一种电力知识库构建方法及系统与流程
本发明涉及一种电力知识库构建方法及系统,属于知识库构建领域。
背景技术:
领域知识库又叫行业知识库或垂直知识库,电力知识库是基于电力数据构建,而现在电力知识库的构建技术还不成熟。目前结构化数据在知识库的构建中仍然占据较大比重,对于非结构化的数据无法有效利用,同时该知识库目前一般由专家通过自顶向下的方式建模,从中提取知识需要大量的、长期的人工干预与校正。
技术实现要素:
本发明提供了一种电力知识库构建方法及系统,解决了背景技术中披露的问题。
为了解决上述技术问题,本发明所采用的技术方案是:
一种电力知识库构建方法,包括,
对语料进行预处理,获得语料文本;
响应于语料文本为非结构化文本,将语料文本输入预先训练的命名实体识别模型,对语料文本中命名实体进行识别;
将命名实体识别后的语料文本输入预先训练的命名实体关系抽取模型,获得命名实体关系数据;
将命名实体关系数据进程存储,构建电力知识库。
响应于语料文本为非结构化文本,将语料文本输入预先训练的命名实体识别模型,对语料文本中命名实体进行识别;响应于语料文本为结构化文本,根据结构信息,获得语料文本中的命名实体关系数据。
对原始语料进行预处理,获得语料文本的过程为,
对语料进行编码转换;
将编码转换后的语料进行繁简转换;
响应于繁简转换后的语料为结构化数据,繁简转换后的语料为语料文本;
响应于繁简转换后的语料为非结构化数据,对繁简转换后的语料依次进行分句、去重、中文分词,获得语料文本。
命名实体关系数据包括存在关系的命名实体对、命名实体间的关系词。
命名实体关系抽取模型包括第一抽取模型和第二抽取模块,第一抽取模型从语料文本中抽取命名实体间的关系词,第二抽取模块根据命名实体间的关系词抽取存在关系的命名实体对。
将命名实体关系数据进程存储,构建电力知识库的过程为,
将命名实体关系数据存储至图数据库;
基于图的机器学习方法对存储的图谱进行补全,得到电力知识库。
一种电力知识库构建系统,包括,
预处理模块:对语料进行预处理,获得语料文本;
实体识别模块:响应于语料文本为非结构化文本,将语料文本输入预先训练的命名实体识别模型,对语料文本中命名实体进行识别;
实体关系抽取模块:将命名实体识别后的语料文本输入预先训练的命名实体关系抽取模型,获得命名实体关系数据;
存储模块:将命名实体关系数据进程存储,构建电力知识库。
命名实体关系抽取模型包括第一抽取模型和第二抽取模块,第一抽取模型从语料文本中抽取命名实体间的关系词,第二抽取模块根据命名实体间的关系词抽取存在关系的命名实体对。
一种存储一个或多个程序的计算机可读存储介质,所述一个或多个程序包括指令,所述指令当由计算设备执行时,使得所述计算设备执行电力知识库构建方法。
一种计算设备,包括一个或多个处理器、存储器以及一个或多个程序,其中一个或多个程序存储在所述存储器中并被配置为由所述一个或多个处理器执行,所述一个或多个程序包括用于执行电力知识库构建方法的指令。
本发明所达到的有益效果:本发明增加了非结构化数据,构建的知识库知识更加丰富,同时本发明通过命名实体识别模型和命名实体关系抽取模型抽取命名实体关系数据,知识库构建不需要自顶向下的建模,降低了构建的门槛,大大减少人工成本,无需大量的、长期的人工干预与校正。
附图说明
图1为本发明方法的流程图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
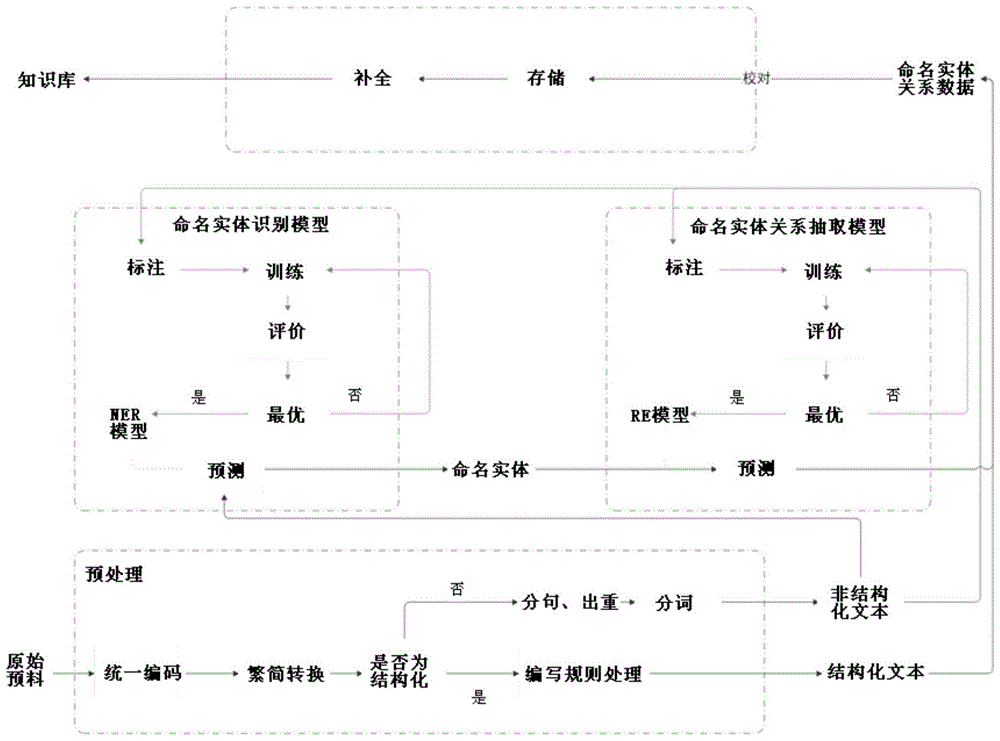
如图1所示,一种电力知识库构建方法,包括以下步骤:
步骤1,对语料进行预处理,获得语料文本。
具体过程如下:
s1)对语料进行编码转换;这里主要是将预料统一转换为utf-8编码。
s2)将编码转换后的语料进行繁简转换。
s3)响应于繁简转换后的语料为结构化数据,繁简转换后的语料为语料文本,该语料文本为结构化语料文本;响应于繁简转换后的语料为非结构化数据,对繁简转换后的语料依次进行分句、去重、中文分词,获得语料文本,该语料文本为非结构化语料文本。
步骤2,判断语料文本是否为结构化文本,,若为非结构化文本,则转至步骤3,否则转至步骤5。
步骤3,响应于语料文本为非结构化文本,将语料文本输入预先训练的命名实体识别模型,对语料文本中命名实体进行识别。
采用自动化/人工标注的非结构化文本构建训练集,采用当前成熟的序列标注技术训练命名实体识别模型,对训练的模型进行评估,将效果最好的模型作为最终的命名实体识别模型(即图中的ner模型),用该模型进行命名实体识别。
步骤4,将命名实体识别后的语料文本输入预先训练的命名实体关系抽取模型,获得命名实体关系数据。
命名实体关系数据包括存在关系的命名实体对、命名实体间的关系词,其为三元组数据<s,p,o>,其中,s与o为命名实体对,p为表示命名实体间的关系词,关系路径为s指向o。
借助句法解析工具包,利用句法规则,辅以人工校对得到精标的命名实体关系数据训练集,例如表一所示:
表一关系数据训练集
命名实体关系抽取模型包括第一抽取模型和第二抽取模块,第一抽取模型从语料文本中抽取命名实体间的关系词,第二抽取模块根据命名实体间的关系词抽取存在关系的命名实体对。相较于传统的关系抽取模型,本模型的最大创新点在于提出了一种反向抽取的方法,即先通过第一抽取模型得到命名实体间的关系词,由关系词再通过第二抽取模型反向搜索文本中对应的命名实体对。两种模型都结合了当前最新的深度学习技术(bert+crf),在效果上比传统的基于句法分析的关系抽取提升很多。训练时,首先将关系词进行序列标注先训练第一抽取模型;其次对命名实体进行序列标注,同时融入命名实体间的关系词训练第二抽取模块。
对训练的模型进行评估,将效果最好的模型作为最终的命名实体关系抽取模型(即图中的re模型),用该模型抽取命名实体关系数据。
步骤5,根据结构信息,获得语料文本中的命名实体关系数据。
步骤6,将命名实体关系数据进程存储,构建电力知识库;具体过程如下:
a1)将命名实体关系数据存储至图数据库;
这里以w3c标准资源描述框架(rdf)组织命名实体关系数据,并将其保存到图数据库neo4j中。
a2)基于transe等图的机器学习方法对存储的图谱进行补全,得到电力知识库。
上述方法增加了非结构化数据,构建的知识库知识更加丰富,同时上述方法通过命名实体识别模型和命名实体关系抽取模型抽取命名实体关系数据,知识库构建不需要自顶向下的建模,降低了构建的门槛,大大减少人工成本,无需大量的、长期的人工干预与校正,在无人工干预的情况依旧就可以长期维护知识库。
一种电力知识库构建系统,包括,
预处理模块:对语料进行预处理,获得语料文本;
实体识别模块:响应于语料文本为非结构化文本,将语料文本输入预先训练的命名实体识别模型,对语料文本中命名实体进行识别;
实体关系抽取模块:将命名实体识别后的语料文本输入预先训练的命名实体关系抽取模型,获得命名实体关系数据;
存储模块:将命名实体关系数据进程存储,构建电力知识库。
命名实体关系抽取模型包括第一抽取模型和第二抽取模块,第一抽取模型从语料文本中抽取命名实体间的关系词,第二抽取模块根据命名实体间的关系词抽取存在关系的命名实体对。
一种存储一个或多个程序的计算机可读存储介质,所述一个或多个程序包括指令,所述指令当由计算设备执行时,使得所述计算设备执行电力知识库构建方法。
一种计算设备,包括一个或多个处理器、存储器以及一个或多个程序,其中一个或多个程序存储在所述存储器中并被配置为由所述一个或多个处理器执行,所述一个或多个程序包括用于执行电力知识库构建方法的指令。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上仅为本发明的实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均包含在申请待批的本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!