一种基于门控循环单元网络的水泥成品比表面积预测方法与流程
本发明涉及水泥磨水泥成品质量指标-比表面积预测技术领域,尤其是一种基于门控循环单元网络的水泥成品比表面积预测方法,用于水泥磨研磨过程水泥成品比表面积在线预测。
背景技术:
水泥工业是我国经济发展、生产建设和人民生活不可或缺的原材料工业,水泥的性能会直接影响到混凝土的性能,而水泥的性能又和水泥的比表面积密切相关。水泥的比表面积就是单位质量的水泥具有的表面积,比表面积可作为评价水泥细度的指标,水泥磨的细,比表面积越大,反之,比表面积越小。通常情况下,如果比表面积过大,将导致水泥的水化速度过快、放热快且集中、混凝土收缩显著提高,将会导致混凝土早期开裂等质量问题。而比表面积太小,水泥颗粒太粗,也会影响到混凝土的质量。因此,比表面积作为评价水泥品质的重要指标应保持在合适的范围内,而实现比表面积的在线预测对于提高混凝土质量具有重要意义。但在水泥成品的比表面积预测方面,由于水泥磨工业流程本身具有时滞和随机性等特点,难以用传统的线性模型来进行预测。
针对上述问题,王贵生等人采用一元线性回归法建立了45μm水泥细度和水泥比表面积的回归方程,水泥细度利用负压筛析仪进行检测,将水泥细度数据带入回归方程中即可求得相应的比表面积。但这种方法仅根据单一指标进行预测,说服力不强,而且没有考虑到水泥磨复杂工况下的变量耦合、时变时延等问题,该方法进行比表面积的预测会产生较大的误差。
技术实现要素:
本发明需要解决的技术问题是提供一种基于门控循环单元网络的水泥成品比表面积预测方法,既能够解决水泥磨复杂工况多变量、强耦合,难以建立机理模型的特点,又能够解决变量数据与水泥成品比表面积指标之间存在的时变时延问题。
为解决上述技术问题,本发明所采用的技术方案是:
一种基于门控循环单元网络的水泥成品比表面积预测方法,包括以下步骤:
步骤1:分析水泥磨工艺流程选取与比表面积相关的8个输入变量,首先将选择的变量数据按照时间序列排列,其次将数据按照gru的输入格式进行处理,再将数据进行归一化作为gru的输入数据;
步骤2:将归一化后的训练数据输入到gru模型中进行训练,输入数据进入到隐层,通过gru网络结构中的更新门来决定前一时刻和当前时间步的信息有多少需要继续进行传递,通过重置门来决定有多少之前时刻的信息需要进行遗忘,最后将单元状态和输出合并为一个最终状态,从而更新当前序列索引的预测输出,完成门控循环单元网络的前向传播;
步骤3:采用基于时间的反向传播算法计算每个神经元的误差项;从输入数据及权重开始,向着输出层传递,最后求出预测值并和目标值构成代价函数;在反向传播的过程中,以代价函数开始,从输入到输出,求各个节点的偏导数,然后利用自适应矩估计算法更新权重参数和偏置参数,重复反向传播过程,直到代价函数的误差满足要求或者到达指定的迭代次数为止;经过上述过程的反复训练,即可实现误差的最小化;
步骤4:将处理后的水泥磨研磨过程中的过程变量数据输入到步骤3中训练好的门控循环单元网络模型,实现水泥磨研磨过程水泥成品比表面积的在线预测。
本发明技术方案的进一步改进在于:步骤1中,与比表面积相关的8个输入变量为喂料量反馈、a磨主机电流、2402开度反馈、a磨循环风机变频反馈、a磨出磨斗提电流反馈、选粉机电流反馈、选粉机转速反馈、8406挡板反馈。
本发明技术方案的进一步改进在于:步骤1中,将输入数据按照gru网络的输入格式进行重构,并将数据进行归一化;归一化使用min-max归一化,公式如下:
其中,x1,x2,...,xn为输入序列,y1,y2,...,yn为归一化后的输出序列。
本发明技术方案的进一步改进在于:步骤2中,门控循环单元网络的前向传播具体的计算过程如下:
gru需要学习的参数共3组,分别是:更新门的权重矩阵wz、重置门权重矩阵wr以及计算单元状态的权重矩阵wh;随机初始化这些权值并开始前向传播:
①更新门来决定前一时刻和当前时间步的信息有多少需要继续进行传递,更新门的输出由前一时刻隐藏状态输出和当前时刻输入共同决定,更新门的计算:
zt=σ(wz·[ht-1,xt]+bz)(1)
上式中,wz是更新门的权重矩阵,[ht-1,xt]表示将前一时刻隐含层状态ht-1和当前时刻输入xt连接成一个更长的向量,σ是sigmoid激活函数,bz为更新门偏置项;
②重置门来决定有多少之前时刻的信息需要进行遗忘,重置门的输出同样由前一时刻隐藏状态输出和当前时刻输入共同决定,重置门的计算:
rt=σ(wr·[ht-1,xt]+br)(2)
上式中,wr是重置门的权重矩阵,[ht-1,xt]表示将前一时刻隐含层状态ht-1和当前时刻输入xt连接成一个更长的向量;σ是sigmoid激活函数,br为重置门偏置项;
③当前输入的单元状态计算:
上式中,wh是单元状态的权重矩阵,rt是重置门的输出,ht-1为前一时刻隐含层状态,xt为当前时刻的输入,tanh是双曲正切激活函数,bh为单元状态偏置项;
④隐含层最终输出由上一时刻的单元状态、当前时刻候选单元状态和更新门输出共同决定:
上式中,h为当前时刻隐含层输出,zt为更新门的输出,ht-1为前一时刻隐含层状态,
⑤更新索引序列预测输出:
上式中,
式(1)到式(5)完成gru模型的前向传播。
本发明技术方案的进一步改进在于:步骤3中,具体的计算过程如下:
采用基于时间的反向传播法,反向计算每个神经元的误差项,一方面,误差项沿时间反向传播,从当前时刻开始,计算之前每个时刻的误差项,另一方面是将误差项向上一层传播;根据相应的误差项,计算每个权重的梯度,更新权重;为了计算方便,将权重矩阵wr、wz、wh拆分成wrh、wrx、wzh、wzx、whh、whx;
①误差项的传播分为两部分,a.沿时序反向传播;b.向上一层传播;定义损失函数:
上式中,
在t时刻,gru隐含层输出为ht,定义t时刻的误差项δt为:
根据gru的计算图和链式求导法则可知,候选状态信息
上式中,l为损失函数,zt为更新门的输出;
更新门梯度为:
重置门梯度为:
上式中,rt是重置门的输出,ht-1为前一时刻隐含层状态;
a.则误差项沿时序反向传播的公式为:
b.误差项向上层传播:
设当前层为l层,定义l-1层的误差项是误差函数对l-1层加权输入的导数,则有
上式中,
本次gru的输入xt由下面的公式得出:
上式中,fl-1表示第l-1层的激活函数;
由全导公式递推可知:
上式中,
②权重梯度的计算
由①可知wrh、wzh、whh各时刻的权重梯度为:
wrx、wzx、whx的权重梯度:
与权重对应的偏置br,bz,bh梯度为:
从①~②,我们求出了在t之前的所有时刻损失函数相对于各参数的梯度,下面进行权重的更新;
③权重的更新,η为模型的学习率,为了增加公式的适用性,对公式
进行泛化,w表示网络中四个节点的权重,l代表四个节点的偏置项;
至此,完成一次前向和反向传播,循环迭代地更新各个部分,每经过一个时间步,求得误差项,若误差项小于阈值,则进行权重矩阵w和偏置项b的更新,知道误差小于设定阈值或达到最大训练次数,退出循环,完成训练。
由于采用了上述技术方案,本发明取得的技术进步是:
1、本发明建立的水泥磨研磨过程水泥成品质量指标-比表面积预测模型,将各变量按照时间序列排列作为输入层,对应于某一时刻的水泥成品比表面积,构建门控循环单元网络模型,消除了变量的时变时延特性对比表面积预测的影响。
2、本发明建立的基于长短时记忆网络的水泥磨研磨过程水泥成品质量指标-比表面积预测模型,充分利用变量数据和预测指标的时序特性,不但具有循环神经网络(rnn)模型的记忆功能,并且能够克服rnn存在的梯度爆炸和梯度消失问题,能选择性的遗忘无效信息并更新记忆有效信息,能在一定程度上解决长期以来本领域存在的技术问题。
3、本发明在模型的反向传播中,采用自适应矩估计算法,通过误差项的反向传播求得权重梯度,从而更新权重和偏置,模型精度和训练效率都很高。
4、本发明既能够解决了水泥磨复杂工况多变量、强耦合,难以建立机理模型的特点,又能够解决变量数据与水泥成品比表面积指标之间存在的时变实延问题,有利于指导水泥磨系统生产调度,将水泥成品比表面积控制在合适的范围内,提高水泥成品性能。
附图说明
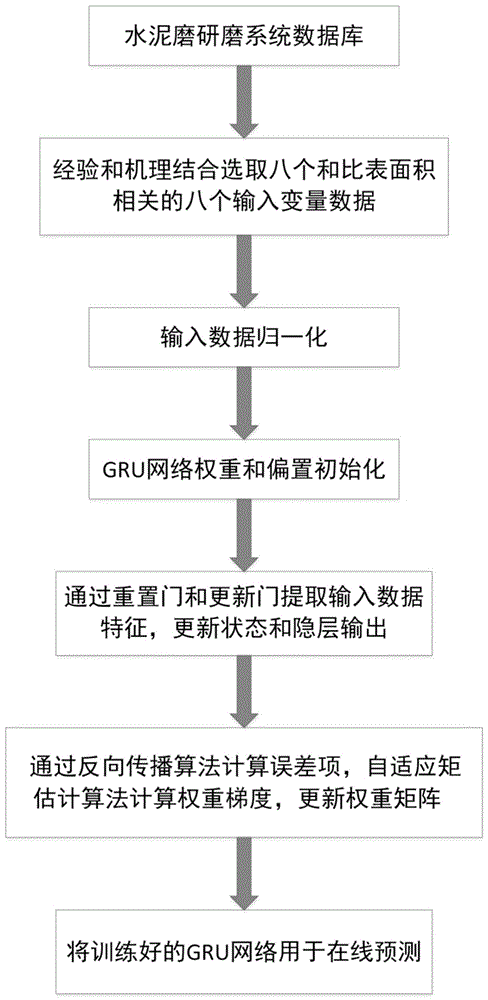
图1是本发明在线预测模型流程图;
图2是本发明在线预测模型的结构图;
图3是门控循环单元网络隐含层结构图。
具体实施方式
本发明是针对水泥磨工业流程本身具有时滞性和随机性,难以用传统的线性模型来进行预测等特点,目前本技术领域现有的研究方法难以解决水泥磨复杂工况下的变量耦合、时变时延等问题而研发的一种基于门控循环单元网络的水泥成品比表面积预测方法。
“循环神经网络”英文为recurrentneuralnetworks,缩写为cnn;
“门控循环单元网络”英文为gatedrecurrentunit,缩写为gru;
“反向传播算法”英文为back-propagationthroughtime,缩写为bptt;
“自适应矩估计算法”英文为adaptivemomentestimation,缩写为adam。
下面结合附图对本发明做进一步详细说明:
如图1、2、3所示,一种基于门控循环单元网络的水泥成品比表面积预测方法,包括以下步骤:
步骤1:分析水泥磨工艺流程选取与比表面积相关的8个输入变量,首先将选择的变量数据按照时间序列排列,其次将数据按照gru的输入格式进行处理,再将数据进行归一化作为gru的输入数据;
首先分析整个水泥磨的生产工艺,结合现场工程师的经验知识以及水泥比表面积的测量工艺,选取了8种与水泥成品比表面积相关的过程参量作为gru模型的输入变量,如图2中输入层所示,8输入变量分别为喂料量反馈p1、a磨主机电流p2、2402开度反馈p3、a磨循环风机变频反馈p4、a磨出磨斗提电流反馈p5、选粉机电流反馈p6、选粉机转速反馈p7、8406挡板反馈p8。充分考虑水泥生产过程的时延和时长,将一段时间的输入变量对应某一时刻的比表面积指标的输出,并从水泥磨研磨系统数据库中导出相关输入输出变量数据。由于所选取的变量有些波动较大,为了提高模型收敛速度以及减少数据特征的损失,对数据进行归一化处理。
将输入数据按照gru网络的输入格式进行重构,并将数据进行归一化;归一化使用min-max归一化,公式如下:
其中,x1,x2,...,xn为输入序列,y1,y2,...,yn为归一化后的输出序列。
步骤2:将归一化后的训练数据输入到gru模型中进行训练,输入数据进入到隐层,通过gru网络结构中的更新门来决定前一时刻和当前时间步的信息有多少需要继续进行传递,通过重置门来决定有多少之前时刻的信息需要进行遗忘,最后将单元状态和输出合并为一个最终状态,从而更新当前序列索引的预测输出,完成门控循环单元网络的前向传播;
归一化后的训练数据作为输入层输入到gru神经网络,进行样本数据训练。
如图3所示,gru需要学习的参数共3组,分别是:更新门的权重矩阵wz、重置门权重矩阵wr以及计算单元状态的权重矩阵wh;随机初始化这些权值并开始前向传播:
①更新门来决定前一时刻和当前时间步的信息有多少需要继续进行传递,更新门的输出由前一时刻隐藏状态输出和当前时刻输入共同决定,更新门的计算:
zt=σ(wz·[ht-1,xt]+bz)(1)
上式中,wz是更新门的权重矩阵,[ht-1,xt]表示将前一时刻隐含层状态ht-1和当前时刻输入xt连接成一个更长的向量,σ是sigmoid激活函数,bz为更新门偏置项;
②重置门来决定有多少之前时刻的信息需要进行遗忘,重置门的输出同样由前一时刻隐藏状态输出和当前时刻输入共同决定,重置门的计算:
rt=σ(wr·[ht-1,xt]+br)(2)
上式中,wr是重置门的权重矩阵,[ht-1,xt]表示将前一时刻隐含层状态ht-1和当前时刻输入xt连接成一个更长的向量;σ是sigmoid激活函数,br为重置门偏置项;
③当前输入的单元状态计算:
上式中,wh是单元状态的权重矩阵,rt是重置门的输出,ht-1为前一时刻隐含层状态,xt为当前时刻的输入,tanh是双曲正切激活函数,bh为单元状态偏置项;
④隐含层最终输出由上一时刻的单元状态、当前时刻候选单元状态和更新门输出共同决定:
上式中,h为当前时刻隐含层输出,zt为更新门的输出,ht-1为前一时刻隐含层状态,
⑤更新索引序列预测输出:
上式中,
式(1)到式(5)完成gru模型的前向传播。
步骤3:采用基于时间的反向传播算法计算每个神经元的误差项;从输入数据及权重开始,向着输出层传递,最后求出预测值并和目标值构成代价函数;在反向传播的过程中,以代价函数开始,从输入到输出,求各个节点的偏导数,然后利用自适应矩估计算法更新权重参数和偏置参数,重复反向传播过程,直到代价函数的误差满足要求或者到达指定的迭代次数为止;经过上述过程的反复训练,即可实现误差的最小化;
具体的计算过程如下:
采用基于时间的反向传播法,反向计算每个神经元的误差项,一方面,误差项沿时间反向传播,从当前时刻开始,计算之前每个时刻的误差项,另一方面是将误差项向上一层传播;根据相应的误差项,计算每个权重的梯度,更新权重;为了计算方便,将权重矩阵wr、wz、wh拆分成wrh、wrx、wzh、wzx、whh、whx;
①误差项的传播分为两部分,a.沿时序反向传播;b.向上一层传播;定义损失函数:
上式中,
在t时刻,gru隐含层输出为ht,定义t时刻的误差项δt为:
根据gru的计算图和链式求导法则可知,候选状态信息
上式中,l为损失函数,zt为更新门的输出;
更新门梯度为:
重置门梯度为:
上式中,rt是重置门的输出,ht-1为前一时刻隐含层状态;
a.则误差项沿时序反向传播的公式为:
b.误差项向上层传播:
设当前层为l层,定义l-1层的误差项是误差函数对l-1层加权输入的导数,则有
上式中,
本次gru的输入xt由下面的公式得出:
上式中,fl-1表示第l-1层的激活函数;
由全导公式递推可知:
上式中,
②权重梯度的计算
由①可知wrh、wzh、whh各时刻的权重梯度为:
wrx、wzx、whx的权重梯度:
与权重对应的偏置br,bz,bh梯度为:
从①~②,我们求出了在t之前的所有时刻损失函数相对于各参数的梯度,下面进行权重的更新;
③权重的更新,η为模型的学习率,为了增加公式的适用性,对公式
进行泛化,w表示网络中四个节点的权重,l代表四个节点的偏置项;
至此,完成一次前向和反向传播,循环迭代地更新各个部分,每经过一个时间步,求得误差项,若误差项小于阈值,则进行权重矩阵w和偏置项b的更新,知道误差小于设定阈值或达到最大训练次数,退出循环,完成训练。
步骤4:将处理后的水泥磨研磨过程中的过程变量数据输入到步骤3中训练好的门控循环单元网络模型,实现水泥磨研磨过程水泥成品比表面积的在线预测。
在本方法中,从水泥企业生产数据库中提取3000组数据,并按所述方法进行数据处理和模型训练。选取其中2400组作为训练数据,其余600组作为预测数据以验证模型有效性。其中训练过程均方根误差为0.0684031,平均绝对误差为0.0481364,平均相对误差为0.135366;测试过程均方根误差0.0713091,平均绝对误差为0.0537601,平均相对误差为0.149327。
综上所述,本发明首先从水泥粉磨系统的数据库中选取与比表面积相关的8个输入变量,按照时间序列排列,采用基于时间的反向传播技术求取神经网络各节点的误差项,采用自适应矩估计算法进行神经网络权值的更新,反复训练得到最小误差,获取最优模型参数集;既能够解决水泥磨复杂工况多变量、强耦合,难以建立机理模型的特点,又能够解决变量数据与水泥成品比表面积指标之间存在的时变时延问题。
- 还没有人留言评论。精彩留言会获得点赞!