基于云覆盖遥感影像和深度学习的作物识别方法和系统与流程
本发明涉及农业遥感技术领域,特别涉及一种基于云覆盖遥感影像和深度学习的作物识别方法和系统,适用于不同农田系统的农业遥感监测研究。
背景技术:
据联合国预测,到2050年世界人口将增至97亿,这对全球的粮食供应系统提出了巨大的挑战。农业遥感监测工作是保障国家粮食安全、农业资源可持续发展的重要手段;而作物类型图是农业遥感监测工作的重要组成部分,为作物生长监测、灾害评估、产量估计等提供基础数据。由于我国耕地破碎程度高、作物类型丰富、种植模式复杂,准确、高效地估计作物的面积和分布是一项艰巨的任务。
季节性是作物最突出的特征之一,每类作物的物候演变产生了独特的光谱反射率时间分布。因此,多时相遥感数据成为监测作物生长动态并对其进行分类的有效数据源。随着越来越多的卫星系统以前所未有的规模和速度生成高空分辨率的时间序列影像,如sentinel-2a/b、gaofen-1/6等,为农业监测工作提供新机遇的同时,对传统的作物分类方法提出了挑战:1)如何更充分地利用这些多光谱时间序列影像;2)针对海量的遥感数据,作物分类算法需具有高效性和可移植性。
目前,基于机器学习的作物识别方法,依赖于特征提取、数据融合等过程,增加了误差传递风险、忽略了时序数据的季节模式和顺序关系,这些都在一定程度上影像了作物识别的准确性。与经典机器学习方法相比,深度学习方法允许机器获取原始数据(例如原始图像的像素值)并自动发现手动模型无法表达的多级别特征。其中,递归神经网络(rnn)和一维卷积神经网络(1dcnn)具有提取长时间序列时域特征的能力。rnn通过循环连接为序列的每个元素执行相同的任务,每个输出值取决于先前的计算;长短期记忆(lstm)rnn是rnn的变体,具有复杂的循环单位(lstm),用于解决随着时间序列增加而出现的梯度消失或爆炸的问题。而1dcnn通过一维卷积核提取时间序列的特征信息。
尽管以上模型已被应用于作物制图领域,但这些工作主要使用无间隙的规则时间序列影像,例如微波数据、基于缺失值重建的光学数据(或植被指数)。此外,大多数高精度遥感影像缺失值重建的方法都很耗时;这些方法分别建立数据修复模型和作物分类模型,不仅操作复杂,而且结果具有一定的不确定性。实际上,深度学习算法在光学时间序列数据中的潜力尚未得到很好的探索。一方面,在早期的工作中已有研究探索了rnn在含缺失值序列数据中的应用,并将其用于语音识别和血糖预测;cnn模型已被证明能够通过卷积核对具有丢失信息的图像进行分类。另一方面,现有的卫星系统具有高频率采集数据的能力,更有利于作物类型特征的提取。
技术实现要素:
本发明针对现有技术的不足提供一种基于云覆盖遥感影像和深度学习的作物识别方法和系统。
本发明采用以下技术方案:
一种基于云覆盖遥感影像和深度学习的作物识别方法,包括以下步骤:
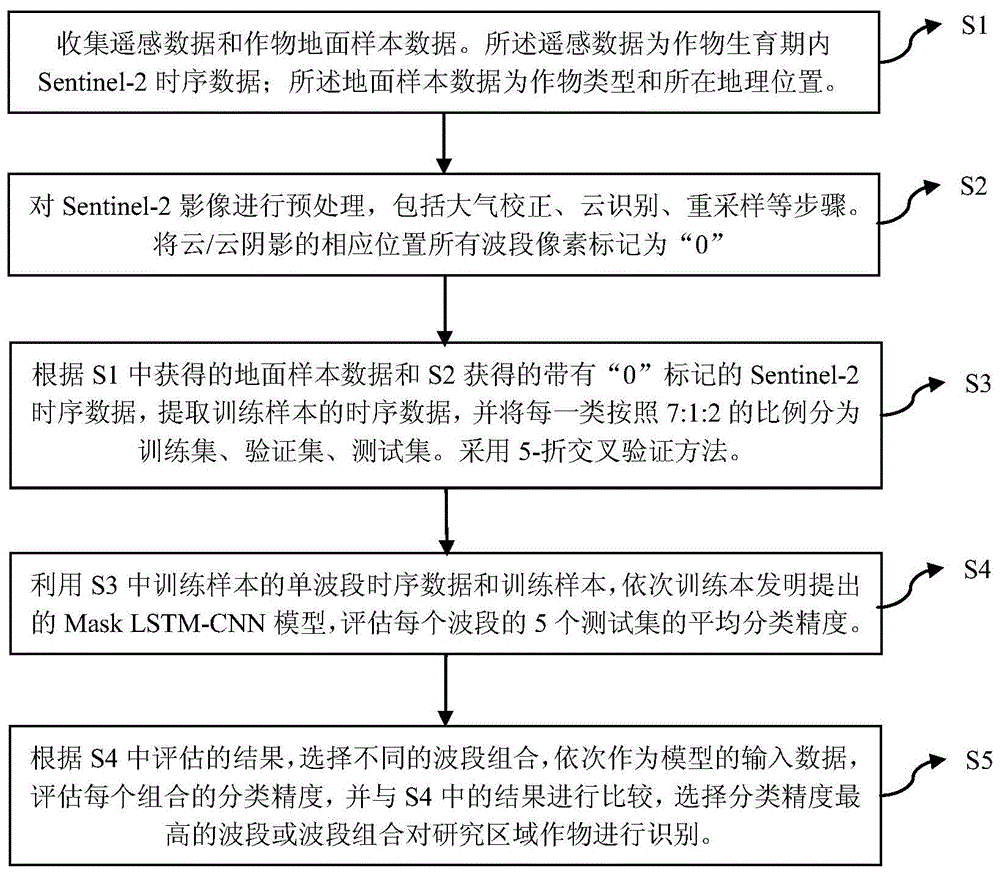
s1,收集遥感数据和作物地面样本数据;所述遥感数据为作物生育期内sentinel-2时序数据;
s2,对sentinel-2影像进行预处理;
s3,训练样本提取;
s3-1,根据s1中获得的地面样本数据和s2获得的带有“0”标记的sentinel-2时序数据,提取训练样本的时序数据;
s3-2,采用l2-范数对样本进行通道归一化,所述通道为一个日期中sentinel-2的一个波段;如果所有样本在一个通道上的记录为x=(x1,x2,…,xn),通道的归一化如公式(1)所示:
||x||2=(|x1|2+|x2|2+…+|xn|2)1/2(1)
式中,n为样本的个数,xn为第n个样本的反射率,x为归一化向量;
s3-3,采用5-折交叉验证方法;由于每一类作物的样本量不同,为获取样本的无偏估计,在每一折交叉验证中,将每一类样本按照7:1:2的比例随机分为训练集、验证集和测试集,共得到5个训练集、验证集和测试集,分类结果取5个测试集的平均值;
s4,单波段评估;利用s3中单波段的5个训练集、验证集和测试集依次训练masklstm-cnn模型,测试精度为5个测试集的平均值,最后比较每个波段的分类精度;
采用整体分类精度oa和kappa系数来对作物的整体分类精度进行评价;同时还利用生产精度aprod和用户精度auser的调和平均值f1来评价每类作物的精度;
式中,n为测试集样本的个数,r为作物类别数,xii为预测标签和真实标签都为第i类的数量,xi+为真实标签为第i类的数量,x+i为为预测标签为第i类的数量;
s5,根据s4中评价的结果,根据oa由大到小的排序依次选择不同的波段组合,当两个波段的oa值相同时,选取kappa值较大的波段;将不同的波段组合依次作为masklstm-cnn模型的输入数据,评估每个组合的5-折交叉验证的平均分类精度,并与s4中的结果进行比较,选择分类精度最高的波段或波段组合对研究区域作物进行识别;根据每类作物的精度f1值,当对某一类作物进行识别时,可选取该作物f1值最高的波段或波段组合进行识别。
所述的作物识别方法,步骤(1)中,所述遥感数据为作物生育期内sentinel-2时序数据,包含level-1c级产品中可见光b2~b4、红边b5~b7、近红外b8/b8a、短波红外b11/b12共计10个波段光谱数据。
所述的作物识别方法,步骤(1)中,所述地面样本数据为作物类型和所在地理位置。
所述的作物识别方法,步骤(2)中,包括大气校正、云识别、重采样步骤;所述大气校正采用sen2cor工具。
所述的作物识别方法,步骤(2)中,所述云识别采用fmask4.0算法识别影像中的云/云阴影像素,并将相应位置所有波段像素标记为“0”。
所述的作物识别方法,步骤(2)中,所述重采样指将空间分辨率为20m的b5~b7、b8a、b11、b12影像重采样到10m。
所述的作物识别方法,所述masklstm-cnn模型包含两部分:masklstm模块和cnn模块;
(1)masklstm模块利用掩膜机制mask对“0”标记的元素进行过滤;设x=(x1,x2,...,xt),式中,t作物生长季内sentinel-2数据获取的次数,
(2)cnn模块利用卷积核计算对“0”标记的元素进行过滤
一个基本的卷积模块由卷积层conv和线性单元层relu组成;假设每一个波段输入数据为x0,第一层卷积核的长度为k,那么第一层时间点t的输出值为
一种基于云覆盖遥感影像和深度学习的作物识别系统,包括以下模块:
s1,遥感数据和作物地面样本数据收集模块;所述遥感数据为作物生育期内sentinel-2时序数据;
s2,sentinel-2影像预处理模块;
s3,训练样本提取模块,训练样本提取模块功能为:
s3-1,根据s1中获得的地面样本数据和s2获得的带有“0”标记的sentinel-2时序数据,提取训练样本的时序数据;
s3-2,采用l2-范数对样本进行通道归一化,所述通道为一个日期中sentinel-2的一个波段;如果所有样本在一个通道上的记录为x=(x1,x2,…,xn),通道的归一化如公式(1)所示:
||x||2=(|x1|2+|x2|2+…+|xn|2)1/2(1)
式中,n为样本的个数,xn为第n个样本的反射率,x为归一化向量;
s3-3,采用5-折交叉验证方法;由于每一类作物的样本量不同,为获取样本的无偏估计,在每一折交叉验证中,将每一类样本按照7:1:2的比例随机分为训练集、验证集和测试集,共得到5个训练集、验证集和测试集,分类结果取5个测试集的平均值;
s4,单波段评估模块;利用s3中单波段的5个训练集、验证集和测试集依次训练masklstm-cnn模型,测试精度为5个测试集的平均值,最后比较每个波段的分类精度;
采用整体分类精度oa和kappa系数来对作物的整体分类精度进行评价;同时还利用生产精度aprod和用户精度auser的调和平均值f1来评价每类作物的精度;
式中,n为测试集样本的个数,r为作物类别数,xii为预测标签和真实标签都为第i类的数量,xi+为真实标签为第i类的数量,x+i为为预测标签为第i类的数量。
s5,根据s4中评价的结果,根据oa由大到小的排序依次选择不同的波段组合,当两个波段的oa值相同时,选取kappa值较大的波段;将不同的波段或波段组合依次作为masklstm-cnn模型的输入数据,评估每个波段或波段组合的5-折交叉验证的平均分类精度,并与s4中的结果进行比较,选择分类精度最高的波段或波段组合对研究区域作物进行识别;当对某一类作物进行识别时,可选取该作物f1值最高的波段或波段组合进行识别。
所述的作物识别系统,遥感数据和作物地面样本数据收集模块中,所述遥感数据为作物生育期内sentinel-2时序数据,包含level-1c级产品中可见光b2~b4、红边b5~b7、近红外b8/b8a、短波红外b11/b12共计10个波段光谱数据。
所述的的作物识别系统,遥感数据和作物地面样本数据收集模块中,所述地面样本数据为作物类型和所在地理位置。
有益效果
1、本发明解决了含有缺失值的时间序列影像的作物识别,避免了遥感数据的云处理操作和误差传递的风险,提高了作物识别的效率。
2、本发明利用深度学习技术,具有“端到端”学习的优势,避免了对专家知识的依赖和传统作物分类系统的复杂性。
3、本发明可对时间密集型、高空间分辨率、多光谱遥感数据的特征进行有效提取,可为我国新型的智能化农业遥感监测提供技术支持。
附图说明
图1为本发明的方法流程图;
图2为本发明具体实施的作物类型和样本分布;
图3为本发明实例中所有样本中未被云/云阴影遮蔽的比例;
图4为本发明提出的模型masklstm-cnn;
图5为本发明masklstm模块的掩膜机制示意图;
图6为本发明实例中每个波段的分类精度;
图7为本发明实例中不同波段组合方案;
图8为本发明实例中不同波段组合方案的分类精度;
图9为本发明实例中不同波段及波段组合整体分类精度对比,a图为单波段,b图为波段组合;
具体实施方式
以下结合附图和具体实施方式对本发明作进一步详细的说明。
基于不规则时序遥感影像和深度学习的作物识别的主要流程为:
s1,收集遥感数据和作物地面样本数据。
通过野外调查获取地面样本数据,具体方法是:首先规划野外调查路线;然后根据调查路线采集不同农田地块的作物类型,并使用gps记录相应地理坐标;最后对采集数据进行室内处理形成地面样本数据(见图2)。地面数据结构为{地面样本编号:3,经度坐标:116.098,纬度坐标:37.390,作物类型:夏玉米,作物类型标签:1}。
本发明收集的遥感数据为作物生育期内sentinel-2时序数据,包含level-1c级产品中可见光(b2~b4)、红边(b5~b7)、近红外(b8/b8a)、短波红外(b11/b12)共计10个波段;时间覆盖范围为:2019年4月1日至2019年9月30日;时序长度为37,时序中每个时间点用doy(dayofyear)表示,例如4月8日,相应的doy为98。
s2,对sentinel-2影像进行预处理。
建立大气校正、云识别、重采样批量处理程序。其中,大气校正算法采用sen2cor工具;云识别采用fmask4.0算法,参数“cloudprobabilitythreshold”为50%;重采样采用双线性二次插值方法。将的云/云阴影像素相应位置的其他波段像素标记为“0”;将空间分辨率为20m的b5~b7、b8a、b11、b12影像重采样到10m。
s3,训练样本提取,包括以下步骤:
s3-1,根据s1中获得的地面样本数据和s2获得的带有“0”标记的sentinel-2时序数据,提取训练样本的时序数据,例如,当一个样本在2019年4月8日(sentinel-2数据获取时间)被云/云阴影覆盖,那么该样本在这个时间的sentinel-2的b2~b8a以及b11和b12的记录为“0”。最终获得的样本没有被云/云阴影覆盖的比例如图3所示。
s3-2,采用l2-范数对样本进行通道归一化,所述通道为一个日期中sentinel-2的一个波段。如果所有样本在一个通道上的记录为x=(x1,x2,…,xn),通道的归一化如公式(1)所示:
||x||2=(|x1|2+|x2|2+…+|xn|2)1/2(1)
式中,n为样本的个数,xn为第n个样本的反射率,x为归一化向量。
s3-3,为避免数据随机分组的偏差,本发明采用5-折交叉验证方法;由于每一类作物的样本量不同,为获取样本的无偏估计,本发明在每一折交叉验证中,将每一类样本按照7:1:2的比例随机分为训练集、验证集和测试集共得到5个训练集、验证集和测试集,分类结果取5个测试集的平均值。
s4,单波段评估。本发明涉及蓝光(b2)绿光(b3)红光(b4)红边1(b5)红边2(b6)红边3(b7)近红外1(b8)近红外2(b8a)短波红外1(b11)短波红外2(b12)共计10个波段。每个波段的时间序列长度为37,相应的doy从93~273,时间间隔为5天。利用s3中单波段的5个训练集、验证集和测试集依次训练本发明提出的masklstm-cnn模型(参照图4),测试精度为5个测试集的平均值。最后比较每个波段的分类精度。所述模型包含两部分:masklstm模块和cnn模块。
(1)masklstm模块利用掩膜机制(mask)对“0”标记的元素进行过滤。设x=(x1,x2,...,xt),式中,t=37,
(2)cnn利用卷积核计算对“0”标记的元素进行过滤。
卷积操作实际上是卷积核和局部输入之间的点积。一个基本的卷积模块总是由卷积层(conv)和线性单元层(relu)组成。假设每一个波段输入数据为x0,第一层卷积核的长度为k,那么第一层时间点t的输出值为
本发明采用体分类精度(oa)和kappa系数(kappa)来对作物的整体分类精度进行评价;同时,利用生产精度(productaccuracy,aprod)和用户精度(useraccuracy,auser)的调和平均值(f1,公式(10))来评价每类作物的精度。
s5,根据s4中评估的结果(参照图6),根据oa由大到小的排序依次选择不同的波段组合(参照图7)作为masklstm-cnn模型的输入数据,当两个波段的oa值相同时,选取kappa值较大的波段作为masklstm-cnn模型的输入数据,评估每个组合5-折交叉验证的平均分类精度(参照图8),并与s4中的结果进行比较,选择分类精度最高的波段组合(com7)对研究区域作物进行识别;此外,根据本发明计算的每类作物的f1值,当对某一类作物进行识别时,可选取该作物f1值最高的波段(或组合)。
在河北省衡水市就本发明提出的方法进行了实验,针对实验的7个类别,结果表明(如图9所示,a图为单波段,b图为波段组合)波段组合com7(近红外2,蓝光,红边1,短波红外1,红光,红边2,绿光)分类精度最高。整体分类精度为0.8657,kappa系数为0.8218。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!