一种基于知识图谱和社交媒体的医疗问诊推荐方法与流程
本发明涉及数据挖掘技术,具体涉及一种基于知识图谱和社交媒体的医疗问诊推荐方法。
背景技术:
目前,人们对于移动医疗服务的需求越来越高。生活中,人们经常会察觉到身体出现某些症状,却不能及时找到对应的科室和服务质量较好的医院及医生。互联网医疗服务(如腾讯医疗、寻医问药、好大夫等)的出现一定程度上缓解了这一问题,然而多数医疗网站仅仅提供疾病科普以及在线预约等功能,少数网站提供疾病自诊的手段,然而其多数仅允许用户输入单个关键词,基于关键词匹配给出推荐疾病,给出的疾病推荐列表非常冗长,没有推荐意义,且其并未涉及到对于医生和医院的推荐。
目前,人们对于医疗知识图谱展开了广泛的研究。国外有rotmensch、wang等人从电子健康记录(ehr,electronichealthrecords)中抽取信息,构建了各种各样的医疗知识图谱,并将其应用到药物推荐、医疗诊断辅助系统等。而国内对于医疗知识图谱也展开了综述性研究,侯梦薇和袁凯琦等人介绍了医疗知识图谱构建的核心技术,并将其应用场景归纳为临床决策支持系统、医疗语义搜索引擎、医疗问答系统等。
近年来,随着自然语言处理技术的发展,也有一些研究工作致力于从医疗评论中挖掘用户情感信息。hao等人基于好大夫网站评论文本数据,采用了lda(latentdirichletallocation,潜在迪利克雷分配)模型挖掘了评论的几个情感属性,并简单分析了在这个几个情感属性上的极性表现。何玲玲同样使用好大夫、阿亮医生网等线上评论文本数据,通过语义词典和语义框架手段,构建了评论的情感主题,并对情感极性及其强弱进行了分析。情感属性提取可以反应用户在特定方面的满意度,但是他们使用的方法具有一定的局限性,没有充分利用自然语言处理领域的前沿方法。
技术实现要素:
针对以上现有技术中存在的问题,本发明提出了一种基于知识图谱和社交媒体的医疗问诊推荐方法。
本发明的基于知识图谱和社交媒体的医疗问诊推荐方法,包括以下步骤:
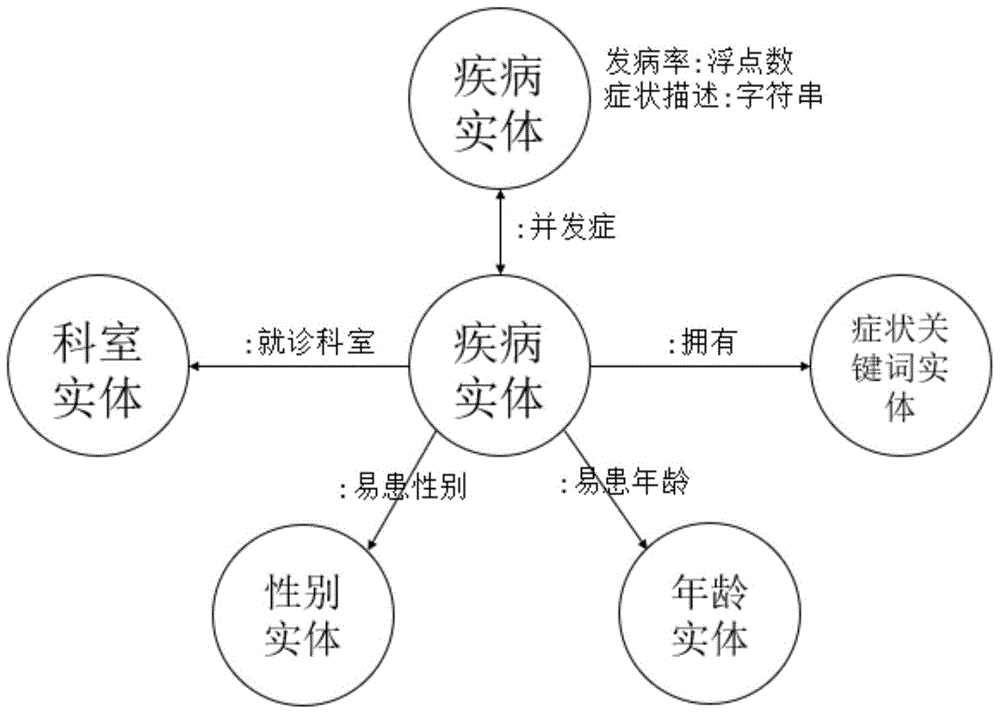
1)获取互联网医疗中开放的结构化疾病信息,从中提取疾病及其相关信息,疾病的相关信息包括症状关键词、发病率、易患人群、并发症、就诊科室和症状描述,从易患人群中进一步抽取年龄和性别信息,构建“疾病—症状”的医疗知识图谱,医疗知识图谱包括五种实体和五种关系,五种实体为:疾病实体、科室实体、年龄实体、性别实体和症状关键词实体,其中疾病实体拥有症状描述属性和发病率属性,五种关系为:疾病实体与疾病实体之间存在并发症关系、疾病实体和症状关键词实体之间存在拥有关系、疾病实体和科室实体之间存在就诊科室关系、疾病实体和年龄实体之间存在易患年龄关系,疾病实体和性别实体之间存在易患性别关系;
2)对步骤1)构建的医疗知识图谱,使用距离翻译模型训练知识图谱嵌入,将医疗知识图谱中的实体和关系映射为向量空间中的表述,得到医疗知识图谱中疾病实体的嵌入向量信息;
3)获取互联网上开放的医疗评论数据,医疗评论数据包含医生名称、医生所属的就诊科室、就诊科室所属的医院以及对医生的患者评论文本;根据医疗服务质量评价指标,标注患者评论文本,使用自然语言处理模型对患者评论文本的每个指标维度进行情感极性分析,统计每个医生的好评率,根据医生与就诊科室的所属关系,对同一就诊科室的患者评论文本进行汇总,得到相应的就诊科室的好评率,并根据威尔逊区间法分别得到医生和就诊科室的威尔逊评分;
4)用户输入的症状关键词、性别、年龄和症状描述信息中的包含症状关键词m种信息,即症状关键词是必须输入的信息,1≤m≤4,根据用户输入的m种信息查询医疗知识图谱,构建初始疾病实体备选集,根据医疗知识图谱中疾病实体的嵌入向量信息选择最为相似的疾病实体扩展备选集,挖掘用户潜在患有的疾病,最后根据用户输入的性别、年龄、症状关键词和症状描述中相应的m个方面的相似性筛选出推荐疾病,并根据相应疾病实体的就诊科室,推荐威尔逊评分最高的就诊科室所属的医院和医生:
a)构建初始疾病实体备选集:根据用户输入的症状关键词,查询医疗知识图谱,根据疾病实体和症状关键词实体之间的拥有关系,筛选出症状关键词最为相似的多个疾病实体,并且根据疾病实体拥有的发病率属性,选取发病率最高的多个疾病实体,得到初始疾病实体备选集;
b)扩充疾病实体备选集:基于医疗知识图谱中疾病实体的嵌入向量,选择与疾病实体备选集中每个疾病实体的嵌入向量的欧式距离最近的一个或多个疾病实体,即最为相似的疾病实体,对初始疾病实体备选集进行扩充,得到疾病实体扩展备选集,从而挖掘用户潜在患有的疾病;
c)给出最终推荐疾病结果:根据性别、年龄、症状关键词和症状描述中的m个方面的相似性,从疾病实体扩展备选集中筛选出推荐结果,其中,性别、年龄的相似度基于字符串匹配,症状关键词的相似度基于集合交运算,症状描述先使用词频-逆文件频率(tf-idf,termfrequency–inversedocumentfrequency)模型得到其向量表述,最终的症状描述相似度以向量之间的余弦相似度衡量;最终选择m个方面的相似度之和最高的多种疾病实体作为推荐结果,并查找医疗知识图谱,根据疾病实体和科室实体之间存在就诊科室关系,分别给出每一疾病实体相应的就诊科室;
d)分别针对每种疾病实体,根据步骤c)得到的最终推荐的每一疾病实体相应的就诊科室,按照步骤3)的威尔逊评分,选择各家医院在这类就诊科室中得分最高的医院,再选择所属的医院的就诊科室下得分最高的医生推荐给用户。
进一步,在步骤4)的d)中,根据步骤c)得到的最终推荐疾病实体的就诊科室,按照步骤3)的威尔逊评分,选择各家医院中在这类就诊科室中得分最高的多家医院,结合社交网站上排名顺序,选择这多家医院中排名最高的医院,再选择所属的医院的就诊科室下得分最高的医生推荐给用户。
在步骤1)中出现的疾病和疾病实体,代指实际上是统一的,疾病实体为知识图谱中的表述,疾病则是对应生活中的表述,其他类似。
在步骤2)中,训练知识图谱嵌入的模型为距离翻译模型中的一种。
在步骤3)中,自然语言处理模型采用深度学习模型,如lstm(longshort-termmemory,长短时记忆网络)、bert(bidirectionalencoderrepresentationsfromtransformers,互感器双向编码预表示模型)等中的一种。情感极性分析以及服务质量的评价信息,包括以下步骤:
a)根据医疗服务质量的评价指标,对患者评论文本进行情感极性人工标注,每个服务质量的评价指标维度标注的情感极性有三种:积极、中性和消极,人工标注的患者评论文本的数目不得少于6000条;
b)将标注好的评论文本数据转换为数字化表示,输入自然语言处理模型进行训练;
c)利用训练好的自然语言处理模型对剩余的评论文本数据进行情感极性分析,得到每个医生的好评率,医生的好评率即同一个医生的积极的患者评论文本的数目占患者评论文本的总数目的比例;
d)根据医生与就诊科室的所属关系,对同一家医院的同一就诊科室的患者评论文本进行汇总,得到相应的医院的就诊科室的好评率,就诊科室的好评率即同一就诊科室的所有医生的积极的患者评论文本的数目占这个就诊科室的所有患者评论文本的总数目的比例;
e)医生和就诊科室的在服务质量的评价指标维度上的威尔逊评分score的计算公式为:
其中,p表示好评率,zα表示正态分布的分位数,取值范围是[1.6,6.0],用于衡量评分可信度,可信度范围为90%~100%,n表示评论文本数据的总数量;
f)根据上面的公式,给出每个医生的威尔逊评分以及每个就诊科室的威尔逊评分。
参考的医疗服务质量评价指标来自于berry等人提出的servqual(servicequality,服务质量)模型,该模型分为五个方面,分别为tangibles(即有形性,用于衡量服务提供商环境设施及服务人员外表等方面的表现)、reliability(即可靠性,用于衡量服务提供商兑现承诺的能力)、responsiveness(即响应性,用于衡量服务提供商帮助顾客迅速提高服务的愿望)、assurance(即保证性,用于衡量服务人员的知识、礼节以及表达出自信和可信能力)、empathy(即共情性,用于衡量服务提供商关心并为顾客提高个性化服务的愿望和能力)。本发明在实际应用的过程中根据医疗评论的特点做了一些微调,具体如下:
1、由于医疗评论缺少对医院硬件设施的描述,删除了有形性评价维度;
2、由于在医疗评论中响应性和共情性表现内容过于相近,本发明将两者合二为一。
本发明的优点:
本发明基于互联网开放的疾病信息构建医疗知识图谱,结合社交媒体的医疗评论数据,根据医疗服务质量的评价指标对医生和医院的服务质量进行了自动化评价,并向用户提供推荐服务,一定程度上满足了用户日益增长的移动医疗服务需求。
相比于其他医疗问诊推荐,本发明具有以下优势:1)同时完成疾病自诊和医生医院推荐服务,为用户提供更好的服务质量;2)结合多方面的信息推荐疾病,避免单纯症状关键词匹配带来的推荐列表冗长、没有推荐意义等问题,同时,本发明利用了医疗知识图谱中的结构化信息,丰富推荐选项,更容易推荐出用户潜在的疾病;3)本发明基于患者评论文本数据,结合现有的医疗服务质量评价指标,分析得到了医生和医院的服务质量,为用户提供了更加开放易明的推荐服务。
附图说明
图1为根据本发明的基于知识图谱和社交媒体的医疗问诊推荐方法得到的医疗知识图谱的示意图。
具体实施方式
下面结合附图,通过具体实施例,进一步阐述本发明。
本实施例的基于知识图谱和社交媒体的医疗问诊推荐方法,包括以下步骤:
1)获取互联网医疗中开放的结构化疾病信息,从中提取疾病及其相关信息,疾病的相关信息包括症状关键词、发病率、易患人群、并发症、就诊科室和症状描述,从易患人群中进一步抽取年龄和性别信息,构建“疾病—症状”的医疗知识图谱,如图1所示,医疗知识图谱包括五种实体和五种关系,五种实体为:疾病实体、科室实体、年龄实体、性别实体和症状关键词实体,其中疾病实体拥有症状描述属性和发病率属性,五种关系为:疾病实体与疾病实体之间存在并发症关系、疾病实体和症状关键词实体之间存在拥有关系、疾病实体和科室实体之间存在就诊科室关系、疾病实体和年龄实体之间存在易患年龄关系,疾病实体和性别实体之间存在易患性别关系,在本实施例中,医疗知识图谱中包含实体15418个,关系85303个;
2)对步骤1)构建的医疗知识图谱,采用transd模型训练知识图谱嵌入,其中,参数为迭代次数150次,向量长度100,学习率为1.0,优化器为随机梯度下降法,最终训练得到的损失为6.807,将医疗知识图谱中的实体和关系映射为向量空间中的表述,得到医疗知识图谱中疾病实体的嵌入向量信息;
3)获取互联网上开放的医疗评论数据,医疗评论数据包含医生名称、医生所属的就诊科室、就诊科室所属的医院以及对医生的患者评论文本;根据医疗服务质量评价指标,标注患者评论文本,使用自然语言处理模型对患者评论文本的每个指标维度进行情感极性分析,统计每个医生的好评率,根据医生与就诊科室的所属关系,对同一就诊科室的患者评论文本进行汇总,得到相应的就诊科室的好评率,并根据威尔逊区间法分别得到医生和就诊科室的威尔逊评分:
a)根据医疗服务质量的评价指标,对患者评论文本进行情感极性人工标注,每个服务质量的评价指标维度标注的情感极性有三种:积极、中性和消极,人工标注患者评论文本6019条;
b)将标注好的评论文本数据转换为数字化表示,输入bert模型进行训练,其中,bert模型加载了官方的预训练中文模型chinese_l-12_h-768_a-12,设计参数为迭代次数1次,序列长度为200,损失函数为分类交叉熵函数(categorical_crossentropy),优化器为adam(0.00001);
c)利用训练好的自然语言处理模型对剩余的评论文本数据进行情感极性分析,得到每个医生的好评率,医生的好评率即同一个医生的积极的患者评论文本的数目占患者评论文本的总数目的比例;
d)根据医生与就诊科室的所属关系,对同一医院的同一就诊科室的患者评论文本进行汇总,得到相应的就诊科室的好评率,就诊科室的好评率即同一就诊科室的所有医生的积极的患者评论文本的数目占这个就诊科室的所有患者评论文本的总数目的比例;
e)医生和就诊科室的在服务质量的评价指标维度上的威尔逊评分score的计算公式为:
其中,p表示好评率,计算方法为积极评论占总评论数量的比重,zα表示正态分布的分位数,取值为2,得分可信度约为95%,n表示评论文本数据的总数量;
f)根据上面的公式,给出每个医生的威尔逊评分以及每个就诊科室的威尔逊评分,存储在json(javascriptobjectnotation,javascript对象表示)文件中;
4)用户输入的症状关键词、性别、年龄和症状描述信息中的包含症状关键词m种信息,即症状关键词是必须输入的信息,1≤m≤4,根据用户输入的m种信息查询医疗知识图谱,构建初始疾病实体备选集,根据医疗知识图谱中疾病实体的嵌入向量信息选择最为相似的疾病实体扩展备选集,挖掘用户潜在患有的疾病,最后根据用户输入的性别、年龄、症状关键词和症状描述中相应的m个方面的相似性筛选出推荐疾病,并根据相应疾病实体的就诊科室,推荐威尔逊评分最高的就诊科室和医生,并给出所属的医院:
a)构建初始疾病实体备选集:根据用户输入的症状关键词,查询医疗知识图谱,根据疾病实体和症状关键词实体之间的拥有关系,筛选出症状关键词最为相似的多个疾病实体,并且根据疾病实体拥有的发病率属性,选取发病率最高的多个疾病实体,得到初始疾病实体备选集;
b)扩充疾病实体备选集:基于医疗知识图谱中疾病实体的嵌入向量,选择与疾病实体备选集中每个疾病实体的嵌入向量的欧式距离最近的一个或多个疾病实体,即最为相似的疾病实体,对初始疾病实体备选集进行扩充,得到疾病实体扩展备选集,从而挖掘用户潜在患有的疾病;
c)给出最终推荐疾病结果:根据性别、年龄、症状关键词和症状描述中的m个方面的相似性,从疾病实体扩展备选集中筛选出推荐结果,其中,性别、年龄的相似度基于字符串匹配,症状关键词的相似度基于集合交运算,症状描述先使用词频-逆文件频率(tf-idf,termfrequency–inversedocumentfrequency)模型得到其向量表述,最终的症状描述相似度以向量之间的余弦相似度衡量;最终选择m个方面的相似度之和最高的多种疾病实体作为推荐结果,并查找医疗知识图谱,根据疾病实体和科室实体之间存在就诊科室关系,分别给出每一疾病实体相应的就诊科室;
d)分别针对每种疾病实体,根据步骤c)得到的最终推荐的每一疾病实体相应的就诊科室,按照步骤3)威尔逊评分,选择各家医院中在这类就诊科室中得分最高的多家医院,在实际推荐的过程中,本发明还考虑了一些经验规则,比如优先推荐在好大夫网站统计中在全国名列前茅的医院,优先推荐类别更高的医院,如三甲医院等,再选择所属的就诊科室下得分最高的医生推荐给用户。
最后需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附的权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!