一种用于执行人工神经网络pooling运算的装置和方法与流程
本公开涉及人工神经网络,具体地涉及一种用于执行pooling运算的装置和方法。
背景技术:
多层人工神经网络被广泛应用于模式识别,图像处理,函数逼近和优化计算等领域,多层人工网络在近年来由于其较高的识别准确度和较好的可并行性,受到学术界和工业界越来越广泛的关注。
pooling运算是指在神经网络的特征层中,进行局部特征的降采样运算,减少特征层的维度。pooling运算分为两种:maxpooling是指在kernel内,取最大值作为结果;avgpooling是指在kernel内,取平均值作为结果。此处的kernel即pooling核,大小是参数指定的,并根据步长stride在特征层上进行滑动,进行pooling运算,得到结果。
一种支持多层人工神经网络pooling运算的正向运算和反向训练的已知方法是使用通用处理器。该方法通过使用通用寄存器堆和通用功能部件执行通用指令来支持上述算法。该方法的缺点之一是单个通用处理器的运算性能较低,无法满足通常的多层人工神经网络运算的性能需求。而多个通用处理器并行执行时,通用处理器之间相互通信又成为了性能瓶颈。另外,通用处理器需要把多层人工神经网络反向运算译码成一长列运算及访存指令序列,处理器前端译码带来了较大的功耗开销
另一种支持多层人工神经网络pooling运算的正向运算和反向训练的已知方法是使用图形处理器(gpu)。该方法通过使用通用寄存器堆和通用流处理单元执行通用simd指令来支持上述算法。由于gpu是专门用来执行图形图像运算以及科学计算的设备,没有对多层人工神经网络运算的专门支持,仍然需要大量的前端译码工作才能执行多层人工神经网络运算,带来了大量的额外开销。另外gpu只有较小的片上缓存,多层人工神经网络的模型数据(权值)需要反复从片外搬运,片外带宽成为了主要性能瓶颈。另外,gpu只有较小的片上缓存,多层人工神经网络的模型数据(权值)需要反复从片外搬运,片外带宽成为了主要性能瓶颈,同时带来了巨大的功耗开销。
公开内容
本公开的一个方面提供了一种用于执行人工神经网络pooling运算的装置,包括控制器单元以及运算模块,其中:控制器单元用于将该指令译码成控制运算模块行为的微指令(或控制信号),然后将微指令发送至运算模块;运算模块用于根据接收到的微指令完成pooling运算。
本公开的另一个方面提供了一种使用上述装置执行人工神经网络pooling运算的方法。
本公开的另一方面提供了一种使用上述装置执行多层人工神经网络pooling运算的方法。
本公开还提供了一种电子装置,包括以上任一所述的装置。
本公开可以应用于以下场景中(包括但不限于):数据处理装置、机器人、电脑、打印机、扫描仪、电话、平板电脑、智能终端、手机、行车记录仪、导航仪、传感器、摄像头、云端服务器、相机、摄像机、投影仪、手表、耳机、移动存储、可穿戴设备等各类电子产品;飞机、轮船、车辆等各类交通工具;电视、空调、微波炉、冰箱、电饭煲、加湿器、洗衣机、电灯、燃气灶、油烟机等各类家用电器;以及包括核磁共振仪、b超、心电图仪等各类医疗设备。
附图说明
为了更完整地理解本公开及其优势,现在将参考结合附图的以下描述,其中:
图1示出了根据本公开实施例的用于执行pooling运算的装置的整体结构的示例框图。
图2示出了根据本公开实施例的用于执行pooling运算的装置中运算模块结构的示例框图。
图3示出了根据本公开实施例的pooling运算的正向运算的过程的示例框图。
图4示出了根据本公开实施例的pooling运算的反向训练的过程的示例框图。
图5示出了根据本公开实施例的pooling运算的正向运算的流程图。
图6示出了根据本公开实施例的pooling运算的反向运算的流程图。
在所有附图中,相同的装置、部件、单元等使用相同的附图标记来表示。
具体实施方式
根据本公开的pooling运算装置所基于的人工神经网络包括两层或者两层以上的多个神经元。对于maxpooling,在正向运算时,在pooling核内依次比较每一个输入向量,取最大值,得到输出向量,若需要反向训练,则同时保存对应的索引向量index;滑动pooling核,循环做上述运算操作,直至本层pooling运算结束。反向训练时,将输入梯度向量按照正向运算时保存的索引向量index,对应输出至相应存储位置,得到输出梯度向量;对于avgpooling,在正向运算时,在pooling核内累加每一个输入向量;然后乘以1/kernel_size,得到输出向量,kernel_size表示pooling核的大小;滑动pooling核,循环做上述运算操作,直至本层pooling运算结束;反向训练时,将输入梯度向量乘以1/kernel_size,对应输出至相应存储位置,得到输出梯度向量。
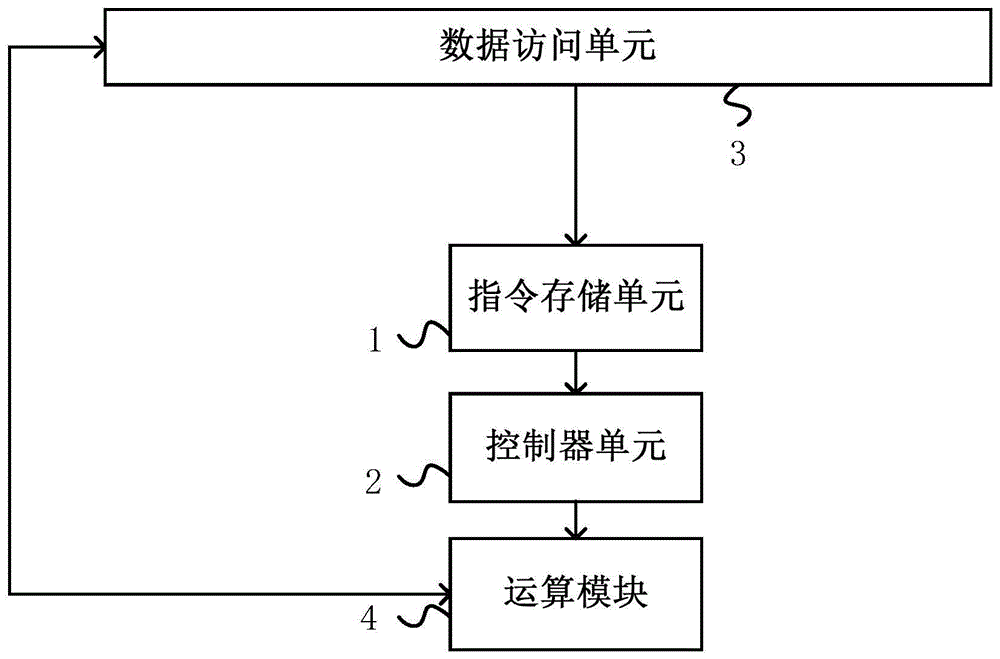
图1示出了根据本公开实施例的用于执行pooling运算的装置的整体结构的示例框图。如图1所示,该装置包括指令存储单元1、控制器单元2、数据访问单元3和运算模块4。指令存储单元1、控制器单元2、数据访问单元3和运算模块4均可以通过硬件电路(包括但不限于fpga、cgra、专用集成电路asic、模拟电路和忆阻器等)实现。
指令存储单元1通过数据访问单元3读入指令并缓存读入的指令。
控制器单元2从指令存储单元1中读取指令,将指令译成控制其他模块行为的微指令并发送给其他模块如数据访问单元3和运算模块4等,即,将指令译码成控制运算模块行为的控制信号,然后将控制信号分发至模块。
数据访问单元3能够访存外部地址空间,直接向装置内部的各个存储单元读写数据,完成数据的加载和存储。
所述运算模块用于完成maxpooling运算的求最大值运算,或用于完成avgpooling运算的累加和乘法运算;
图2示出了根据本公开实施例的用于执行pooling运算的装置中运算模块4的结构的示例框图。如图2所示,运算模块4包括运算单元41、数据依赖关系判断单元42和神经元存储单元43。
神经元存储单元43用于缓存运算模块4在计算过程中用到的输入数据和输出数据。运算单元41完成运算模块的各种运算功能。数据依赖关系判断单元42是运算单元41读写神经元存储单元43的端口,同时能够保证对神经元存储单元43中数据的读写不存在一致性冲突。具体地,数据依赖关系判断单元42判断尚未执行的微指令与正在执行过程中的微指令的数据之间是否存在依赖关系,如果不存在,允许该条微指令立即发射,否则需要等到该条微指令所依赖的所有微指令全部执行完成后该条微指令才允许被发射。例如,所有发往数据依赖关系单元42的微指令都会被存入数据依赖关系单元42内部的指令队列里,在该队列中,读指令的读取数据的范围如果与队列位置靠前的写指令写数据的范围发生冲突,则该指令必须等到所依赖的写指令被执行后才能够执行。控制器单元2输出的指令发送给运算单元41和依赖关系判断单元42,来控制其行为。
运算模块4完成pooling运算的正向运算和反向训练过程。其正向运算的过程以人工神经网络pooling层为例,maxpooling过程为:out=max(in),avgpooling过程为:out=avg(in)=σin*1/kernel_size,其中,out与in是列向量,kernel_size为pooling核kernel的大小,对于每一个输出向量out,都对应的是一组kernel内的输入向量in,通过kernel的在特征层上的滑动,循环完成整个pooling层的pooling运算。其反向训练的过程以人工神经网络pooling层为例,maxpooling过程为:out_gradient=index*in_gradient,avgpooling过程为:out_gradient=in_gradient*1/kernel_size,其中,out_gradient是输出梯度向量,in_gradient是输入梯度向量,index是maxpooling正向运算时,保存的输出神经元向量与输入神经元向量对应的索引向量,kernel_size为pooling核kernel的大小,其中每一个输入梯度向量in_gradient都对应一组输出梯度向量out_gradient。
根据本公开实施例,还提供了在前述装置上执行pooling运算正向运算和反向训练的指令集。指令集中包括config指令、compute指令、io指令、nop指令、jump指令和move指令,其中:
config指令在每层人工神经网络计算开始前配置当前层计算需要的各种常数;
compute指令完成每层人工神经网络的算术逻辑计算;
io指令实现从外部地址空间读入计算需要的输入数据以及在计算完成后将数据存回至外部空间;
nop指令负责清空当前装至内部所有微指令缓存队列中的微指令,保证nop指令之前的所有指令全部指令完毕。nop指令本身不包含任何操作;
jump指令负责控制器将要从指令存储单元读取的下一条指令地址的跳转,用来实现控制流的跳转;
move指令负责将装置内部地址空间某一地址的数据搬运至装置内部地址空间的另一地址,该过程独立于运算单元,在执行过程中不占用运算单元的资源。
本公开的执行pooling运算的方法包括如下几个阶段:
对于maxpooling,在正向运算时,由运算模块4依次完成比较每一个输入向量大小,取最大值的操作,得到输出向量,若需要反向训练,则同时保存对应的索引向量;循环读取新的pooling核kernel的输入向量,做上述比较大小的运算操作,得到新的kernel的输出向量,直至本层pooling运算结束。反向训练时,运算模块4根据正向运算时保存的索引向量,通过数据访问单元3将输入梯度向量对应输出至相应的存储位置,得到输出梯度向量;
对于avgpooling,在正向运算时,由运算模块4依次完成累加每一个输入向量;然后在运算模块4中完成乘以1/kernel_size运算,得到输出向量,kernel_size表示pooling核的大小;循环读取新的kernel的输入向量,做上述累加、乘法运算操作,得到新的kernel的输出向量,直至本层pooling运算结束;反向训练时,运算模块4将输入梯度向量乘以1/kernel_size,通过数据访问单元3将输入梯度向量对应输出至相应的存储位置,得到输出梯度向量。
图3示出了根据本公开实施例的神经网络pooling层正向运算过程的示例框图。对于avgpooling,在运算模块4中,对该pooling核kernel内的输入神经元向量分别进行累加,然后进行乘法运算,与1/kernel_size进行相乘,得到对应的输出神经元值,所有这些输出神经元值组成最终输出神经元向量,公式描述为:
out=σin*1/kernel_size,
其中out输出神经元向量、in是输入神经元向量、kernel_size是对应pooling核kernel的大小。根据控制器单元2的控制信号,运算模块4将输入神经元向量[in0,…,inn]暂存在神经元存储单元43中。然后将输入神经元向量进行累加,并在神经元存储单元43中存储中间结果向量。完成对整个kernel的输入神经元的累加后,对中间结果向量进行乘法运算,与1/kernel_size进行相乘,得到对应的输出神经元值。然后循环做下一个kernel的pooling运算,直至本层pooling运算结束。
对于maxpooling,在运算模块4中,依次对该pooling核kernel内的输入神经元向量进行比较大小运算,取最大值,得到对应的输出神经元值,所有这些输出神经元值组成最终输出神经元向量,公式描述为:
out=max(in),
其中out输出神经元向量、in是输入神经元向量。根据控制器单元2的控制信号,运算模块4将输入神经元向量[in0,…,inn]暂存在神经元存储单元43中。然后依次对输入神经元向量进行与中间结果向量比较大小操作,取最大值,并在神经元存储单元43存储中间结果向量,最后得到最后的输出神经元向量[out0,out1,out2,…,outn]。然后循环做下一个kernel的pooling运算,直至本层pooling运算结束。
图4示出了根据本公开实施例的神经网络pooling层反向训练过程的示例框图。计算输出梯度向量的maxpooling过程为out_gradient=index*in_gradient,其中index是maxpooling正向运算时得到的索引向量,其和输入梯度向量in_gradient相乘得到输出梯度向量,以传递梯度;avgpooling过程为out_gradient=1/kernel_size*in_gradient,其中kernel_size是对应的pooling核kernel的大小,其和输入梯度向量in_gradient相乘得到输出梯度向量,以传递梯度。
参考图4所示,in_gradient(图4中的[in0,…,in3])是第n+1层的输出梯度向量,得到第n层的输入梯度向量,该过程在运算模块4中完成,暂存在运算模块4的神经元存储单元43中。然后,输入梯度向量与索引向量index或1/kernel_size相乘得到第n层的输出梯度向量,out_gradient(图4中的[out0,…,out3])。
图5示出根据一个实施例的pooling运算正向运算流程图。该流程图描述利用本公开的装置和指令集实现的一种pooling运算正向运算的过程。
在步骤s1,在指令存储单元1的首地址处预先存入一条io指令。
在步骤s2,运算开始,控制器单元2从指令存储单元1的首地址读取该条io指令,根据译出的微指令,数据访问单元3从外部地址空间读取相应的所有pooling运算指令,并将其缓存在指令存储单元1中。
在步骤s3,控制器单元2接着从指令存储单元读入下一条io指令,根据译出的微指令,数据访问单元3从外部地址空间读取运算模块4需要的所有数据(例如,包括输入神经元向量、插值表、常数表等)至运算模块4的神经元存储单元43。
在步骤s4,控制器单元2接着从指令存储单元读入下一条config指令,根据译出的微指令,装置配置该层pooling运算需要的各种常数。例如,运算单元41根据微指令里的参数配置单元内部寄存器的值,所述参数例如包括本层计算的精度设置、激活函数的数据(例如本层计算的精度位,avgpooling时pooling核大小的倒数1/kernel_size等)
在步骤s5,根据compute指令译出的微指令,运算模块4的运算单元41从神经元存储单元43读取输入神经元向量和中间结果向量,完成对输入神经元向量的运算(avgpooling中是累加输入神经元向量,然后与1/kernel_size相乘,maxpooling是比较大小,求得最大值),并将最后的输出神经元向量写回至神经元存储单元43。
在步骤s6,控制器单元接着从指令存储单元读入下一条io指令,根据译出的微指令,数据访问单元3将神经元存储单元43中的输出神经元向量存至外部地址空间指定地址,运算结束。
图6是示出根据一个实施例的pooling运算反向训练流程图。该流程图描述利用本公开的装置和指令集实现一种pooling运算反向训练的过程。
在步骤t1,在指令存储单元1的首地址处预先存入一条io指令。
在步骤t2,运算开始,控制器单元2从指令存储单元1的首地址读取该条io指令,根据译出的微指令,数据访问单元3从外部地址空间读取与该pooling运算反向训练有关的所有指令,并将其缓存在指令存储单元1中。
在步骤t3,控制器单元2接着从指令存储单元读入下一条io指令,根据译出的微指令,数据访问单元3从外部地址空间读取运算模块4需要的所有数据至运算模块4的神经元存储单元43,所述数据包括输入梯度向量和maxpooling时需要的索引向量index。
在步骤t4,控制器单元2接着从指令存储单元读入下一条config指令,运算单元根据译出的微指令里的参数配置运算单元内部寄存器的值,包括该层pooling运算需要的各种常数,avgpooling时pooling核大小的倒数1/kernel_size、本层计算的精度设置、更新权值时的学习率等。
在步骤t5,根据compute指令译出的微指令,运算模块4的运算单元41从神经元存储单元43读取输入梯度向量和maxpooling时需要的索引向量index,完成乘法运算(avgpooling中是与1/kernel_size相乘,maxpooling是与索引向量index相乘),传递输出梯度向量,得到下一层反向训练的输入梯度向量,将其写回至神经元存储单元43。
在步骤t6,控制器单元接着从指令存储单元读入下一条io指令,根据译出的微指令,数据访问单元3将神经元存储单元43中的输出梯度向量存至外部地址空间指定地址,运算结束。
对于多层人工神经网络的pooling运算,其实现过程与单层神经网络的pooling运算类似,当上一层人工神经网络执行完毕后,下一层的运算指令会将运算模块中计算出的输出神经元向量或输出梯度向量作为下一层训练的输入神经元向量或输入梯度向量进行如上的计算过程,指令中的权值地址和权值梯度地址也会变更至本层对应的地址。
通过采用用于执行pooling运算的装置和指令集,解决了cpu和gpu运算性能不足,前端译码开销大的问题。有效提高了对多层人工神经网络pooling运算的支持。
通过采用针对pooling运算的专用片上缓存,充分挖掘了输入神经元和权值数据的重用性,避免了反复向内存读取这些数据,降低了内存访问带宽,避免了内存带宽成为pooling运算正向运算及反向训练性能瓶颈的问题。
前面的附图中所描绘的进程或方法可通过包括硬件(例如,电路、专用逻辑等)、固件、软件(例如,被具体化在非瞬态计算机可读介质上的软件),或两者的组合的处理逻辑来执行。虽然上文按照某些顺序操作描述了进程或方法,但是,应该理解,所描述的某些操作能以不同顺序来执行。此外,可并行地而非顺序地执行一些操作。
在前述的说明书中,参考其特定示例性实施例描述了本公开的各实施例。显然,可对各实施例做出各种修改,而不背离所附权利要求所述的本公开的更广泛的精神和范围。相应地,说明书和附图应当被认为是说明性的,而不是限制性的。
- 还没有人留言评论。精彩留言会获得点赞!