一种基于信息融合的人脸特征点定位方法及系统与流程
本发明涉及人脸识别技术领域,特别涉及一种基于信息融合的人脸特征点定位方法及系统。
背景技术:
人脸特征点定位是指在人脸图像上,通过机器视觉技术精确的定位出脸部的关键特征点位置,关键特征点包括嘴角、眼角、鼻尖等器官位置以及脸部轮廓等位置。人脸特征点定位是人脸识别系统、表情识别系统和人脸属性分析系统等应用领域的技术基础,人脸特征点定位的质量好坏会直接影响到后续工作的可靠性和精准度。
近20年来,人脸特征点定位算法一直是机器视觉领域的研究热点,涌现出很多经典算法,具体算法可以分为以下几类:
(1)基于传统技术的人脸特征点定位算法,该类算法主要基于人脸的统计形状模型方法和级联回归的方法,如经典的算法:asm、aam、sdm、lbf等。该类算法的特点是利用人脸器官的几何位置关系,采用统计方法和级联优化的方法获取最终的人脸特征点位置,由于算法提取人脸特征的表达能力有限,并且对人脸特征点之间的形状约束并没有考虑,该类算法的特征点定位精准度误差较大。
(2)基于深度学习的人脸特征点定位算法,近年来,深度学习技术凭借着可以模拟人类大脑神经网络,能够进行精确的非线性预测,各个领域都得到了广泛的关注和应用,出现了一批经典的人脸特征点定位网络框架,如记忆下降法(mnemonicdescentmethod,mdm)、面部地标探测器(apracticalfaciallandmarkdetectordensenet,pfld),基于深度多任务学习的人脸标志点检测(faciallandmarkdetectionbydeepmulti-tasklearning,tcdcn)等。该类算法的特点是利用卷积神经网络模型抓取人脸的深层语义特征,利用这些深层语义特征,或基于多分支任务训练模式,或基于级联多个神经网络模型迭代优化训练模式,获取最终的人脸特征点位置。该类算法相对于传统技术的人脸特征点定位算法,人脸特征点定位精准度有很大的提升,但是特征点定位主要利用的是人脸的深层语义信息,而深层语义信息对于人脸器官细节信息不敏感,导致人脸特征点的定位存在一定的误差。
技术实现要素:
本发明的目的在于克服上述背景技术存在的缺陷,提高人脸特征点定位的精准性。
为实现以上目的,一方面,本发明采用一种基于信息融合的人脸特征点定位方法,包括:
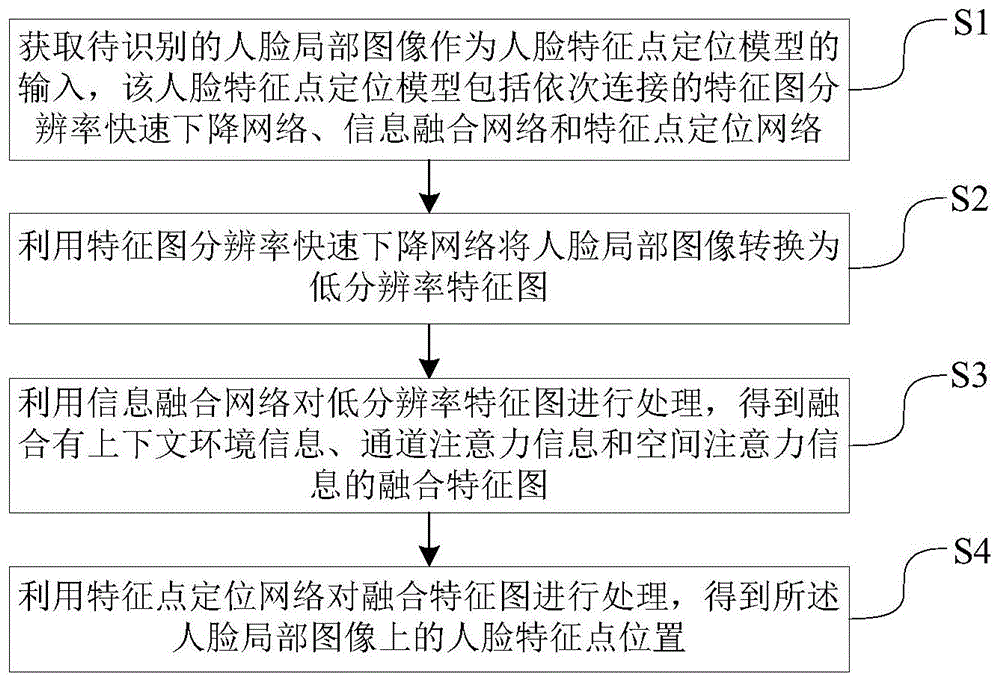
获取待识别的人脸局部图像作为人脸特征点定位模型的输入,该人脸特征点定位模型包括依次连接的特征图分辨率快速下降网络、信息融合网络和特征点定位网络;
利用特征图分辨率快速下降网络将人脸局部图像转换为低分辨率特征图;
利用信息融合网络对低分辨率特征图进行处理,得到融合有上下文环境信息、通道注意力信息和空间注意力信息的融合特征图;
利用特征点定位网络对融合特征图进行处理,得到所述人脸局部图像上的人脸特征点位置。
进一步地,所述特征图分辨率快速下降网络包括卷积层conv0和最大值池化层maxpool0,卷积层conv0的输入为所述人脸局部图像、输出与最大值池化层maxpool0连接,最大值池化层maxpool0输出为所述低分辨率特征图。
进一步地,所述信息融合网络包括依次连接的信息融合模块rcam0、rcam1、rcam2和rcam3,信息融合模块rcam0的输入为所述低分辨率特征图,信息融合模块rcam3的输出为所述融合特征图;
每个信息融合模块包括依次连接上下文环境信息模块、综合注意力模块、拼接层concat和卷积层conv2,拼接层concat的输入连接最大值池化层maxpool1的输出,上下文环境信息模块和最大值池化层maxpool1输入为上一信息融合模块的输出或所述特征图分辨率快速下降网络的输出。
进一步地,所述上下文环境信息模块包括合并层contextsum、卷积层contextconv0、contextconv1_0、contextconv2_0、contextconv3_0、contextconv1_1、contextconv2_1、contextconv3_1、contextconv2_2、contextconv3_2、contextconv3_3以及contextconv4;
卷积层contextconv0、contextconv1_0、contextconv2_0和contextconv3_0作为所述上下文环境信息模块的输入层,卷积层contextconv1_0的输出接卷积层contextconv1_1,卷积层contextconv2_0的输出接卷积层contextconv2_1的输入,卷积层contextconv2_1的输出接卷积层contextconv2_2的输入,卷积层contextconv3_0的输出依次经卷积层contextconv3_1、contextconv3_2与contextconv3_3的输入连接;
卷积层contextconv0、contextconv1_1、contextconv2_2和contextconv3_3的输出均与合并层contextsum连接,合并层contextsum的输出与卷积层contextconv4的输入连接,卷积层contextconv4的输出与所述综合注意力模块的输入连接。
进一步地,所述综合注意力模块包括通道注意力模块和空间注意力模块,通道注意力模块包括基于特征图宽度和高度维度的全局均值池化层globalavepool0、基于特征图宽度和高度维度的全局最大值池化层globalmaxpool0、全连接层amf0和amfc1、第一sigmod层以及通道加权层scale0;
空间注意力模块包括基于特征图通道维度的全局均值池化层globalavepool1、基于特征图通道维度的全局最大值池化层globalmaxpool1、卷积层amconv0、第二sigmod层和像素加权层scale1;
基于特征图宽度和高度维度的全局均值池化层globalavepool0、基于特征图通道维度的全局均值池化层globalavepool1和通道加权层scale0的输入为所述上下文环境信息模块的输出,基于特征图宽度和高度维度的全局最大值池化层globalmaxpool0输出的特征图与基于特征图宽度和高度维度的全局均值池化层globalavepool0输出的特征图按通道维度拼接后作为全连接层amf0的输入,全连接层amf0的输出经全连接层amfc1与第一sigmod层输入连接,第一sigmod层输出与通道加权层scale0的输入连接;
基于特征图通道维度的全局均值池化层globalavepool1输出的特征图和基于特征图通道维度的全局最大值池化层globalmaxpool1输出的特征图按通道维度进行拼接后作为卷积层amconv0的输入,卷积层amconv0的输出经第二sigmod层与像素加权层scale1的输入连接;
通道加权层scale0的输出与像素加权层scale1的输入连接,像素加权层scale1的输出作为所述拼接层concat的输入。
进一步地,所述通道加权层scale0用于对输入的特征图的各个通道特征图进行加权,加权计算公式为:
fsc(x,y)=sc*fc(x,y)
其中,fsc(x,y)表示输出加权特征图的第c个通道(x,y)位置处的数值,sc表示第c个通道的权重值,fc(x,y)表示输入的特征图的第c个通道(x,y)位置处的数值。
进一步地,所述像素加权层scale1用于对输入的特征图按照逐像素位置进行加权,加权计算公式为:
fsc(x,y)=s(x,y)*fc(x,y)
其中,fsc(x,y)表示输出加权特征图的第c个通道(x,y)位置处的数值,s(x,y)表示输入特征图的(x,y)位置处的重要程度权重值,fc(x,y)表示输入特征图的第c个通道第(x,y)位置处的数值。
进一步地,所述特征点定位网络包括全局均值池化层ave-pool和全连接层fc,全局均值池化层ave-pool的输入与所述信息融合网络的输出连接、输出与全连接层fc的输入连接。
进一步地,在所述获取待识别的人脸局部图像作为人脸特征点定位模型的输入之前,还包括对所述人脸特征点定位模型进行训练,具体为:
获取训练样本图像集,该集合中的样本图像为标注有特征点位置信息的人脸局部图像;
设置所述人脸特征点定位模型的目标损失函数谓均方差损失函数;
将训练样本图像集送入人脸特征点定位模型,学习模型参数。
另一方面,采用一种基于信息融合的人脸特征点定位系统,包括:获取模块、转换模块、融合模块和定位模块,其中:
获取模块用于获取待识别的人脸局部图像并输入至人脸特征点定位模型,该人脸特征点定位模型包括依次连接的特征图分辨率快速下降网络、信息融合网络和特征点定位网络;
转换模块用于利用特征图分辨率快速下降网络将人脸局部图像转换为低分辨率特征图;
融合模块用于利用信息融合网络对低分辨率特征图进行处理,得到融合有上下文环境信息、通道注意力信息和空间注意力信息的融合特征图;
定位模块用于利用特征点定位网络对融合特征图进行处理,得到所述人脸局部图像上的人脸特征点位置。
进一步地,所述特征图分辨率快速下降网络包括卷积层conv0和最大值池化层maxpool0,卷积层conv0的输入为所述人脸局部图像、输出与最大值池化层maxpool0连接,最大值池化层maxpool0输出为所述低分辨率特征图;
所述信息融合网络包括依次连接的信息融合模块rcam0、rcam1、rcam2和rcam3,信息融合模块rcam0的输入为所述低分辨率特征图,信息融合模块rcam3的输出为所述融合特征图;
每个信息融合模块包括依次连接上下文环境信息模块、综合注意力模块、拼接层concat和卷积层conv2,拼接层concat的输入连接最大值池化层maxpool1的输出,上下文环境信息模块和最大值池化层maxpool1输入为上一信息融合模块的输出或所述特征图分辨率快速下降网络的输出。
与现有技术相比,本发明存在以下技术效果:本发明基于深度学习技术设计人脸特征点定位模型,该模型利用人脸图像的具有上下文信息的融合特征,使得人脸特征点定位模型能够兼顾人脸图像的深层语义信息和浅层细节信息,精准的计算出人脸特征点位置;利用综合注意力机制,使得深度神经网络模型能够更好的关注有效的特征区域,人脸特征点定位更加精准,鲁棒性更高。
附图说明
下面结合附图,对本发明的具体实施方式进行详细描述:
图1是一种基于信息融合的人脸特征点定位方法的流程图;
图2是本发明整体设计流程图;
图3是人脸特征点定位模型的结构图;
图4是信息融合模块的结构图;
图5是上下文环境信息模块的结构图,其中c0表示调整后的特征图通道数目,取值远小于输入特征图通道数目;
图6是综合注意力模块的结构图,其中,r表示网络挤压因子;
图7是一种基于信息融合的人脸特征点定位系统的结构图。
图中:每个模块图形旁边的字母数字,表示当前模块的输出特征图尺寸,即:特征图高度×特征图宽度×特征图通道数。
具体实施方式
为了更进一步说明本发明的特征,请参阅以下有关本发明的详细说明与附图。所附图仅供参考与说明之用,并非用来对本发明的保护范围加以限制。
如图1所示,本实施例公开了一种基于信息融合的人脸特征点定位方法,其用于利用所设计的人脸特征点定位模型对任意给出的人脸局部图像进行人脸特征点的识别定位,具体包括如下步骤s1至s4:
s1、获取待识别的人脸局部图像作为人脸特征点定位模型的输入,该人脸特征点定位模型包括依次连接的特征图分辨率快速下降网络、信息融合网络和特征点定位网络;
s2、利用特征图分辨率快速下降网络将人脸局部图像转换为低分辨率特征图;
s3、利用信息融合网络对低分辨率特征图进行处理,得到融合有上下文环境信息、通道注意力信息和空间注意力信息的融合特征图;
s4、利用特征点定位网络对融合特征图进行处理,得到所述人脸局部图像上的人脸特征点位置。
需要说明的是,本发明所设计的人脸特征点定位模型中采用了信息融合网络,用于融合上下文环境信息、通道注意力信息和空间注意力信息,兼顾了人脸图像的深层语义特征和浅层细节信息,可以精准的定位出人脸图像的特征点位置。
需要说明的是,在上述对待识别的人脸图像进行人脸特征点定位之前,还需对人脸特征点定位模型进行构建及训练,然后利用训练好的人脸特征点定位模型进行人脸特征点定位,如图2所示:
(1)设计人脸特征点定位模型:
需要说明的是,本发明所设计的人脸特征点定位模型采用的是卷积神经网络(cnn),为了方便叙述本发明,定义一些术语:特征图分辨率指的是特征图高度×特征图宽度,特征图尺寸指的是特征图高度×特征图宽度×特征图通道数,核尺寸指的是核宽度×核高度,跨度指的是宽度方向跨度×高度方向跨度,另外,每一个卷积层后面均带有批量归一化层和非线性激活层。人脸特征点定位模型的设计思路如下:
1-1)设计深度神经网络模型的输入图像:
本发明所采用的输入图像是一幅图像分辨率为224×224的3通道rgb图像,输入图像尺寸越大,其包含的细节越多,越有利于精确定位人脸特征点。
1-2)设计深度神经网络模型的主体网络,主体网络主要用于融合人脸图像的深层语义信息和人脸图像的浅层细节信息,提取人脸图像的具有上下文信息的融合特征,人脸的融合特征提取质量直接影响后续人脸特征点的定位准确度。
由于本发明采用的输入图像尺寸较大,不利于深度神经网络模型的快速运行,因此,需要一种能够快速提取输入人脸图像特征的高效网络。如图3所示,本发明采用改进的经典resnet网络结构作为模型主体网络,包括特征图分辨率快速下降网络、信息融合网络和特征点定位网络。
1-2-1)设计特征图分辨率快速下降网络:
特征图分辨率快速下降网络包括卷积层conv0和最大值池化层maxpool0,conv0层是一个核尺寸为7×7,跨度为2×2的卷积层;maxpool0层是一个核尺寸为2×2,跨度为2×2的最大值池化层;conv0层和maxpool0层共同组成了一个特征图分辨率快速下降网络,主要作用是在保留更多图像细节的同时,快速降低特征图分辨率,减少后续操作的运算量。
1-2-2)设计信息融合网络:
信息融合网络包括包括信息融合模块rcam0、rcam1、rcam2、和rcam3,信息融合模块主要是在resnet网络的resblock的基础上,融合了上下文环境信息、通道注意力信息和空间注意力信息。
信息融合模块的具体结构如图4所示,maxpool1层是一个核尺寸为2×2,跨度为2×2的最大值池化层;concat层是按通道维度进行拼接的拼接层;conv2是一个核尺寸为3×3,跨度为1×1的卷积层,主要用于融合拼接后的特征图;contextmodule是融合了上下文环境信息的resblock改进模块即接上下文环境信息模块,attentionmodule是综合注意力模型即综合注意力模块,融合了通道注意力机制和空间注意力机制。
其中,上下文环境信息模块contextmodule的具体网络结构如图5所示,contextconv0层是一个核尺寸为1×1,跨度为2×2的卷积层;contextconv1_0、contextconv2_0、contextconv3_0均是核尺寸为1×1,跨度为1×1的卷积层,主要用于调整特征图通道数目;contextconv1_1、contextconv2_1、contextconv3_1均是核尺寸为3×3,跨度为2×2的卷积层;contextconv2_2、contextconv3_2、contextconv3_3均是核尺寸为3×3,跨度为1×1的卷积层;其中,contextconv2_1和contextconv2_2这两层网络通过两个核尺寸为3×3的卷积操作来完成一个核尺寸为5×5的卷积操作,contextconv3_1、contextconv3_2和contextconv3_3这三层网络通过三个核尺寸为3×3的卷积操作来完成一个核尺寸为7×7的卷积操作;contextsum层是一个把多个输入特征图按逐像素相加的方式生成一个输出特征图的合并层;contextconv4是一个核尺寸为3×3,跨度为1×1的卷积层,主要用于融合合并后的特征图。
其中综合注意力模块attentionmodule的具体网络结构如图6所示,综合注意力模块包括通道注意力模块和空间注意力模块,通道注意力模块包括基于特征图宽度和高度维度的全局均值池化层globalavepool0、基于特征图宽度和高度维度的全局最大值池化层globalmaxpool0、全连接层amf0和amfc1、第一sigmod层以及通道加权层scale0;空间注意力模块包括基于特征图通道维度的全局均值池化层globalavepool1、基于特征图通道维度的全局最大值池化层globalmaxpool1、卷积层amconv0、第二sigmod层和像素加权层scale1。
globalavepool0层的输出特征图和globalmaxpool0层的输出特征图按通道维度进行拼接;amf0、amfc1均是全连接层,用于提取输入特征图每个通道的重要程度权值;globalavepool1是一个基于特征图通道维度的全局均值池化层,globalmaxpool1是一个基于特征图通道维度的全局最大值池化层;globalavepool1层的输出特征图和globalmaxpool1层的输出特征图按通道维度进行拼接;amconv0是一个核尺寸为7×7,跨度为1×1的卷积层,主要用于提取输入特征图上各个像素位置的重要程度权值;sigmod层是sigmod类型的激活函数;scale0层是按通道加权层,其作用是对输入特征图的各个通道特征图进行加权;scale1层是按像素加权层,其作用是对输入特征图按照逐像素位置进行加权。
所述通道加权层scale0用于对输入的特征图的各个通道特征图进行加权,加权计算公式为:
fsc(x,y)=sc*fc(x,y)
其中,fsc(x,y)表示输出加权特征图的第c个通道(x,y)位置处的数值,sc表示第c个通道的权重值,fc(x,y)表示输入的特征图的第c个通道(x,y)位置处的数值,*表示乘号。
进一步地,所述像素加权层scale1用于对输入的特征图按照逐像素位置进行加权,加权计算公式为:
fsc(x,y)=s(x,y)*fc(x,y)
其中,fsc(x,y)表示输出加权特征图的第c个通道(x,y)位置处的数值,s(x,y)表示输入特征图的(x,y)位置处的重要程度权重值,fc(x,y)表示输入特征图的第c个通道第(x,y)位置处的数值。
1-2-3)设计特征点定位网络:
特征点定位网络包括全局均值池化层ave-pool和全连接层fc,全局均值池化层ave-pool的输入与所述信息融合网络的输出连接、输出与全连接层fc的输入连接,fc层是一个输出特征为2xn维的全连接层,n表示人脸特征点的个数。
(2)训练深度神经网络模型:
主要是通过大量的标注好的训练样本数据,优化深度神经网络模型参数,使得深度神经网络模型能够精确定位出人脸特征点位置,具体的步骤如下:
2-1)获取训练样本图像,主要是收集各种场景,各种光线、各种角度下的人脸图像,通过现有的人脸检测算法,获取每个人脸的局部区域图像,然后在每个人脸局部图像上标注n个特征点的位置,并记录特征点位置信息;
2-2)设计深度神经网络模型的目标损失函数,本发明采用的是均方差(mse)损失函数。
2-3)训练深度神经网络模型,主要是把标注好的人脸样本图像集合送入定义好的深度神经网络模型,学习相关的模型参数.
(3)使用深度神经网络模型,对于任意给出的一个人脸局部图像,经过深度神经网络模型前向运算后,直接输出人脸特征点位置。
如图7所示,本实施例公开了一种基于信息融合的人脸特征点定位系统,包括:获取模块10、转换模块20、融合模块30和定位模块40,其中:
获取模块10用于获取待识别的人脸局部图像并输入至人脸特征点定位模型,该人脸特征点定位模型包括依次连接的特征图分辨率快速下降网络、信息融合网络和特征点定位网络;
转换模块20用于利用特征图分辨率快速下降网络将人脸局部图像转换为低分辨率特征图;
融合模块30用于利用信息融合网络对低分辨率特征图进行处理,得到融合有上下文环境信息、通道注意力信息和空间注意力信息的融合特征图;
定位模块40用于利用特征点定位网络对融合特征图进行处理,得到所述人脸局部图像上的人脸特征点位置。
需要说明的是,该系统中采用的人脸特征点定位模型与上述实施例公开的基于信息融合的人脸特征点定位方法中所采用的人脸特征点定位模型结构和原理相同,该处不再赘述。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!