一种基于对抗学习的限定域事件检测方法与流程
本发明涉及互联网技术领域,尤其涉及一种基于对抗学习的限定域事件检测方法。
背景技术:
随着互联网技术的发展,互联网上每日都会产生海量的文本数据,其中包含大量有价值的信息,对其进行自动挖掘与分析具有重要的意思,这推动着自然语言技术,尤其是信息抽取技术的快速发展。事件检测,作为信息抽取技术的一种,是文本语义理解及知识图谱构建的重要基础技术,这些年引起了学术界和工业界的普遍关注。
限定域事件检测是指,对于给定的一个或者几个领域的文本,在检测过程中将检测到的事件分类为预定义的事件类型。另外,限定域事件检测任务通常需要对每一种事件类型给出少量的标注数据。
本发明中关于限定域事件检测的定义采用ace评测会议关于限定域事件检测任务的定义。限定域事件检测任务是指,对于给定一个句子,定位事件触发词(句中最能表示一个事件发生的词)并正确分类其对应的事件类型。另外,限定域事件检测任务涉及包括新闻、博客在内的多个领域的文本数据,对于检测方法的泛化能力有着不小的挑战。当前,用于限定域事件检测的方法包括三种,即基于模式匹配的方法、基于特征工程的机器学习方法以及近年来发展的基于深度学习的方法。
基于模式匹配的方法通过人为定义的模式或者系统依据少量的标注数据自动学习的模式完成限定域事件检测任务,其中的代表性系统包括autoslog、palka、aotoslog-ts等。总体来说,基于模式匹配的方法在特定领域中性能较好。然而,该类方法依赖于文本的具体形式(语言、领域和文档格式等),获取模板的过程费时费力,具有很强的专业性,召回率低。而且,制定的模式很难覆盖所有的事件类型,当语料发生变化时,需要重新获取模式。
基于特征工程的机器学习方法将限定域事件检测任务建模成一个多分类的问题,特征到分类的映射关系使用有监督的分类器建模,其中典型的分类器包括支持向量机模型、朴素贝叶斯模型、隐马尔可夫模型、最大熵模型、最大熵隐马尔可夫模型等,最具代表性的方法是ahn在2006年提出的模型。基于特征工程的方法在一定程度上克服了基于模式匹配的方法的模板获取费时费力、召回率低的问题,但特征工程依然依赖于人工,同时特征提取的过程中过分依赖于词性标注器、句法分析器等传统的自然语言处理工具,会造成误差积累的问题。
随着词向量技术的发展,基于深度学习的方法凭借其自动学习特征的能力,成为近年事件检测相关研究的重点及主流。
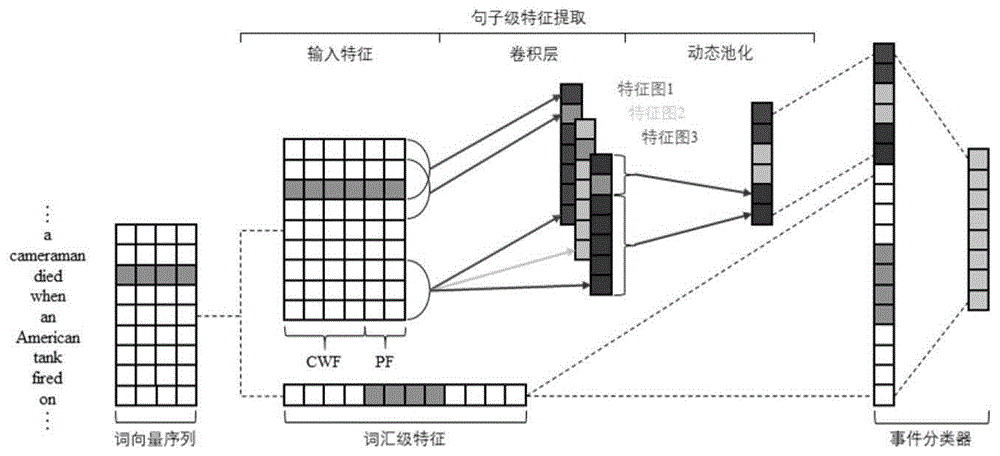
如图1所示,现有技术的“eventextractionviadynamicmulti-poolingconvolutionalneuralnetworks”文章中,提到基于动态池化的卷积神经网络(convolutionalneuralnetwork)的限定域事件检测方案。
首先,根据词到预训练词向量的映射关系,将表示句子的词序列[w1,w2,…,wt,…,wn]转化为对应的词向量矩阵e=[e1,e2,…,et,…,en],其中,t表示选定的待检测词的位置下标,
l=et-1:et:et+1式(2-1)
其中:表示向量的拼接,
然后,对词向量序列中每个向量拼接对应的位置向量得到卷积神经网络的输入矩阵
cij=f(wj·vi:i+h-1+bj)式(2-2)
c=cleft:cright式(2-5)
其中·表示矩阵的点积,vi:i+h-1表示矩阵v的第i行至第i+h-1行构成的子矩阵,
最后,拼接词汇级特征及句子级特征得到分类特征,并输入到由一层全连接网络构成的分类器中进行事件类型的打分,其计算过程如下:
f=l:c式(2-7)
o=wof+bo式(2-8)
其中
模型的训练使用adadelta算法,采用交叉熵定义损失函数:
其中,oy表示第y种事件类型的打分,m表示训练数据的数目,θ表示可训练的参数,y(m)表示第m条训练数据的正确事件类别。
发明人在研究过程中发现,对于“eventextractionviadynamicmulti-poolingconvolutionalneuralnetworks”现有技术中:
1、限定域事件检测依赖于以潜在触发词为核心的判别性特征;
由于上述问题导致现有技术存在以下缺点:
1、对于训练数据稀疏的触发词,现有技术的准确率和召回率较低;
2、跨领域的泛化性较差;
技术实现要素:
为了解决上述问题,对于应用于限定域事件检测任务的深度模型,本发明提出一种约束相同事件类型数据的特征分布的正则项,该正则项采用对抗学习的方式实现,使得模型学习更多的跨触发词的特征信息,以此提高在稀疏触发词上模型的泛化能力。
本发明提出一种基于对抗学习的正则项,该方法包括:
步骤一、将待检测文本进行分词,并设定待检测词位置;
步骤二、根据预训练词向量表,词序列转化为对应的词向量序列,并拼接位置向量,得到卷积神经网络的输入v,同时根据式(2-1)得到待检测词的词汇级特征l;
步骤三、根据式(2-2)至式(2-5),将步骤二得到的v输入到基于动态池化的卷积神经网络中得到待检测词的句子级特征c;
步骤四、将步骤二得到的词汇级特征l与步骤三得到的句子级特征c进行拼接,送入到由一层全连接网络构成的事件分类器中,输出事件类别预测概率分布p如式(2-7)至式(2-9)所示,其中概率最高的事件类别作为模型预测的事件类别输出;
步骤五、随机采样一个插值系数σ~beta(α,β),其中α和β为超参数,对于当前迭代步中所使用的训练数据,采样其中事件类型(除去默认事件类型)相同的数据对
步骤六、将真实数据的句子级特征及步骤四中得到的句子级特征输入到判别器中,判别器将句子级特征映射成概率,该概率表示输入句子级特征源于真实数据的可能性大小,映射用d表示,以此计算正则项jg(θ,θd)及判别器损失函数jd(θ,θd)如下式所示:
步骤七、输入训练数据的正确事件分类标签,根据式(2-1)至式(2-10)计算事件检测的损失函数jb(θ);
步骤八、采用对抗学习的策略,先根据jd(θ,θd)优化判别器的参数θd,再根据如下式所示的总损失函数j(θ,θd)优化事件检测模型的参数θ,其中ε为正则项的超参数:
j(θ,θd)=jb(θ)+εjg(θ,θd)式(3-4)
步骤九、在训练集上训练,重复步骤一至七直到模型参数收敛,保存在开发集上性能最高的参数,并将保存的模型在测试集上测试以及在未标注数据上做限定域事件检测。
附图说明
图1为基于动态池化的卷积神经网络(convolutionalneuralnetwork)的事件检测模型示意图;
图2为本发明的事件检测模型训练框架示意图;
图3为本发明的事件检测方法的流程图;
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。其中,本实施例中出现的缩略语和关键术语定义如下:
bp:backpropagation反向传播;
cnn:convolutionalneuralnetwork卷积神经网络;
dynamicmulti-pooling:动态池化;
dmcnn:dynamicmulti-poolingcnn基于动态池化的卷积神经网络;
relu:rectifiedlinearunit线性整流函数,是一种激活函数。
cwf:context-wordfeature,表示词对应的词向量;
pf:positionembedding位置向量;
实施例一
参照图1、2、3所示,图1、2、3示出了本发明所采用的事件检测模型的结构以及训练过程中所使用的基于对抗学习的正则项技术,该方法包括:
步骤一、将待检测文本进行分词,得到对应的词序列,并设定待检测词位置;
其中,数据集选用ace2005中文事件检测数据集,其中包含33种事件类型,涉及broadcastnews、newswire及weblog三个领域的599篇文章的标注数据,其中以newswire中随机采样40篇文章作为测试集,其余文章中随机30篇为开发集,剩下数据为训练集;
将待检测文本进行分词后,以待检测词为中心,左右各15个词,通过滑窗的方式在原词序列上进行采样,缺失的词用表示填充的“[pad]”符号代替,得到一系列总长度为31的词序列。
步骤二、根据预训练词向量表,词序列转化为对应的词向量序列,并拼接位置向量,得到卷积神经网络的输入v,同时根据式(2-1)得到待检测词的词汇级特征l;
预训练的词向量表,收集《人民日报》的新闻文章作为训练词向量的语料,对新闻文章进行分词。设语料中共有m个不同的词,词向量的维度de为300维,利用skip-gram算法训练每个词对应的词向量,在此基础上,随机设置一个对应所有未出现词的词向量,设置一个对应于“[pad]”符号的零向量,从而得到包含m+2个向量的预训练词向量表,该表在事件检测模型训练过程中保持不变;
设置模型输入的词序列的最大长度ns为31,位置向量采用随机初始化的31个向量表示,对应31个相对位置,维度dp设为50,从待检测词左侧距离为15到右侧距离为15的位置id依次设为[1,2,...,31],位置向量对应参数在模型训练阶段更新;
步骤三、根据式(2-2)至式(2-5),将步骤二得到的v输入基于动态池化的卷积神经网络得到待检测词的句子级特征c;
其中,卷积核的窗口大小h设置为3,卷积核的数量s设置为200;
步骤四、对于当前迭代步中所使用的训练数据,采样其中事件类型(除去默认事件类型)相同的数据对
步骤五、将真实数据的句子级特征及步骤四中得到的句子级特征输入到判别器中,判别器将句子级特征映射成概率,该概率表示输入句子级特征源于真实数据的可能性大小,映射用d表示,以此计算正则项jg(θ,θd)及判别器损失函数jd(θ,θd)如下式所示:
进一步的,判别器采用两层全连接结构,d(c)的计算过程如下式所示:
其中,
relu(x)=max(0,x)
步骤六、输入训练数据的正确事件分类标签,根据式(2-1)至式(2-10)计算事件检测的损失函数jb(θ);
其中,分类器输入设置dropout层,droprate设置为0.5;
步骤七、采用对抗学习的策略,先根据jd(θ,θd)优化判别器的参数θd,再根据如下式所示的总损失函数j(θ,θd)优化事件检测模型的参数θ,其中ε为正则项的超参数:
j(θ,θd)=jb(θ)+εjg(θ,θd)
其中,ε设置为1.0;
步骤八、在训练集上训练,重复步骤一至七直到模型参数收敛,保存在开发集上性能最高的参数,并将保存的模型在测试集上测试以及在未标注数据上做限定域事件检测。
本发明实施例一在原有应用于限定域事件检测任务的深度模型上,引入了约束相同事件类型数据的特征分布的正则项,该正则项采用对抗学习的方式实现,使得模型学习更多的跨触发词的特征信息,以此提高在稀疏触发词上模型的泛化能力。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!