一种非结构化数据文件解析方法及工具与流程
本发明涉及数据处理技术领域,特别涉及一种非结构化数据文件解析方法及工具。
背景技术:
非结构化数据库是指其字段长度可变,并且每个字段的记录又可以由可重复或不可重复的子字段构成的数据库,用它不仅可以处理结构化数据(如数字、符号等信息)而且更适合处理非结构化数据(全文文本、图象、声音、影视、超媒体等信息)。
随着互联网的高速发展,每天都会有大量的数据产生,这些数据大多杂乱无章,无法直接产生价值。在采集大批量数据时,不同网站产生的数据结构风格也各不相同。而随着数据量得不断增大,数据解析的压力也会越来越大。当有大量的数据文件产生时,提高数据解析的效率也显得尤为重要。
其中,存储在数据库里的结构化数据即行数据,是可以用二维表结构来逻辑表达实现的数据,因而容易解析与搜索。与结构化数据相对应的,非结构化数据先有数据,再有结构,因而不易解析与搜索。
随着网络技术的发展,特别是internet和intranet技术的飞快发展,使得非结构化数据的数量日趋增大。这时,主要用于管理结构化数据的关系数据库的局限性暴露地越来越明显。因而,数据库技术相应地进入了"后关系数据库时代",发展进入基于网络应用的非结构化数据库时代。
非结构化web数据库主要是针对非结构化数据而产生的,与以往流行的关系数据库相比,其最大区别在于它突破了关系数据库结构定义不易改变和数据定长的限制,支持重复字段、子字段以及变长字段并实现了对变长数据和重复字段进行处理和数据项的变长存储管理,在处理连续信息(包括全文信息)和非结构化信息(包括各种多媒体信息)中有着传统关系型数据库所无法比拟的优势。
随着网络技术和网络应用技术的飞快发展,完全基于internet应用的非结构化数据库将成为继层次数据库、网状数据库和关系数据库之后的又一重点、热点技术。
为了实现对大量非结构数据的解析、提取,获得结构化的便于直观分析的数据,本发明提出了一种非结构化数据文件解析方法及工具。旨在提高数据解析效率的前提下也保证数据解析的准确性及工具易用性。
准确性是指数据解析的是否符合要求,解析后得到的数据需要能正确的存入到指定数据库中。
易用性是指此工具操作简单,容易配置,从而降低用户的学习成本与时间成本。
技术实现要素:
本发明为了弥补现有技术的缺陷,提供了一种简单高效的非结构化数据文件解析方法及工具。
本发明是通过如下技术方案实现的:
一种非结构化数据文件解析方法,其特征在于:基于数据处理相关python类包,结合java与js数据处理算法,实现对各类非结构化数据文件的高兼容,提高数据解析的速度,在保证效率的同时也要保证数据解析的准确性与工具易用性。
具体包括以下步骤:
第一步,配置读取路径,写入路径与解析规则;
第二步,管理并启动解析任务;
第三步,对解析任务进行实时监控,当解析任务现错误时,反馈错误原因,并提供建议修复方案或自定义修复方案。
本发明非结构化数据文件解析方法,解析规则采用自动配置的方式,同时也支持自定义算法。
本发明非结构化数据文件解析方法,解析任务支持定时执行,自启动执行和实时执行三种方式。
本发明非结构化数据文件解析方法,在数据解析过程中,生成相应的解析日志,用于校验与纠错。
所述解析日志以json格式写入日志文件jobname_yyyymmdd.log。
所述解析日志文件按天分片,每个任务每天只产生一个日志文件。
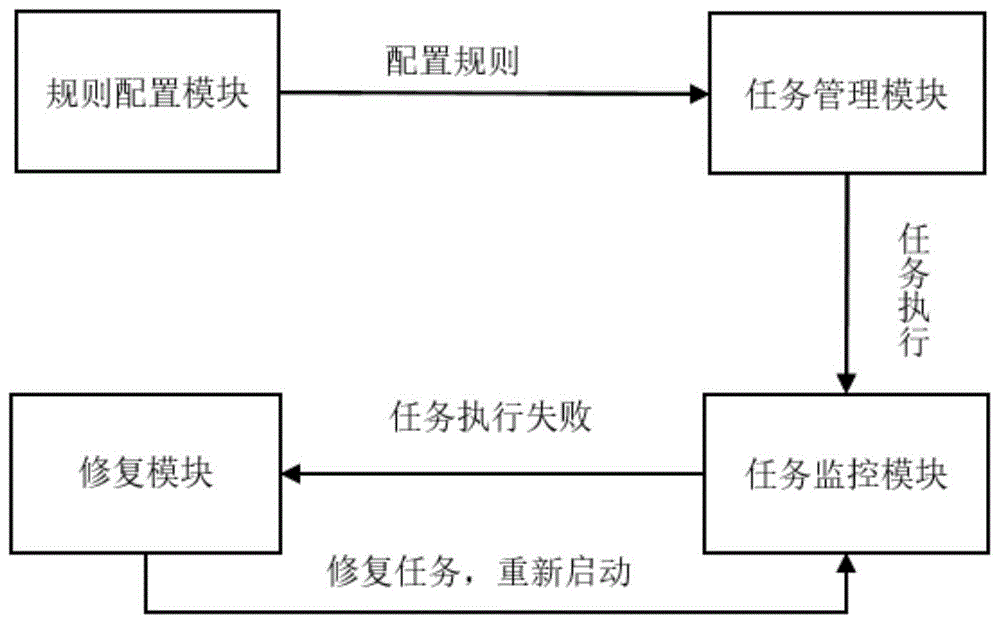
本发明非结构化数据文件解析工具,其特征在于:包括规则配置模块,任务管理模块,任务监控模块和任务修复模块;
所述规则配置模块支持多种解析规则或自定义规则配置,用于配置读取路径、写入路径、解析规则;
所述任务管理模块用于进行多任务管理及启动,提供定时执行,自启动执行与实时执行三种执行方式;
所述任务监控模块与修复模块相结合提供解析任务修复功能。
所述任务监控模块用于实时监控解析任务的执行状况,并生成相应的解析日志,将报错任务交予修复模块进行修复;
当解析任务出现错误时,所述修复模块用于反馈错误原因,并提供建议修复方案或自定义修复方案。
本发明的有益效果是:该非结构化数据文件解析方法及工具,适用于多种非结构化数据文件的解析,不仅减轻了非结构化数据文件处理的工作量,还提高了数据文件解析过程中的容错性,保证了数据文件解析的准确性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
附图1为本发明非结构化数据文件解析工具示意图。
具体实施方式
为了使本技术领域的人员更好的理解本发明中的技术方案,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚,完整的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
该非结构化数据文件解析方法,基于数据处理相关python类包,结合java与js数据处理算法,实现对各类非结构化数据文件的高兼容,提高数据解析的速度,在保证效率的同时也要保证数据解析的准确性与工具易用性。
该非结构化数据文件解析方法,包括以下步骤:
第一步,配置读取路径,写入路径与解析规则;
第二步,管理并启动解析任务;
第三步,对解析任务进行实时监控,当解析任务现错误时,反馈错误原因,并提供建议修复方案或自定义修复方案。
该非结构化数据文件解析方法,解析规则采用自动配置的方式,同时也支持自定义算法。
该非结构化数据文件解析方法,解析任务支持定时执行,自启动执行和实时执行三种方式。
该非结构化数据文件解析方法,在数据解析过程中,生成相应的解析日志,用于校验与纠错。
所述解析日志以json格式写入日志文件jobname_yyyymmdd.log。
所述解析日志文件按天分片,每个任务每天只产生一个日志文件。
该非结构化数据文件解析工具,包括规则配置模块,任务管理模块,任务监控模块和任务修复模块;
所述规则配置模块支持多种解析规则或自定义规则配置,用于配置读取路径、写入路径、解析规则;
所述任务管理模块用于进行多任务管理及启动,提供定时执行,自启动执行与实时执行三种执行方式;
所述任务监控模块与修复模块相结合提供解析任务修复功能。
所述任务监控模块用于实时监控解析任务的执行状况,并生成相应的解析日志,将报错任务交予修复模块进行修复;
当解析任务出现错误时,所述修复模块用于反馈错误原因,并提供建议修复方案或自定义修复方案。
与目前的现有技术相比,该非结构化数据文件解析方法及工具,具有以下特点:
第一、适用于多种非结构化数据文件的解析;
第二、减轻了非结构化数据文件处理的工作量;
第三、提高了数据文件解析过程中的容错性;
第四、保证了数据文件解析的准确性。
以上所述的实施例,只是本发明具体实施方式的一种,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!