一种基于双色彩空间引导的动漫线稿自动上色方法与流程
本发明属于动漫线稿自动上色技术领域,涉及一种给定动漫线稿和可选人工提示,得到自动上色结果的技术,具体涉及一种基于双色彩空间引导的动漫线稿自动上色方法。
背景技术:
动漫线稿自动上色在计算机图形学和计算机视觉领域都是一项具有挑战性的任务,因为所有颜色,纹理和阴影的生成仅仅基于信息高度抽象且稀疏的线稿。此外,真实的动漫彩图绘制还是一个主观的任务,需要插画师理解诸如色相变化,饱和度对比和明暗对比等绘画先验,并在更接近人类视觉认知系统的hsv色彩空间中利用它们。因此,隐含在hsv色彩空间中的信息对线稿上色任务将有很大的帮助。然而,现存的方法都仅仅在rgb色彩空间中对方法改进来提升上色效果,而没有考虑到hsv色彩空间。
动漫线稿上色领域的最新进展主要是由深度学习方法驱动的,且主要利用的是goodfellow等人提出生成对抗网络(goodfellowij,pouget-abadiej,mirzam,etal.generativeadversarialnetworks.advancesinneuralinformationprocessingsystems,2014,3:2672-2680.)gan的能力。以生成对抗网络为基础工作,研究者们提出了不同的线稿上色方法来生成彩色图像。例如,taizan等人提出的paintschainer系列(paintschainertanpopo,canna,satsuki,2016.https://petalica-paint.pixiv.dev/indexzh.html)提供了易于操作的上色框架,并产生了一些可被大众接受的结果。但是,该系列中的canna,tanpopo受限于颜色溢出问题,不能遵循给定线稿的限制得到干净整洁的上色结果,而satsuki则会产生颜色失真问题,其输出仅为同一颜色倾向的结果。相比之下,基于双阶段判别修正的方法style2paints(zhangl,lic,wongtt,etal.two-stagesketchcolorization.acmtransactionsongraphics,2018,37(6):1-14.)改进了paintschainer出现的问题,并获得了更好的视觉效果。然而,由于其第二阶段的判别修正方式过于严苛,其生成的图像通常缺乏精确的阴影的丰富的色彩,并且每次生成都需要采用两步方式,比较耗时。除此之外,ci等人(y.ci,x.ma,z.wang,h.li,andz.luo,user-guideddeepanimelineartcolorizationwithconditionaladversarialnetworks.acmmultimediaconferenceonmultimediaconference,mm2018,pp.153)提出了一种新颖的方法ugdalac,其利用提取局部特征作为条件输入的方式,来提高生成网络对于真实线稿的泛化能力来得到合理的上色结果。虽然这些方法在动漫线稿上色领域进展斐然,但他们仍然无法生成具有明显明暗对比,丰富的色彩和合理的饱和度分布的上色结果。
针对上述问题,本发明提出了一种新颖的线稿上色算法,其基本思想是参考人类插画师的创作流程,充分考虑隐含在hsv色彩空间中的信息。结合hsv与rgb色彩空间以构造双色彩空间。并在此基础上分别提出像素级监督绘画先验dp损失函数以及全局监督双色彩空间对抗dcsa损失函数。dp损失函数使本发明能够隐式的学习插画师在真实创作过程中融入到hsv色彩空间的绘画先验得到具有和谐色彩组成的上色结果,dcsa能够鼓励本方法充分考虑rgb和hsv色彩空间的全局分布来减少伪影和人工生成物得到更加平滑的结果以满足大众的审美期望。
技术实现要素:
本发明目的提出一种基于双色彩空间引导的线稿自动上色方法。处理目标:真实的动漫线稿图像,处理目的:根据线稿结合可选输入的色彩提示生成高质量的动漫线稿上色结果。
本发明的技术方案:
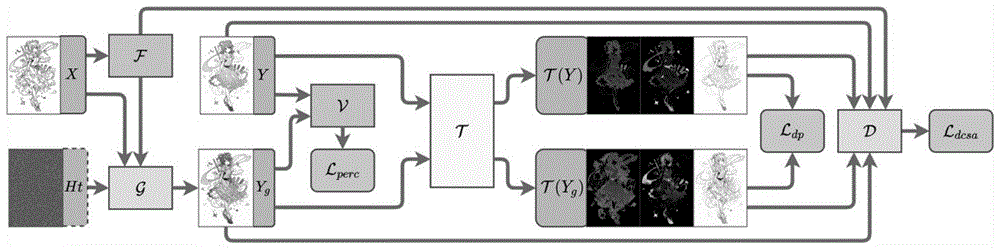
一种基于双色彩空间引导的动漫线稿自动上色方法,结合rgb和hsv色彩空间构建双色彩空间;以此为基础提出像素级及全局监督,利用生成对抗网络的方式进行训练;具体包括网络架构设计部分和算法训练部分;
(1)网络架构设计部分
算法共包含三个网络:色彩空间转换网络t、生成器g和判别器d;
色彩空间转换网络t来实现rgb到hsv色彩空间的转换,将hsv色彩空间引入到算法中以构建双色彩空间,考虑到rgb到hsv的变换是像素级的三个非线性函数,不需关注任何全局或局部信息,因此仅使用卷积核大小为1,步长为1的卷积层进行网络构建;色彩空间转换网络t的开始部分包含3个卷积层,中间部分含5个resnext(xies,girshickr,dollár,piotr,etal.aggregatedresidualtransformationsfordeepneuralnetworks.2016.)残差块来提升网络拟合性能,在末尾采用3个卷积层得到输出;为确保色彩空间转换网络t能正确地学习rgb到hsv色彩空间的转换函数,使用真实的rgb彩色动漫图像和其对应的hsv图像采用l1损失函数对网络t进行预训练;
生成器g采用ugdalac算法进行构建,采用其提出的局部特征抽取方法来缓解训练过程中出现的过拟合问题,提升生成结果的泛化效果。
判别器d的设计,在ugdalac的判别器输入层进行了改进;采用生成器g的输出,以及色彩空间转换网络t的输出串联得到的结果作为判别器d的输入,以此使判别器d从双色彩空间对算法进行监督,产生更加出众的上色结果。
(2)算法训练部分
第一步,使用生成线稿x,随机颜色提示ht,局部特征f(x)作为生成器g的输入,输出上色结果yg;
其中生成线稿x由真实彩色图像y经过xdog滤波算法得到,随机颜色提示ht由真实彩色图像y的4倍下采样结果进行随机采点得到。局部特征f(x)为局部特征提取器,方法中采用的是预训练好的illustration2vec(saitom,matsuiy.illustration2vec:asemanticvectorrepresentationofillustrations.siggraphasiatechnicalbriefs.acm,2015.)网络的第6层卷积后的结果;
第二步,采用wgan-gp框架的训练方式,结合提出的双色彩空间对抗dcsa损失函数对判别器d进行训练;
将真实彩色图像y以及生成器g的输出的上色结果yg输入到色彩空间转换网络t中得到对应的hsv色彩空间的结果t(y)和t(yg);将y与t(y)串联,yg和t(yg)串联的结果分别输入到判别器d中,利用公式1的dsca损失函数对判别器d进行训练,以此从双色彩空间进行全局监督,来提升生成器g的上色效果;
ldcsa=lad+lp公式1
其中,lad为对抗损失项,lp为梯度惩罚项,采用的是wgan-gp的损失函数定义方式来获取稳定的训练性能,具体定义如公式2,公式3所示;
在公式2中,
第三步,采用wgan-gp框架的训练方式,结合上面提到的双色彩空间对抗dcsa损失函数,以及下面的提出的绘画先验dp损失函数
其中λdp取值为10,由于dp损失是一个像素级别的损失,没有考虑到全局信息将导致不和谐纹理的产生;因此,采用公式2的双色彩空间对抗dcsa损失函数取λ1值为1e-4从双色彩空间对生成结果进行全局监督,以此来平滑人工生成物,得到符合人类审美的上色结果;除此之外,还采用了广泛应用于生成任务的视觉感知损失函数
其中,v为预训练的vgg16网络,采取其第4层卷积输出的结果作为损失计算的特征图,c,h,w分别代表特征图的通道数,高度和宽度。
本发明的有益效果:采用本发明能够对输入的动漫线稿进行高质量的自动上色,生成具有和谐色彩组成的上色结果,具体表现为丰富多样的色彩倾向,合适的饱和度及明度对比。同时,本发明极大的缓解了生成结果颜色溢出和人工生成物的问题,解决了现有方法的不足之处,更加符合人类的审美。
附图说明
图1为本发明的整体流程图。
具体实施方式
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
本发明基于pytorch深度学习框架搭建整体算法网络,基础的数据处理采用python语言实现。
step1:使用xdog滤波算法对真实的彩色动漫图像提取生成线稿,制作上色任务训练数据集data1;使用rgb到hsv色彩空间的转换公式获取真实彩色动漫图像的hsv结果,制作色彩转换网络训练数据集data2。
step2:构建色彩转换网络t,使用刚刚制作得到的配对数据集data2,采用l1损失函数训练色彩转换网络t至收敛。
step3:构建illustration2vec和vgg16网络,并获取其预训练权重待用。
step4:按照ugdalac算法的设计搭建生成器,判别器,采用ugdalac的算法的损失函数及训练流程,在上色任务数据集data1上训练至收敛。
step5:构建本发明中提出的生成器g,判别器d。采用step4中得到的生成器权重对本发明的g进行权重初始化,舍弃掉step4中的判别器权重。冻结g的权重,采用本发明的损失函数对判别器d在上色任务数据集data1中进行1000次迭代训练。
step6:结束step5的初始化操作后,采用本发明提出的训练方式和损失函数对生成器g和判别器d在data1数据集上训练至收敛。
step7:使用真实的动漫线稿及可选的颜色提示作为生成器g的输入,得到动漫线稿自动上色的结果。
- 还没有人留言评论。精彩留言会获得点赞!