基于场景分类和多尺度特征融合的复杂场景人群计数方法与流程
本发明属图像处理技术领域,具体涉及一种基于场景分类和多尺度特征融合的复杂场景人群计数方法。
背景技术:
随着社会的不断发展,全球人口急剧增加,有越来越多的人涌入大城市生活工作,给城市带来安全隐患。在地铁站、大商场和各种集会中,过度密集的人群一旦失去控制,很容易发生骚乱,造成一系列拥堵、踩踏等恶性事件。假如安保人员能够在集会进行时掌握人群数量和分布情况,就可以在密度达到警戒线时及时采取相应措施,对此类恶性事件进行预防。正是基于这个需求,人群密度估计渐渐成为了计算机视觉领域的一个热门课题。大致上,人群密度估计方法可分为基于探测的方法、基于回归的方法和基于深度学习的方法。基于探测和回归的方法都是通过手工设计的特征来对人群进行估计,例如个体的形状、梯度直方图特征,整体的面积、周长等特征。这些特征无法应对遮挡、阴影等复杂情况。基于深度学习的方法借助于神经网络来提取图片中与人群有关的高级特征,其计数准确度相比于利用手工设计特征的方法有了很大提升。但是由于真实场景下存在着各种复杂情况,例如由于拍摄角度不同造成的尺度畸变、由于人员流动造成的密度分布不均等,导致这种方法的性能仍有很大的提升空间。
技术实现要素:
为了克服现有技术的不足,本发明提供一种基于场景分类和多尺度特征融合的复杂场景人群计数方法。首先,标注并建立密度等级数据集;然后,利用建立的数据集分别对分类、稀疏估计和密集估计子网络进行预训练;接着,结合自标记机制,利用测试数据集对网络再次进行训练;最后,将实际待测图片输入到训练好的网络,利用分类权重对两种密度估计结果进行加权后得到人群密度图。本发明可以解决由于拍摄角度不同导致的图片尺度畸变和人群分布不均问题,提高整体的估计准确度。
一种基于场景分类和多尺度特征融合的复杂场景人群计数方法,其特征在于步骤如下:
步骤1:由公开的数据集shanghaitechparta中随机裁截出2000-4000张图片,并计算这些图片中人数的平均值,以人数平均值的2/3为阈值α1,以人数平均值的4/3为阈值α2,将图片中人数低于α1的图片类别标注为稀疏,归入稀疏数据集,将图片中人数高于α2的图片类别标注为密集,归入密集数据集,将图片中人数处于α1和α2之间的图片类别随机标注为稀疏或密集,并归入相应的数据集;如果得到的稀疏数据集和密集数据集中的图片数量不同,在原数据集shanghaitechparta中进行新的图片随机裁截,并按照前面所述方法根据阈值α1和α2进行图片类别标注和分类,直至两个数据集中的图片数量相同;两个数据集共同构成密度等级数据集;
步骤2:构建包括前端特征提取模块、分类模块、密集估计模块和稀疏估计模块四个模块的分类估计网络模型,其中,前端特征提取模块由在imagenet数据集上预训练过的vgg-16的前10层卷积层组成,其输出为512通道的特征图,作为后续三个模块的输入;分类模块包括1个自适应池化层、3个卷积层和1个全连接层,3个卷积层的通道数分别为512、256、128,卷积核大小均为3×3,全连接层的输入为128通道,输出为2通道,分别代表密集与稀疏的权重,权重为0-1范围内的值,两个权重值的和为1;密集估计模块和稀疏估计模块的网络结构相同,均包含6层卷积层,通道数分别为512、256、256、128、32、1,卷积核大小均为3×3,输出分别为密集估计的密度图和稀疏估计的密度图,密度图中的像素值代表在该像素位置处的人数,密度图中所有像素值的和即为图片的人数估计值;
所述的特征提取模块与密集估计模块、稀疏估计模块还存在如下连接:特征提取模块的第7层卷积层的输出与密集估计模块的第3层卷积层的输出按通道叠加后输入到密集估计模块的第4层卷积层,特征提取模块的第10层卷积层的输出与密集估计模块的第1层卷积层的输出按通道叠加后输入到密集估计模块的第2层卷积层,特征提取模块的第7层卷积层的输出与稀疏估计模块的第3层卷积层的输出按通道叠加后输入到稀疏估计模块的第4层卷积层,特征提取模块的第10层卷积层的输出与稀疏估计模块的第1层卷积层的输出按通道叠加后输入到稀疏估计模块的第2层卷积层;
步骤3:首先,设定分类模块的损失函数为交叉熵损失函数,计算公式为:
其中,lc表示交叉熵损失函数,y表示真值标签(密集或稀疏),
固定稀疏估计模块和密集估计模块中的参数,将密度等级数据集输入到网络对分类模块进行训练;
然后,设定密集估计和稀疏估计两个模块的损失函数都为均方差损失函数,计算公式为:
其中,ld表示均方差损失函数,n表示测试图片数量,i表示图片标号,yi表示第i张图片的真值人数,y'i表示第i张图片的预测人数;
固定分类模块、特征提取模块和稀疏估计模块的参数,将密集数据集输入到网络对密集估计模块进行训练;
最后,固定分类模块、特征提取模块和密集估计模块的参数,将稀疏数据集输入到网络对稀疏估计模块进行训练,至此完成整个网络的预训练;
步骤4:对于测试数据集,首先,将其训练集中的所有图片输入到步骤3预训练后的网络,并按下式对图片进行密集程度标记:
其中,dend表示密集估计模块输出的人数估计值,dens表示稀疏估计模块输出的人群估计值,gt代表图片中总人数的真实值,label表示输入图片的密集程度标签,dense表示密集,sparse表示稀疏;
然后,将带密集程度标签的训练集中的所有图片输入到网络进行整体训练,训练中设定网络总的损失函数lall为:
lall=αlc+βld(4)
其中,α为控制分类模块比重的权重系数,取值范围为0-1,β为控制密集估计模块和稀疏估计模块比重的权重系数,取值范围为0-1;
所述的待测试数据集包括shanghaitech数据集、ucf_cc数据集;
步骤5:将待计数人群图片输入到步骤4得到的训练好的网络中,经过三个模块的估计,分别得到密集与稀疏的分类权重、密集估计结果和稀疏估计结果,将密集估计结果和稀疏估计结果按照其对应的分类权重进行加权求和,即得到图片的密度图,将密度图中所有像素值相加,即得到图片的估计总人数。
本发明的有益效果是:通过场景分类的方法建立不同密度等级的数据集,并对网络进行预训练,使网络在面对人群分布不均问题时具有更高的估计准确度;由于构建的分类估计网络不同模块间存在交叉连接,使深层和浅层间的特征信息相互融合,能够使网络更好地结合图片的多尺度特征信息,在面对尺度畸变问题时,具有更强的鲁棒性。
附图说明
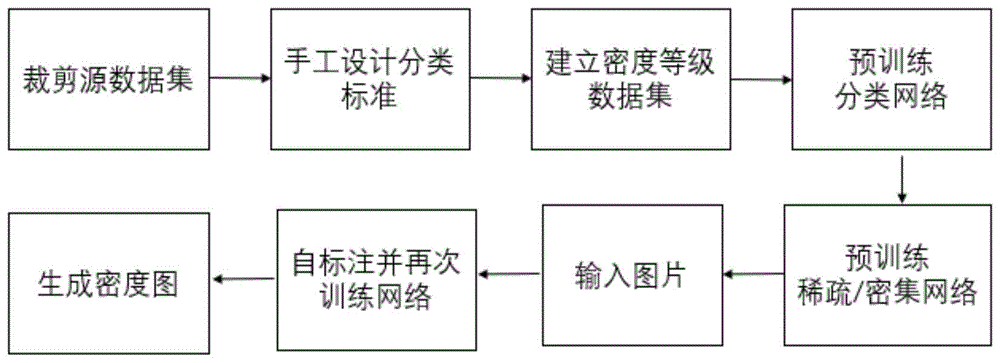
图1是本发明的基于场景分类和多尺度特征融合的复杂场景人群计数方法流程图;
图2是本发明构建的分类估计神经网络示意图;
图3是多尺度信息结合示意图。
具体实施方式
下面结合附图和实施例对本发明进一步说明,本发明包括但不仅限于下述实施例。
本发明提供了一种基于场景分类和多尺度特征融合的复杂场景人群计数方法,利用对场景中的人数进行统计并生成密度图来显示人群的分布状况。如图1所示,其具体实现过程如下:
1、构建密度等级数据集。
由公开的数据集shanghaitechparta中随机裁截出2000-4000张图片,并计算这些图片中人数的平均值,以人数平均值的2/3为阈值α1,以人数平均值的4/3为阈值α2,将图片中人数低于α1的图片类别标注为稀疏,归入稀疏数据集,将图片中人数高于α2的图片类别标注为密集,归入密集数据集,将图片中人数处于α1和α2之间的图片类别随机标注为稀疏或密集,并归入相应的数据集;如果得到的稀疏数据集和密集数据集中的图片数量不同,由原数据集shanghaitechparta中进行新的图片随机裁截,并按照前面所述方法根据阈值α1和α2进行图片类别标注和分类,直至两个数据集中的图片数量相同;两个数据集共同构成密度等级数据集。
2、构建分类估计网络。
本发明构建了分类估计神经网络,如图2所示,整个网络包括四个模块,即前端特征提取模块、分类模块、密集估计模块和稀疏估计模块。其中,前端特征提取模块由在imagenet数据集上预训练过的vgg-16的前10层卷积层组成,其输出为512通道的特征图,作为后续三个模块的输入;分类模块包括1个自适应池化层、3个卷积层和1个全连接层,其中,卷积层的通道数分别为512、256、128,卷积核大小均为3×3,全连接层输入为128通道,输出为2通道,代表密集与稀疏的权重,权重为0-1范围内的值,且所有权重值的和为1;密集估计模块和稀疏估计模块的网络结构相同,均包含6层卷积层,通道数分别为512、256、256、128、32、1,卷积核大小均为3×3,输出分别为密集估计的密度图和稀疏估计的密度图,其中密度图中的像素值代表在该像素处的人数,因此将所有像素值求和即可得到人数的估计值;
为了解决实际应用中常见的尺度畸变问题,本发明在网络的浅层和深层之间建立连接,将浅层网络提取到的特征图输入到深层网络,连接的建立方式如图3所示。由于网络的浅层和深层的感受野不同,提取到的特征信息尺度不同,因此将深浅层网络提取到的特征信息结合在一起处理,可以帮助网络处理图片中的人群尺度畸变的问题。将特征提取模块的10层卷积层命名为pre_conv1-pre_conv10,将密集估计模块和稀疏估计模块的卷积层分别命名为den_conv1-den_conv6和spar_conv1-spar_conv6。共建立四条连接,具体是:
(1)将pre_conv7的输出与den_conv3的输出结合后(结合方式是按通道叠加,即两个256通道合为512通道)作为den_conv4的输入;
(2)将pre_conv10的输出与den_conv1的输出结合作为den_conv2的输入;
(3)将pre_conv7的输出与spar_conv3的输出结合作为spar_conv4的输入;
(4)将pre_conv10的输出与spar_conv1的输出结合作为spar_conv2的输入。
通过以上四条连接可实现多尺度的特征信息融合,提高网络在面对尺度畸变问题时的鲁棒性。
3、对网络进行分步预训练。
设定分类模块的损失函数为交叉熵损失函数,计算公式为:
其中,lc表示交叉熵损失函数,y表示真值标签(密集或稀疏),
首先固定稀疏估计模块和密集估计模块中的参数,将密度等级数据集输入到网络中进行训练,目的是训练分类模块的参数。将人群图片输入到训练好的分类模块中可以输出得到密集与稀疏两个指标的权重,表示该图片属于密集或稀疏的概率,两个权重之和为1;
设定密集估计和稀疏估计两个模块的损失函数为均方差损失函数,计算公式为:
其中,ld表示均方差损失函数,n表示测试图片数量,i表示图片标号,yi表示第i张图片的真值人数,y'i表示第i张图片的预测人数;
固定分类模块、特征提取模块和稀疏估计模块的参数,将密集数据集输入网络中对密集估计模块进行训练,训练好的模块输出人群密度图且该模块对与较密集的图片估计准确度更高;再固定分类模块、特征提取模块和密集估计模块的参数,将稀疏数据集输入到网络中对稀疏估计模块进行训练,训练好的模块同样输出人群密度图且该模块对较稀疏的图片估计准确度更高,至此整个网络的预训练完成。
4、网络训练。
将待测试数据集(shanghaitech数据集或ucf_cc数据集)中的训练集输入到步骤3得到的网络中进行微调,此时所有网络参数均不固定。由于训练分类模块时需要图片密集程度的标签(密集或稀疏),而待测试数据集中没有该标签。因此,可利用密集估计模块和稀疏估计模块的输出按下式对输入图片进行标注:
其中,dend表示密集估计模块输出的人数估计值,即密度图的像素值之和,dens表示稀疏估计模块输出的人群估计值,gt代表图片中总人数的真实值,label表示对输入图片的密集度标签,分为稀疏和密集,dense表示密集,sparse表示稀疏。
然后,对整体网络进行训练,利用数据集自带的人数真值监督整个网络,提高最终的估计准确度。同时,利用自标注机制得到的标签信息监督分类模块,进一步提高分类的准确性。
训练时设定网络总的损失函数为:
lall=αlc+βld(8)
其中,lall表示在该训练阶段总的损失函数,lc表示用于训练分类模块的交叉熵损失函数,
5、人数估计。
将待计数的人群图片输入到步骤4得到的训练好的网络中,经过三个模块的估计,得到分类权重、密集估计结果和稀疏估计结果,将密集估计结果和稀疏估计结果按照分类权重进行加权求和,即得到人群图片的密度图,其中每个像素的值表示该像素处的人数,将密度图中所有像素值相加即可得到图片的估计总人数。
为验证本发明方法的有效性,在中央处理器为
实验过程中选取绝对误差(mae)和均方根误差(mse)作为评价指标来定量分析性能。mae用来衡量模型的准确度,mse用来衡量模型的稳定性。分别选取zhang等人在文献“y.zhang,d.zhouands.chen.single-imagecrowdcountingviamulti-columnconvolutionalneuralnetwork.ieeeconferenceoncomputervisionandpatternrecognition,589-597,2016.”中提出多列网络方法(mcnn)、sindagi等人在文献“v.a.sindagiandv.m.patel.cnn-basedcascadedmulti-tasklearningofhigh-levelprioranddensityestimationforcrowdcounting.ieeeconferenceonadvancedvideoandsignalbasedsurveillance,1-6,2017.”中提出的多任务学习方法(cmtl)和zhang等人在文献“l.zhang,m.shiandq.chen.crowdcountingviascale-adaptiveconvolutionalneuralnetwork.ieeewinterconferenceonapplicationsofcomputervision.1113-1121,2018.”中提出的尺度自适应方法(sacnn)进行对比。采用不同方法得到的结果如表1所示。可以看出,在parta数据集中,采用本发明方法得到的两项指标均为最优。在partb数据集中,采用本发明方法得到的mae值最优,mse值略低于sacnn方法。总体来看,本发明方法在处理尺度畸变和人群分布不均等复杂场景时,取得了更优的结果。本发明可以应用在公共场所安防、交通管理等方面。
表1
- 还没有人留言评论。精彩留言会获得点赞!