时候,函数值恒为0,神经元不会被激活;当x取值大于0的时候,函数则是一个一次函数。因此,在relu的作用下,只有部分神经元被激活,促使网络的稀疏性,便于网络的训练。简单的结构使得relu具有更快的收敛速度且有效的避免了梯度消失问题。
(5)损失函数设置:为了使模型的预测值能够更加接近真实值,采用均方误差作为预测模型的损失函数,其数学表达式如下:
其中,n为训练样本的数量,
(6)选择合并模式,即在传递到下一层前,组合正向和反向输出的模式。blstm层的输出能够采取四种合并模式进行组合:
①sum:输出相加。
②mul:输出相乘。
③concat:输出的连接。
④ave:输出的平均值。
四种合并模式将会产生不一样的模型性能,依照具体序列的预测问题各有差别。由于是进行回归预测,最终只有1个输出,因此本发明采用ave模式。
5、模型的训练和实现:
(1)设置神经网络学习目标:学习目标为最小平方误差、优化方法为adma、评量指针为平均绝对误差。
(2)设置训练参数:迭代次数为200次,一次训练所选取的样本数为16,隐层结点个数为120。
(3)将预处理后得到的新数据集以8:2的比例划分为训练集和测试集,将每十二条数据作为输入,预测一个输出,以此类推,每次将时间向后平移一个小时,按照此规律扩充训练集用以训练模型。
(4)在训练时,显示训练过程、训练错误率和神经网络权重,训练结束后用plot函数绘制预测结果图。
(5)将测试数据集代入模型进行预测,并取得预测结果。
具体流程图如图4所示。
6、数据反归一化处理:
为了加快模型的收敛速度,并且提高模型的精度,在数据预处理阶段采用了归一化,将待处理数据统一映射到0~1内进行操作。因此,需要采用反归一化的方式,将数据还原成原本的量纲,以便于后续进行预测结果分析。计算公式如下:
y=x*(max-min)+min
其中,y为反归一化后的数据。
7、评价指标的设计:
为了验证本发明的有效性,利用平均绝对误差(meanabsoluteerror,mae)、平均绝对百分比误差(meanabsolutepercenterror,mape)、均方根误差(rootmeansquarederror,rmse)来检验模型的性能并对预测结果进行误差分析,利用皮尔逊相关系数(pearson)来评估预测数据集和原始数据集的线性相关程度。计算公式如下所示。
其中,n为训练样本的数量,
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!