一种适用于增强现实应用的视觉惯导融合位姿估计方法与流程
本发明属于增强现实技术领域,具体涉及一种适用于增强现实应用的视觉惯导融合位姿估计方法。
背景技术:
目前,增强现实(ar)技术在世界范围内正呈现爆发式的增长态势,同时定位与建图(slam)技术能够为ar眼镜或者移动端ar提供鲁棒和精确的位姿估计,解决了ar中几何一致性的关键问题,因而成了ar系统当中的关键技术。slam技术提供的鲁棒精确的位姿估计确保了ar系统为用户所带来的沉浸式体验。
低精度的消费级memsimu在移动端的快速普及以及诸如手机等移动端计算能力的提升为视觉和imu惯导融合位姿估计算法在移动端上的应用提供了可能。视觉和imu两种传感器之间的天然互补性为视觉惯导融合的位姿估计算法拥有更好的鲁棒性提供了理论依据。然而目前的视觉惯导融合位姿估计方法多是针对移动机器人的定位与建图问题而设计的。在ar应用场景中,目前的方法面临着对诸如快速运动、大角度旋转等敏捷运动不够鲁棒以及运算量偏大等诸多挑战。由此导致跟踪失败或者因为累积误差无法消除导致3d虚拟物体产生漂移,严重影响了ar应用的用户体验。
技术实现要素:
本发明的目的在于,针对位姿估计算法对敏捷运动不够鲁棒以及累积误差不易消除的缺陷,提出了一种新型的适用于增强现实应用的视觉惯导融合位姿估计方法,该方法能够降低位姿估计方法的累积误差并对敏捷运动的情况下保持良好的位姿估计精度和鲁棒性。
本发明采用的技术方案:
一种适用于增强现实应用的视觉惯导融合位姿估计方法,具体包括如下步骤:步骤1、分别从图像传感器和imu中采集图像和imu数据;步骤2、图像和imu数据的鲁棒预处理;步骤3、系统鲁棒初始化;步骤4、启动位姿估计模块,持续不断地对系统位姿进行估计并向外输出系统最新的位姿;步骤5、启动回环检测和位姿图优化模块,基于点特征和线特征描述子构建图像数据库,将到来的最新关键帧图像和数据库中的图像进行对比,如果相似度大于某个阈值,则认为出现了回环,利用检测到的回环信息消除最新关键帧的累积误差。
所述步骤1中,所述图像传感器和imu集成在一起构成视觉惯性模组,并开放相关的api,通过调用api即可采集得到图像和imu数据。
在视觉惯性模组中集成一个晶振,图像和imu数据的时间戳均由同一个晶振产生,以此降低图像和imu数据之间的时延,保证图像和imu数据的时间戳在硬件上的同步。
所述步骤2包括图像的鲁棒预处理和imu数据的鲁棒预处理,
其中,图像的鲁棒预处理包括如下步骤:
步骤2.1、检测imu数据中的加速度值,如果加速度值超过了一定的阈值,则认为发生了敏捷运动,在进一步处理之前需要使用维纳滤波对图像进行去模糊处理;如果加速值没有超过阈值,则无需进行去模糊的处理;
步骤2.2、对图像调用lsd线段提取算法,提取图像中所包含的线段;提取完线段之后,再在图中非线段处提取特征点;
imu数据的鲁棒预处理包括如下步骤:
步骤2.3、确定imu数据为载体加速度值和角速度值,根据图像和imu数据所带的时间戳对图像和imu数据进行时间戳对齐;
步骤2.4、imu数据预积分,确定tk时刻和tk+1时刻内,位移、速度和方向的增量,分别为
其中:
对步骤2.4当中的连续型积分公式,采用中值积分进行离散化处理,对于第i+1个imu数据ai+1,ωi+1,中值积分的公式如下:
其中
将[tktk+1]时刻内的所有imu数据都按上述公式进行处理后,可以得到时刻tk和tk+1之间的位移、速度和方向的增量
因为[tktk+1]时间段内的imu输出是不会变得,所以状态增量
为了后续的imu残差项的构建,还需要对imu预积分量
利用公式
pk+1=fpkft+vqvt(6)
进行预积分量协方差的递推,其中pk是tk时刻的协方差矩阵,f为误差项对状态增量的一阶导,v为误差项对噪声项的一阶导而q为噪声项的协方差矩阵,这样,最新时刻的状态增量的协方差矩阵pk+1得到更新和维护。
所述步骤3包括求解滑窗内所有帧的位姿、所有3d点的位置、所有线段的相关参数、重力方向、尺度因子、陀螺仪的bias以及每一图像帧所对应的速度。
所述步骤4包括如下步骤:在位姿估计模块中,系统维护的核心数据结构是大小为10的滑动窗口;对于滑动窗口中包含的每一个关键帧都含有一个总的带估计变量x,变量x包含了所有需要估计的具体变量,具体地有
根据滑窗中所维护的数据结构,构建imu残差项、特征点残差项、线特征残差项以及滑动窗口滑动时边缘化所产生的先验项;在构建完所有的残差项之后,将这些残差项一起构成联合优化函数,通过最小化联合优化函数得到状态的最优估计。
具体地步骤如下:
构建imu残差项:
根据滑动窗口中两个图像帧之间的预积分量,构建imu残差函数如下:
特征点残差项:假设第l个特征点首次在第i个图像帧中被观测到,转换到当前的第j个图像帧所对应的相机坐标系下,则定义视觉重投影误差为:
其中,
线特征残差项与特征点构成重投影残差类似,每一条空间直线可以构成如下的重投影误差函数:
其中,elk,j=d(zk,j,khcwlw,j)表示空间直线的重投影误差,lw,j为空间直线的普吕克坐标,ρ为鲁棒性核函数;
当滑动窗口开始滑动时,对滑窗中的状态进行边缘化,由边缘化可以产生先验残差;
通过联合前面几个残差函数构成联合优化项,对于该联合优化项进行优化,随后,将系统最新的位姿向外输出;系统都会往外输出一个最新位姿,如此不断往复,持续对系统位姿进行估计并输出。
所述步骤5包括如下步骤:
步骤5.1、使用大量的特征描述子进行训练,通常采用离线的方式构建视觉词典;
步骤5.2、利用kmeans++算法进行聚类,在进行训练之前指定词典数的深度l和每层的节点数k;
步骤5.3、在建立好视觉词典后,对输入图像和历史图像之间的相似性进行对比。
与现有技术相比,本发明的有益效果在于:
(1)本发明提供一种适用于增强现实应用的视觉惯导融合位姿估计方法,在视觉前端部分构建了一个融合了点特征和线特征的视觉跟踪模块,即使是在特征点缺失的场景中也能够因为有线特征的存在而稳定工作,为后端优化持续提供准确的位姿初值,大大提升位姿估计方法的鲁棒性。
(2)如果出现敏捷运动,从相机采集到的图像可能会产生运动模糊的情况。当运动模糊产生时,视觉前端失效,后端仅靠imu数据进行位姿估计,此时,因为imu读数漂移的特性将不可避免地产生累积误差;为了应对敏捷运动过程中造成的运动模糊,本方法通过检测imu中加速度计的瞬时输出,如果输出值大于某个阈值则认为出现了敏捷运动,那么在视觉前端部分将对采集到的图像使用维纳滤波进行去模糊的处理,去模糊后得到更加清晰的图像这将降低运动模糊对前端视觉跟踪的影响。
(3)对于采集到的imu读数,本方法采用imu预积分的方式进行处理,这样做的好处在于当滑动窗口中的带估计状态进了一次非线性优化之后可以避免imu数据的重传,节省了大量的计算时间。
(4)为了进一步减少累积误差并提升系统的鲁棒性,该方法构建了一个基于点描述子和线描述子和混合词袋模型,在混合词袋模型的基础上构建相应的关键帧的检索和匹配模块,基于该模块实现的回环检测能够对两帧图像中所包含的点特征和线特征进行检索和匹配,这种融合了点特征和线特征的检索与匹配能够提升在弱纹理场景下的回环检测和重定位的成功率提升系统鲁棒性,降低累积误差。
附图说明
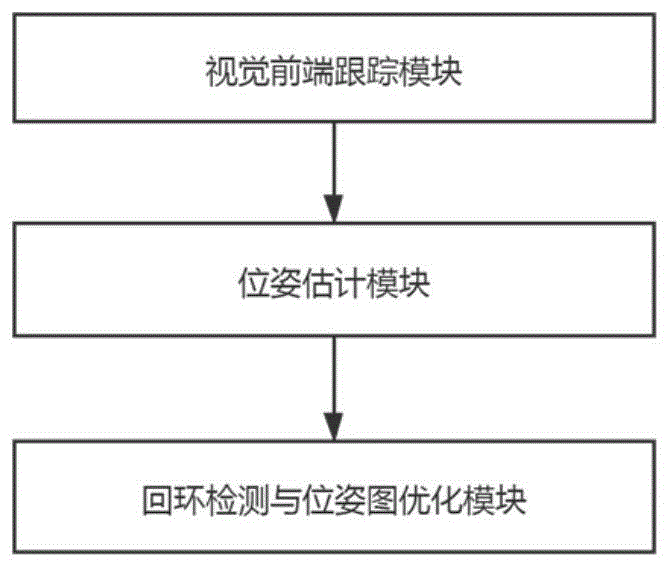
图1为本位姿估计方法的主要功能模块;
图2为本位姿估计方法的处理流程。
具体实施方式
下面结合附图和具体实施例对本发明提供的一种适用于增强现实应用的视觉惯导融合位姿估计方法作进一步详细说明。
如图1所示,一种视觉惯导融合位姿估计系统,包括视觉前端跟踪模块、位姿估计模块、回环检测和位姿图优化模块;其中:视觉前端跟踪模块,主要功能是接收图像和imu数据并进行鲁棒性预处理;位姿估计模块,在系统进行非线性优化状态之前,需要对系统进行鲁棒性初始化,获取环境的初始局部地图;回环检测和位姿图优化模块,能够提升系统的鲁棒性和估计精度。
如图2所示,本发明提供的一种适用于增强现实应用的视觉惯导融合位姿估计方法,
具体包括如下步骤:
步骤1、分别从图像传感器和imu中采集图像和imu数据
图像传感器和imu集成在一起构成视觉惯性模组,比如将左右两个摄像头和一个imu器件集成在一个电路板上构成一个视觉惯性模组;并开放相关的api用于读取图像和imu数据,在使用时通过调用api即可采集得到图像和imu数据。
值得注意的是,视觉惯导融合位姿估计算法要求图像和imu数据的时延尽可能低,最好是没有时延。因此,在视觉惯性模组中集成一个晶振,图像和imu数据的时间戳均由同一个晶振产生,以此来尽可能降低图像和imu数据之间的时延,这就保证了图像和imu数据的时间戳在硬件上的同步。经过时间同步的图像和imu数据能够在后续的数据处理过程中降低累积误差的产生。
步骤2、图像和imu数据的鲁棒预处理
图像的鲁棒预处理:
在获取一帧图像之后,首先检测imu数据中的加速度值,加速度值反映了视觉惯性模组此时的瞬时运动状态。如果加速度值超过了一定的阈值,则认为发生了敏捷运动,在进一步处理之前需要使用维纳滤波对图像进行去模糊处理,以防止敏捷运动造成了图像模糊影响后续的位姿估计精度;如果加速值没有超过阈值,则无需进行去模糊的处理。
随后,先是对图像调用lsd线段提取算法,提取图像中所包含的线段;提取完线段之后,再在图中非线段处提取特征点。
为了限制计算量需要对所提取的线段和特征点的数量进行限定,限定的策略灵活多样,比如限定线段和特征点的数量为n,优先提取l个线段之后再提取p个特征点并保持n=l+p的数量关系。
imu数据鲁棒预处理:
对于六轴imu而言,它的输出数据为载体加速度值和角速度值。由于imu数据和图像是硬件同步的,因此可以根据图像和imu数据所带的时间戳对图像和imu数据进行时间戳对齐。
对于imu的输出数据建模如下:
其中:
上述公式表明,imu中加速度计和陀螺仪的输出的测量值
其中右上角的w表示这些状态是在世界坐标系也就是惯性坐标系下的状态,
其中
可以看到上述积分公式中,tk+1时刻的载体状态
为了避免上述情况发生,一般会采用imu预积分的方法。所谓预积分是指这段tk时刻和tk+1时刻内,位移、速度和方向的增量,记作
其中
因为imu器件输出的是采样后的离散值,因此对于上述的连续型积分公式,在实际应用中需要进行离散化处理。比如采用中值积分,对于第i+1个imu数据ai+1,ωi+1,中值积分的公式如下:
其中
将[tktk+1]时刻内的所有imu数据都按上述公式进行处理后,可以得到时刻tk和tk+1之间的位移、速度和方向的增量
因为[tktk+1]时间段内的imu输出是不会变得,所以状态增量
同时为了后续的imu残差项的构建,还需要对imu预积分量
这里采用的是误差随时间变化的递推方程的形式,利用公式pk+1=fpkft+vqvt进行预积分量协方差的递推,其中pk是tk时刻的协方差矩阵,f为误差项对状态增量的一阶导,v为误差项对噪声项的一阶导而q为噪声项的协方差矩阵,这样,最新时刻的状态增量的协方差矩阵pk+1可以得到更新和维护。
步骤3、系统鲁棒初始化
系统鲁棒初始化包含了求解滑窗内所有帧的位姿、所有3d点的位置、所有线段的相关参数、重力方向、尺度因子、陀螺仪的bias以及每一图像帧所对应的速度等。
设定滑动窗口大小为10,对于依次到来的前十帧图像,系统不做任何处理,直到滑动窗口被塞满了十帧图像,此时,开始进行系统的鲁棒初始化。
首先利用纯sfm方法求解滑窗内所有帧的位姿、3d点的位置和图像中线段的相关参数,在求解到了滑窗中所有帧的位姿之后,通过将纯视觉sfm的结果与imu预积分结果进行对齐可以对陀螺仪的bias作出一个较为准确的估计;随后,通过最小化预积分增量
步骤4、启动位姿估计模块
在系统完成了初始化步骤之后,就进入位姿估计模块。系统在位姿估计模块要做的便是持续不断地对系统位姿进行估计并向外输出系统最新的位姿。在位姿估计模块中,系统维护的核心数据结构是大小为10的滑动窗口;对于滑动窗口中包含的每一个关键帧都含有一个总的带估计变量x,变量x包含了所有需要估计的具体变量,具体地有
根据滑窗中所维护的数据结构,可以构建imu残差项、特征点残差项、线特征残差项以及滑动窗口滑动时边缘化所产生的先验项;在构建完所有的残差项之后,将这些残差项一起构成联合优化函数,通过最小化联合优化函数得到状态的最优估计。
具体地步骤如下:
(1)根据滑动窗口中两个图像帧之间的预积分量,构建imu残差函数如下:
对于滑动窗口中的每两个图像帧之间都可以构建一个imu残差函数,该残差函数对两帧之间的相对位姿构成了一个约束。
(2)对于滑窗中两帧之间的特征点,它们可以构成重投影误差:假设第l个特征点首次在第i个图像帧中被观测到,转换到当前的第j个图像帧所对应的相机坐标系下,则可以定义视觉重投影误差为:
其中,
(3)与(2)中特征点构成重投影残差类似,每一条空间直线可以构成如下的重投影误差函数:
其中,elk,j=d(zk,j,khcwlw,j)表示空间直线的重投影误差,lw,j为空间直线的普吕克坐标,ρ为鲁棒性核函数。
(4)当滑动窗口开始滑动时,为了尽可能少地减少约束信息的丢失,需要对滑窗中的状态进行边缘化,由边缘化可以产生先验残差。
(5)通过联合前面几个残差函数构成联合优化项,对于该联合优化项,使用诸如g-m或者l-m之类的非线性优化方法进行优化,通过最小化该联合优化函数即可得到待估计状态x的最大后验估计,随后,将系统最新的位姿向外输出。
系统每当接收到一幅图像帧都会进行一次上述从(1)到(5)的整个过程,这个过程称为局部ba,也就是说每经过一次局部ba,系统都会往外输出一个最新位姿,如此不断往复,持续对系统位姿进行估计并输出。
步骤5、启动回环检测和位姿图优化模块
随着系统运行时间的增加,微小的误差不断累积将造成较大的误差导致系统输出的位姿不再准确;因此,需要有回环检测模块来消除累积误差,该模块的主要功能是基于点特征和线特征描述子构建图像数据库,将到来的最新关键帧图像和数据库中的图像进行对比,如果相似度大于某个阈值,则认为出现了回环,利用检测到的回环信息消除最新关键帧的累积误差。
具体地,在本申请实施例中构建了一个点线综合的视觉词典用于回环检测。
(1)首先使用大量的特征描述子进行训练,通常采用离线的方式构建视觉词典。
(2)然后利用kmeans++算法进行聚类,在进行训练之前指定词典数的深度l和每层的节点数k。本实例中采用的是orb特征点的描述子和lbd直线特征描述子。这两种描述子都是256位的二进制描述子。为了区别点和线特征的描述子,在描述子中添加标志位,标志位为0表示orb点特征描述子,标志位为1表示lbd线特征描述子。
(3)在建立好视觉词典后,就可以对输入图像和历史图像之间的相似性进行对比了。在本实例中,使用tf-idf对不同词汇的重要程度进行加权判断。其中idf称为逆文档频率,表示某词汇在词典中出现频率的高低,如果特征出现的频率越低,则分类时该特征的区分度就更高。tf称为词频表示某词汇在一个图像中出现的频率,如果出现的频率越高,则它的区分度就越高。对于词典中的某个词汇wi,idf由下面的式子计算得到:
其中n表示数据集中所有特征的总数,ni表示输出词汇wi的特征数量。对于图像中某个词汇wi,tf由下面的式子计算得出:
其中n表示图像中所有特征的总数,ni表示图像中属于词汇wi的特征数量。最后词汇wi的权重等于tf和idf的乘积:
ηi=tfi×idfi
(1)当一帧图像到来时,将图像离散成词包向量,词包向量的形式为:
v={(w1,η1),(w2,η2),…,(wk,ηk)}
(2)对于任意两个词包向量va和vb,使用l1范数衡量它们之间的相似性:
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应该涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!