一种功率谱密度估计的高效实现方法与流程
本发明属于通信数字信号处理领域,特别涉及基于认知无线电或者非协作通信中的频谱感知、功率谱密度分析、信号盲检测以及参数盲估计技术。
背景技术:
功率谱估计有着极其广泛的应用,不仅在认识一个随机信号时,需要估计它的功率谱。它还被广泛地应用于语音、图像、光电等信号处理中。在信号处理的许多场所,要求预先知道信号的功率谱密度(或自相关函数)。例如,在最佳线性过滤问题中,要设计一个维纳滤波器就首先要求知道(或估计出)信号与噪声的功率谱密度(或自相关函数)。根据信号与噪声的功率谱才能设计出能够尽量不失真的重现信号,这是功率谱估计在信号处理中的一个重要用途。
功率谱估计是数字信号处理的重要研究内容之一。经典功率谱估计主要包括周期图法和自相关法,但由于这两种方法的功率谱估计性能较差,便提出了周期图法的改进算法,及对其进行加窗、平均等修正。welch法作为周期图法的改进算法,主要有如下两点修正:(1)将数据分段,并且分段数据可以重叠,这样每段数据之间的相关性将会减低,由此改善方差特性;(2)每段数据都乘以同一个窗函数,窗函数的选择可以任意,这样直接周期图法中由矩形窗带来的频谱失真将得到改善。welch谱估计法算法简单稳定以及物理意义明确,在工程实现中应用比较广泛。
实际应用中,对于突发数据信号,在突发间隔满足条件下,可将因重叠可能丢失的数据存储在ram中,此时采用welch法可实现功率谱密度估计。但是在应对数据流时,由于数据重叠致使数据处理速度滞后于数据流速度,这将导致数据丢失。如何提高数据流功率谱估计的吞吐率,同时降低硬件资源消耗成为工程设计中的一个难点。
技术实现要素:
为解决上述技术问题,本发明提出一种功率谱密度估计的高效实现方法,采用两路并行fft实现架构提高功率谱密度估计的吞吐率,同时对fft输出结果做归一化,实现时钟频率高达250mhz,吞吐率为250msps的功率谱密度估计。
本发明采用的技术方案为:一种功率谱密度估计的高效实现方法,包括:
s1、采用welch算法将将长度为i的数据流均等分成l段,将这l段数据合并成奇数段与偶数段两部分;
s2、记fft的点数为n,取数据流前n点数据估计缩放因子;
s3、分别对已对齐的奇数段与偶数段两部分数据进行加窗并做fft变换;
s4、根据步骤s2的缩放因子分别对步骤s3的输出奇数段与偶数段的结果进行移位处理;
s5、对经步骤s4处理后的奇数段与偶数段的结果分别求平方后相加,得到信号幅度的平方;
s6、根据步骤s5的信号幅度,计算功率谱估计值。
进一步的,步骤s2具体为:
s21、取数据流前n点数据,加窗之后做fft,分别计算fft输出实部与虚部的绝对值,找到实部与虚部绝对值中的最大值;
s22、记fft输出有符号定点数kbits,其中小数mbits,找出最大值非零最高位的位置p;如果m≤p≤k-1,则缩放因子s_factor为p-m;如果0≤p≤m,则缩放因子s_factor为m-p。
进一步的,步骤s3包括:从第n+1点数据开始,采用第一双端口ram,对奇数段数据延迟n/2时钟周期,从第3n/2点开始偶数段数据到达,此时读取第一双端口ram中奇数段数据,使得奇偶两段数据对齐。
进一步地,步骤s4具体为:如果m≤p≤k-1,则将步骤s3的输出奇数段与偶数段的结果右移p-mbits;如果0≤p≤m,则将步骤s3的输出奇数段与偶数段的结果左移m-pbits。
进一步地,步骤s6具体为:使用第二双端口ram对功率谱做递归累加,当累加次数达到外部控制所设值时,结束功率谱密度计算,同时输出功率谱估计值。
进一步的,加窗所用窗函数的点数为n。
本发明的有益效果:一种功率谱密度估计的高效实现方法,通过将原welch算法对数据流拆分成的l段数据合并成奇数段与偶数段两部分,采用两路并行fft实现架构,实现时钟频率高达250mhz,吞吐率为250msps的功率谱密度估计;先对fft输出结果估计缩放因子,再采用移位的方式对fft输出结果做归一化,不仅省掉了除法器的使用,而且减少了后续乘法器的计算量,降低了硬件资源的消耗。
附图说明
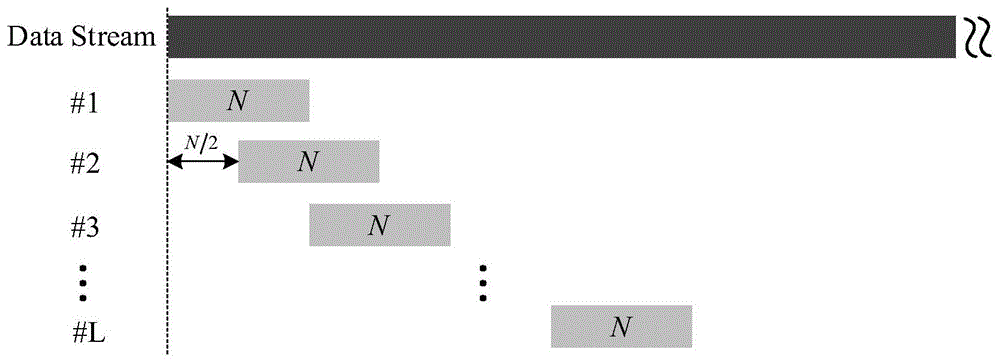
图1为welch算法分段数据流之间的重叠关系。
图2为将分段数据合并成奇偶部分后与原数据流的关系。
图3为功率谱密度估计的高效硬件实现架构。
具体实施方式
为便于本领域技术人员理解本发明的技术内容,下面结合附图对本发明内容进一步阐释。
本发明通过将原welch算法对数据流拆分成的l段数据合并成奇数段与偶数段两部分,记fft的点数为n,则偶数段数据与原数据流相差n/2点数据;采用两路并行fft实现架构分别对奇数段与偶数段数据做频域变换;在频谱叠加时为了保证奇偶两段数据对齐,采用ram对奇数段数据延迟n/2个时钟周期;利用fft首个n点输出估计缩放因子,根据缩放因子对fft后续输出做归一化,降低硬件开销。
n的值根据频谱分辨率来确定的,n越大频谱分辨率越高,同时越消耗硬件资源。
如图1所示为welch算法分段数据流之间的重叠关系,包括以下步骤:
将长度为i的数据流均等分成l段,由此得到的每段数据长度假设为j,并且假定相邻每段数据重叠长度为j/2,于是可以计算出welch算法所得段数如下:
图1中datastream表示数据流。
如图2所示为本发明将分段数据合并成奇偶部分后与原数据流的关系,重新调整图1分段数据间的关系,可以发现奇数段数据合并起来刚好与原始数据流一致,而偶数段合并起来与原始数据流相差最开始一个重叠长度。
图2中oddpart表示奇数段部分,evenpart表示偶数段部分。
如图3所示为本发明的功率谱密度估计的高效硬件实现架构图,包括以下的具体步骤:
(1)取数据流前n点数据,加窗之后做fft;即对fft首个n点输出,分别计算fft输出实部与虚部的绝对值,找到实部与虚部绝对值中的最大值;
(2)假设fft输出有符号定点数kbits,其中小数mbits,找出最大值非零最高位的位置p。如果m≤p≤k-1,则缩放因子s_factor为p-m;如果0≤p≤m,则缩放因子s_factor为m-p;
(3)从第n+1点数据开始,采用第一双端口ram1,对奇数段数据延迟n/2时钟周期,从第3n/2点开始偶数段数据到达,此时读取第一双端口ram1中奇数段数据,使得奇偶两段数据对齐;
(4)分别对奇偶两段数据加窗并做fft变换,如图3所示,奇数段数据的fft变换记做fft1,偶数段数据的fft变换记做fft2;本发明采用移位方式代替除法对fft输出做归一化,更易于硬件实现:根据步骤(2)计算所得的缩放因子,如果m≤p≤k-1,则缩放因子为p-m,表示fft输出是大于1的数,此时归一化需要将fft输出右移p-mbits;如果0≤p≤m,则缩放因子为m-p,表示fft输出是小于1的数,此时归一化需要将fft输出左移m-pbits;
本发明中窗函数的点数为n,窗函数的选择可以任意,比如汉宁窗,布莱克曼窗等。
(5)分别对归一化后的fft输出求平方,并将求平方后的奇偶计算所得结果相加,得到信号幅度的平方,即功率的估计值;
(6)使用第二双端口ram2对功率谱做递归累加,当累加次数达到外部控制所设值时,结束功率谱密度计算,同时输出功率谱估计值。外部设定值是根据需要达到功率谱密度估计的精度来确定的,累加次数越多精度越高,功率谱密度曲线越平滑。这个参数取值范围是大于或等于1,即至少要有一次重叠累加,没有设置上限。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!