基于BERT预训练模型的刑事案件要素识别方法与流程
本发明涉及基于bert预训练模型的刑事案件要素识别方法,属于自然语言处理技术领域。
背景技术:
涉案新闻文本是舆情监测的对象,针对互联网海量舆情新闻的自动检测需要对新闻文本进行理解,特别是对于刑事特案要案,舆情监测工作尤为重要。针对涉刑事案件相关新闻文本理解,需要基于案件相关的案件要素和要素关系辅助进行语义理解,因此,刑事案件要素的识别是基础。
在刑事案件领域的案件要素识别,其实就是通用领域常说的实体识别,而实体识别是自然语言处理(naturallanguageprocessing,nlp)过程中一项重要的任务。对实体识别方法的研究,有基于规则的方法、基于机器学习的方法和基于深度学习的方法。但刑事案件领域的案件要素识别比较特殊,案件要素识别任务是从刑事案件新闻文本中自动识别出嫌疑人、被害人、法院和案发地点等案件要素。例如“某网网6月8日电永定公安微信公众号今日刊发通报称,6月8日11时许,某省某市某区发生一起持刀伤人事件,致1人受伤,侯某某已被公安机关控制。”就是要识别出案发地点“某省某市某区”和嫌疑人“侯某某”。可以看出,刑事案件领域的案件要素比较特殊,有多个实体组合而成,这样组合成的案件要素除了案发地点,还有法院“某市某区人民法院”,这类案件要素类型的识别比单一实体的识别难。
针对这个问题,提出了一种基于bert预训练模型的刑事案件要素识别方法,使用bert预训练模型对刑事案件新闻文本进行语义表征,是为了提升语义表征的能力,实现更准确的案件要素识别,在刑事案件语料库上进行了理论与技术的验证,实验结果表明该方法能提升刑事案件要素识别的效果。
技术实现要素:
本发明提供了基于bert预训练模型的刑事案件要素识别方法,该方法使用bert预训练模型提升语义表征能力,实现更准确的案件要素识别。
本发明的技术方案是:基于bert预训练模型的刑事案件要素识别方法,包括如下步骤:
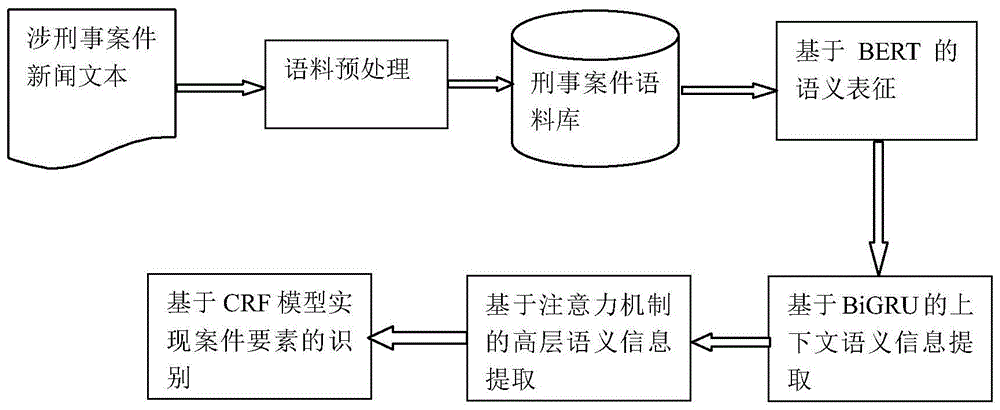
step1、首先从百度新闻、新浪新闻和腾讯新闻等新闻网站上爬取涉刑事案件新闻文本语料,并对文本进行去重、去噪和分句语料预处理;
step2、将经过预处理之后的刑事案件新闻文本语料数据进行语料标记工作,构建针对案件要素识别任务的刑事案件语料库;
step3、利用bert预训练模型对标记后的刑事案件新闻文本进行语义表征,获得刑事案件新闻文本的语义表征向量;
step4、利用bigru提取刑事案件新闻文本的上下文语义信息,构建bigru层;
step5、引入注意力机制对高层上下文语义信息进行提取,构建attention层;
step6、融合crf模型实现对刑事案件要素的识别。
进一步地,所述步骤step1中,刑事案件新闻文本语料预处理的具体步骤为:
step1.1、利用爬虫技术将新闻网站上的非结构涉刑事案件描述文爬取并保存;
step1.2、对文本进行去重、去噪和分句处理。
进一步地,所述步骤step2中,对刑事案件新闻文本语料数据进行语料标记的具体步骤为:
step2.1、对预处理后的刑事案件新闻文本语料数据进行分字,将分字后的一部分数据作为训练模型的训练语料,一部分作为测试模型的测试语料;
step2.1、对训练语料采用bio进行逐字标记。
进一步地,所述步骤step3中:使用google提供的开源简单版bertbase进行刑事案件新闻文本的语义向量表征。
进一步地,所述步骤step6中,将含有高层上下文语义信息的向量输入crf层,输出拥有最大概率的标签序列,实现刑事案件要素的识别。
所述步骤step4中,经过bert字向量训练之后输入到bigru层提取上下文特征,双向gru同时考虑文本的上下文语境,充分利用上下文信息。
所述步骤step5中,在案件要素识别过程中每个信息对案件要素识别的作用是不一样的,加入了注意力机制,根据作用的不同给予不同的权重。
本发明的有益效果是:本发明的识别结果可以为后续的案件要素关系抽取提供了强有力的支撑,在刑事案件语料库上的实验结果表明,该方法能提升刑事案件要素识别的效果。
附图说明
图1为本发明中的流程图;
图2为本发明中基于bert的刑事案件要素识别模型结构图;
图3为本发明中刑事案件新闻训练语料bio标记结果图。
具体实施方式
实施例1:如图1-3所示,基于bert预训练模型的刑事案件要素识别方法,包括如下步骤:
step1、首先从百度新闻、新浪新闻和腾讯新闻等新闻网站上爬取涉刑事案件新闻文本语料,并对文本进行去重、去噪和分句语料预处理;
step2、将经过预处理之后的刑事案件新闻文本语料数据进行语料标记工作,构建针对案件要素识别任务的刑事案件语料库;
step3、利用bert预训练模型对标记后的刑事案件新闻文本进行语义表征,获得刑事案件新闻文本的语义表征向量;
step4、利用bigru提取刑事案件新闻文本的上下文语义信息,构建bigru层;
step5、引入注意力机制对高层上下文语义信息进行提取,构建attention层;
step6、融合crf模型实现对刑事案件要素的识别。
进一步地,所述步骤step1中,刑事案件新闻文本语料预处理的具体步骤为:
step1.1、利用爬虫技术将新闻网站上的非结构涉刑事案件描述文爬取并保存;
step1.2、对文本进行去重、去噪和分句处理。
进一步地,所述步骤step2中,对刑事案件新闻文本语料数据进行语料标记的具体步骤为:
step2.1、对预处理后的刑事案件新闻文本语料数据进行分字,将分字后的9000句作为训练模型的训练语料,3000句作为测试模型的测试语料,并对9000句训练语料进行标记,用来训练模型;
step2.1、对训练语料采用bio(b-begin,i-inside,o-outside)进行逐字标记。
本发明中选用5种案件要素类型,即某嫌疑人、某受害人、某法院、某案发地点和某警方;为方便标记,对每个案件要素进行了缩写代表,例如,用sus代表某嫌疑人,loc代表某案发地点,所有的缩写代表见表1。b代表开始,b-sus代表嫌疑人名字的首字,i-sus代表嫌疑人名字的非首字部分;b-loc代表案发地名的首字,i-loc代表案发地名的非首字部分,其它的法院、警方和被害人以此类推,o代表所定义的5种案件要素之外的要素和无关的字符。部分标记结果如图3所示。
表1刑事案件要素类型缩写代表
进一步地,所述步骤step3中:使用google提供的开源简单版(bertbase),进行刑事案件新闻文本的语义向量表征。google开源提供了简单(bertbase)和复杂(bertlarge)两种版本,两个版本本质一样,只有设置的参数数量不同,具体如表2所示。
表2两个bert版本的参数比较
进一步的,所述步骤step4中利用bigru提取刑事案件新闻文本的上下文语义信息,构建bigru层:
将经过bert语义表征后的向量输入到bigru层提取上下文特征信息,双向gru同时考虑文本的上下文语境,充分利用文本信息。输入bigru层的字向量序列{x1,x2,x3,...,xn},第t个字的的前向gru为
进一步的,所述步骤step5中,构建attention层:
经过bigru编码之后提取的上下文特征信息,都有着相同的权重,不利于要素种类的识别,因为在识别过程中每个信息对要素识别的作用是不一样的,因此,加入了注意力机制层,对特征信息根据作用的不同给予不同的权重。
进一步地,所述步骤step6中,将含有高层上下文语义信息的向量输入crf层,输出拥有最大概率的标签序列,实现刑事案件要素的识别。
本发明中使用google开发的tensorflow框架训练模型,seq-length最大序列长度为128,训练批次train-batch-size大小为16,测试批次test-batch-size大小为8,训练模型的学习率learning_rate为2×10-5,gradientclipping设为5,bigru隐藏单元128,crf层全连接参数5,分为5类;使用未标记的3000句测试语料测试模型;
本发明主要从三个方面来评价本次实验的效果:正确率(precision,简称p)、召回率(recall,简称r)、f值:
为了验证本文方法(bert-bigru-attention-crf)对刑事案件要素识别的效果,设置以下4组实验。
(1)使用本文方法识别刑事案件要素,在刑事案件新闻语料上进行实验,对5种案件要素类型识别的实验结果如表3所示。
表3本文方法识别刑事案件要素的结果
从表3可以看出,本文模型对嫌疑人和被害人的识别度比对案发地点和法院的高出很多,最主要的原因是案发地点多半是由商场名、街道名、小区名等组成的复合实体,例如“某县西大街某商场门前”,法院的组成也是包括省、市和某某人民法院,如“某省某市某中级人民法院”。
(2)为了验证bert的语义表征能力强于word2vec,设置了bert-bigru-attention-crf与word2vec-bigru-attention-crf的对比实验,使用刑事案件新闻语料进行实验,实验结果如表4所示。
表4bert与word2ve对比实验结果
从表4看出bert-bigru-attention-crf对刑事案件要素的识别效果好于word2vec-bigru-attention-crf,证明了bert语义表征能力确实强于word2vec,表明了本文方法在刑事案件要素识别中取得了很好的效果。
(3)为了验证attention的重要性,设置了bert-bigru-attention-crf与bert-bigru–crf的对比实验,在刑事案件语料上进行实验,结果如表5所示。
表5attention的实验对比结果
从表5得出加了attention之后的案件要素识别效果优于bert-bigru-crf,证明了attention在案件要素识别中起着重要作用,加attention可以提取高层的语义信息,提升案件要素识别的准确率,证明了本文方法在刑事案件要素识别任务中取得了很好的效果。
(4)为了验证bigru比bilstm更适合刑事案件要素识别任务,设置了bert-bilstm-a-crf与bert-bigru-a-crf的对比实验,同样使用刑事案件新闻语料进行实验,实验结果如表6所示。
表6bigru比bilstm对比实验结果
从表6看出使用bigru识别效果稍好于bilstm,因为bigru是bilstm的简化版,需要训练的参数的较少,训练时间短,但是性能不变;也证明本文方法对刑事案件要素识别有很好的效果。
综合以上实验结果分析,证明了本文提出的基于bert预训练模型的案件要素识别方法在刑事案件要素识别任务中取得了很好的效果。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!