一种强化车辆执行最佳动作的训练方法与流程
本发明涉及车联网控制领域,特别涉及一种强化车辆执行最佳动作的训练方法。
背景技术:
智能网联车辆是通过智能控制器进行分析决策从而控制车辆在复杂多变的环境中实现安全行驶,现有的分析决策模型是通过开发者提前将各种可能会遇到的环境部署到决策模型中,使车辆在某一特定环境下,自动执行最优动作,保证车辆行驶安全。在构建的决策模型中,模型参数是经过反复实践确定的,因此,网联车辆决策模型的建立工作量巨大,面对千变万化的车辆行驶环境,开发者并不能够保证决策模型中包含每一种驾驶环境,即现有的分析决策模型并不能很好的适应复杂多变的环境,因此,需要一种能够强化车辆执行最佳动作的训练方法,使车辆具备自主学习能力,当遇到陌生环境时,能够经过训练学习,不断调整执行动作,直到执行最佳动作,达到适应新的环境的目的。
技术实现要素:
为解决上述技术问题,本发明提出具备自主学习能力的一种强化车辆执行最佳动作的训练方法。
本方法中,主要包括以下步骤:
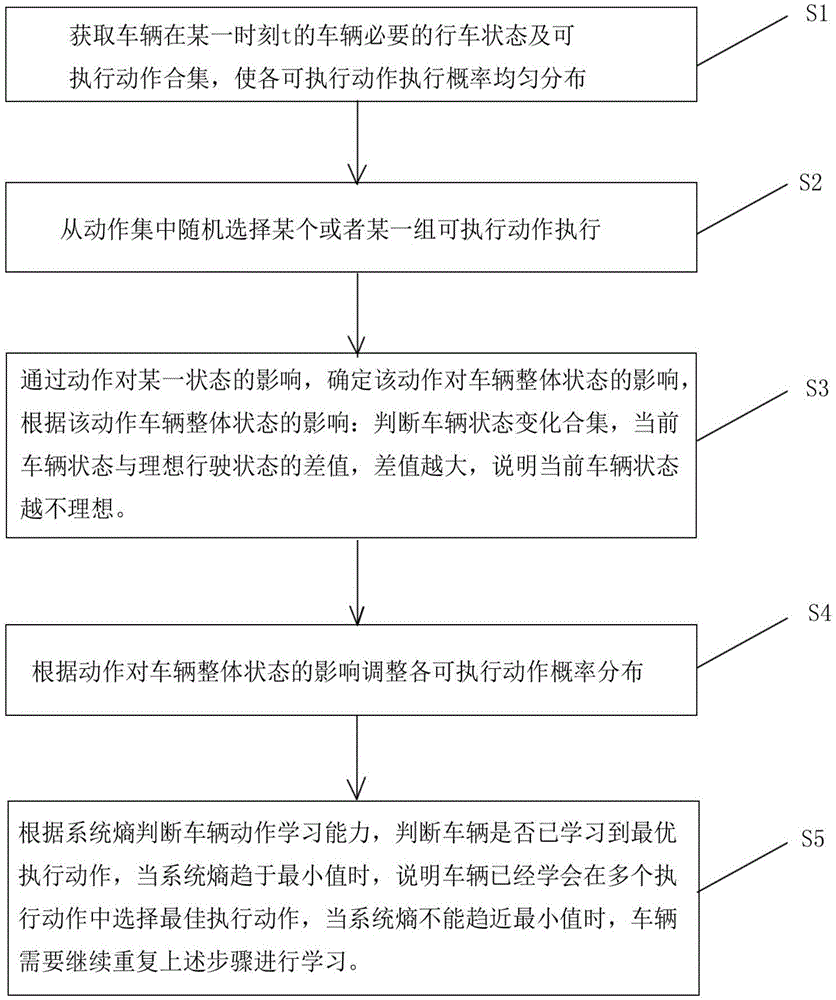
s1:获取车辆在某一时刻t的车辆必要的行车状态及可执行动作合集,使各可执行动作执行概率均匀分布;
必要的状态合集是指车辆在环境感知决策过程中需要参考的当前车辆信息数据;在t时刻,获取车辆的状态参数集合s,其中s包括但不限于车辆行驶速度、加速度、偏航角度、在地图中的坐标位置等信息、障碍物位置坐标等。
s2:从动作集中随机选择某个或者某一组可执行动作执行;
动作集中可能既包含单个动作,也包含动作组。
s3:根据不同维度的状态参数,评估车辆状态变化,建立状态影响函数;
当车辆执行某一动作后,车辆状态发生变化,以多个状态评估参数评估车辆状态的变化,例如车辆震荡参数、车辆行驶效率,车辆安全系数等评估参数。建立以动作执行为输入变量,以状态评估参数为输出变量的映射函数即状态影响函数;建立状态参数s的临界值s1、s2及理想值s0,其中s0∈[s1,s2],当s0超出该临界值区间时,表示状态参数不可接受。
建立车辆状态变化合集:
ε=ε(s)={ε(si)|i=1,2,……ns}
其中,ns为车辆状态集大小,ε表示当前车辆状态与理想行驶状态的差值,差值越大,说明当前车辆状态越不理想。
建立执行动作对车辆在t时刻的某一状态评估参数的影响函数:
在上式中,第一项计算的是受控变量与期望值之间的平方误差,第二项计算的是对动作大小(强度)变化进行的奖惩数,选取时刻t,时间段为x的动作大小变化,ωt表示t时刻执行动作大小,
根据执行动作对车辆某一状态评估参数的影响函数建立该动作
对车辆整体状态的影响函数:
ε(s)={w1s1(t)+w2s2(t)+wisi(t)}
其中,wi表示该状态评估因素对整个车辆状态的影响因子,si(t)表示评估参数影响函数。
s4:根据动作对车辆整体状态的影响调整各可执行动作概率分布;
其中,pi表示调整后的动作执行概率,pi-1表示该动作原执行概率,η为函数模型参数;yi-1表示上一次动作执行时损失函数迭代的目标值,损失函数的计算方法如下:
上式中,π(si)是利用贪婪策略进行计算,
上式中,p(ek|si)表示在si状态下,车辆执行动作ek的概率。系统熵能够判断车辆执行动作的自我调整能力,进而可以判断动作执行模型的自适应性。
根据系统熵判断车辆是否已经学习最优执行动作。当系统熵趋于最小值时,说明车辆已经学会在多个执行动作中选择最佳执行动作,当系统熵不能趋近最小值时,车辆需要继续重复上述步骤进行学习。
有益效果:本发明方法能够极大的提高智能驾驶车辆的智能化水平。一方面,本发明方法使车辆获得自主学习能力,免去了现有技术中人工训练的巨大工作量;另一方面,车辆在执行某一动作后,通过自身状态评价参数进行反馈该动作的合理性,并以该数据为依据使车辆不断自动调整动作执行,最终获取最优执行动作,当车辆再次遇到该环境时,能够直接执行最佳动作,通过训练车辆的自主学习能力,能够使车辆快速的适应陌生环境,提高了车辆的决策水平,克服了现有技术中由于环境数据有限导致的模型自适应性差的问题。
附图说明
图1为本发明的逻辑流程示意图。
具体实施方式
以下将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,基于本发明中的方法,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有变化,都属于本发明保护的范围。
本方法中,主要包括以下步骤:
s1:获取车辆在某一时刻t的车辆必要的行车状态及可执行动作合集,使各可执行动作执行概率均匀分布;
具体地,必要的状态合集是指车辆在环境感知决策过程中需要参考的当前车辆信息数据;在t时刻,获取车辆的状态参数集合s,其中s包括但不限于车辆行驶速度、加速度、偏航角度、在地图中的坐标位置等信息、障碍物位置坐标等。
具体地,可执行动作合集是指车辆在该环境下能够执行的所有动作合集。在t时刻,获取车辆的可执行动作合集e,其中e包括但不限于车辆可执行的加速度,可执行的方向盘偏转角度等动作。
s2:从动作集中随机选择某个或者某一组可执行动作执行;
某一个动作是指不需要其他配合动作的、通过改变某一个单独数据参数就能够完成的执行动作,例如直线制动动作,仅需要控制改变速度这一参数即可;某一组动作是指需要其他动作配合、需要改变多个控制参数才能完成的执行动作,例如转向动作,至少需要同时改变方向盘偏转角度参数、车辆行驶速度参数才能够配合完成转向执行动作。因此,动作集中可能既包含单个动作,也包含动作组。
s3:根据不同维度的状态参数,评估车辆状态变化,建立状态影响函数;
当车辆执行某一动作后,车辆状态发生变化,以多个状态评估参数评估车辆状态的变化,例如车辆震荡参数、车辆行驶效率,车辆安全系数等评估参数。建立以动作执行为输入变量,以状态评估参数为输出变量的映射函数即状态影响函数;建立状态参数s的临界值s1、s2及理想值s0,其中s0∈[s1,s2],当s0超出该临界值区间时,表示状态参数不可接受。
具体地,在车辆的行驶过程中,某一动作的执行影响多个状态评估参数,在执行动作时,必须将各个状态评估参数保持动态平衡才能使车辆达到理想状态,例如,车辆在一些起伏路面行驶过程中,随着速度的增加,车辆震荡参数将会持续增大,影响乘车体验,而随着车速的减小,车辆震荡参数逐渐降低,乘车体验变好,但车辆行驶效率降低。
该过程中,动作执行是速度控制,速度控制所影响的状态评估参数包括车辆震荡参数和行驶效率,因此,需要使车辆震荡参数和行驶效率达到一个平衡状态,即在保证车辆通行效率的同时保证车辆乘车体验,从而使车辆处于最理想的行驶状态。建立车辆状态变化合集:
ε=ε(s)={ε(si)|i=1,2,……ns}
其中,ns为车辆状态集大小,ε表示当前车辆状态与理想行驶状态的差值,差值越大,说明当前车辆状态越不理想。
建立动作与车辆状态参数的对应关系:(si,ei)。
建立执行动作对车辆在t时刻的某一状态评估参数的影响函数:
在上式中,第一项计算的是受控变量与期望值之间的平方误差,第二项计算的是对动作大小(强度)变化进行的奖惩数,选取时刻t,时间段为x的动作大小变化,ωt表示t时刻执行动作大小,
根据执行动作对车辆某一状态评估参数的影响函数建立该动作对车辆整体状态的影响函数:
ε(s)={w1s1(t)+w2s2(t)+wisi(t)}
其中,si(t)表示评估参数影响函数,wi表示该状态评估因素对整个车辆状态的影响因子,在训练初期,影响因子的确定可以结合专家经验确定,专家确定可根据ahp层次分析法,两两比较状态评估因素对车辆整体状态影响的重要程度,构建对比矩阵,通过求特征根的方式确定影响因子数值,并通过后期的训练不断修正影响因子。
进一步地,当车辆在执行某项动作后,任一状态评估参数超出可接受评估范围,此时该动作对车辆状态的影响函数直接取特定值或者较大的常数r,例如r=0或r=100000。
根据该动作车辆整体状态的影响:判断车辆状态变化合集,即当前车辆状态与理想行驶状态的差值,差值越大,说明当前车辆状态越不理想。
s4:根据动作对车辆整体状态的影响调整各可执行动作概率分布;
其中,pi表示调整后的动作执行概率,pi-1表示该动作原执行概率,η为函数模型参数,无特别要求,可以根据需要自动调整;yi-1表示上一次动作执行时损失函数迭代的目标值,损失函数的计算方法如下:
上式中,π(si)是利用贪婪策略进行计算,
s5:根据系统熵判断车辆动作学习能力;
上式中,p(ek|si)表示在si状态下,车辆执行动作ek的概率。系统熵能够判断车辆执行动作的自我调整能力,进而可以判断动作执行模型的自适应性。
根据系统熵判断车辆是否已经学习最优执行动作,具体地,判断系统熵是否趋于最小值,当系统熵趋于最小值时,说明车辆已经学会在多个执行动作中选择最佳执行动作,当系统熵不能趋近最小值时,车辆需要继续重复上述步骤进行学习。
需要说明的是,同后期实际应用相比,本发明方法更适用于网联车辆的前期训练,通过车辆的自主学习能力,可以省去巨大的人工训练工作量。在某些情况下,例如由于学习次数较少时,车辆还不能学习到最佳的执行动作,车辆可能会执行一些比较糟糕的选择,如果在实际应用中,可能会产生较为恶劣的后果。但是,即便如此,同现有技术相比,本方法也是较为先进的,现有技术中一些车辆的预设模型中不具备某些环境,那么当车辆一旦进入该陌生环境,车辆每次都会随机的选择动作执行,而本方法,或许车辆在前几次会选择比较糟糕的动作执行,但随着车辆的不断学习,随着进入该陌生环境的次数增多,车辆会逐渐调整动作,直到找到最佳的执行动作,并在以后进入该环境时,直接执行最佳动作,本方法同现有的技术相比,具有实质性的进步。
- 还没有人留言评论。精彩留言会获得点赞!