一种基于深度学习的规划子目标合并方法与流程
本发明涉及智能规划领域和深度学习领域,特别涉及一种基于深度学习的规划子目标合并方法。
背景技术:
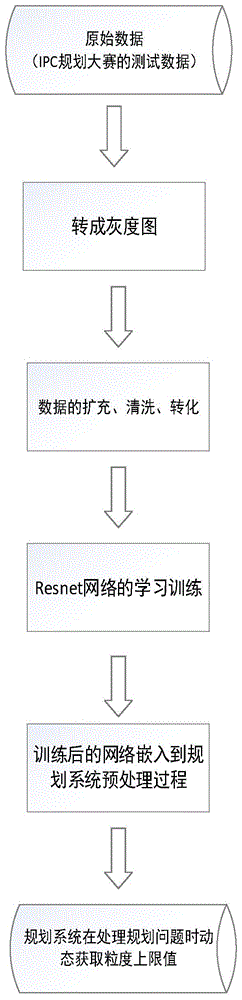
:智能规划的研究开始于20世纪60年代,源于对状态空间搜索、定理证明和控制理论的研究,以及机器人调度和其他领域的实际需求。在过去几十年的发展过程中,有关智能规划领域的规划系统在求解效率和求解质量都有了明显提升。然而规划系统在面对大规模的复杂问题时,依然有很大的瓶颈,人们尝试将原来的任务分解,通过分治思想来完成目标状态,以此来简化原来的规划问题,相关学者设计了分层任务网络规划系统(htn),此类规划系统的核心是将原任务逐步分解细化,分解成小规模子任务,其中每个子任务都是原子任务(primitivetask),只需直接执行规划操作就能实现这些子任务。然而此类规划系统相比较与主流的启发式搜索规划系统,很难构造能合理分解子任务的方法集合,使用此类规划系统需要对该领域有着足够了解。过高的使用门槛大大限制了htn规划系统的实际应用。为此相关研究者们设计了多种子目标排序算法,在基于启发式搜索的规划系统上引入了任务分解的概念。子目标排序算法的基本思想是先确定原始目标集合的交互关系,再根据交互关系确定目标之间的顺序关系,将含有先后次序的目标集合进行拆分,规划系统再按序求解各个拆分后的简单任务集合。可纳排序算法相比较与强制排序、合理排序等其他排序算法,更弱化了子目标间的约束条件,且它是合理的排序方法,相关研究人员已经通过理论证明其正确性。排序算法的思想是其仅仅给出了符合实际的合理建议,并不要求子目标之间的顺序强制性,顺序先后的次序更有利于最优规划解的产生。然而,在实际使用过程中,基于可纳排序算法的asop规划系统在部分领域处理规划问题时,可能会出现规划解质量不够理想,也可能会出现求解同一领域相同规模的规划问题时,求解效率明显不一致的情况,使得规划求解效率不稳定。究其原因在于可纳排序关系并非总是符合最优的子目标实现顺序,错误的排序可能会导致之后的搜索方法发生异常。通过子目标部分的合并可以缓解存在的问题,然而合并会增加单个目标集合的命题数,使得状态的搜索空间会增大,导致求解能力的下降。设置粒度的上限值,即子目标合并后最大集合的命题数占所有命题数的比例上限,可以平衡求解质量和求解效率。如何确定不同领域不同规划问题的目标集合粒度上限值,有着重要的研究意义。技术实现要素:为了能够更好确定目标集合粒度的上限阈值,进而平衡规划系统在求解问题时的效率和质量,本发明提出了一种基于深度学习的规划子目标合并方法,将深度学习技术与智能规划领域相结合,动态调整粒度的上限阈值。本发明提出了一种基于深度学习的规划子目标合并方法,包括如下步骤:s1:数据集的生成,即用来获取训练用的数据集,数据集包含规划问题,一开始用数据模型来表示,从ipc国际规划大赛获取数据模型并转化为灰度图,将其作为样本的输入,子目标粒度的上限值作为样本的输出,以此来构建数据集,并对样本进行数据扩充和数据清洗。因为后面深度学习要很多数据量,所以需要扩充数据量。具体的子流程如下:s11:将ipc国际规划大赛的数据模型作为基本数据集,包括领域模型和问题模型,并通过locm2模型获取工具来扩充数据量,并清洗数据,去除不符合要求的数据,其中,通过一个数据模型能表示一个规划问题,包括问题的初始状态、目标状态和其他信息;领域模型主要包含一些动作,如对于tpp(购买者旅行问题),这里的动作包括汽车car的drive动作、buy动作、load动作、upload动作;问题模型主要包含问题的初始状态和目标状态;s12:使用defli规划系统的数据翻译功能,将步骤s11的所述数据模型从规划表示语言pddl语言转化成可用作学习的灰度图,以此作为样本的输入部分,这是因为后面深度学习需要用图作为输入,而步骤s11里面的数据模型不是图表示,所以这边需要用这个工具将数据模型转化成图;s13:使用基于可纳排序的asop规划系统对步骤s11的数据模型进行规划求解,求解时设置规划过程中粒度的上限阈值maxps,maxps表示子目标合并后最大集合的命题数占所有命题数的比例上限。maxps默认初始值为最小值0%,表示不允许合并操作。s14:如果规划求解质量提高,则将maxps值增加1%,重复步骤s13操作,直至maxps为100%或者基于可纳排序的asop规划系统的规划求解质量不再提高,将此阈值maxps作为样本的输出部分,其中maxps为100%表示对合并后的集合粒度大小没有限制。因为子目标合并主要影响求解的质量,当求解质量不再改变时,就可以不需要再合并了,也就是说此时就能确定maxps值。s2:将步骤s1获取的样本作为深度学习模型进行训练,模型选取resnet,对不同领域的规划问题分开训练,从而产生各个领域的训练后的深度学习模型。具体的子流程如下:s21:选取卷积神经网络resnet50残差网络进行数据训练,其网络结构由一系列的卷积层、池化层和批量的归一化层所构成,并使用了relu激活函数,能有效对图像数据分类预测进行学习和训练,该网络可以通过tensorflow开源软件库引入,训练的数据为步骤s1获取的任一领域样本;s22:重复步骤s21,对不同领域的样本数据分开训练,直至所有样本训练完毕;s23:生成各个领域训练后的深度学习模型,以领域名称作为深度学习模型的唯一标识符。s3:修改基于可纳排序的asop规划系统的预处理过程,加入子目标粒度阈值的更新功能,通过训练后的深度学习模型,规划系统能够根据具体规划问题来确定粒度的上限。具体的子流程如下:s31:修改asop规划系统的预处理代码,构造参数<p,domain>,p表示处理成灰度图的规划问题,domain表示领域名称,如domain值若为“tpp”,表示该领域为tpp领域;s32:根据参数<p,domain>调用步骤s23训练后的该领域的深度学习模型;s33:接收训练后的该领域的深度学习模型运行后的返回值maxps,maxps表示该规划问题最恰当的粒度上限;s34:更新原来设置的maxps为步骤s33的接收值。本发明所提供的一种基于深度学习的规划子目标合并方法,可以合理确定集合粒度的上限值,通过学习的方法使得计算机自身能够识别不同领域不同规划问题的特征,其将特征学习融入到了智能规划领域,减少了人为设计特征造成的不完备性,通过动态地调整上限值,可以有效平衡求解质量和求解效率。附图说明图1为本发明的方法流程图;图2为构建数据集的流程图;图3为resnet网络结构的示意图;图4为改进后的子目标排序及合并方法流程图;图5为改进后的规划系统求解规划问题的流程图。具体实施方式下文与图示本发明原理的附图一起提供对本发明一个或者多个实施例的详细描述。结合这样的实例描述本发明,但是本发明不限于任何实施例。本发明的范围仅由权利要求书限定,并且本发明涵盖诸多替代、修改和等同物。在下文描述中阐述诸多具体细节以便提供对本发明的透彻理解。出于示例的目的而提供这些细节,并且无这些具体细节中的一些或者所有细节也可以根据权利要求书实现本发明。如上所述,本发明所提供的一种基于深度学习的规划子目标合并方法,可以合理确定集合粒度的上限值,通过学习的方法使得计算机自身能够识别不同领域不同规划问题的特征,其将特征学习融入到了智能规划领域,减少了人为设计特征造成的不完备性,通过动态地调整上限值,可以有效平衡之后规划器运行时候的求解质量和求解效率。在进行深度学习的模型训练前,首先需要获取ipc规划大赛的测试数据充当原始样本,数据由多个领域构成,这里以tpp领域为例,该领域包含30个问题模型和1个领域模型,将其中的每个问题模型和共有的领域模型作为一条记录,每条记录都是由pddl语言表示,问题模型表达了具体的问题结构,每个问题模型作为该问题的唯一标识符,主要由初始状态、目标状态构成。领域模型由对象类型、谓词、动作三部分组成,每个领域模型作为该领域的唯一标识符,具体的数据格式如表1所示。表1tpp领域模型place地点(对象类型)depot仓库(对象类型)market市场(对象类型)truck卡车(对象类型)goods货物(对象类型)(loaded?g-goods?t-truck?l-level)货物g处在运载状态(谓词)(ready-to-load?g-goods?m-market?l-level)货物g处在装载状态(谓词)(stored?g-goods?l-level)货物g处在储存状态(谓词)(on-sale?g-goods?m-market?l-level)货物g处在销售状态(谓词)drive驾驶(动作,用于卡车)load运载(动作,用于卡车和货物)unload卸载(动作,用于卡车和货物)buy购买(动作,用于卡车和货物)参考图2,本发明的步骤s1关注数据集的生成,从ipc国际规划大赛获取数据模型并转化为灰度图,将其作为样本的输入,子目标粒度的上限值作为样本的输出,以此来构建数据集,并对样本进行数据扩充和数据清洗。具体的子流程如下:s11:将ipc国际规划大赛的数据模型作为基本数据集,包括领域模型和数据模型,并通过locm2模型获取工具来扩充数据量,具体的扩充部分在于问题模型的扩充,每增加一个问题模型,相当于增加一个样本数据,增加的数量可以根据实际情况来确定,这边选取包括tpp、storage等7个领域,并对每个领域的数据扩充到约10000条。之后进行数据的清洗,去除一些不符合实际的数据和噪声数据。s12:使用defli规划系统的数据翻译功能,将步骤s11的数据模型从规划表示语言pddl语言转化成可用作学习的灰度图,灰度图由图的邻接矩阵(n,e)来表示,表明这是个大小为n*n的黑白图像,以此作为样本的输入部分。s13:使用基于可纳排序的asop规划系统对s11的数据模型求解,求解时设置规划过程中粒度的上限阈值maxps,maxps表示子目标合并后最大集合的命题数占所有命题数的比例上限。maxps默认初始值为最小值0%,表示不允许合并操作。s14:如果规划求解质量提高,对maxps值增加1%,重复步骤s13的操作,直至maxps为100%或者规划系统的规划求解质量不再提高,将此阈值maxps作为样本的输出部分,其中maxps为100%表示对合并后的集合粒度大小没有限制。参考图3,本发明的步骤s2将步骤s1获取的样本作为深度学习模型进行训练,模型选取resnet,并定义参数。训练过程中,需要对不同领域的规划问题分开训练,从而产生各个领域的特征模型,具体的子流程如下:s21:选取卷积神经网络resnet50残差网络进行数据训练,其网络结构由一系列的卷积层、池化层和批量的归一化层所构成,并使用了relu激活函数,能有效对图像数据分类预测进行学习和训练,该网络可以通过tensorflow开源软件库引入,训练的数据为步骤s1获取的任一领域样本。引入网络之后,首先需要对所需参数初始化,参数包括:设置批尺寸batch_size为2;学习速率为0.0001;线程数num_threads为4;队列容量capacity为10000;队列最小保留数据量为9900。接下来将label值进行onehot编码,直接调用tf.one_hot函数,由于输出类别有100类,类别值为1%至100%,故depth设置成100。之后定义损失函数、优化器和准确率函数,其中损失函数选取sigmoid函数,优化器选取adamoptimizer,准确率函数选取argmax函数。网络构建完毕后,就可以运行学习模型来对样本进行训练,训练的数据为步骤s1获取的任一领域样本;s22:重复步骤s21,对不同领域的样本数据分开训练,直至所有样本训练完毕;s23:生成各个领域训练后的深度学习模型,以领域名称作为深度学习模型的唯一标识符。由于输入样本包含7个领域,故最后会生成7个模型,使用时根据规划问题所处的领域来确定具体的模型。参考图4、图5,本发明的s3主要在于规划系统的修改,修改内容为asop规划系统的预处理过程,加入子目标粒度阈值的更新功能,通过训练后的模型,规划系统能够根据具体规划问题来确定粒度的上限。具体的子流程如下:s31:修改asop规划系统的预处理代码,将原来静态的粒度阈值改为函数getmaxps的动态获取,getmaxps函数的参数为<p,domain>,其中p表示处理成灰度图的规划问题,domain表示领域名称,如domain值若为“tpp”,表示该领域为tpp领域;s32:根据输入的规划问题可以构造参数<p,domain>,并使用getmaxps函数调用步骤s23训练后的深度学习模型;s33:接收模型运行后的返回值maxps,maxps表示该规划问题最恰当的粒度上限;s34:更新原来设置的maxps为步骤s33的接收值。综上所述,本发明提供了基于深度学习的规划子目标合并方法,以上说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均有改变之处,综上所述,本说明书的内容不应该被理解为对本发明的限制。因此,在不偏离本发明的精神和范围的情况下,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附的权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1