一种分布式基础词库的构建和同步的方法及装置与流程
本发明涉及一种分布式基础词库的构建和同步的方法及装置,属于涉及数据处理、信息管理、办公自动化领域。
背景技术:
随着业务信息化程度的不断深入,积累了大量的结构化与非结构化数据资源,数据资源的挖掘和利用是未来业务信息化到数字化的重要手段。当前中文数据资源的挖掘与利用的主要技术包括:文本挖掘、自然语言处理、机器学习、深度学习等相关技术,针对中文文档处理的最基础工作就是对文本内容进行分词,分词的过程则紧密依赖于基础词库。随着微服务、服应用的理念与设计思想不断深入,大量应用以微服务的方式存在,模板与模板之间的耦合度越来越低。构建一种分布式基础词库成为文本数据挖掘的重要课题,建立容纳不同分类的词库并实现分布式的同步机制是构建方法的核心。
目前的应用开发过程中使用的词库还是以开源为主,比较流行的有jieba、thulac、pkuseg、hanlp等,当前这些词库涉及词库新增与新词发现的过程基本都需要依赖于发布新版本,以人工拷贝的方式进行词库的更新操作,暂缺少一种分布式基础词库,并能实现分布式、定时同步新词等应用。
技术实现要素:
为了解决上述现有技术中存在的问题,本发明提供一种分布式基础词库的构建和同步的方法及装置,基于基础的语料进行新词发现,并整合构建词库服务,实现对智能化应用的基础词库支撑。
本发明的技术方案如下:
技术方案一:
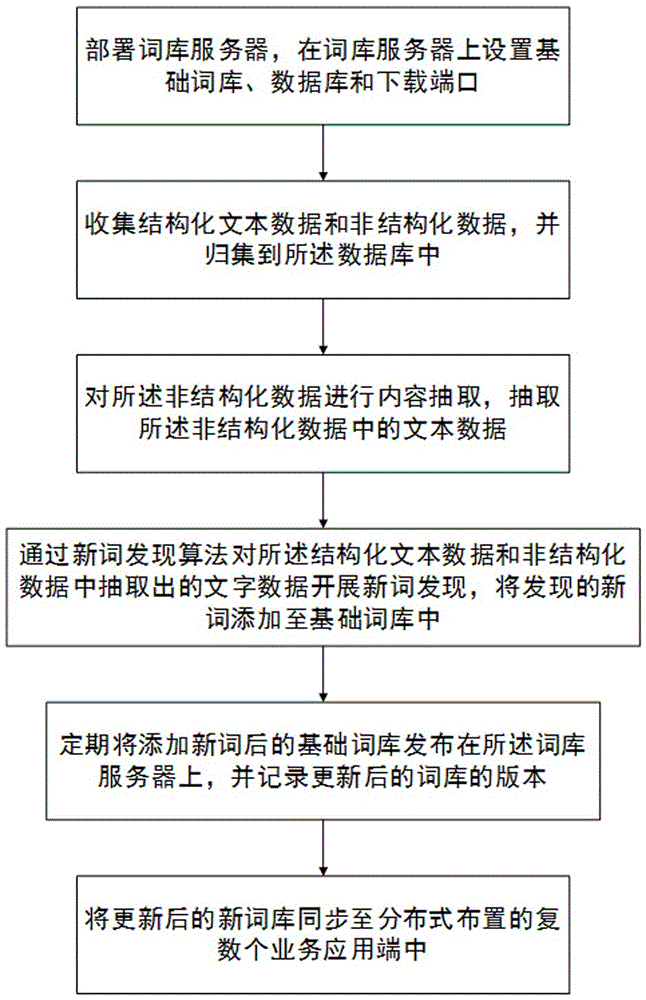
一种分布式基础词库的构建和同步的方法,包括以下步骤:
部署词库服务器,在所述词库服务器上设置基础词库、数据库和下载端口;
基础语料获取,收集结构化文本数据和非结构化数据,并归集到所述数据库中;
内容加工,对所述非结构化数据进行内容抽取,抽取所述非结构化数据中的文本数据;
新词发现,通过新词发现算法对所述结构化文本数据和非结构化数据中抽取出的文字数据开展新词发现,将发现的新词添加至基础词库中;
词库发布,定期将添加新词后的基础词库发布在所述词库服务器上,并记录更新后的词库的版本;
词库同步,在分布式布置的复数个业务应用端上设置与所述词库服务器通信连接的接口,所述业务应用端通过所述接口定期读取所述词库服务器中记录的词库的版本,并判断所述远程服务器上记录的词库的版本是否高于所述业务应用端当前使用的词库的版本,若词库服务器上记录的词库的版本业务应用端当前使用的词库的版本,则业务应用端通过所述下载端口从所述词库服务器上下载新的词库进行更新;若词库服务器上的词库的版本不高于业务应用端当前使用的词库的版本,则结束。
进一步的,在所述新词发现步骤中,所述将发现的新词加入至基础词库中的方法具体包括以下步骤:
根据所述基础词库构建包含所有已存在于所述基础词库中的词语的非新词库,当通过所述新词发现算法发现新词时,判断该新词是否在非新词库中;
若新词在非新词库中,则舍弃该新词;
若新词不在非新词库中,则通过人工进行审核,审核该新词是否属于新的词语,审核通过则将该新词加入至基础词库中,审核不通过则将该新词加入至非新词库中。
进一步的,所述定期将加入新词后的基础词库发布在所述词库服务器上,并记录更新后的词库的版本的方法具体包括以下步骤:
所述词库服务器生成一链接列表,用于提供最近发布的词库的下载链接;
定期将添加新词后的基础词库作为新词库发布于所述链接列表中,记录新词库的版本并以新词库的版本号作为名称命名该新词库;
所述链接列表以新词库发布的时间倒序设置。
进一步的,所述新词发现算法为hmm算法。
进一步的,所述基础词库基于hanlp构建。
技术方案二:
一种分布式基础词库的构建和同步的装置,包括存储器和处理器,所述存储器存储有指令,所述指令适于由处理器加载并执行以下步骤:
部署词库服务器,在所述词库服务器上设置基础词库、数据库和下载端口;
基础语料获取,收集结构化文本数据和非结构化数据,并归集到所述数据库中;
内容加工,对所述非结构化数据进行内容抽取,抽取所述非结构化数据中的文本数据;
新词发现,通过新词发现算法对所述结构化文本数据和非结构化数据中抽取出的文字数据开展新词发现,将发现的新词添加至基础词库中;
词库发布,定期将添加新词后的基础词库发布在所述词库服务器上,并记录更新后的词库的版本;
词库同步,在分布式布置的复数个业务应用端上设置与所述词库服务器通信连接的接口,所述业务应用端通过所述接口定期读取所述词库服务器中记录的词库的版本,并判断所述远程服务器上记录的词库的版本是否高于所述业务应用端当前使用的词库的版本,若词库服务器上记录的词库的版本业务应用端当前使用的词库的版本,则业务应用端通过所述下载端口从所述词库服务器上下载新的词库进行更新;若词库服务器上的词库的版本不高于业务应用端当前使用的词库的版本,则结束。
进一步的,在所述新词发现步骤中,所述将发现的新词加入至基础词库中的方法具体包括以下步骤:
根据所述基础词库构建包含所有已存在于所述基础词库中的词语的非新词库,当通过所述新词发现算法发现新词时,判断该新词是否在非新词库中;
若新词在非新词库中,则舍弃该新词;
若新词不在非新词库中,则通过人工进行审核,审核该新词是否属于新的词语,审核通过则将该新词加入至基础词库中,审核不通过则将该新词加入至非新词库中。
进一步的,所述定期将加入新词后的基础词库发布在所述词库服务器上,并记录更新后的词库的版本的方法具体包括以下步骤:
所述词库服务器生成一链接列表,用于提供最近发布的词库的下载链接;
定期将添加新词后的基础词库作为新词库发布于所述链接列表中,记录新词库的版本并以新词库的版本号作为名称命名该新词库;
所述链接列表以新词库发布的时间倒序设置。
进一步的,所述基础词库基于hanlp构建。
进一步的,所述新词发现算法为hmm算法。
本发明具有如下有益效果:
1、本发明采用分布式词库的构建,提升了大型智能化应用服务中的词库同步的问题,有效提升了词库更新的及时率,避免在文档索引、内容分词、关键词提供、文档摘要过程中因新词更新延迟造成应用效果不佳的问题。
2、本发明通过非新词库进行初筛,再通过人工进行审核,大大提高了新词筛选的效率,降低了业务人员的工作强度。
3、本发明通过链接列表的方式统一发布新词库,各应用服务端与词库服务器连接上后就能快速的下载新版本的词库。
附图说明
图1为本发明实施例的流程图。
具体实施方式
下面结合附图和具体实施例来对本发明进行详细的说明。
实施例一:
参见图1,一种分布式基础词库的构建和同步的方法,包括以下步骤:
部署词库服务器,在所述词库服务器上设置基础词库、数据库和下载端口;
基础语料获取,从业务系统端,如办公、档案、电子文件系统中收集结构化文本数据和非结构化数据,并归集到所述数据库中;
内容加工,对所述非结构化数据进行内容抽取,抽取所述非结构化数据中的文本数据,非结构化数据比如word文件、excel文件或者pdf文件,无法直接得到文本数据,对word文件、excel文件可以采用poi工具进行内容抽取,对pdf文件可以采用tika工具进行内容抽取;
新词发现,通过新词发现算法对所述结构化文本数据和非结构化数据中抽取出的文字数据开展新词发现,将发现的新词添加至基础词库中;
词库发布,定期将添加新词后的基础词库发布在所述词库服务器上,并记录更新后的词库的版本;
词库同步,在分布式布置的复数个业务应用端(例如检索服务应用、关键词提供应用、内容分词应用等)上设置与所述词库服务器通信连接的接口,例如蜂窝网络接口。所述业务应用端通过所述接口定期读取所述词库服务器中记录的词库的版本,并判断所述远程服务器上记录的词库的版本是否高于所述业务应用端当前使用的词库的版本,若词库服务器上记录的词库的版本业务应用端当前使用的词库的版本,则业务应用端通过所述下载端口从所述词库服务器上下载新的词库进行更新;若词库服务器上的词库的版本不高于业务应用端当前使用的词库的版本,则结束;各应用服务端在首次下载词库时,会在本地存储词库的版本号信息,并解压词库包进行应用,在判断词库版本高低时通过本地的版本号进行判断。
本实施例采用分布式词库的构建,提升了大型智能化应用服务中的词库同步的问题,有效提升了词库更新的及时率,避免在文档索引、内容分词、关键词提供、文档摘要过程中因新词更新延迟造成应用效果不佳的问题。
实施例二:
进一步的,在所述新词发现步骤中,所述将发现的新词加入至基础词库中的方法具体包括以下步骤:
根据所述基础词库构建包含所有已存在于所述基础词库中的词语的非新词库,当通过所述新词发现算法发现新词时,判断该新词是否在非新词库中;
若新词在非新词库中,则舍弃该新词;
若新词不在非新词库中,则通过人工进行审核,审核该新词是否属于新的词语,审核通过则将该新词加入至基础词库中,审核不通过则将该新词加入至非新词库中。
例如,从非结构化数据中抽取到的文本数据为“w.费勒将半群方法引入马尔可夫过程的研究,流形上的马尔可夫过程、马尔可夫向量场等都是正待深入研究的领域”,经过新词发现后,得到的新词包括“半群方法”、“向量场”,遍历非新词库后,判断这两个新词不在非新词库中,则相关人员对这两个新词进行审核,判断是否为新词,如审核通过,则将“半群方法”、“向量场”添加到基础词库中。
进一步的,所述定期将加入新词后的基础词库发布在所述词库服务器上,并记录更新后的词库的版本的方法具体包括以下步骤:
所述词库服务器生成一链接列表,用于提供最近发布的词库的下载链接;
定期将添加新词后的基础词库作为新词库发布于所述链接列表中,记录新词库的版本并以新词库的版本号作为名称命名该新词库,在本实施例中版本号为年(4位)-月(2位)-日(2位)-序号(2位)为标准,如:2020-04-20-01;
所述链接列表以新词库发布的时间倒序设置,例如:
2020-04-20-03;
2020-04-20-02;
2020-04-20-01;
2020-04-19-03;……
进一步的,所述新词发现算法为hmm算法。
进一步的,所述基础词库基于hanlp构建。
本实施例在实施例一的基础上,进一步提出了新词添加时的具体方法,通过非新词库进行初筛,再通过人工进行审核,大大提高了新词筛选的效率,降低了业务人员的工作强度;提出了通过链接列表的方式统一发布新词库,各应用服务端与词库服务器连接上后就能快速的下载新版本的词库。
实施例三:
参见图1,一种分布式基础词库的构建和同步的装置,包括存储器和处理器,所述存储器存储有指令,所述指令适于由处理器加载并执行以下步骤:
部署词库服务器,在所述词库服务器上设置基础词库、数据库和下载端口;
基础语料获取,从业务系统端,如办公、档案、电子文件系统中收集结构化文本数据和非结构化数据,并归集到所述数据库中;
内容加工,对所述非结构化数据进行内容抽取,抽取所述非结构化数据中的文本数据,非结构化数据比如word文件、excel文件或者pdf文件,无法直接得到文本数据,对word文件、excel文件可以采用poi工具进行内容抽取,对pdf文件可以采用tika工具进行内容抽取;
新词发现,通过新词发现算法对所述结构化文本数据和非结构化数据中抽取出的文字数据开展新词发现,将发现的新词添加至基础词库中;
词库发布,定期将添加新词后的基础词库发布在所述词库服务器上,并记录更新后的词库的版本;
词库同步,在分布式布置的复数个业务应用端(例如检索服务应用、关键词提供应用、内容分词应用等)上设置与所述词库服务器通信连接的接口,例如蜂窝网络接口。所述业务应用端通过所述接口定期读取所述词库服务器中记录的词库的版本,并判断所述远程服务器上记录的词库的版本是否高于所述业务应用端当前使用的词库的版本,若词库服务器上记录的词库的版本业务应用端当前使用的词库的版本,则业务应用端通过所述下载端口从所述词库服务器上下载新的词库进行更新;若词库服务器上的词库的版本不高于业务应用端当前使用的词库的版本,则结束;各应用服务端在首次下载词库时,会在本地存储词库的版本号信息,并解压词库包进行应用,在判断词库版本高低时通过本地的版本号进行判断。
本实施例采用分布式词库的构建,提升了大型智能化应用服务中的词库同步的问题,有效提升了词库更新的及时率,避免在文档索引、内容分词、关键词提供、文档摘要过程中因新词更新延迟造成应用效果不佳的问题。
实施例四:
进一步的,在所述新词发现步骤中,所述将发现的新词加入至基础词库中的方法具体包括以下步骤:
根据所述基础词库构建包含所有已存在于所述基础词库中的词语的非新词库,当通过所述新词发现算法发现新词时,判断该新词是否在非新词库中;
若新词在非新词库中,则舍弃该新词;
若新词不在非新词库中,则通过人工进行审核,审核该新词是否属于新的词语,审核通过则将该新词加入至基础词库中,审核不通过则将该新词加入至非新词库中。
例如,从非结构化数据中抽取到的文本数据为“w.费勒将半群方法引入马尔可夫过程的研究,流形上的马尔可夫过程、马尔可夫向量场等都是正待深入研究的领域”,经过新词发现后,得到的新词包括“半群方法”、“向量场”,遍历非新词库后,判断这两个新词不在非新词库中,则相关人员对这两个新词进行审核,判断是否为新词,如审核通过,则将“半群方法”、“向量场”添加到基础词库中。
进一步的,所述定期将加入新词后的基础词库发布在所述词库服务器上,并记录更新后的词库的版本的方法具体包括以下步骤:
所述词库服务器生成一链接列表,用于提供最近发布的词库的下载链接;
定期将添加新词后的基础词库作为新词库发布于所述链接列表中,记录新词库的版本并以新词库的版本号作为名称命名该新词库,在本实施例中版本号为年(4位)-月(2位)-日(2位)-序号(2位)为标准,如:2020-04-20-01;
所述链接列表以新词库发布的时间倒序设置,例如:
2020-04-20-03;
2020-04-20-02;
2020-04-20-01;
2020-04-19-03;……
进一步的,所述新词发现算法为hmm算法。
进一步的,所述基础词库基于hanlp构建。
本实施例在实施例一的基础上,进一步提出了新词添加时的具体方法,通过非新词库进行初筛,再通过人工进行审核,大大提高了新词筛选的效率,降低了业务人员的工作强度;提出了通过链接列表的方式统一发布新词库,各应用服务端与词库服务器连接上后就能快速的下载新版本的词库。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!