一种基于多源数据和神经网络模型的PM2.5反演方法与流程
本发明具体涉及一种基于多源数据和神经网络模型反演pm2.5的反演方法。
背景技术:
近年来pm2.5成为人们重点关注的大气污染物之一,其输送距离远,在空气中停留时间长,会对人体和环境造成不良影响,研究表明长期暴露于pm2.5污染中将严重危害人体的健康。避开高污染区是减少威胁的有效方法,但有效避开高污染区的路线选择需要高时间精度、大范围、高质量的pm2.5分布数据做支撑。当前已有pm2.5监测站,但其分布稀疏且集中在城市建成区,数据分布不均匀且精度低,近年来利用覆盖范围广的遥感影像和其他数据的多源数据pm2.5反演方法快速发展。中分辨率成像光谱仪(modis)aod、多角度成像光谱仪(misr)aod、可见红外成像辐射计(viirs)aod等是当前常用的遥感影像产品。然而这些影像的分辨率较低,pm2.5反演结果精度受限。aod产品是结合影像通过算法获得的,误差累计的风险比直接使用影像数据要高。目前使用的多源数据有气象、土地利用类型、人口密度等等,表征人类活动的数据较少,然而人类活动与大气质量之间有着密切的联系。现有利用遥感影像反演地面pm2.5浓度的方法有线性回归模型、线性混合模型以及神经网络等。线性回归模型和线性混合模型忽略了空间异质性,在下垫面情况复杂的情况下,模型不能正确反映污染物浓度。如果不对多源数据进行处理,无论哪种方法都容易出现过拟合的情况。
技术实现要素:
发明目的:鉴于上述问题,本发明的目的是提供一种基于多源数据和神经网络模型的pm2.5反演方法,以解决应用高级统计模型和低精度遥感影像反演pm2.5时存在精度较低的问题。
技术方案:为解决上述技术问题,本发明所采用的技术方案是:
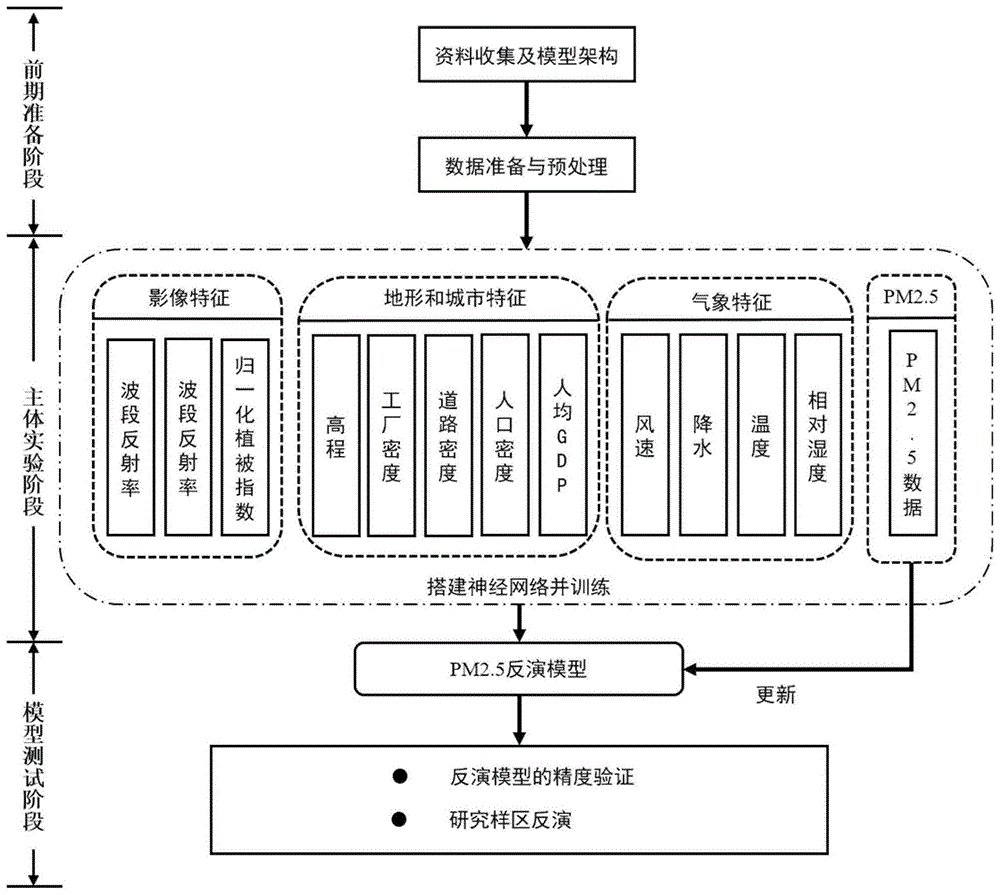
一种基于多源数据和神经网络模型的pm2.5反演方法,包括如下步骤:
步骤一:获取landsat8影像数据,pm2.5监测数据,气象数据,高程数据和城市特征数据;
步骤二:提取landsat8影像特征及其衍生特征;
步骤三:提取风速、温度、降水和相对湿度与pm2.5具有相关性的气象特征;
步骤四:提取地形特征以及工厂密度、道路密度、人口密度和人均gdp等城市特征;
步骤五:搭建神经网络模型,对数据集进行训练;
步骤六:根据留出法的验证结果对模型进行优化;
步骤七:使用反演模型得到pm2.5反演结果;
步骤八:利用逐小时气象数据实时更新反演结果并利用逐小时空气质量数据对反演结果进行纠偏。
进一步的,所述的步骤一中的气象数据包括风速、相对湿度、温度、和降水量;城市特征数据包括工厂和道路分布数据、人均gdp和人口密度栅格图。
进一步的,所述的步骤二具体为:
2.1对landsat8遥感影像进行辐射校正、大气校正、去云的预处理;
2.2提取landsat8影像数据的红光波段反射率r和蓝光波段反射率b;
2.3提取影像成像的月份m;
2.4根据如下公式计算ndvi:
其中,nir为近红外波段反射率,r为红光波段反射率。
进一步的,所述的步骤三具体为:
3.1构建气象站点的泰森多边形,将落入各泰森多边形中的pm2.5监测站点与各多边形对应的气象站点匹配;
3.2提取pm2.5监测站点对应的气象站当天和前一天的数据。
进一步的,所述的步骤四具体为:
4.1在每个栅格像元中心的一定范围内定义一个邻域area,将邻域内点的数量相加,得到count,然后除以邻域面积,即得到工厂的密度df;
4.2定义一个领域半径r,以栅格像元中心为圆心,绘制半径为r的邻域,计算线状要素落入该邻域的长度之和l,并与该邻域面积πr2相除,得到道路密度dr;
4.3提取站点周围30m的平距高程h,平均工厂密度daf和平均道路密度dar;
4.4从人口密度和人均gdp的栅格图像中提取监测站点的人口密度dpop和人均gdp数据gdpa。
进一步的,所述的步骤五具体为:
5.1对多源数据进行主成分分析,保留主成分;
5.2搭建多层感知器神经网络模型,输入保留数据集进行训练;
5.3通过以下四种方法对模型进行优化:①增加或减少隐藏层的层数与每层所包含的神经元的个数;②添加dropout层并使用正则化,防止出现过拟合的情况;③调整迭代次数,确定最优解情况下的大致迭代次数;④调整模型的学习率,学习率太小会导致训练速度过慢或者出现局部最优解,学习率太大可能会导致模型错过最优解,需要根据具体训练情况来确定。
进一步的,所述的步骤六中留出法验证模型精度具体为对数据集进行划分,将80%作为训练集进行训练,20%作为测试集进行验证。
进一步的,所述的步骤七中使用反演模型的到pm2.5反演结果的具体步骤为反演结果与真实值的相关系数较大,平均绝对误差较小时得出反演模型;将待反演影像所对应的主成分数据输入到模型中得到该天的pm2.5反演结果。
进一步的,所述的步骤八中具体步骤为:
8.1按照多源数据的时间分辨率更新多源数据,如气象数据的更新速率可以达到每小时一次,数据更新后可获得新的pm2.5反演结果;
8.2构建pm2.5监测站点的泰森多边形,计算落如泰森多边形的像元的平均pm2.5浓度
8.3使用cn=c+δc公式对泰森多边形内像元的pm2.5浓度c进行每小时一次的调整得到新的pm2.5浓度cn。
有益效果:本发明首先获取landsat8影像数据,pm2.5监测数据,气象数据,高程数据和城市特征数据;提取遥感影像波段信息和成像月份并计算归一化植被指数(ndvi);提取影像成像当天与前一天的气象数据和当天的pm2.5浓度;然后提取高程和城市特征;接着搭建神经网络模型,对以上的数据进行训练;基于“留出法”对模型精度进行验证,并根据验证结果对模型参数进行修改,以达到最优效果;综上得到pm2.5反演模型;最后基于多源数据,并利用监测站逐小时pm2.5数据更新调整反演结果,在研究区空间范围内实现pm2.5的实时计算。本发明提供的一种高精度的pm2.5反演方法能够较准确的反演出pm2.5实时浓度,得到pm2.5的空间分布规律,其中预测值和真实值的相关性高达0.89,时间分辨率达1小时,空间分辨率达30m*30m,可以为一些需要高精度pm2.5分布数据的研究提供基础数据。
附图说明
图1为本发明的基于多源数据和神经网络模型的pm2.5反演方法实施例的流程图;
图2为本发明实施例的气象站点和pm2.5站点匹配示意图;
图3为本发明实施例的工厂的密度df示意图;
图4为本发明实施例的主要道路的密度dr示意图;
图5为本发明实施例的反演结果示意图。
具体实施方式
下面将对本发明实施例中的技术方案进行清楚、完整地描述,以使本领域的技术人员能够更好的理解本发明的优点和特征,从而对本发明的保护范围做出更为清楚的界定。本发明所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明的一种基于多源数据和神经网络模型的pm2.5反演方法包含以下步骤:
步骤一:获取杭州市landsat8影像数据,pm2.5监测数据,气象数据,高程数距和城市特征数据。其中气象数据包括风速、相对湿度、温度和降水;城市特征数据包括工厂和道路分布数据、人均gdp和人口密度栅格图。
步骤二:将landsat的影像数据进行辐射校正、大气校正和去云等预处理,根据ndvi计算公式
步骤三:构建气象站点泰森多边形,多边形的任意位置离该气象站点最近,离其他气象站点距离远,将落在多边形内的pm2.5监测站与该多边形对应的气象站点的数据匹配,如图2所示。提取pm2.5数据前一天和当天的气象数据。
步骤四:在每个栅格像元中心的一定范围内定义一个邻域area,将邻域内点的数量相加,得到count,然后除以邻域面积,即得到工厂的密度df,如图3所示;定义一个领域半径r,以栅格像元中心为圆心,绘制半径为r的邻域,计算线状要素落入该邻域的长度之和l,并与该邻域面积πr2相除,得到道路密度dr,如图4所示;提取站点周围30m的平距高程h,平均工厂密度daf和平均道路密度dar;从人口密度和人均gdp的栅格图像中提取监测站点的人口密度dpop和人均gdp数据gdpa。
步骤五:整合波段反射率、成像月份、ndvi、成像前一天和当天的风速、相对湿度、温度、降水,高程、工厂密度、道路密度、人口密度和人均gdp数据,进行主成分分析,保留主成分,将主成分的数据与pm2.5浓度构建bp神经网络;通过以下四种方法对模型进行优化①增加或减少隐藏层的层数与每层所包含的神经元的个数。②添加dropout层并使用正则化,防止出现过拟合的情况。③调整迭代次数,确定最优解情况下的大致迭代次数。④调整模型的学习率,学习率太小会导致训练速度过慢或者出现局部最优解,学习率太大可能会导致模型错过最优解,需要根据具体训练情况来确定。
步骤六:采用机器学习中常用的“留出法”对数据集进行划分,将80%作为训练集进行训练,20%作为测试集进行验证。以杭州市为例,训练结果显示,反演结果与真实值的相关系数为0.89,平均绝对误差为9.74μg/m3,相关性较为显著。
步骤七:使用反演模型的到pm2.5反演结果的具体步骤为反演结果与真实值的相关系数较大,平均绝对误差较小时得出反演模型;将待反演影像对应的主成分数据输入到模型中得到该天的pm2.5反演结果,如图5所示。
步骤八:按照多源数据的时间分辨率更新多源数据,如气象数据的更新速率可以达到每小时一次,数据更新后可获得新的pm2.5反演结果;接着构建pm2.5监测站点的泰森多边形,计算落如泰森多边形的像元的平均pm2.5浓度
本发明提供的一种高精度的pm2.5反演方法能够较准确的反演出pm2.5实时浓度,得到pm2.5的空间分布规律,为需要高精度pm2.5分布数据的研究提供基础数据。
- 还没有人留言评论。精彩留言会获得点赞!