一种基于深度学习的非接触式自动贴图方法与流程
本发明主要涉及的是图像处理与计算机图形学中对三维模型的贴图方法及其过程,以及相机的内外参数估计方法,涉及人工智能领域的深度学习方法。
背景技术:
随着计算机技术的飞速发展,各行各业的数字化需求也与日俱增。数字化过程对于某些行业来说,就是将现实世界的物体使用计算机图形学的技术数字化到计算机中并加以存储和展示,而贴图过程是数字化的重要一环。贴图的过程是指对已有的原始纹理图片进行一定处理后,将纹理图片的颜色对应到三维模型的坐标上,使三维模型渲染时更贴近真实世界的外观。
现有的纹理贴图方法主要依靠具有一定贴图经验的艺术家与科技人员使用专业的贴图软件进行手工贴图,如:mudbox,3dmax等。由于对纹理贴图的精度要求,对一个三维物体的贴图过程可能需要使用多张不同角度的图像。在手工贴图的过程中最耗费时间的步骤就是将采集到的图像中需要的部分与三维模型精准的对齐,而这个过程中存在的问题是专业软件与拍摄图像使用的相机参数并不相同,所以图像与专业软件中的视角的扭曲程度不同,导致无法对齐。所以手工贴图的方式存在的缺点是耗费时间较长,并且质量较低。
自动贴图的方法能够较好的解决上述问题,自动贴图过程中重要的步骤就是获得相机的内外参数,但是现有的自动贴图方法主要是手工标定模型的特征点与对应纹理图中的屏幕坐标,然后通过坐标对获得相机的外参数,在进行手工标定模型时,许多方法为了便于标定在扫描过程中为模型中添加尖锐物体充当特征点,但是这种方法对于某些行业例如文物保护行业并不适用,因为这些行业要求在扫描过程中需要进行非接触式操作,所以添加尖锐物体并不可行。而且对于要求纹理图质量的行业也不适用,因为一个模型的可能有几十张纹理图,每张图片都进行手工选取坐标对仍然是一个很耗费时间的工作。
深度学习方法应用在各个领域都有显著成效,例如在图形学中外观采集领域使用深度学习的方法获取外观能够达到便捷高效并且较为准确的结果,在计算机视觉中人脸检测、自动驾驶等领域使用深度学习的方法不断被提出。所以深度学习能够帮助简化贴图过程中的手工任务,并且提高工作效率。
[参考文献]
[1]zhengyouzhang.aflexiblenewtechniqueforcameracalibration[j].1998.
[2]zhouy,tuzelo.voxelnet:end-to-endlearningforpointcloudbased3dobjectdetection[j].2017.
技术实现要素:
针对上述现有技术,本发明提出一种基于深度学习的非接触式自动贴图方法,从而针对类似于文物保护与数字化的行业进行自动非接触式自动贴图,主要是在原始图像采集的过程中添加非接触式的标定物来帮助相机参数估计,通过基于深度学习的方法自动获得每张图像中相机的外参数,得到参数后,使用计算机图形学的渲染方法自动对齐扫描得到的三维模型与图像,对齐后由用户决定图像使用的部分,自动将颜色值对应到物体三维模型上,完成贴图操作。
为了解决上述技术问题,本发明提出的一种基于深度学习的非接触式自动贴图方法,步骤如下:
步骤一、准备物体和使用的相机,通过张正友标定法对相机进行标定,标定过程中使用色彩测试卡充当标定板,标定结束后得到相机内参数;针对物体采集多张原始图像,在采集每张原始图像的过程中,记录焦距参数;从而得到原始图像和与每张原始图像对应的相机内参数;利用色彩测试卡图片对每张原始图像进行色彩校正,所得图像为图像a;
步骤二、建立并训练相机外参数估计网络,所述相机外参数估计网络为卷积神经网络;
步骤三、将图像a、相机内参数和物体的三维模型输入到训练好的相机外参数估计网络中,得到相机外参数;
步骤四、将相机外参数、相机内参数、物体的三维模型和图像a输入到渲染管线中,对所述相机外参数、相机内参数、物体的三维模型进行渲染处理后得到渲染结果,调整渲染结果与对应的图像a的轮廓的重合程度达到要求;
步骤五、用户根据需求在所述图像a中确定要使用的区域,渲染管线将该区域内的图像的颜色值根据uv坐标保存在一个纹理贴图文件中,至此完成自动贴图。
进一步讲,本发明所述的基于深度学习的非接触式自动贴图方法,其中:
步骤一的具体内容是:在搭建好采集纹理贴图的工作平台后,将色彩测试卡摆放到工作台上,使用相机对色彩测试卡在不同角度拍摄,拍摄4~7张图片;将获得的色彩测试卡的图片作为输入,传入到张正友标定法的代码中,得到色彩测试卡图片的相机内参数并记录下来,分别包括成像坐标系原点相对于像素坐标系原点偏移量(x0,y0)、成像坐标系与像素坐标系横纵坐标的缩放尺度α,β;利用相机对物体进行图像采集,获得该物体的多张原始图像,采集过程中记录当前相机使用的焦距f;利用色彩测试卡图片对原始图像进行色彩校正,得到图像a。
步骤二的具体内容是:建立相机外参数估计网络,相机外参数估计网络结构包括纹理特征提取网络、内参数特征提取网络、模型特征提取网络和全连接层a,对应所述的纹理特征提取网络、内参数特征提取网络、模型特征提取网络的输入分别为一张图像a、与图像a对应的相机内参数和物体的三维模型;
对所述相机外参数估计网络进行训练得到训练后的相机外参数估计网络,过程是:准备数据集,包括100个具有纹理的三维模型样本mi,随机生成相机内参数ii和相机外参数oi,在渲染管线中使用相机内参数ii、相机外参数oi和三维模型样本mi生成对应的图像样本ti;使用相机内参数ii、图像样本ti和三维模型样本mi作为相机外参数估计网络的输入,相机外参数oi作为标签训练相机外参数估计网络,所述相机外参数估计网络的输出是相机外参数oie,训练过程使用的损失函数表示为:
步骤三的具体内容包括:
步骤3-1:将图像a输入到训练后的相机外参数估计网络中的纹理特征提取网络中,所述纹理特征提取网络结构包括四个二维卷积层和全连接层b,四个二维卷积层依次记为第一二维卷积层、第二二维卷积层、第三二维卷积层和第四二维卷积层,每个二维卷积层后面依次有一层激活层和一层归一化层;将图像a输入到第一二维卷积层中,该第一二维卷积层对该图像a进行卷积,得到的是通道数为16的特征图输出,输出的特征由所述第一二维卷积层后面的激活层和归一化层依次操作后传入到后续的第二二维卷积层中,以此类推,经过第四二维卷积层后面的激活层和归一化层依次操作后,最后经过全连接层b得到1024维的纹理特征向量;
步骤3-2:将与所述图像a对应的相机内参数输入到训练后的相机外参数估计网络中的内参数特征提取网络中,所述内参数特征提取网络结构包括全连接层c;相机内参数经过全连接层c卷积后,得到512维的相机内参数特征向量;
步骤3-3:将物体的三维模型输入到训练后的相机外参数估计网络中的模型特征提取网络中,所述模型特征提取网络包括体素特征编码块、两个三维卷积层、两个二维卷积层和全连接层d,两个三维卷积层记为第一三维卷积层和第二三维卷积层,两个二维卷积层记为第五二维卷积层和第六二维卷积层,第五二维卷积层和第六二维卷积层后面依次有一层激活层和一层归一化层;先对物体的三维模型进行坐标归一化操作,然后进行体素化处理,将体素化的结果输入到体素特征编码块中进行卷积编码,得到的特征结果的维度为(128,128,128,16);将体素特征编码块提取的特征结果输入到第一三维卷积层后再经过第二三维卷积层的操作后得到一个四维特征,将该四维特征重塑为三维特征后输入到第五二维卷积层及其后面的激活层和归一化层,最后经过第六二维卷积层及其后面的激活层和归一化层的操作后,将第六二维卷积层后的归一化层输出的特征输入到全连接层d中,得到512维的模型特征向量;
步骤3-4:将上述的1024维的纹理特征向量、512维的相机内参数特征向量和512维的模型特征向量进行拼合,得到一个2048维的特征向量,输入到全连接层a中,输出结果即是估计的相机外参数;
重复上述步骤3-1至3-4,直至得到与每张图像a对应的相机外参数。
步骤四的具体内容包括:
步骤4-1:首先渲染管线读取物体的三维模型,将物体的三维模型的点云坐标输入到顶点着色器中,同时将步骤一得到的相机内参数和步骤三得到的相机外参数输入到顶点着色器中;
步骤4-2:在顶点着色器中对物体的三维模型中的点云进行坐标转换过程,使用的公式如下:
式中,x,y是转换后的屏幕坐标,(x0,y0)是成像坐标系原点相对于像素坐标系原点偏移量,α,β是成像坐标系与像素坐标系横纵坐标的缩放尺度,f为与图像a相对应的焦距,r为相机的外参数中的旋转矩阵,大小为3×3,t为相机外参数中的平移矩阵,是一个三维列向量,(xw,yw,zw)为点云中某点的坐标;
步骤4-3:将顶点着色器得到的转换结果传入片段着色器中,渲染过程中加入点光源,并且赋予银色的颜色;此时渲染出的结果图的视角与图像a的视角相同;
步骤4-4:读取图像a,将图像a同样渲染到当前窗口,并加入0.5的透明度;
步骤4-5:调整渲染出的结果图与对应的图像a的轮廓的重合程度达到要求为止。
步骤五的具体内容是:判断该物体的三维模型中的点哪些被实体部分遮挡住,使用反映射的方法将图像a中的屏幕坐标反映射到物体的三维模型上,从而将图像a的颜色值与未被遮挡的点对应起来,在用户确定的图像a中使用区域内,将图像a使用区域内每个颜色值赋给对应的未被遮挡住的点,将物体的三维模型中给出的未遮挡点的uv坐标作为一个零矩阵的索引,将颜色值记录在矩阵中;
重复上述过程,依次遍历该物体的三维模型对应的所有的图像a,最终将根据uv坐标位置记录颜色值的矩阵保存在一个纹理贴图文件中;之后使用时根据物体的三维模型的uv坐标即可提取出该三维模型每个点的纹理。
与现有技术相比,本发明的有益效果是:
本发明是基于卷积神经网络的相机参数估计过程,并且提出了完备的自动贴图系统与方法,相比于以往的方法能够在非接触式的基础上大量减少贴图过程中的手工步骤。同时使用物理相对准确的渲染管线渲染出的数据作为训练数据训练网络能够得到较好的结果,使用渲染管线(opengl)实现了自动贴图过程,并且能够接受用户传入的参数,同时用户能够进行微调,能够加速对贴图有高质量要求的任务的贴图速度。
附图说明
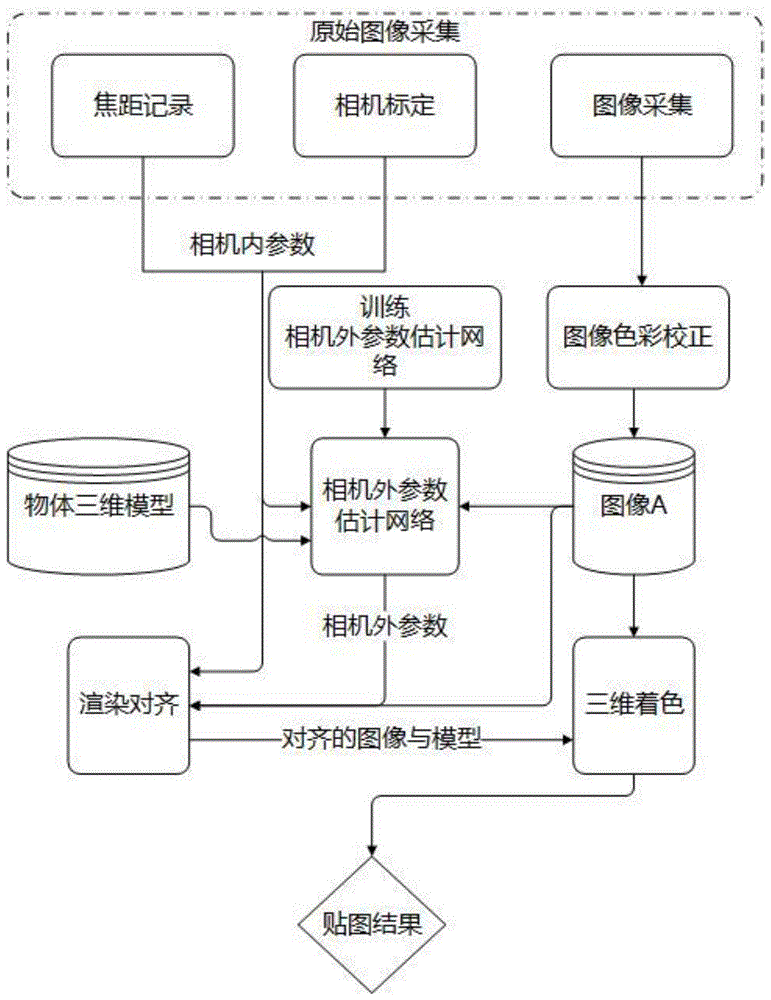
图1为本发明基于深度学习的非接触式自动贴图方法的流程图;
图2为获取相机外参数的网络结构。
具体实施方式
下面结合附图及具体实施例对本发明做进一步的说明,但下述实施例绝非对本发明有任何限制。
本发明提出了一种基于深度学习的非接触式自动贴图方法,设计思路是使用深度学习的方法代替传统的使用标定点对获取相机参数的方法。方法实施的基本步骤是:如图1所示,首先准备要采集的物体、采集使用的相机和物体的三维模型,然后通过张正友标定法[1]对相机进行标定,标定过程中使用色彩测试卡充当标定板,标定结束后得到了相机的内参数,但是由于采集每张图像的过程中要变换焦距,所以焦距参数需要手动记录;之后使用色彩测试卡的图片对原始图像进行色彩校正;这样就得到了图像a和与每张图像a对应的相机内参数。将得到的相机内参数和图像a与准备好的三维模型输入到训练好的如图2所示的相机外参数估计网络中。所述相机外参数估计网络为卷积神经网络,由三个部分组成,分别是贴图特征提取网络、内参数特征提取网络和模型特征提取网络。由相机外参数估计网络得到外参数后,将相机外参数、相机内参数、物体的三维模型和图像a输入到渲染管线中,使用渲染管线进行渲染对齐,使得调整渲染结果与对应的图像a的轮廓的重合程度达到要求,得到对齐的渲染结果后用户进行微调,并且确定一个长方形区域的大小,渲染管线会根据长方形的大小决定使用每张图像a的部分,然后将图像a的颜色值根据uv坐标保存在一个纹理贴图文件中中方便下次使用。
本发明基于深度学习的非接触式自动贴图方法具体的实现步骤如下:
步骤一:采集原始图像并进行色彩校正,得到图像a与相机内参数。
采集原始图像时需要进行的参数恢复步骤如下:
步骤1-1:在搭建好采集原始图像的工作平台后,将色彩测试卡摆放到工作台上,使用相机对色彩测试卡在不同角度拍摄,拍摄5张图片左右。
步骤1-2:将步骤1中获得的色彩测试卡的图片作为输入,传入到张正友标定法的代码中,得到色彩测试卡图片的相机的内参数,内参数并记录下来,包括成像坐标系原点相对于像素坐标系原点偏移量(x0,y0)、成像坐标系与像素坐标系横纵坐标的缩放尺度α,β;
步骤1-3:利用相机对物体进行图像采集,获得该物体的多张原始图像,采集过程中记录当前相机使用的焦距f;
步骤1-4:根据色彩测试卡使用专业软件并利用色彩测试卡图片对原始图像进行色彩校正,之后得到的图像记为图像a。
步骤二:对相机外参数估计网络进行训练。
建立相机外参数估计网络,相机外参数估计网络结构如图2所示,分为三个特征提取部分:纹理特征提取网络、内参数特征提取网络和模型特征提取网络,对应每个特征提取网路的输入分别为一张图像a、此图像a对应的相机内参数和三维模型;同时,该相机外参数估计网络结构还包括一个全连接层a。
对此网络进行训练需要准备数据集,是100个具有纹理的三维模型,一个三维模型样本记为mi,随机生成相机内参数与外参数,分别记为ii,oi,在渲染管线中使用相机内参数与外参数ii,oi和三维模型样本mi生成对应的图像样本,记为ti。使用相机内参数ii、渲染得到的图像样本ti和三维模型样本mi作为该网络的输入,相机外参数oi作为标签训练网络,该网络估计出来的相机外参数记为oie使用的损失函数表示如下:
式中,
步骤三:将准备好的物体三维模型、图像a与每张图像a对应的相机内参数输入到训练好的相机外参数估计网络中,得到每张贴图的相机外参数。
此步骤的任务将每张图像a联合上一步求得的相机内参数和扫描得到的物体的三维模型同时输入进相机外参数估计网络中,该网络的输出是此图像a的相机外参数。如图2所示,相机外参数估计网络包括了三个特征提取部分和一个全连接层,记为全连接层a(dense-a),三个特征提取部分分别是纹理特征提取网络、内参数特征提取网络和模型特征提取网络。最后将三个特征提取网络的输出拼合到一起再输入到最后的全连接层a中,得到最后的外参数估计结果。
相机外参数估计网络的参数估计过程包括以下步骤:
步骤3-1:将图像a(texture)输入到训练后的相机外参数估计网络中的纹理特征提取网络中,所述纹理特征提取网络结构包括四个二维卷积层和全连接层,全连接层记为全连接层b(dense-b),四个二维卷积层依次记为第一二维卷积层(conv2d-1)、第二二维卷积层(conv2d-2)、第三二维卷积层(conv2d-3)和第四二维卷积层(conv2d-4),每个二维卷积层后面依次有一层激活层(relu)和一层归一化层(bn)(图2中conv2d灰色部分),。该纹理特征提取网络参数如表1所示。
表1纹理特征提取网络参数
当前步骤的数据流动如下:读取宽度为w高度为h有rgb三通道的图像a,将图像a由0-255的整数归一化为0-1的浮点数,归一化方法可以选择图片所有像素同时除以255。然后输入到第一二维卷积层中,该卷积层对图片进行卷积,得到的是通道数为16的特征图输出,输出的特征由激活层进一步激活,然后传入到归一化层进行归一化操作。归一化后的特征传入后续的二维卷积层(第二、第三和第四)中,经过第四二维卷积层后面的激活层和归一化层依次操作后,最后经过全连接层b计算得到提取的特征。特征的维度是1024维。
步骤3-2:与所述图像a对应的相机内参数(图2中i)输入到内参数特征提取网络中,内参数特征提取网络结构仅包括一个全连接层,记为全连接层c(dense-c)。内参数经过全连接层c卷积后,得到了512维的内参数特征向量。内参数特征提取网络的参数如表2所示。
表2内参数特征提取网络参数
步骤3-3:将物体的三维模型(mesh)输入到模型特征提取网络中,得到与该模型相关的特征向量。模型特征提取网络的结构有一个体素特征编码块(vfe)、两个三维卷积层和两个与纹理特征提取网络中相同的含有激活层和归一化层的二维卷积层,两个三维卷积层分别命名为第一三维卷积层(conv3d-1)与第二三维卷积层(conv3d-2),两个二维卷积层,顺次命名为第五二维卷积层(conv2d-5)和第六二维卷积层(conv2d-6),最后还包括一个全连接层,该全连接层记为全连接层d(dense-d)。模型特征提取网络参数如表3所示。
表3模型特征提取网络参数
模型特征提取网络的数据流动如下:
首先将物体的三维模型文件进行体素化,由于点云坐标是由三维扫描仪扫描得到,所以坐标尺度不能确定,在对该三维模型进行体素化之前,需要进行一个坐标归一化的操作。归一化的过程:首先通过遍历模型文件中点云的坐标值,记录点云坐标在三个方向上的最大值:
m0=max(max(vix,viy,viz))vi∈v
其中v是点云坐标集;然后模型所有坐标都除以这个最大值;经过上述操作,该模型的所有坐标都落在了[-1,1]中。
对坐标进行归一化之后,将模型在三个分量上分别切割为128个体素块,即一个体素块的边长为2.0/128,然后将体素化的结果输入到vfe(体素特征编码块)中,vfe为yinzhou在2017年的研究成果[2],作用是对输入的体素块进行卷积编码。
体素特征编码块vfe中的结构为一层随机采样操作(sampling),两层全连接层(dense-vfe1,dense-vfe2),两层最大池化层(pooling-1,pooling-2)与一层拼合(concat)操作。数据流动方向如下:假设输入的模型切割为(h,w,d)个体素块,首先对体素化的模型中每个体素块进行随机采样操作,在每个体素块中根据采样率采样部分点云坐标,然后对每个体素块将随机采样得到的点云坐标输入到dense-vfe1全连接层中,得到逐点特征,输入到pooling-1最大池化层中得到本地聚合特征,将本地均值特征与逐点特征进行拼合(concat)得到当前体素块的逐点均值特征,将逐点均值特征依次输入到dense-vfe2全连接层与pooling-2最大池化层中,得到了最后能够表达当前体素的特征向量,维度为c。对每个体素块执行上述操作,则得到了表示整个模型的特征,维度为(h,w,d,c)。详细的操作步骤参见文献[2],这里不再赘述。
由于本步骤的目的是估计相机的外参数,不需要高精度的模型,所以在vfe的采样阶段,本发明使用的是1%作为采样率,16作为体素块的特征维度。vfe得到的特征维度为(128,128,128,16)。
如图2所示,将体素特征编码块vfe提取的特征结果输入到三维卷积层中,三维卷积层的作用与二维卷积层作用类似,同样是使用卷积运算提取特征。在经过第一三维卷积层(conv3d-1)和第二三维卷积层(conv3d-2)的操作之后,重塑输出特征的形状,内容不变,将第二三维卷积层(conv3d-2)输出的四维特征重塑为三维特征,然后输入到第五二维卷积层(conv2d-5)和第六二维卷积层(conv2d-6)中进行操作,这两个二维卷积层末尾同样都有激活层与归一化层。最后将提取出的特征输入到全连接层d中。最后得到512维的模型特征向量。
步骤3-4:将上述三个步骤得到的三个特征向量(包括1024维的纹理特征向量、512维的相机内参数特征向量和512维的模型特征向量)进行拼合,得到一个2048维的特征向量,输入到最后的全连接层a中,输出结果即是估计的相机外参数。
在相机外参数估计网络的结构中,各个层的作用如下:
卷积层的作用是提取图像或体素的特征,通过卷积运算,提取输入矩阵的高维信息,然后将这些高维信息作为特征输出。相机外参数估计网络结构中使用的填充方式是不足补0的方法,代码实现时参数传入的是‘same’。在构建卷积层时还有其他几个参数需要设置,例如卷积核数、卷积核大小、卷积步长等。
激活层的作用是将线性的卷积操作转化为非线性的操作,使相机外参数估计网络能够模拟更复杂的函数形式,本文中使用的使泄露修正线性单元(leakyrelu),它的函数形式如下:
归一化层的作用是将提取出来的特征中心点规范化到0的位置,帮助训练更加稳定,收敛更快,防止出现训练崩溃的情况。在本发明中使用的归一化函数为批归一化(batchnormalization)。
全连接层的作用是对特征进行矩阵向量乘积的操作,意义在于将输出的每个神经元都与其他的神经元关联起来,将相机外参数估计网络的感受野进一步扩大。
最大池化层的作用是将输入的特征进行局部最大保留操作,目的是在保留最显著特征的同时减少特征数量。
本发明中,通过上述步骤三可以得到的结果是与每张图像a对应的相机外参数。
步骤四:得到了相机的内参数和外参数之后,就可以使用渲染管线进行渲染对齐。
本发明中所称的渲染对齐是指:通过渲染管线渲染出的结果图与对应的图像a的轮廓的重合程度达到用户要求的状态。渲染对齐过程步骤如下:
步骤4-1:首先渲染管线读取物体的三维模型,将物体的三维模型的点云坐标输入到顶点着色器中,同时将步骤一得到的相机内参数和步骤三得到的相机外参数输入到顶点着色器中。
步骤4-2:在顶点着色器中对物体的三维模型中的点云进行坐标转换过程,使用的公式如下:
式中,x,y是转换后的屏幕坐标,(x0,y0)是成像坐标系原点相对于像素坐标系原点偏移量,α,β是成像坐标系与像素坐标系横纵坐标的缩放尺度,f为与图像a相对应的焦距,r为相机的外参数中的旋转矩阵,大小为3×3,t为相机外参数中的平移矩阵,是一个三维列向量,(xw,yw,zw)为点云中某点的坐标;
步骤4-3:将顶点着色器得到的转换结果传入片段着色器中,渲染过程中加入点光源,并且赋予银色的颜色;此时渲染出的结果图的视角与图像a的视角相同;
步骤4-4:读取图像a,将图像a同样渲染到当前窗口,并加入0.5的透明度;
步骤4-5:调整渲染出的结果图与对应的图像a的轮廓的重合程度达到要求为止。
步骤五:对齐后需要用户确定一个长方形区域的大小,渲染过程会根据长方形的大小决定贴图使用的区域,最后将图像a的颜色根据模型的uv坐标保存在一个纹理贴图文件中,方便以后使用。
本发明中,渲染管线使用opengl库实现完成。
首先,在步骤4得到对齐的结果之后,需要判断模型中的点哪些是在视野范围内的,哪些被遮挡住了。判断的方法就是使用类似于opengl库中深度测试的方法,在顶点着色器中已经进行了坐标转化,得到了相机坐标,同时也得到了深度值,深度值能够检测点是否被遮挡。对于那些未被遮挡的点,根据用户确定的长方形大小,使用opengl库的反映射函数将长方形区域中图像a中每个颜色值的屏幕坐标反映射到模型上,将图像a的颜色值赋给对应的未被遮挡住的点。
记录的方式是:首先创建一个全为0并且足够大的方形矩阵,每个元素的坐标除以行或者列的最大值就是对应的uv坐标。依次遍历所有图像a,根据模型中给出的未遮挡点的uv坐标,将每张图像a颜色值以对应点的uv坐标位置作为一个零矩阵的索引,将颜色值记录在矩阵中,重复上述过程,依次遍历该物体的三维模型对应的所有的图像a,最后得到了方形的纹理贴图矩阵,将矩阵保存成一个纹理贴图文件,之后使用时根据模型的uv坐标即可提取出物体三维模型中每点的纹理,至此实现了自动贴图。
尽管上面结合附图对本发明进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨的情况下,还可以做出很多变形,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!