用于多内核之间动态逻辑块地址分布的系统和方法与流程
1.本公开的实施例涉及一种在多内核之间分布逻辑块地址的方案。
背景技术:
2.计算机环境范例已经变成可以随时随地使用的普适计算系统。因此,诸如移动电话、数码相机和笔记本电脑的便携式电子装置的使用已经迅速增加。这些便携式电子装置通常使用具有存储器装置的存储器系统,即数据存储装置。数据存储装置用作便携式电子装置的主存储装置或辅助存储装置。
3.由于使用存储器装置的存储器系统没有活动部件,因此其具有优良的稳定性、耐用性、高信息访问速度和低功耗。具有这些优点的存储器系统的示例包括通用串行总线(usb)存储器装置、诸如通用闪存(ufs)的具有各种接口的存储卡和固态驱动器(ssd)。诸如基于nand闪存的存储器系统的存储器系统可以包括存储器控制器和nand闪速存储器装置。存储器控制器可以用多内核实施,以解决云应用和大数据需求的增长的需求。
技术实现要素:
4.本发明的各方面包括在多内核之间动态分布逻辑块地址(lba)的系统和方法。
5.在一方面,一种数据处理系统包括:主机;多个存储器装置,被配置成并行操作;以及控制器,包括主机接口控制器和分别联接到多个存储器装置的多个内核。控制器将与内核中的每一个相关联的逻辑块地址(lba)范围划分为多个lba组。控制器检测内核之中是否存在工作负载的不平衡。当检测到内核之中存在工作负载的不平衡时,控制器识别导致工作负载不平衡的第一内核和第二内核,在第一内核的lba范围之中选择第一lba组,并且在第二内核的lba范围之中选择第二lba组。控制器将与第一lba组相关联的数据传送到第二lba组,并且将最初打算用于第一lba组的数据重新路由到第二lba组。
6.在另一方面,一种操作数据处理系统的方法,该数据处理系统包括:主机;多个存储器装置,被配置成并行操作;以及控制器,包括主机接口控制器和分别联接到多个存储器装置的多个内核。该方法包括:将与内核中的每一个相关联的逻辑块地址(lba)范围划分为多个lba组;检测内核之中是否存在工作负载的不平衡;当检测到内核之中存在工作负载的不平衡时,识别导致工作负载不平衡的第一内核和第二内核,在第一内核的lba范围之中选择第一lba组,并且在第二内核的lba范围之中选择第二lba组;将与第一lba组相关联的数据传送到第二lba组;并且将最初打算用于第一lba组的数据重新路由到第二lba组。
7.通过以下描述,本发明的附加方面将变得明显。
附图说明
8.图1是示出根据本发明的实施例的数据处理系统的框图。
9.图2是示出根据本发明的实施例的存储器系统的框图。
10.图3是示出根据本发明的实施例的存储器装置的存储块的电路图。
11.图4是示出根据本发明的实施例的包括包含多内核的存储器系统的数据处理系统的示图。
12.图5示出图4的内核之间的静态逻辑块地址(lba)分布的示例。
13.图6示出根据本发明的实施例在存储器系统中切换lba路由方案。
14.图7示出根据本发明的实施例将每个内核的lba范围划分为组。
15.图8是示出根据本发明的实施例的lba分布操作的流程图。
16.图9a和图9b示出根据本发明的实施例的用于工作负载平衡的lba组的传送操作。
17.图10示出存储器系统中的内核之间的不平衡损耗。
18.图11示出根据本发明的实施例的针对被选择lba组的交换操作的示例。
19.图12示出根据本发明的实施例的针对被选择lba组的交换操作的应用示例。
20.图13示出根据本发明的实施例的针对被选择lba组的混合操作的示例。
21.图14示出根据本发明的实施例的基于设定模式针对被选择lba组的混合操作的应用示例。
具体实施方式
22.下面参照附图更详细地描述各个实施例。然而,本发明可以以不同的形式实现,并且因此不应被解释为受限于本文阐述的实施例。相反,提供这些实施例以使本公开更加详尽且完整,并且将本发明的范围充分传达给本领域技术人员。此外,本文中对“实施例”、“另一实施例”等的参考不一定仅针对一个实施例,并且对任何这种短语的不同参考不一定针对相同的实施例。在整个公开中,相同的附图标记在本发明的附图和实施例中指代相同的部件。
23.本发明可以以包括如下列的许多种方式来实施:进程;设备;系统;在计算机可读存储介质上实现的计算机程序产品;和/或处理器,诸如适于运行存储在联接到处理器的存储器上和/或由联接到处理器的存储器提供的指令的处理器。在本说明书中,这些实施方式或本发明可以采用的任意其它形式可以被称为技术方案。通常,可以在本发明的范围内改变所公开的进程的步骤的顺序。除非另有说明,否则被描述为适于执行任务的、诸如处理器或存储器的组件可以被实施为临时配置成在给定时间执行该任务的通用组件或被制造为执行该任务的专用组件。如本文所使用的,术语“处理器”等是指适于处理诸如计算机程序指令的数据的一个或多个装置、电路和/或处理内核。
24.以下与示出本发明的方面的附图一起提供本发明的实施例的详细描述。虽然结合这种实施例来描述本发明,但是本发明不限于任何实施例。本发明的范围仅由权利要求书限定。本发明涵盖在权利要求的范围内的许多替代方案、修改方案和等同方案。在以下的描述中阐述了许多具体细节,以便提供对本发明的透彻理解。提供这些细节是为了示例的目的;可以在没有一些或全部这些具体细节的情况下根据权利要求来实践本发明。为清楚起见,没有详细描述与本发明相关的技术领域中已知的技术材料,以免不必要地模糊本发明。
25.图1是示出根据本发明的实施例的数据处理系统2的框图。
26.参照图1,数据处理系统2可以包括主机装置5和存储器系统10。存储器系统10可以从主机装置5接收请求并且响应于接收到的请求而操作。例如,存储器系统10可以存储待由主机装置5访问的数据。
27.主机装置5可以利用各种电子装置中的任意一种来实施。在各个实施例中,主机装置5可以包括诸如台式计算机、工作站、三维(3d)电视、智能电视、数字音频记录器、数字音频播放器、数字图片记录器、数字图片播放器和/或数字视频记录器以及数字视频播放器的电子装置。在各个实施例中,主机装置5可以包括诸如移动电话、智能电话、电子书、mp3播放器、便携式多媒体播放器(pmp)和/或便携式游戏播放器的便携式电子装置。
28.存储器系统10可以用诸如固态驱动器(ssd)和存储卡的各种存储装置中的任意一种来实施。在各个实施例中,存储器系统10可以被设置为诸如以下的电子装置中的各种组件中的一种:计算机、超移动个人计算机(pc)(umpc)、工作站、上网本计算机、个人数字助理(pda)、便携式计算机、网络平板pc、无线电话、移动电话、智能电话、电子书阅读器、便携式多媒体播放器(pmp)、便携式游戏装置、导航装置、黑盒、数码相机、数字多媒体广播(dmb)播放器、三维电视、智能电视、数字音频记录器、数字音频播放器、数字图片记录器、数字图片播放器、数字视频记录器、数字视频播放器、数据中心的存储装置、能够在无线环境中接收和传输信息的装置、射频识别(rfid)装置,以及家庭网络的各种电子装置中的一种、计算机网络的各种电子装置中的一种、远程信息处理网络的电子装置中的一种或计算系统的各种组件中的一种。
29.存储器系统10可以包括存储器控制器100和半导体存储器装置200。存储器控制器100可以控制半导体存储器装置200的全部操作。
30.半导体存储器装置200可以在存储器控制器100的控制下执行一个或多个擦除操作、编程操作和读取操作。半导体存储器装置200可以通过输入/输出线接收命令cmd、地址addr和数据data。半导体存储器装置200可以通过电力线接收电力pwr,并且通过控制线接收控制信号ctrl。根据存储器系统10的设计和配置,控制信号ctrl可以包括命令锁存使能信号、地址锁存使能信号、芯片使能信号、写入使能信号、读取使能信号以及其它操作信号。
31.存储器控制器100和半导体存储器装置200可以被集成在诸如固态驱动器(ssd)的单个半导体装置中。ssd可以包括用于将数据存储在其中的存储装置。当半导体存储器系统10用于ssd中时,联接到存储器系统10的主机装置(例如,图1的主机装置5)的操作速度可以显著提高。
32.存储器控制器100和半导体存储器装置200可以被集成在诸如存储卡的单个半导体装置中。例如,存储器控制器100和半导体存储器装置200可以被如此集成以配置个人计算机存储卡国际协会(pcmcia)的个人计算机(pc)卡、紧凑型闪存(cf)卡、智能媒体(sm)卡、记忆棒、多媒体卡(mmc)、减小尺寸的多媒体卡(rs-mmc)、微尺寸版本的mmc(微型mmc)、安全数字(sd)卡、迷你安全数字(迷你sd)卡、微型安全数字(微型sd)卡、高容量安全数字(sdhc)和/或通用闪存(ufs)。
33.图2是示出根据本发明的实施例的存储器系统的框图。例如,图2的存储器系统可以描绘图1所示的存储器系统10。
34.参照图2,存储器系统10可以包括存储器控制器100和半导体存储器装置200。存储器系统10可以响应于来自主机装置(例如,图1的主机装置5)的请求而操作,并且特别地,存储待由主机装置访问的数据。在下文中,为简便起见,存储器控制器和半导体存储器装置分别被称为控制器和存储器装置。
35.存储器装置200可以存储待由主机装置访问的数据。
36.存储器装置200可以用诸如动态随机存取存储器(dram)和/或静态随机存取存储器(sram)的易失性存储器装置或诸如以下的非易失性存储器装置来实施:只读存储器(rom)、掩膜rom(mrom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)、铁电随机存取存储器(fram)、相变ram(pram)、磁阻ram(mram)和/或电阻式ram(rram)。
37.控制器100可以控制数据在存储器装置200中的存储。例如,控制器100可以响应于来自主机装置的请求来控制存储器装置200。控制器100可以将从存储器装置200读取的数据提供到主机装置,并且可以将从主机装置提供的数据存储到存储器装置200中。
38.控制器100可以包括通过总线160联接的存储装置110、控制组件120、错误校正码(ecc)组件130、主机接口(i/f)140和存储器接口(i/f)150,控制组件120可被实施为诸如中央处理单元(cpu)的处理器。
39.存储装置110可以用作存储器系统10和控制器100的工作存储器,并且存储用于驱动存储器系统10和控制器100的数据。当控制器100控制存储器装置200的操作时,存储装置110可以存储由控制器100和存储器装置200用于诸如读取操作、写入操作、编程操作和擦除操作的操作的数据。
40.存储装置110可以利用诸如静态随机存取存储器(sram)或动态随机存取存储器(dram)的易失性存储器来实施。如上所述,存储装置110可以将主机装置所使用的数据存储在存储器装置200中以用于读取操作和写入操作。为了存储数据,存储装置110可以包括程序存储器、数据存储器、写入缓冲器、读取缓冲器、映射缓冲器等。
41.控制组件120可以控制存储器系统10的一般操作,并且响应于来自主机装置的写入请求或读取请求,控制对存储器装置200的写入操作或读取操作。控制组件120可以驱动被称为闪存转换层(ftl)的固件,以控制存储器系统10的一般操作。例如,ftl可以执行诸如逻辑至物理(l2p)映射、损耗均衡、垃圾收集和/或坏块处理的操作。l2p映射称为逻辑块寻址(lba)。
42.在读取操作期间,ecc组件130可以检测并校正从存储器装置200读取的数据中的错误。当错误位的数量大于或等于可校正错误位的阈值数量时,ecc组件130可以不校正错误位,而是可以输出指示校正错误位失败的错误校正失败信号。
43.在各个实施例中,ecc组件130可以基于诸如以下的编码调制来执行错误校正操作:低密度奇偶校验(ldpc)码、博斯-查德胡里-霍昆格姆(bose-chaudhuri-hocquenghem,bch)码、涡轮码、涡轮乘积码(tpc)、里德-所罗门(reed-solomon,rs)码、卷积码、递归系统码(rsc)、网格编码调制(tcm)或分组编码调制(bcm)。然而,错误校正不限于这些技术。因此,ecc组件130可以包括适于错误校正操作的任意和所有电路、系统或装置。
44.主机接口140可以通过诸如以下的各种接口协议中的一种或多种与主机装置通信:通用串行总线(usb)、多媒体卡(mmc)、高速外围组件互连(pci-e或pcie)、小型计算机系统接口(scsi)、串列scsi(sas)、串行高级技术附件(sata)、并行高级技术附件(pata)、增强型小型磁盘接口(esdi)和电子集成驱动器(ide)。
45.存储器接口150可以提供控制器100和存储器装置200之间的接口,以允许控制器100响应于来自主机装置的请求来控制存储器装置200。存储器接口150可以在控制组件120的控制下生成用于存储器装置200的控制信号并且处理数据。当存储器装置200是诸如nand
闪速存储器的闪速存储器时,存储器接口150可以在控制组件120的控制下生成用于存储器的控制信号并且处理数据。
46.存储器装置200可以包括存储器单元阵列210、控制电路220、电压生成电路230、行解码器240、可以是页面缓冲器的阵列的形式的页面缓冲器阵列250、列解码器260以及输入和输出(输入/输出)电路270。存储器单元阵列210可以包括可以存储数据的多个存储块211。电压生成电路230、行解码器240、页面缓冲器阵列250、列解码器260以及输入/输出电路270可以形成用于存储器单元阵列210的外围电路。外围电路可以对存储器单元阵列210执行编程操作、读取操作或擦除操作。控制电路220可以控制外围电路。
47.电压生成电路230可以生成各种电平的操作电压。例如,在擦除操作中,电压生成电路230可以生成诸如擦除电压和通过电压的各种电平的操作电压。
48.行解码器240可以与电压生成电路230和多个存储块211电通信。行解码器240可以响应于由控制电路220生成的行地址,在多个存储块211之中选择至少一个存储块,并且将从电压生成电路230供应的操作电压传输到被选择存储块。
49.页面缓冲器阵列250可以通过位线bl(图3中所示)与存储器单元阵列210联接。页面缓冲器阵列250可以响应于控制电路220所生成的页面缓冲器控制信号,利用正电压对位线bl预充电,在编程操作中将数据传输到被选择存储块并且在读取操作中从被选择存储块接收数据,或临时存储传输的数据。
50.列解码器260可以将数据传输到页面缓冲器阵列250并且从页面缓冲器阵列250接收数据,或者可以将数据传输到输入/输出电路270并且从输入/输出电路270接收数据。
51.输入/输出电路270可以通过输入/输出电路270,将从外部装置(例如,图1的存储器控制器100)接收的命令和地址传输到控制电路220,将来自外部装置的数据传输到列解码器260,或将来自列解码器260的数据输出到外部装置。
52.控制电路220可以响应于命令和地址来控制外围电路。
53.图3是示出根据本发明的实施例的半导体存储器装置的存储块的电路图。例如,图3的存储块可以是图2所示的存储器单元阵列210的存储块211中的任意一个。
54.参照图3,示例性存储块211可以包括联接到行解码器240的多个字线wl0至wln-1、漏极选择线dsl和源极选择线ssl。这些线可以并联布置,并且多个字线在dsl和ssl之间。
55.示例性存储块211可以进一步包括分别联接到位线bl0至blm-1的多个单元串221。每列的单元串可以包括一个或多个漏极选择晶体管dst和一个或多个源极选择晶体管sst。在所示出的实施例中,每个单元串具有一个dst和一个sst。在单元串中,多个存储器单元或存储器单元晶体管mc0至mcn-1可以串联地联接在选择晶体管dst和sst之间。存储器单元中的每一个可以形成为多个层单元。例如,存储器单元中的每一个可以形成为存储1位数据的单层单元(slc)。存储器单元中的每一个可以形成为存储2位数据的多层单元(mlc)。存储器单元中的每一个可以形成为存储3位数据的三层单元(tlc)。存储器单元中的每一个可以形成为存储4位数据的四层单元(qlc)。
56.每个单元串中的sst的源极可以联接到公共源极线csl,并且每个dst的漏极可以联接到相应位线。单元串中的sst的栅极可以联接到ssl,并且单元串中的dst的栅极可以联接到dsl。横跨单元串的存储器单元的栅极可以联接到各个字线。也就是说,存储器单元mc0的栅极联接到相应字线wl0,存储器单元mc1的栅极联接到相应字线wl1等。联接到特定字线
的存储器单元的组可以被称为物理页面。因此,存储块211中的物理页面的数量可以对应于字线的数量。
57.页面缓冲器阵列250可以包括联接到位线bl0至blm-1的多个页面缓冲器251。页面缓冲器251可以响应于页面缓冲器控制信号而操作。例如,在读取操作或验证操作期间,页面缓冲器251可以临时存储通过位线bl0至blm-1接收的数据或感测位线的电压或电流。
58.在一些实施例中,存储块211可以包括nand型闪速存储器单元。然而,存储块211不限于这种单元类型,而是可以包括nor型闪速存储器单元。存储器单元阵列210可以被实施成组合两种或更多种类型的存储器单元的混合闪速存储器,或者控制器嵌入在存储器芯片内部的1-nand闪速存储器。
59.图4是示出根据本发明的实施例的包括包含多内核的存储器系统400的数据处理系统的示图。
60.参照图4,数据处理系统可以包括主机5和存储器系统400。存储器系统400可以利用多内核实施,以解决云应用和大数据需求的增长的需求。换言之,存储器系统400可以包括主机接口控制器(或主机接口层中的内核(hil内核))410和多个内核420至429。多个内核中的每一个可以利用闪存转换层中的中央处理单元(cpu)(fcpu)来实施。多个并行的存储器装置可以分别联接到多个内核420至429。例如,多个nand区域(例如,管芯或块)430至439分别联接到多个内核420至429。虽然在图4中未示出,但是控制器100和存储器装置200可以包括如图2所示的存储器系统10的各种其它组件。
61.图5示出图4中的存储器系统400的内核之间的静态逻辑块地址(lba)分布的示例。
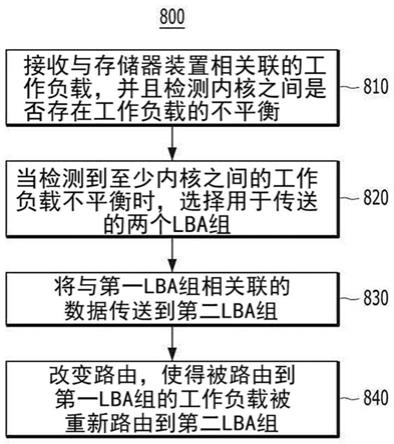
62.参照图5,存储器系统400可以利用固态驱动器(ssd)来实施,该ssd包括分别联接到nand存储器管芯430至433的多个内核420至423。内核420至423中的每一个从主机5接收命令并且独立地处理命令。为了促进ssd中的操作的并行性,可以将lba静态地路由到不同的内核。每个内核都有自己的数据结构和lba范围。根据这种静态lba分布,如图5所示,所有内核相互独立。因此,移除或添加一个或多个内核对其它内核而言透明,并且任何顺序的读取操作/写入都完美并行。然而,可能存在相比于其它内核,工作负载将更频繁地触发一个内核的情况,这引起ssd的过早磨损。这种情况可能导致ssd的性能显著下降。因此,期望提供能够平衡存储器系统中的多个内核之间的工作负载的动态lba分布方案。
63.图6示出根据本发明的实施例在存储器系统400中切换lba路由(或映射)方案。
64.参照图6,存储器系统400从主机5接收与工作负载(例如,写入操作、读取操作或擦除操作)相关联的lba,并且使用第一lba路由方案(#1)将所接收到的lba分布到一个或多个内核fcpu#0至fcpu#3中。当工作负载相比于其它fcpu#1至fcpu#3,更频繁地触发一个内核(例如,fcpu#0),或者以不均匀的速率触发内核时,发生工作负载不平衡。例如,内核fcpu#0至fcpu#3的工作负载变得不相等或不均匀,例如fcpu#0>fcpu#1>fcpu#2>fcpu#3。为了解决这种不平衡,存储器系统400可以从第一lba路由方案(#1)切换到第二lba路由方案(#2),从而使内核fcpu#0至fcpu#3的工作负载变得相等或至少更加平衡;理想情况下:fcpu#0=fcpu#1=fcpu#2=fcpu#3。
65.本发明人观察到,改变针对每个单个lba的lba映射往往会带来高的存储器开销,尤其对于具有较大lba范围的ssd而言。而且,本发明人观察到,不均匀的工作负载可以定位在特定的窄lba范围中。因此,实施例将每个内核的lba范围划分成如图7所示的组,使得仅
对小范围的lba,即lba组切换lba路由方案。
66.在图7的图示中,内核fcpu0至fcpu3中的每一个具有完整的lba范围,该完整的lba范围可以被划分成范围集合,即多个组。每个内核的lba范围可以不连续,也可以连续。第一内核fcpu0的lba范围被划分成多个组,例如3个组group01至group03。第二内核fcpu1的lba范围被划分成多个组,例如3个组group11至group13。第三内核fcpu2的lba范围被划分成多个组,例如3个组group21至group23。第四内核fcpu3的lba范围被划分成多个组,例如3个组group31至group33。上文识别的组中的每一个的大小可以相等。除上面提到的三个组外,内核中的每一个还可以包括其大小与该内核中的其它组不同的最后lba组。每个内核中的最后组可以小于该内核中的其它组中的每一个。
67.实施例可以限定每个组的在内核的lba和标识符(id)之间映射的lba路由(或映射)方案。每次切换特定组的lba路由方案时,与该组相关联的所有数据被传送到新位置。因此,lba组的大小直接影响完成从一个lba路由方案至另一路由方案的切换所需的时间。组中的lba越多,存储lba映射所需的存储器就越少。然而,切换lba路由方案的时间随着组中lba的数量增加而增长。因此,可以基于存储器的大小和/或lba路由选择方案的切换时间、优选地基于这些竞争性考虑因素两者来确定组的大小,即组中lba的数量。
68.图8是示出根据本发明的实施例的lba分布操作800的流程图。lba分布操作800可以由图4中的存储器系统400的主机接口控制器410执行。如图7所示,在执行lba分布操作800之前,主机接口控制器410将每个内核的lba范围划分为多个组。总体上,多个组包括lba组的总数量。
69.参照图8,在步骤s810中,主机接口控制器410可以从主机接收与存储器装置相关联的工作负载,并且检测内核之间是否存在工作负载的不平衡。相比于其它内核,一些工作负载可能会更多地触发存储器系统中的一些内核,从而导致工作负载不平衡。这是由于与工作负载相对应的大多数操作都被路由到相同内核的事实而引起。在这种情况下,可以通过改变路由方案,即如何将工作负载路由到至少引起不平衡的内核来提高存储器系统的性能。
70.在步骤s820中,当检测到至少两个内核之间的工作负载不平衡时,主机接口控制器410可以选择用于传送的两个lba组。换言之,主机接口控制器410可以在所有lba组之中选择与不平衡相关联的两个不同内核的第一lba组和第二lba组。
71.这样,一旦检测到工作负载不平衡,就选择用于在内核之间传送的lba组。每个组的特征可以在于其写入强度,该写入强度描述了来自该组的lba被写入的频率。可以以允许平衡不同内核上的负载的方式来选择用于传送的组:从热内核的lba组中选择写入强度高于平均值的组,从冷内核的lba组中选择写入强度低于平均值的组。
72.在一些实施例中,主机接口控制器410可以通过在设定时段中监测横跨所有内核的lba组中的每一个的写入强度,来检测内核之间是否存在工作负载的不平衡。
73.在另一实施例中,主机接口控制器410可以监测lba组中的每一个的擦除计数,并且可以基于监测的擦除计数来检测内核之间是否存在工作负载的不平衡。在该实施例中,第一lba组具有在其中lba的最大擦除计数与该lba组的平均擦除计数之间的最大差值,并且第二lba组具有在其中lba的最大擦除计数与该lba组的平均擦除计数之间的最小差值。
74.在另一实施例中,主机接口控制器410可以监测总lba组中的每一个的写入次数,
并且基于监测的写入次数来检测内核之间是否存在工作负载的不平衡。在该实施例中,第一lba组具有与所有lba组的平均写入次数相差最大的写入次数,并且第二lba组具有与所有lba组的平均写入次数相差最小的写入次数。
75.在步骤s830中,主机接口控制器410可以将与第一lba组相关联的数据传送到第二lba组。在步骤s840中,主机接口控制器410可以改变路由,使得被路由到第一lba组的工作负载被重新路由到第二lba组。
76.图9a和图9b示出根据本发明的实施例的用于工作负载平衡的lba组的传送操作。图9a示出交换操作,并且图9b示出混合操作。在图9a的交换操作中,将内核fcpu0的组02的所有lba传送到内核fcpu1的组11,反之亦然。在该示例中,每个组中lba的顺序没有改变。在图9b的混合操作中,仅将一些lba在内核fcpu2的组22与内核fcpu3的组33之间传送。在该示出的示例中,每个组中lba的顺序被改变。由于仅可以从组中传送最热lba和最冷lba,因此混合操作可以优于交换操作,从而减少传送时间并提高其效率。然而,与交换操作相比,混合操作可能具有更大的存储器需求以存储组映射。
77.图10示出存储器系统中的内核之中的不平衡损耗。存储器系统上的工作负载导致内核上的负载不平衡,这反映在lba的写入强度中。
78.参照图10,示出内核fcpu0至fcpu3之间的不平衡的示例。在示出的示例中,每个内核的lba范围包括6个lba组,并且每个组包括10个lba。内核fcpu0至fcpu3之间的不平衡磨损可能是由相应nand存储器管芯中存储的lba的不相等写入强度引起的。lba的写入强度以颜色等级来表示。组中lba的平均写入强度定义组的写入强度,而内核中的组的平均写入强度定义内核的写入强度。在示出的示例中,fcpu0的写入强度最高,fcpu1的写入强度比fcpu0的写入强度低,fcpu2的写入强度比fcpu1的写入强度低,并且fcpu3的写入强度是最低的写入强度。
79.如前所述,可以使用连续监测存储器系统中的最大擦除计数差值或最大擦除计数与平均擦除计数之间的差值的方法来检测不平衡。另一方法是监测被路由到每个内核的写入次数,直到该写入次数大约等于该内核的实际擦除次数为止。
80.选择用于传送的lba组可以通过选择内核之中的、具有写入强度的最大差值的组来实施。这种方法允许以最快的方式补偿不平衡。重要的是,一旦检测到不平衡,则立即进行补偿。否则,关于组写入强度的信息可能由于工作负载的改变而过时。可以如图11和图12所示执行针对两个被选择lba组的传送操作。
81.图11示出根据本发明的实施例的针对被选择lba组的交换操作的示例。
82.参照图11,在fcpu0的lba组group04和fcpu3的lba组group36之间执行交换操作。在这种情况下,先前分配给fcpu3的lba可以通过路由方案被重新命名并路由到fcpu0,并且fcpu0的lba将被路由到fcpu3。通过这样做,可以保留它们的相对位置。然而,结果可能是,与相应内核相关联的nand区域(例如,管芯)中已经存在被切换的组的数据。然后,这些数据从相应nand区域被读取并被传送到另一内核,使得可以将其写入新位置。同时对两个或更多个内核执行切换了路由方案的lba组的已存在数据的传送。如果传送足够多的组并且工作负载足够持久,则fcpu的写入强度变得更加平衡。
83.图12示出根据本发明的实施例的针对被选择lba组的交换操作的应用示例。该示例可以应用于分区的ssd,其中每个分区可以包括多个nand块(例如512mb)。当处理分区的
ssd时,可以实施组的交换。为了简单起见,假设单个分区对应于单个lba组。在这种情况下,组的交换是fcpu内核之间的分区的交换。对于交换操作,组路由方案可以存储到如图12所示的组到组映射表中。组到组映射表用于将来自主机的请求中的组的标识符(id)重新映射到新的值,该新的值稍后用于确定应向其发送请求的fcpu内核。
84.图13示出根据本发明的实施例的针对被选择lba组的混合操作的示例。
85.参照图13,在fcpu0的lba组和fcpu3的lba组之间执行混合操作。在所示的示例中,在fcpu0的6个lba组和fcpu3的6个lba组之间执行混合操作。然而,可以根据所需的性能混合任意数量的组。
86.在一些实施例中,可以根据设定模式从整体lba范围(或全局lba范围)中选择用于混合操作的组的lba。该模式可以指定应为每个组选择哪些lba。例如,该模式可以具有以下形式:某个lba范围的位图;内核数量的伪随机序列(参见图14);或固定模式或方法。所有模式的通用规则是仅可以为一个组,而不是为不同的组选择单个lba。一旦判定哪些组将参与混合操作,就为这些组选择模式,确认待被混合的各个组中的lba。相应lba被传送到其在nand存储器区域中的新位置,使得根据模式的路由将是正确的。可以选择模式,使得对lba的写入强度分布保持相等,因此补偿写入强度的不平衡。例如,具有较大写入强度的多个lba应被传送到冷内核并且具有较低写入强度的多个lba应被传送到热内核。
87.图14示出根据本发明的实施例的基于设定模式的针对被选择lba组的混合操作的应用示例。该示例可以应用于普通ssd。
88.参照图14,假设ssd中有四个内核。整个lba范围被划分为大小等于lba组大小的多个相等部分。然后,针对每4个部分,形成不同内核的4个组。通过根据lba分布模式,即数字的伪随机序列,例如{0、1、2、3、1、0、3、2、2、3、0、1、3、2、1、0、...},从这些部分中选择某些lba来形成每个lba组。在该序列中,每个数字表示具有相应索引的lba应被移动到的fcpu内核的标识符(id)。例如,在以上序列中,“0”表示fcpu#0,“1”表示fcpu#1,“2”表示fcpu#2,并且“3”表示fcpu#3。根据被映射的lba索引对组的id进行选择。因此,在该示例中,如果序列从lba#0开始,则使用组g01、g11、g12和g13。lba分布模式可以固定。可选地,在执行交换操作之后,可以将lba分布模式改变成其它模式,诸如:
89.{3、1、2、0、3、1、2、0、3、1、2、0、3、1、2、0、...};
90.{1、3、0、2、3、1、2、0、0、2、1、3、2、0、3、1、...};或
91.{0、1、2、3、3、2、1、0、1、0、3、2、2、3、0、1、...}。
92.如上所述,实施例提供了用于在存储器系统中的多内核之间动态分布逻辑块地址的系统和方法。实施例能够平衡多内核之间的工作负载。
93.虽然出于清楚和理解的目的已经较为详细地示出并描述了前述实施例,但是本发明并不限于所提供的细节。如本领域技术人员根据前述公开内容将理解的,存在许多实施本发明的替代方式。因此,所公开的实施例是说明性的,而不是限制性的。本发明旨在涵盖落入权利要求范围内的所有修改方案和替代方案。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1