一种基于三维卷积神经网络的山火检测方法与流程
本发明属于深度学习技术领域,具体涉及一种基于三维卷积神经网络的山火检测方法。
背景技术:
森林是维持地球生态平衡的关键。森林火灾和山火不仅造成巨大的经济损失,对生态环境也有严重的破坏。人们曾采用瞭望塔上目视的方式,发现火情和发出报警信息。这种方式不仅成本高昂、效率低下,也容易受人为疏忽的影响。因此,设计一套具有一定自主决策能力的无人化智能山火检测技术,对于维护生态环境正常运转和保持国泰民安至关重要。
为了实现山火的远距离探测,出现了的利用遥感卫星来检测大面积山火的技术。不幸的是,遥感图像的空间分辨率受限于时间分辨率和遥感距离,易受气象条件的影响,同时这类方法无法做到针对关注区域的实时监控,也无法检测早期小面积山火。而地基山火检测技术弥补了天基检测技术的不足,利用可见光或红外摄像机采集图像,通过图像处理或计算机视觉技术检测山火。这类方法早期依赖特征工程技术,提取图像的颜色、纹理、形态等空间特征,或者通过频谱分析提取图像的频谱特征。通过监督学习训练分类器,结合图像金字塔和滑动窗口技术实现山火的分类和定位。近年来随着深度学习的崛起,出现了将以卷积神经网络(convolutionneuralnetwork,cnn)为基础的分类或者目标检测技术引入山火检测领域的尝试。然而早期的方法过于依赖特征工程,难以获得适合山火检测的性能优异的特征描述子;而随后的二维cnn类方法只关注于空间特征的建模,虽然适用于图像级别的分类或检测,但应用在有显著运动特征的山火检测上仍然难以获得较高的精度。
技术实现要素:
为了克服传统的山火检测技术时空特征建模能力低下和误报率过高的不足,本发明提出了一种以三维卷积神经网络(3-dimensionalconvolutionneuralnetwork,3dcnn)为基础的山火检测技术,通过深度学习对山火的时空特征进行建模,获得性能优异的视频特征描述子,并在此基础上实现山火的高精度检测。
为实现上述目的,本发明采用如下技术方案:
一种基于三维卷积神经网络的山火检测方法,包括以下步骤:
s1、构建训练数据集:获取多个相同区域发生山火与未发生山火的视频,其中未发生山火的视频数量大于等于发生山火的视频数量,并分别用标签1和0标注;将所有视频裁剪为长度2秒的视频片段,对发生山火的视频,对视频片段中第一帧中山火区域的坐标进行标注获得训练数据集;
s2、采用10个三维卷积层、5个池化层和loss层构建三维卷积神经网络:将三维卷积层定义为convn,池化层定义为pooln,n是指层数,依次为:conv1、pool1、conv2、pool2、conv3、conv4、pool3、conv5、conv6、pool4、conv7、conv8、pool5、conv9、conv10、softmax层,其中,conv1-conv8的卷积核大小均为3x3x3,步长为[1,1,1],所有池化层的池化核大小为2x2x2,pool1的步长为[1,2,2],pool2-pool5的步长为[2,2,2],conv9的卷积核大小为1x3x3,步长为[1,1,1],conv10的卷积核大小为1x1x1,步长为[1,1,1];采用的损失函数包括物体存在与否的损失(lobj)、类别概率损失(lclass)和位置大小(lxywh)的损失,其中,lobj和lclass均采用二值交叉熵,其计算公式为:
li=-(yilogxi+(1-yi)log(1-xi)),i∈0,1,...,n-1
其中的x表示预测值,y表示目标值,n表示批量大小;
lxywh采用均方误差,其计算公式为:
li=(xi-yi)2,i∈0,1,...,n-1
最后总的损失是lobj、lclass和lxywh之和;
s3、对训练数据集,采用随机时空扰动、随机水平翻转及等比例缩放的方式将其规范化为16x224x224的视频片段后,对构建的三维卷积神经网络进行训练:采用以批量大小为30的随机梯度下降法进行训练,采用学习率预热方式,最开始的1000个批量逐渐将学习率从0提升至0.0005,然后保持,直到总迭代次数的90%和95%的时候分别将学习率降低5倍,总的训练周期为200;获得训练好的三维卷积神经网络;
s4、对实时获取的视频,将其分为视频片段后输入训练好的三维卷积神经网络3dnetdet,获得山火检测结果。
本发明的有益效果为:(1)以深度学习取代特征工程,自动提取图像序列的时空特征,大大提升特征描述子的开发效率;(2)以三维卷积取代传统的二维卷积,不仅能学习图像的空间模式,同时也能学习图像序列之间的运动模式,大大提升了视频特征描述子的表达和判别能力;(3)以3dcnn取代传统的二维卷积网络搭建目标检测器,大大提升了山火的检测精度。
附图说明
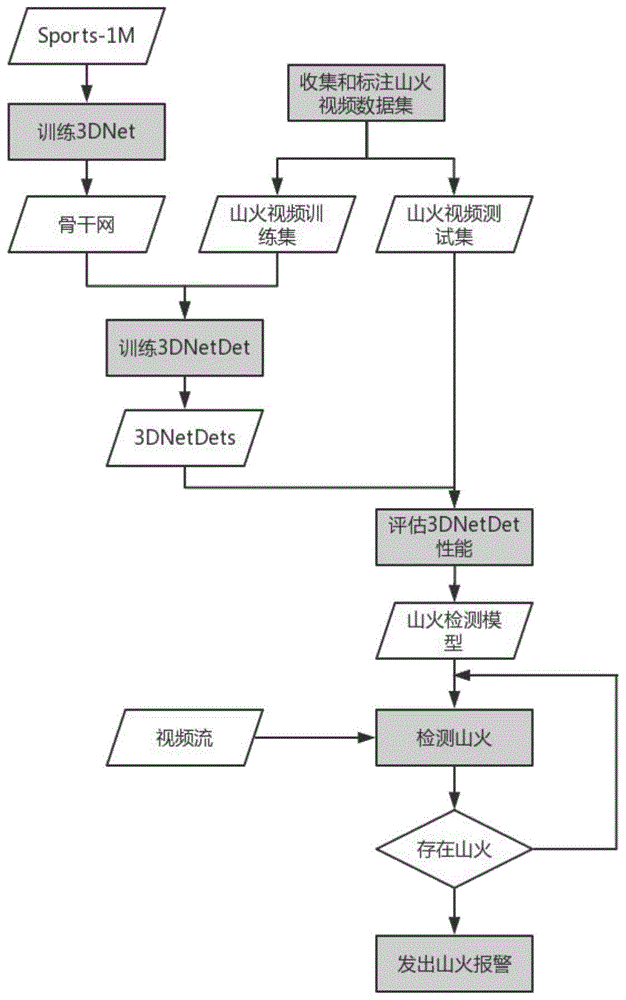
图1为山火检测流程图;
图2为以3dcnn为基础的分类器示意图;
图3为山火检测子网络示意图;
图4为矩形交集面积和并集面积示意图。
具体实施方式
下面结合附图和实施例对本发明进行进一步说明。
实施例
本例的处理流程如图1所示,在本例中,收集山火视频数据集的方式包括:从互联网新闻网站、视频网站或者大型的森林防火项目数据发布官网获取山火视频,还可以安排专人在保证安全的情况下模拟山火,并通过摄像机录像获取山火视频。同时收集至少同等数量的没有发生山火的关注类型区域的视频。将视频裁剪成长度为2秒的视频片段,分别用标签“0”和标签“1”标注没有山火和有山火的视频片段的类别。如果视频片段有山火,标注视频片段第一帧中山火区域的坐标,包括最上、最左、最下和最右边的坐标。汇集所有标注好的视频片段作为山火视频数据集,在本例中,通过测试集对所提出的方案进行验证,因此随机获取其80%的视频片段作为训练集,剩下的视频片段构成测试集。
搭建以3dcnn为基础的分类网络,将其命名为3dnet。如表1所示是3dnet的网络配置,表中通道顺序均遵循时间、高度、宽度的先后顺序。所有的三维卷积都采用3x3x3大小的卷积核,总共有8个三维卷积层。在卷积层conv1、conv2、conv4、conv6和conv8之后分别接最大池化层,5个池化核的大小均为2x2x2,除了第一个池化层以外,其余池化层的池化步长均为2,而第一个池化层在时间维度的步长为1,两个空间维度的步长为2。在最后一个池化层之后接两个包含4096个神经元的全连接层,最后接softmax层执行分类。
表1分类网络3dnet网络架构
在大型视频分类数据集sports-1m上训练3dnet。对于每个视频,从中随机提取5个2秒钟长的视频片段,并缩放至127x171。训练的时候,采用时空随机扰动的方法从视频片段中截取16x112x112的视频片段用于训练,并以50%的概率对视频片段进行水平翻转。以批量大小为30的随机梯度下降(sgd)训练,初始学习率设为0.003,每经过150000次迭代将学习率减半,总共训练20个周期。
搭建以3dnet为骨干网的山火检测网络3dnetdet。目标检测与图像分类相比,需要更多的细节信息,所以将网络的输入大小扩大2倍至16x224x224。将最后一个最大池化层之后的所有层去除,添加用于执行检测任务的模块。表2是3dnetdet网络检测模块配置。检测模块需要预测山火的类别和位置。loss/decoder层用于在训练的时候计算损失,或者在推理的时候解码山火的类别概率、位置和大小。3dnetdet的损失包含物体存在与否的损失(lobj)、类别概率损失(lclass)和位置大小(lxywh)等三个部分的损失。其中,lobj和lclass均采用二值交叉熵,其计算公式为:
li=-(yilogxi+(1-yi)log(1-xi)),i∈0,1,...,n-1(公式1)
其中的x表示预测值,y表示目标值,n表示批量大小。lxywh采用均方误差,其计算公式为:
li=(xi-yi)2,i∈0,1,...,n-1(公式2)
其中变量的含义同公式1。
表23dnetdet检测模块配置
在山火视频数据集的训练集上训练3dnetdet。以3dcnn分类网络的骨干网参数初始化3dnetdet的骨干网。对于训练集中的每个视频片段,采用随机时空扰动、随机水平翻转及等比例缩放的方式将其规范化为16x224x224的视频片段。与此同时,采用随机的色度、饱和度和亮度调整,以及对比度增强等方法处理规范化之后的视频片段,作为训练时3dnetdet的输入。以批量大小为30的随机梯度下降(sgd)训练。采用学习率预热技术,最开始的1000个批量逐渐将学习率从0提升至0.0005,然后保持,直到总迭代次数的90%和95%的时候分别将学习率降低5倍。总的训练周期为200。
在山火视频数据集的测试集上测试3dnetdet的检测性能。对于3dnetdet的每个预测值,将置信度低于0.005的预测值移除,同时以非最大值抑制合并同一物体的检测框,然后和山火的标注数据比较,计算准确率和召回率。对于每一个保留的预测值,如果预测框和真实框的最大的交并面积比(intersectionoverunion,iou)大于0.5,就认为这个预测值是有效的,对应类别的“真正”(truepositive,tp)计数器累加一;反之,则对应的“假正”(falsepositive,fp)计数器累加一。测试集中“假负”(falsenegative,fn)的数量和tp之和就是测试集中类别标签为“1”的视频片段的总数。分别以公式3和公式4计算准确率和召回率。
在部署3dnetdet检测山火时,从摄像机获取实时视频流,并将其切分成帧长为16的视频片段,同时要确保相邻的视频片段有8帧的重合。对于3dnetdet输出的预测值,如果其概率大于设定的阈值(阈值的典型值为0.5),就认为测试的视频片段描述了一例山火事件,于是结合对应的预测框位置、防山火设备安装位置信息(经纬度、海拔)、摄像头的内外参数以及地理信息系统推算着火点的空间坐标。防山火系统将3dnetdet的预测值和着火点空间坐标作为报警信息的一部分发送到相关责任单位。
- 还没有人留言评论。精彩留言会获得点赞!