一种机器学习训练数据受投毒攻击的防御方法与流程
本发明属于信息安全领域,更具体地,涉及一种机器学习训练数据受投毒攻击的防御方法。
背景技术:
近年来,随着机器学习的发展,基于机器学习的各类系统如自动驾驶系统、人脸检测系统、语音识别系统等都得到了广泛的应用,特别是智能安防系统。然而,机器学习本身面临的各种安全性问题也逐渐显现。
机器学习是指通过大量的训练数据不断地学习、识别特征、建模最后能够得到有效的系统模型。最近的研究表明,机器学习对数据投毒攻击高度敏感。在这种情况下,攻击者可以通过向训练数据集中注入少量恶意样本来破坏学习过程。此类安全漏洞可能会给各种关键安全领域带来严重风险,例如,恶意软件检测、无人驾驶汽车、生物识别身份识别。因此,如何防御机器学习中训练数据投毒攻击是机器学习安全领域必须解决的科学问题。
为了防御机器学习中训练数据投毒攻击,目前已经研究了一些防御机制,但是,这些防御技术在很大程度上是特定于攻击的:它们是针对一种特定类型的攻击而设计的,可能不适用于其他类型的攻击,这主要是由于在攻击过程中遵循不同的原理。例如,通过识别和重建后门触发器来缓解后门攻击(投毒攻击的一类)。这种防御可以检测到某些统一的后门触发器,但是在将可变扰动添加到训练数据中时会失败。在另一种情况下,一些研究者使用knn的方法来防御标签翻转攻击(另一种投毒攻击),但是这种方法不能在回归的情况下应用于投毒攻击。迄今为止,针对这种投毒攻击的通用防御策略很少,没有有效地能够防御大多数投毒攻击方法的防御方法。
技术实现要素:
本发明提供一种机器学习训练数据受投毒攻击的防御方法,用以解决现有智能安防检测模型训练用训练数据受投毒攻击的防御方法中只针对特定攻击方式的限制问题。
本发明解决上述技术问题的技术方案如下:一种机器学习训练数据受投毒攻击的防御方法,用于智能安防,所述训练数据采集于安防视频数据,所述防御方法包括:
获取待识别训练数据集对应的干净训练数据集的预测值分布;并将每个待识别训练数据输入已训练的预测模型,得到预测值;基于所述预测值与所述预测值分布确定该训练数据是否为投毒数据,以实现攻击防御;
其中,所述预测模型由以下训练方法得到:基于与待识别训练数据同类型的可信任训练数据进行数据增强,生成多个合成数据;采用由所述多个合成数据和所述可信任训练数据所构成的增强数据集训练并得到所述预测模型;所述增强数据集的分布同所述干净训练数据集,所述预测模型基于所述增强数据集所输出的预测值的分布作为所述预测值分布。
本发明的有益效果是:本发明会首先获得一个已训练预测模型,该预测模型的训练方法是:在能获得部分可信任训练数据的情况下,生成与原始的干净训练数据集分布相似的数据集,在获得足够的有效数据之后,训练预测网络,得到与原始的干净训练数据集所训练的预测模型(或者说检测模型)预测性能相似的模拟预测模型,作为上述的已训练预测模型,确保该方法在可信任训练数据不足的情况下正常适用,在得到预测模型的同时,也能够得到预测值分布并将其作为干净训练数据集的预测值分布,其中,训练数据是从智能安防视频或图像中采集获取,包括数据特征和条件信息(如分类标签或回归值),训练数据的获取为常规获取方法,另外,上述的预测值按照预测任务可为分类信息或回归值。然后将每个待识别训练数据输入已训练的预测模型,得到预测值;基于预测值与预测值分布确定该训练数据是否为投毒数据,识别出投毒数据后将投毒数据剔除,即可有效实现机器学习训练数据受投毒攻击的防御,以用于实际智能安防中的分类和回归任务。与现有防御技术方案相比较,本方法可以广泛地用于保护分类和回归任务,无需明确机器学习算法或攻击类型即可提供有效保护,是一种针对实际智能安防检测模型训练数据受各种投毒攻击的通用防御方法,解决了现有防御方法中只针对特定攻击方法的限制问题。
上述技术方案的基础上,本发明还可以做如下改进。
进一步,基于多个可信任训练数据,通过对抗训练的方式,训练cgan网络,并采用训练得到的cgan网络生成最终的合成数据;其中,在训练过程中,采用认证器监督所述cgan网络中的生成器生成合成数据,使得最终的合成数据与可信任训练数据构成的增强数据集同所述干净训练数据集。
本发明的进一步有益效果是:由于构建得到增强数据集用于得到预测模型和干净训练数据集对应的预测值分布,待识别训练数据会输入预测模型得到一个预测值,基于预测值和预测值分布来识别训练数据是否是投毒数据,因此,增强数据集的构建对于后续的投毒样本识别具有关键作用,本方法利用了gan技术的优势,采用认证器来监督cgan中生成器的生成过程,对cgan进行了优化,能够有效提高所生产合成数据的可靠性,进而保证有效的投毒攻击防御。
进一步,将多个包括条件信息的可信任训练数据输入所述判别器,同时将对应多个噪声数据和所述条件信息输入所述生成器;所述生成器基于所述条件信息将所述多个噪声数据转换为多个合成数据并输入给所述判别器和所述认证器;所述判别器度量所述多个可信任训练数据和所述多个合成数据间的差异,得到cgan损失函数;同时所述认证器预测所述多个合成数据对应的预测值并将其与对应真实值对比,得到认证器损失函数并反馈给所述cgan损失函数,以用于调整所述cgan网络的参数,其中,所述条件信息包括数据标签或回归值。
本发明的进一步有益效果是:在每次合成数据迭代过程中将认证器的损失反馈到cgan部分,充分发挥了认证器的监督作用,有效提高生成数据的可靠性。另外,在cgan和认证器的输入中均包括条件信息,能够在标签的限制下,提高训练效率。
进一步,所述反馈给所述cgan损失函数,具体为:
将所述cgan损失函数与所述认证器损失函数相减,作为所述判别器的新的损失函数;将所述cgan损失函数与所述认证器损失函数相加,作为所述生成器的新的损失函数。
进一步,采用蒙特卡洛最大期望算法和随机梯度下降法调整所述cgan网络的参数。
进一步,所述训练并得到所述预测模型,实现方式为:
基于所述增强数据集,采用对抗训练的方式,训练cwgan-gp网络,其中,所述cwgan-gp网络为在wgan-gp网络的生成器和判别器中增加标签数据输入而得到;将训练得到的所述cwgan-gp网络中的判别器作为所述预测模型。
本发明的进一步有益效果是:基于wgan-gp网络,将条件信息(标签)加入到wgan-gp网络中的生成器与判别器中得到cwgan-gp网络并训练,并将其中的判别器dw模型作为上述的预测模型,保证有效的攻击防御。
进一步,所述基于所述预测值与所述预测值分布确定该训练数据是否为投毒数据,实现方式为:
采用z-score法确定所述预测值分布的检测边界阈值;当该预测值小于所述检测边界阈值时,则该预测值对应的训练数据为投毒数据,否则为非投毒训练数据。
本发明的进一步有益效果是:比较检测边界阈值和预测值,将投毒数据与干净训练数据区分开,从而有效达到防御训练数据投毒攻击的目的。
进一步,所述检测边界阈值的确定方法为:
基于实际所需置信度水平值,查表确定所述预测值分布的zs值;
计算所述增强数据集的均值和方差;
基于所述zs值、所述均值和所述方差,计算得到检测边界阈值。
本发明的进一步有益效果是:采用z-score法,根据实际所需设置检测边界阈值,灵活性高。
进一步,所述预测值分布符合正态分布。
本发明的进一步有益效果是:得到的预测值分布符合正态分布,该分布能够方便根据实际所需置信度水平值查表zs值,进而得到合理的检测边界预测,以进行有效的投毒攻击防御。
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述存储介质所在设备执行如上所述的一种机器学习训练数据受投毒攻击的防御方法。
附图说明
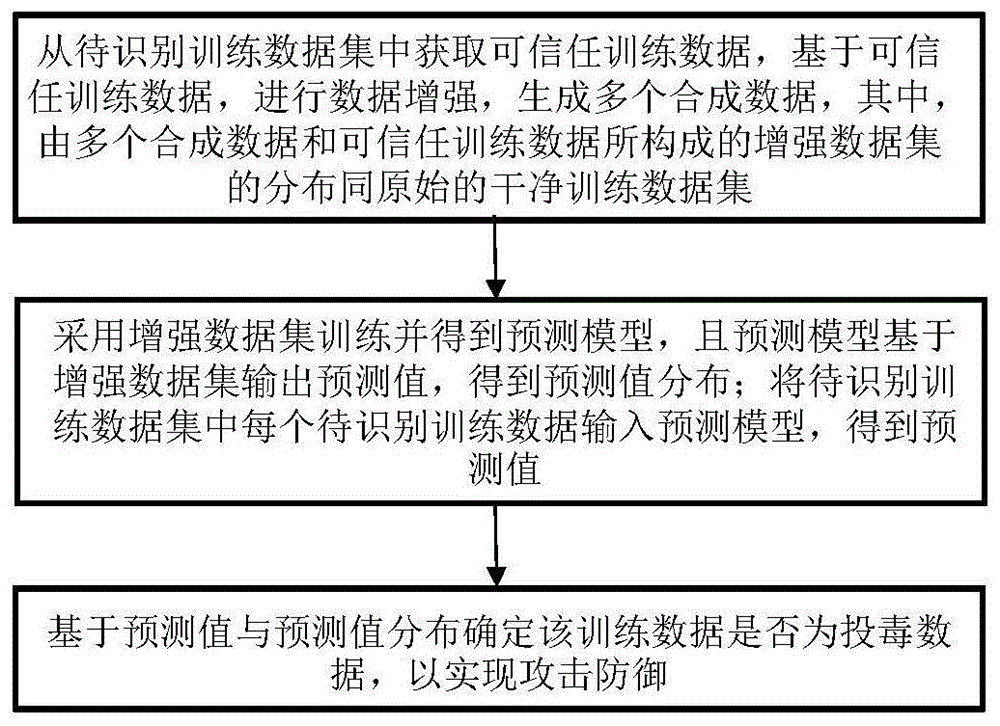
图1为本发明实施例提供的一种机器学习训练数据受投毒攻击的防御方法流程框图;
图2为本发明实施例提供的一种机器学习训练数据受投毒攻击的防御方法示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
实施例一
一种机器学习训练数据受投毒攻击的防御方法,包括:
获取待识别训练数据集对应的干净训练数据集的预测值分布;并将每个待识别训练数据输入已训练的预测模型,得到预测值;基于预测值与预测值分布确定该训练数据是否为投毒数据,以实现攻击防御;
其中,预测模型由以下训练方法得到:基于与待识别训练数据同类型的可信任训练数据进行数据增强,生成多个合成数据;采用由多个合成数据和可信任训练数据所构成的增强数据集训练并得到所述预测模型;增强数据集的分布同干净训练数据集,预测模型基于增强数据集所输出的预测值的分布作为上述预测值分布。
攻击者发动投毒攻击的一种基本实践方式为:注入的投毒样本(即投毒数据)要远离干净样本(即干净数据),也就是投毒样本与干净样本的差异很大,从而可以操纵由干净样本训练的目标模型的决策边界。本实施例基于此,首先是在获取部分信任数据集(也即由多个可信任训练数据构成的可信任训练数据集)的情况下对其增强训练数据集,获取与原始干净训练数据集类似(在规模、分布方面类似)的数据集。然后构建模拟模型,模仿与目标模型一致的行为。最后可以通过比较测试样本通过模拟模型的输出与检测边界之间的大小差异,将中毒样本与干净样本区分开。
需要说明的是,上述方法中描述有:待识别训练数据集、干净训练数据集、可信任训练数据和增强数据集,为了使得上述方法更清楚,现对这四者的关系做一个说明:可信任训练数据可以从待识别训练数据集中确定和获取,也可以从与待识别训练数据集同类型的另一个训练数据集中确定和获取,其中,关于同类型为:数据特征的来源(例如,某一类目标的图片、某一类目标的采集数值)和类型(例如,图片的亮度、大小;设备的振动信息、噪音信息)相同。另外,获取可信任训练数据的目的是:实际中,能确定的属于没有受投毒攻击的数据可能不多,因此找出部分没有受投毒攻击的训练数据作为可信任训练数据并进行数据增强,以构建与原始的干净训练数据集类似的增强数据集。由此,增强数据集是基于可信任训练数据得到。另外,上述方法中提到的干净训练数据集可以代指增强数据集也可以是上述另一个训练数据集的原始的干净训练数据集(因为该原始的干净训练数据集为没有受到投毒攻击的干净训练数据集,其可能会受到投毒攻击,而变成该另一个训练数据集),因此,上述方法中提到的待识别训练数据集与上述方法中提到的干净训练数据集也同类型。
例如,基于获取到的可信任训练数据构成可信任训练数据集,表示为st={s1,...,sn},共n个可信任训练数据,其中第i个可信任训练数据表示为:si={xi,yi},xi表示数据的特征,yi表示数据的标签或者回归值。在许多实际场景中,尤其是在用户提供的数据系统中,仅从可信数据源(例如信誉良好的用户)中获取少量干净数据(即可信任训练数据)是可行的。
另外,上述方法中提到的预测模型为基于增强数据集训练的一个模拟预测模型,模拟预测模型与上述的待识别训练数据集或上述的另一个训练数据集的原始干净训练数据集所训练出来的预测模型预测性能相似。将增强数据集输入预测模型得到预测数据集,进而得到预测值分布并将其作为干净训练数据集的预测值分布。
为了更清楚的说明本方法,现举例如下:(1)当方法中提到的可信任训练数据和待识别训练数据来源于同一原始的干净训练数据集(即方法提到的干净训练数据集)时,如图1所示,防御方法包括:从待识别训练数据集中获取可信任训练数据,基于可信任训练数据,进行数据增强,生成多个合成数据,其中,由多个合成数据和可信任训练数据所构成的增强数据集的分布同原始的干净训练数据集;采用增强数据集训练并得到预测模型,且预测模型基于增强数据集输出预测值,得到预测值分布;将待识别训练数据集中每个待识别训练数据输入预测模型,得到预测值;基于预测值与预测值分布确定该训练数据是否为投毒数据,以实现攻击防御。(2)当方法中提到的可信任训练数据和待识别训练数据集来源于不同但属于同类型的原始干净训练数据集时,其中,可信任训练数据来源于原始干净训练数据集a,待识别训练数据集来源于原始干净训练数据集b,则先采用可信任训练数据得到与原始干净训练数据集a分布相似的增强数据集,并基于该增强数据集得到预测模型和预测值分布;再将待识别训练数据集中每个待识别训练数据输入该预测模型得到预测值,基于该预测值和预测值分布进行投毒识别判断。
本实施例会首先获得一个训练的预测模型,其在能获得部分可信任训练数据的情况下,生成与原始干净数据集相似的数据集,在获得足够的有效数据之后,训练预测网络,确保该方法在可信任训练数据不足的情况下正常适用,在得到预测模型的同时,也能够得到预测值分布并将其作为干净训练数据集的预测值分布。然后将每个待识别训练数据输入已训练的预测模型,得到预测值;基于预测值与预测值分布确定该训练数据是否为投毒数据,识别出投毒数据后将投毒数据剔除,即可有效实现机器学习训练数据受投毒攻击的防御。与现有防御技术方案相比较,本方法可以广泛地用于保护分类和回归任务,无需明确机器学习算法或攻击类型即可提供有效保护,是一种针对机器学习中训练数据投毒攻击的通用防御方法,解决了现有防御方法中只针对特定攻击方法的限制问题。
需要说明的是,本方法也可适用于生物特征识别、推荐、目标检测、智能在线交互、自动驾驶等。其中,在生物特征识别中,训练数据可以为指纹或人脸信息;在推荐中,训练数据可以为电影评分信息;在目标检测中,训练数据可以为特定目标类型的图片信息;在智能在线交互中,训练数据可以为单词信息,在自动驾驶中,训练数据可以为激光传感器或雷达传感器采集的路况信息。
例如,智能安防中的生物特征识别,尤其是人脸识别与指纹识别被广泛应用于犯罪预防预警、治安交通管理、刑事案件侦查等,在追捕逃犯、发现嫌疑人身份、寻找走失人口等方面发挥了重要的作用,而在日常工作生活中人脸识别与指纹识别被应用在移动支付、手机解锁、考勤打卡等场景,为大家的生活提供了便利。当生物特征识别系统受到投毒攻击危害时,攻击者利用精心构造的数据去改变识别系统的识别结果,可以让特定的人脸与指纹直接通过识别系统的识别,例如用别人的手机可实现刷脸解锁或刷脸支付,嫌疑人可以戴上特定面具来躲避追捕从而造成巨大的损失,因此在生物特征识别系统中对所用训练数据的投毒攻击进行防御具有重要意义。其中,当进行人脸识别时,训练数据的获取方法可为:采集真实世界中n个人的m张人脸图片,其中,n可为1(例如私人手机只需要一个人的人脸信息),n也可以大于1(例如在公司、车站等需要特定部分的人脸信息);每个人包括了不同表情、光照、姿态和年龄等特征,从m张人脸图片中分别采集相同类型的特征数据及其对应的条件信息构成训练数据集。当进行指纹识别时,训练数据的获取方法可为:采集真实世界中n个人的m张指纹图片,同上n可为1(例如私人手机只需要一个人的人脸信息),n也可以大于1(例如在公司、车站等需要特定部分的人脸信息);每个人包括了不同手指、手指长宽、基本纹路等特征,从m张指纹图片中分别采集相同类型的特征数据和标签构成训练数据集。
优选的,上述数据增强的方式为:
基于多个可信任训练数据,通过对抗训练的方式,训练cgan网络,并采用训练得到的cgan网络生成最终的合成数据;其中,在训练过程中,采用认证器监督cgan网络中的生成器生成合成数据,使得最终的合成数据与可信任训练数据构成的增强数据集同干净训练数据集。
由于构建得到增强数据集用于得到预测模型和干净训练数据集的预测值分布,待识别训练数据会输入预测模型得到一个预测值,基于预测值和预测值分布来识别训练数据是否是投毒数据,因此,增强数据集的构建对于后续的投毒样本的识别具有关键作用,本方法利用了gan技术的优势,采用认证器来监督cgan中生成器的生成过程,对cgan进行了优化,能够有效提高所生产合成数据的可靠性,进而保证有效的投毒攻击防御。
优选的,如图2所示,上述cgan网络的训练过程中每次迭代训练具体为:
将多个包括条件信息的可信任训练数据输入所述判别器,同时将对应多个噪声数据和上述条件信息输入生成器;生成器基于条件信息将多个噪声数据转换为多个合成数据并输入给判别器和认证器;判别器度量多个可信任训练数据和多个合成数据间的差异,得到cgan损失函数;同时认证器预测多个合成数据对应的预测值并将其与对应真实值对比,得到认证器损失函数并反馈给cgan损失函数,以用于调整cgan网络的参数,其中,因为机器学习任务包括了分类与回归,在分类中条件信息叫标签,在回归中条件信息叫回归值本实施例防御方法能够用于分类和回归两种情况。
通过认证器来监督生成数据的可靠性,并在每次合成数据迭代过程中将认证器的损失反馈到cgan部分。
优选的,上述反馈给cgan损失函数,具体为:
将cgan损失函数与认证器损失函数相减,作为判别器的新的损失函数;将所述cgan损失函数与认证器损失函数相加,作为生成器的新的损失函数。
具体的,将k个可信任训练数据的数据特征x与条件信息y作为cgan判别器dc的初始输入,将k个噪声数据z与同样的条件信息y为cgan生成器gc的初始输入,再通过对抗训练来训练cgan模型参数,生成与原始数据集相似(在规模、分布方面类似)的合成数据集,期间基于认证器来监督cgan进行数据增强的过程。
其中,生成对抗网络gan包含了生成器g与判别器d。在训练过程中,g的输入是一个噪声向量z,g会尽量的生成与原始数据样本相似(在规模、分布方面类似)的样本,判别器d会判别出数据样本属于生成的数据样本还是真实的数据样本。g跟d交替训练,最终达到均衡。而cgan为了解决原始gan中模式崩塌的缺点,在g跟d的输入中都引入了额外的信息,如类别标签或者回归值,这样生成的数据会在一个有监督的条件下进行,其cgan损失函数可以描述成:
另外,一般机器学习任务主要分为分类与回归。对于分类任务来说,认证器(authenticator)是一个卷积神经网络,其输入是在每次迭代过程中gc的输出,并将认证器的损失反馈到cgan部分,其中,分类时,认证器的损失函数为:
将认证器的损失函数反馈到cgan部分,与gan训练过程类似,具体到cgan的判别器部分的损失函数发展成lcgan-la,cgan的生成器部分的损失函数发展成lcgan+la。
优选的,使用蒙特卡洛最大期望算法来估计深度网络中的参数,并用随机梯度下降来更新每次迭代过程中的参数,最终得到最优的合成数据。
迭代过程如下:
基于em算法估计模型参数,整个训练过程可以阐述成以下优化问题:
计算logp(θ|s,zs)关于p(zs|θi,s)的期望:
最大化q函数:
在此迭代过程中利用蒙特卡洛随机采样方法估算期望计算,并利用随机梯度下降(sgd)更新模型参数。在得到最优参数模型后,就能学习到与原始的干净训练数据集相似(在规模、分布方面类似)的数据集,然后将生成器得到的合成数据ss与可信任训练数据一起作为最后的增强数据集saug,其大小与原始的干净训练数据集大小一致,分布与原始数据集相似。
优选的,上述训练并得到预测模型,实现方式为:
基于增强数据集,采用对抗训练的方式,训练cwgan-gp网络,其中,cwgan-gp网络为在wgan-gp网络的生成器和判别器中增加标签数据输入而得到;将训练得到的cwgan-gp网络中的判别器作为预测模型。将增强数据集输入该预测模型得到预测值的集合,进而得到预测值分布。
cwgan-gp网络的生成器gw在每次迭代过程中都会尽量的生成与增强样本集分布相似的数据样本,判别器dw会判别出样本属于生成的样本还是真实的样本。之后gw和dw交替训练,到两者的损失收敛时,将判别器dw模型作为最终的预测模型。
上述cwgan-gp网络的损失函数表示为:
基于wgan-gp网络,将条件信息(标签)加入到wgan-gp网络中的生成器与判别器中得到cwgan-gp网络并训练,并将其中的判别器dw模型作为上述的预测模型,用于攻击防御。
本实施例具体利用了gan技术的优势,并在增强数据部分对设计认证器对cgan进行了优化,在模型模拟部分基于wgan-gp提出了条件的wgan-gp网络,进而得到上述一整套防御投毒攻击的方案,与现有防御技术方案相比较,可以广泛地用于保护分类和回归任务。
优选的,上述基于预测值与预测值分布确定该训练数据是否为投毒数据,实现方式为:
采用z-score法确定预测值分布的检测边界阈值;当预测值小于所述检测边界阈值时,则该预测值对应的训练数据为投毒数据,否则为干净训练数据。
基于dw模型,设置检测边界来检测投毒点与干净数据。分析出干净样本通过dw之后的输出分布符合正态分布,并且比投毒样本的输出大。因此,若分类预测值小于检测边界阈值,分类预测值对应的训练数据为投毒数据,否则为干净训练数据。
优选的,上述检测边界阈值的确定方法为:
基于实际所需置信度水平值,查表确定预测值分布的zs值;计算增强数据集的均值和方差;基于zs值、均值和方差,计算检测边界阈值。基于z-score法,检测边界阈值ythr=zs×σ+μ,如果测试样本通过dw模型之后的输出ypre满足ypre<ythr,那么测试样本即为投毒点,否则为干净样本。
优选的,经研究分析,任何一组可信任训练数据经过前述方法得到与原始干净训练数据集相似的增强数据集,经采用该增强数据集训练上述cwgan-gp,并经训练后的cwgan-gp的预测,得到的预测值分布符合正态分布,该分布能够方便根据实际所需置信度水平值查表zs值,进而得到合理的检测边界预测,以进行有效的投毒攻击防御。
因此,在得到模拟的预测模型之后,通过模型输出与设定的检测边界比较,将投毒数据与干净数据区分开,从而达到防御训练数据投毒攻击的目的。
实施例二
一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序被处理器运行时控制所述存储介质所在设备执行如上所述的一种机器学习训练数据受投毒攻击的防御方法。相关技术方案同实施例一,在此不再赘述。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!