基于LDA主题模型与分层神经网络的情感分类方法与流程
本发明涉及自然语言处理中的情感分析领域,尤其是指一种基于lda主题模型与分层神经网络的情感分类方法。
背景技术:
随着互联网行业的快速发展,越来越多的人选择通过网络来表述自己的观点与情感,如何从海量数据中高效提取出有价值的信息是一个研究重点,情感分析研究对自然语言处理、管理科学、政治学、经济学和社会科学都有很大的价值。
情感分析结合文本数据的主题是一个重要研究课题,文档主题向量本质是表示文档的深层语义,是主题和语义的内在结合,抽取的文档主题向量可以广泛的应用于情感分析任务中,例如社交网络和新媒体的舆情分析,新闻热点的及时获取等。
当前的情感分析方法主要包括以下三类:基于语言规则的方法、基于传统机器学习的方法和基于深度神经网络的方法。近年来,随着互联网的发展和数据工程的发展,文本数据的体量急剧增大和语言表示的多元化,使得神经网络技术的优势逐渐明显。相比于基于规则的方法和传统机器学习的方法,深度神经网络由于其模型与函数的复杂性,在面对当今复杂多变的语言模型时,可以捕捉更全面,更深层的文本特征,及对文本有更好的理解能力,故在情感分析领域也可以达到更好的效果,因此使用神经网络的方法成为主流方法。
现有的基于深度神经网络的情感分析的研究中,主要的工作是将文本通过神经网络的embedding层训练并表示成向量或矩阵的形式,然后构建合适的深度神经网络模型进行深层特征的抽象,最后在神经网络模型的输出层利用激活函数进行分类概率的计算。这类深度学习的方法仅仅是将文本内容转换成数字向量作为模型的输入,并未考虑到文本数据所在的领域特殊性,也没有充分的利用文本的层次结构去挖掘出文本的信息。
技术实现要素:
本发明的目的是为了克服现有方法模型的缺陷,针对缺乏对文本具体领域的关注和没有充分利用文档层次结构挖掘文档潜在信息的问题,提出一种新的基于lda主题模型和分层神经网络的情感分类方法,可以合理使用文档主题特征的同时,又充分学习到文档所包含的潜在信息,提高模型的泛化能力和情感分析的准确度。
本发明的核心思想是:充分利用文档的主题信息和层次结构,得到更有利于情感分类的文档向量表示。为符合文档的层次结构,使用分层的神经网络模型,在词汇层融入由lda主题模型提取出的主题信息,并在词汇和句子两层使用注意力机制提取文本不同位置,不同意义的词汇及句子的重要性,完成了主题信息的融入,也学习到了包含文档上下文的语义信息,时序信息及显著信息的文档向量。
鉴于此,本发明采用的技术方案是:基于lda主题模型与分层神经网络的情感分类方法,包括以下步骤:
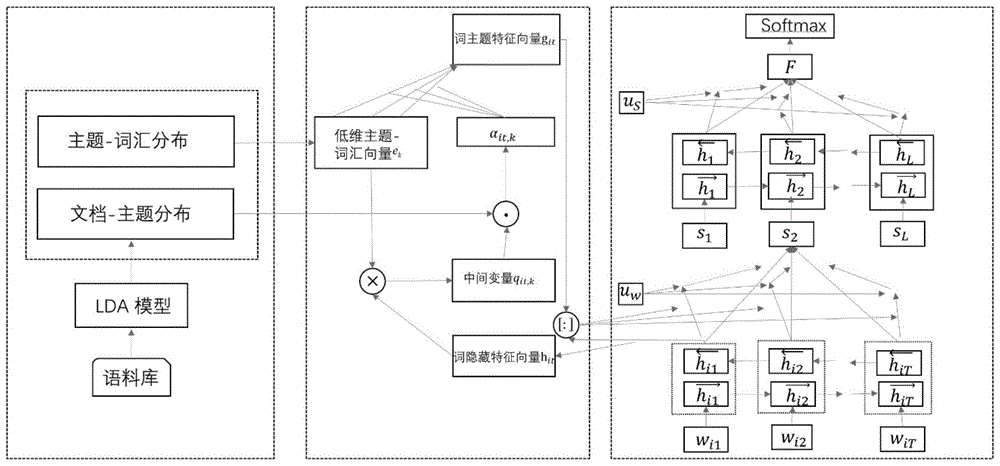
s1、将文档输入lda主题模型获得文档的文档-主题分布和主题-词分布;
s2、将文档以标点符号划分为句子,以句子为单位进行分词,并将句中的词汇表示为词向量,输入到双向循环神经网络中,获取词汇的隐藏状态向量;
s3、在词汇层面,获取词级别的主题特征向量,结合词汇的隐藏状态向量,使用注意力机制对句子中的词汇进行加权,形成句子的向量表示;
s4、在句子层面,将句子向量输入到双向循环神经网络中,获得句子的隐藏状态向量后,使用注意力机制对文档中的句子进行加权,获取文档的向量表示。
本发明具有以下有益效果:
1.本发明方法利用lda主题模型提取文档的主题信息,主题信息为θd和βk,在深度学习方法引入领域信息,在本文中具体表现为在词汇层面,获取词级别的主题特征向量,结合词汇的隐藏状态向量后,使用注意力机制对句子中的词汇进行加权,形成句子的向量表示,这样处理增强了模型在处理不同数据集时的泛化能力。
2.本发明方法使用的神经网络符合文档的层次结构,该神经网络共有两层,一层处理词汇合成句子向量表示,另一层处理句子合成词汇向量表示,这样能够充分挖掘文档的上下文信息和时序信息。
3.本发明方法在词汇层次和句子层次都使用了注意力机制,赋予不同位置和不同意义的词汇和句子不同的注意力权重αit和αi,能够充分利用文档的显著信息。
图说明
图1是本发明一种基于lda主题模型和分层神经网络的情感分析方法的流程图;
图2是本发明方法中lda主题模型的概率图模型示意图。
具体实施方式
为了使本发明的目的,技术方案及优点更加清楚明白,以下根据附图及实施例对本发明所述的分类方法进一步详细说明。
如图1所示,一种基于lda主题模型和分层神经网络的情感分析方法,其基本实施过程如下:
步骤s1、将文档输入lda主题模型获得文档的文档-主题分布θd和主题-词分布βk。
具体实现过程如下:
主题模型lda假设文档集中共有d篇文档,所有文档共有k个主题,v个词汇(不重复),在输入所有文档后,经过lda算法,会得到每篇文档分属这k个主题的概率分布θd和每个主题下v个词汇的概率分布βk。
lda的长文本主题挖掘能力强且是无监督模型,被认为不依赖训练样本,不存在领域转移问题,具有很好的领域适应性;lda模型为完全贝叶斯的概率图模型,参数的推理需要推断参数的后验分布,因此采用吉布斯采样算法估计模型参数,如图2为lda概率图模型示意图,刻画了整个长文本数据集的生成过程,详细过程阐述如下:
1)对于每一篇文档d=1,…,d:
采样一个文档-主题分布θd~dir(α)
2)对于每一个主题k=1,…,k:
采样一个主题-词汇分布βk~dir(η)
3)对于文中的每一个词w=1,…,v:
3.1)采样一个主题标签zdv~mult(θd)
3.2)在主题标签zdv的主题词汇分布下采样一个单词
其中mult(.)是多项式分布,dir(.)是dirichlet分布,θd是任一文档d的主题分布,α是分布的超参数,是一个k维向量。k代表主题个数;βk是任一主题k的词汇分布,η是分布的超参数,是一个v维向量。v代表数据集中所有文档中不重复的词的个数;文档-主题分布,主题-词汇分布是模型需要学习的参数,zdv是隐变量,表示数据中任一文档d中的第n个词,从主题分布θd中得到的主题编号zdv的分布,wdv是可观察到的变量。
步骤s2、将文档以句号,问号等标点符号划分为句子,以句子为单位进行分词,去停用词等预处理,并将句中的词汇表示为词向量,输入到双向循环神经网络中,获取词汇的隐藏状态向量。
具体实现过程如下:
步骤s2.1、将文档以句号,问号等标点符号划分为句子,d=(s1,…,si,…,sl);
步骤s2.2、以句子为单位进行分词,去停用词等预处理;
步骤s2.3、将句中的词汇表示为词向量,本发明利用google的开源word2vec工具将句中的词汇全部表示为词向量,si=(wi1,…,wit,…wit);
步骤s2.4、将句子的词向量,输入到双向循环神经网络中,获取词汇的隐藏状态向量;假设将文档的第i个句子的第t个单词的词向量wit,传入到双向gru,得到包含上下文信息的隐藏状态向量,其过程即如下表示:
其中,
步骤s3,在词汇层面,获取词级别的主题特征向量,结合词汇的隐藏状态向量后,使用注意力机制对句子中的词汇进行加权,形成句子的向量表示。
具体实现过程如下:
步骤s3.1、将lda主题模型提取出的主题-词分布通过全连接层转化成低维主题嵌入ekk∈[1,k],得到的ek具有与词汇隐藏状态向量相同的维数:
ek=tanh(wβk)
ek表示低维主题嵌入,βk表示主题-词汇分布,w是参数矩阵,tanh是非线性函数。
步骤s3.2、针对句中的每个词,计算出词与每个主题之间的关联权重:
qit,k=hit·ekt
αit,k=softmax(qit,k·θk)
qit,k是一个用于计算α的中间变量,直观上来看,qit,k是衡量词的隐藏向量与主题向量ek的匹配程度,从而在一定程度上反映了词与主题之间的相关性,为了包含更多的主题信息,所以引入θk,θk代表文档-主题分布里第k个主题的概率,hit表示词汇的隐藏状态向量,ek表示低维主题嵌入,αit,k代表第i个句子中第t个词汇和第k个主题之间的关联权重。
步骤s3.3、计算出词级别的主题特征向量:
git是第i个句子第t个词汇的词汇主题特征向量,αit,k是词与每个主题之间的关联权重,ek表示低维主题嵌入
步骤s3.4、结合词汇的隐藏状态向量,使用注意力机制对句子中的词汇进行加权,形成句子的向量表示:
hi't=[hit,git]
uit=tanh(wwhi't+bw)
hit表示第i个句子第t个词汇的隐藏状态向量,git表示第i个句子第t个词汇的主题特征向量,hi't表示将词汇的隐藏状态向量和主题特征向量进行特征融合形成的包含主题信息的词汇向量表示;uit是hi't通过单层感知机得到的隐藏的表示;αit是衡量该词汇在整个句子中的重要性权重;si是句子的向量表示;另外的参数ww,bw,uw为需要学习的模型参数。
步骤s4,在句子层面,将句子向量输入到双向循环神经网络中,获得句子的隐藏状态向量后,使用注意力机制对文档中的句子进行加权,获取文档的向量表示。
具体实现过程如下:
步骤s4.1、假设文档的第i个句子向量为si,i∈[1,l],l代表一篇文档总共为l个句子。传入到双向gru得到句子的隐藏状态向量hi:
步骤s4.2、使用注意力机制对文档中的句子进行加权,获取文档的向量表示v:
ui=tanh(wshi+bs)
hi表示第i个句子的隐藏状态向量;ui是hi通过单层感知机得到的隐藏的表示;αi是衡量该句子在整个文档中的重要性权重;f是文档的向量表示;另外的参数ws,bs,us为需要学习的模型参数。
步骤s5、使用大规模语料来训练基于lda主题模型与分层神经网络的情感分类模型。
首先,对大规模文本数据集进行预处理,包括中文分词,噪声处理等;
设置lda模型超参数,主题个数;dirichlet先验分布超参数α=50/topic,
然后通过上述模型的步骤,根据训练测试数据集的情感维度,假设数据集的情感维度是四,0代表高兴,1代表悲伤,2代表兴奋,3代表中立,不悲不喜,可以获得每篇文档的情感所属,假设文档的情感为高兴,则模型输出0;假设文档的情感为悲伤,则模型输出为1,其余同理可推。
- 还没有人留言评论。精彩留言会获得点赞!