一种检测Kafka集群中Leader进程的可用状态方法及装置与流程
本发明涉及数据处理技术领域,特别是涉及一种检测kafka集群中leader进程的可用状态方法及装置。
背景技术:
kafka集群是由apache软件基金会开发的开源流处理平台,即是高吞吐量的分布式发布订阅消息系统,通过hadoop的并行加载机制统一线上和离线的消息处理,处理用户在网站中的网页浏览、搜索和访问等所有动作的数据消息。
leader是kafka集群中一台服务器上运行的进程,负责读写数据。如果leader进程出现宕机情况,kafka则通过zookeeper进程自动选举出新的leader进程。如果leader进程显示状态正常,可以正常的写入和读取数据,则说明leader进程处于可用状态,如果leader进程显示进程正常运行,却不能写入和读取数据,则说明leader进程处于不可用状态。如果leader进程显示状态正常,没有出现宕机情况,只是存储数据的数据磁盘出现问题,而kafka集群本身无法检测因数据磁盘问题引起的功能不可用,使得kafka集群无法正常提供服务。
技术实现要素:
有鉴于此,本发明提供一种检测kafka集群中leader进程的可用状态方法及装置,主要目的在于解决现有技术中kafka集群本身无法检测因数据磁盘问题引起的功能不可用的问题。
依据本发明一个方面,提供了一种检测kafka集群中leader进程的可用状态方法,包括:
根据预置检测方法,监控数据磁盘的读写状态;
如果所述读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息;
如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息;
如果查找结果为是,或者捕获所述第二预置异常状态信息,则生成所述leader进程的不可用状态告警信息,以便于运维人员对所述kafka集群进行维护。
依据本发明另一个方面,提供了一种检测kafka集群中leader进程的可用状态装置,包括:
监控模块,用于根据预置检测装置,监控数据磁盘的读写状态;
查找模块,用于如果所述读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息;
捕获模块,用于如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息;
生成模块,用于如果查找结果为是,或者捕获所述第二预置异常状态信息,则生成所述leader进程的不可用状态告警信息,以便于运维人员对所述kafka集群进行维护。
根据本发明的又一方面,提供了一种计算机存储介质,所述计算机存储介质中存储有至少一种可执行指令,所述可执行指令使处理器执行如上述检测kafka集群中leader进程的可用状态方法对应的操作。
根据本发明的再一方面,提供了一种计算机设备,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
所述存储器用于存放至少一种可执行指令,所述可执行指令使所述处理器执行上述检测kafka集群中leader进程的可用状态方法对应的操作。
借由上述技术方案,本发明实施例提供的技术方案至少具有下列优点:
本发明提供了一种检测kafka集群中leader进程的可用状态方法及装置,首先根据预置检测方法,监控数据磁盘的读写状态,如果读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息,如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息,如果查找结果为是,或者捕获第二预置异常状态信息,则生成leader进程的不可用状态告警信息,以便于运维人员对kafka集群进行维护。与现有技术相比,本发明实施例通过独立运行的kafka集群插入检测kafka集群中leader进程的可用状态的方法,在不影响现有kafka集群运行的前提下,如果leader进程处于不可用状态,可以通过查找kafka集群日志中的异常状态信息,或者在磁盘测试程序运行是捕获异常状态信息,进而确定提前发现leader进程的不可用状态,以使得运维人员可以尽早开始维护kafka集群,保障kafka集群的正常运行。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1示出了本发明实施例提供的一种检测kafka集群中leader进程的可用状态方法流程图;
图2示出了本发明实施例提供的另一种检测kafka集群中leader进程的可用状态方法流程图;
图3示出了本发明实施例提供的一种检测kafka集群中leader进程的可用状态装置组成框图;
图4示出了本发明实施例提供的另一种检测kafka集群中leader进程的可用状态装置组成框图;
图5示出了本发明实施例提供的一种计算机设备的结构示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
在kafka集群的运行机制中没有对磁盘功能的验证,并且内部的组件相对固定,修改固定组件而达到检测可用状态的目的比较繁琐,不利于方案的推广与实施。故而,本发明实施例提供了一种检测kafka集群中leader进程的可用状态方法,如图1所示,该方法包括:
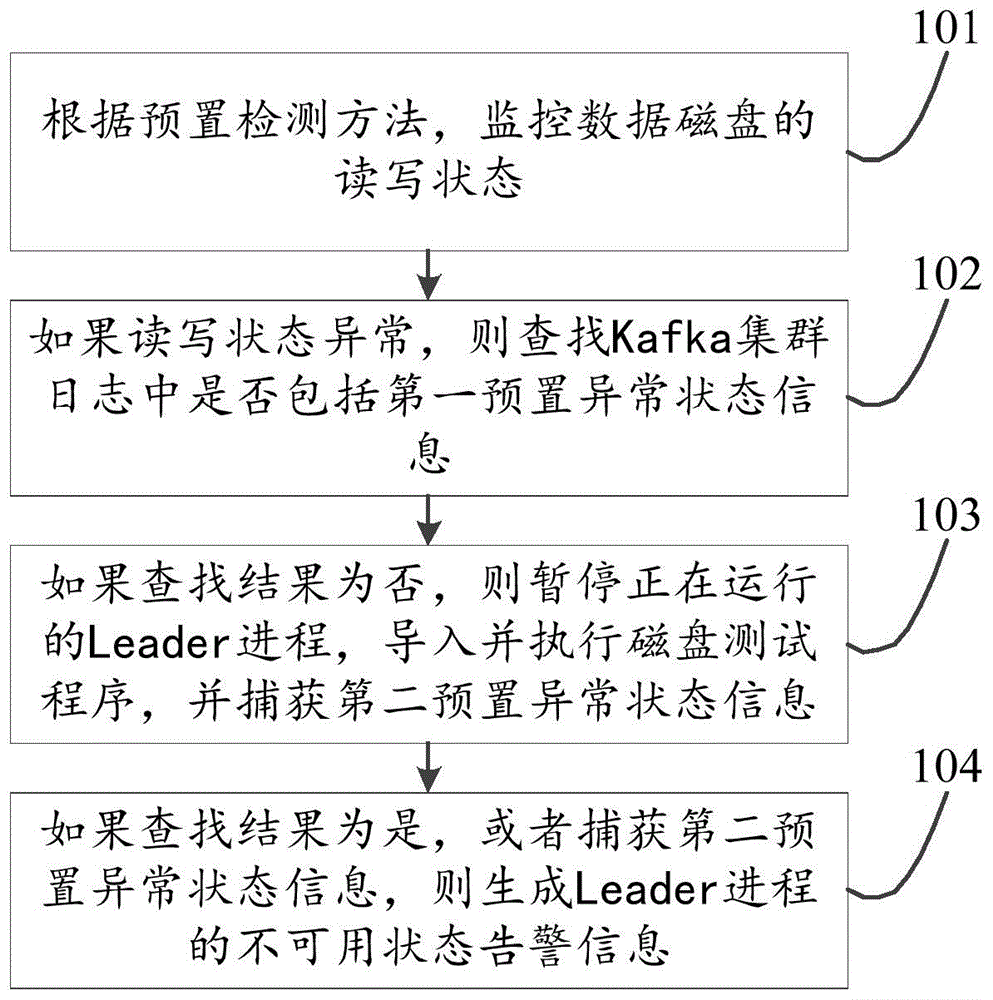
101、根据预置检测方法,监控数据磁盘的读写状态。
数据磁盘用于存储kafka集群在运行过程中所需的存储空间。只有在磁盘能够正常运行的前提下,kafka集群才能正常运行。监控数据磁盘也就是监控数据磁盘的读写状态。在监控过程中可采用的预置检测方法包括:hdparm命令、dd命令或zabbix监控。
102、如果读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息。
读写状态异常是指数据磁盘不能进行读操作、写操作或者读写的速度较慢。一旦监控到磁盘的读写状态异常,则获取kafka集群的日志,并查找kafka集群日志在是否包括第一预置异常状态信息。第一预置异常信息可以为kafka.common.notleaderforpartitionexception。
103、如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息。
磁盘测试程序,可以是向磁盘写入一条测试数据,也可以是从磁盘读出一条存储数据。由于磁盘出现异常,正在运行的leader进程不能有任何实质的数据处理进展,所以暂停正在运行的leader进程。导入并执行磁盘测试程序,以进一步检测,磁盘异常状态产生的原因。第二预置异常状态信息是指在执行磁盘测试程序过程中产生的任意异常状态信息。在捕获第二预置异常状态信息时,可采用catch语句进行捕获操作。在执行磁盘测试程序中,可以采用createandvalidatelogdirs方法中校验程序是否成功执行。
104、如果查找结果为是,或者捕获第二预置异常状态信息,则生成leader进程的不可用状态告警信息。
如果查找到第一预置异常状态信息,或者捕获第二异常状态信息,则认为leader进程处于不可用状态,生成不可用状态告警信息,以便于运维人员对kafka集群进行维护。
如果未查找到第一预置异常状态信息,并且未捕获第二异常状态信息,则说明该磁盘的读写状态异常,可能是由于kafka集群本身的问题导致的。
本发明提供了一种检测kafka集群中leader进程的可用状态方法,首先根据预置检测方法,监控数据磁盘的读写状态,如果读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息,如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息,如果查找结果为是,或者捕获第二预置异常状态信息,则生成leader进程的不可用状态告警信息,以便于运维人员对kafka集群进行维护。与现有技术相比,本发明实施例通过独立运行的kafka集群插入检测kafka集群中leader进程的可用状态的方法,在不影响现有kafka集群运行的前提下,如果leader进程处于不可用状态,可以通过查找kafka集群日志中的异常状态信息,或者在磁盘测试程序运行是捕获异常状态信息,进而确定提前发现leader进程的不可用状态,以使得运维人员可以尽早开始维护kafka集群,保障kafka集群的正常运行。
本发明实施例提供了另一种检测kafka集群中leader进程的可用状态方法,如图2所示,该方法包括:
201、根据预置检测方法,监控数据磁盘的读写状态。
数据磁盘用于存储kafka集群在运行过程中所需的存储空间。只有在磁盘能够正常运行的前提下,kafka集群才能正常运行。监控数据磁盘也就是监控数据磁盘的读写状态。在监控过程中可采用的预置检测方法包括:hdparm命令、dd命令或zabbix监控。
如果采用zabbix监控方式监控数据磁盘,则具体包括:加载磁盘监控的配置文件;根据预置监控参数,配置所述读写状态的监控项,所述监控项包括读操作耗时、写操作耗时和i/o操作耗时;根据所述监控参数和所述配置文件,监控所述数据磁盘的磁盘地址。
在数据磁盘正常读写操作,其读操作耗时、写操作耗时和i/o操作耗时都具有固定的可容忍耗时范围,当监控的磁盘地址的监控项耗时超过可容易耗时范围时,则判断数据磁盘的读写状态异常。可容忍耗时范围记录在预置监控参数中。
202、如果读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息。
读写状态异常是指数据磁盘不能进行读操作、写操作或者读写的速度较慢。一旦监控到磁盘的读写状态异常,则获取kafka集群的日志,并查找kafka集群日志在是否包括第一预置异常状态信息。第一预置异常信息可以为kafka.common.notleaderforpartitionexception。
查找具体过程可以包括:根据预置日志存储路径,获取kafka集群日志中的文本信息,所述kafka集群日志是指根据预置存储空间或者预置时间间隔动态更新的部分集群日志;通过文本编辑器vim,查找所述文本信息中是否包括所述第一预置异常状态信息。按照预置存储空间动态更新,是指当kafka集群日志中存储的日志信息所占用的存储空间大于预置存储空间后,重新生成kafka集群日志文件保存新的日志信息,也就是当前kafka集群日志中,最多保留日志信息所摘要的存储空间小于等于预置存储空间。按照预置时间间隔动态更新,是指当kafka集群日志中存储的日志信息,按照日志生成的时间顺序存储,当日志信息的记录时间达到预置时间间隔,则重新生成kafka集群日志文件保存新的日志信息,也就是当前kafka集群日志中,最多保留预置时间间隔时长范围内的日志信息。
查找具体过程还可以包括:通过轻量型日志采集器filebeat获取所述kafka集群日志;根据搜索服务器elasticsearch查找所述kafka集群日志中是否包括所述第一预置异常状态信息。在查找过程中,也可以借助现有的日志采集和搜索程序查找kafka集群日志中是否包括所述第一预置异常状态信息。
203、如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息。
磁盘测试程序,可以是向磁盘写入一条测试数据,也可以是从磁盘读出一条存储数据。由于磁盘出现异常,正在运行的leader进程不能有任何实质的数据处理进展,所以暂停正在运行的leader进程。导入并执行磁盘测试程序,以进一步检测,磁盘异常状态产生的原因。第二预置异常状态信息是指在执行磁盘测试程序过程中产生的任意异常状态信息。在捕获第二预置异常状态信息时,可采用catch语句进行捕获操作。在执行磁盘测试程序中,可以采用createandvalidatelogdirs方法中校验程序是否成功执行。
204、如果查找结果为是,或者捕获第二预置异常状态信息,则生成leader进程的不可用状态告警信息。
如果查找到第一预置异常状态信息,或者捕获第二异常状态信息,则认为leader进程处于不可用状态,生成不可用状态告警信息,以便于运维人员对kafka集群进行维护。如果未查找到第一预置异常状态信息,并且未捕获第二异常状态信息,则说明该磁盘的读写状态异常,可能是由于kafka集群本身的问题导致的。
205a、将不可用状态告警信息,发送至leader进程的运行状态显示终端。
通过运行状态显示终端,不断地重复地显示不可用状态告警信息,已提示运维人员对kafka集群进行维护。
205b将不可用状态告警信息,发送至手持终端通信地址。
随着远程控制技术的不断发展,通过远程监控、远控控制、远程解决问题的方式越来越普遍。为了解决运维人员不会实时观察运行状态显示终端而导致的发现不可用状态告警信息滞后的问题,可以将不可用状态告警信息,发送至手持终端通信地址。其中,手持终端通信地址包括但不限于邮箱、微信账号和qq账号。通过手持终端通信地址,以使得运维人员能够即时接收到leader进程的运行状态,以便kafka集群的运行故障能够被及时处理。
本发明提供了一种检测kafka集群中leader进程的可用状态方法,首先根据预置检测方法,监控数据磁盘的读写状态,如果读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息,如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息,如果查找结果为是,或者捕获第二预置异常状态信息,则生成leader进程的不可用状态告警信息,以便于运维人员对kafka集群进行维护。与现有技术相比,本发明实施例通过独立运行的kafka集群插入检测kafka集群中leader进程的可用状态的方法,在不影响现有kafka集群运行的前提下,如果leader进程处于不可用状态,可以通过查找kafka集群日志中的异常状态信息,或者在磁盘测试程序运行是捕获异常状态信息,进而确定提前发现leader进程的不可用状态,以使得运维人员可以尽早开始维护kafka集群,保障kafka集群的正常运行。
进一步的,作为对上述图1所示方法的实现,本发明实施例提供了一种检测kafka集群中leader进程的可用状态装置,如图3所示,该装置包括:
监控模块31,用于根据预置检测装置,监控数据磁盘的读写状态;
查找模块32,用于如果所述读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息;
捕获模块33,用于如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息;
生成模块34,用于如果查找结果为是,或者捕获所述第二预置异常状态信息,则生成所述leader进程的不可用状态告警信息,以便于运维人员对所述kafka集群进行维护。
本发明提供了一种检测kafka集群中leader进程的可用状态装置,首先根据预置检测方法,监控数据磁盘的读写状态,如果读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息,如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息,如果查找结果为是,或者捕获第二预置异常状态信息,则生成leader进程的不可用状态告警信息,以便于运维人员对kafka集群进行维护。与现有技术相比,本发明实施例通过独立运行的kafka集群插入检测kafka集群中leader进程的可用状态的方法,在不影响现有kafka集群运行的前提下,如果leader进程处于不可用状态,可以通过查找kafka集群日志中的异常状态信息,或者在磁盘测试程序运行是捕获异常状态信息,进而确定提前发现leader进程的不可用状态,以使得运维人员可以尽早开始维护kafka集群,保障kafka集群的正常运行。
进一步的,作为对上述图2所示方法的实现,本发明实施例提供了另一种检测kafka集群中leader进程的可用状态装置,如图4所示,该装置包括:
监控模块41,用于根据预置检测装置,监控数据磁盘的读写状态;
查找模块42,用于如果所述读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息;
捕获模块43,用于如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息;
生成模块44,用于如果查找结果为是,或者捕获所述第二预置异常状态信息,则生成所述leader进程的不可用状态告警信息,以便于运维人员对所述kafka集群进行维护。
进一步地,所述监控模块41,包括:
加载单元411,用于加载磁盘监控的配置文件;
配置单元412,用于根据预置监控参数,配置所述读写状态的监控项,所述监控项包括读操作耗时、写操作耗时和i/o操作耗时;
监控单元413,用于根据所述监控参数和所述配置文件,监控所述数据磁盘的磁盘地址。
进一步地,所述查找模块42,包括:
获取单元421,用于根据预置日志存储路径,获取kafka集群日志中的文本信息,所述kafka集群日志是指根据预置存储空间或者预置时间间隔动态更新的部分集群日志;
查找单元422,用于通过文本编辑器vim,查找所述文本信息中是否包括所述第一预置异常状态信息。
进一步地,所述查找模块42,包括:
所述获取单元421,还用于通过轻量型日志采集器filebeat获取所述kafka集群日志;
所述查找单元422,还用于根据搜索服务器elasticsearch查找所述kafka集群日志中是否包括所述第一预置异常状态信息。
进一步地,所述装置还包括:
发送模块45,用于所述生成所述leader进程的不可用状态告警信息之后,将所述不可用状态告警信息,发送至所述leader进程的运行状态显示终端;和/或,
所述发送模块45,还用于所述生成所述leader进程的不可用状态告警信息之后,将所述不可用状态告警信息,发送至手持终端通信地址,所述手持终端通信地址包括邮箱、微信账号和qq账号。
本发明提供了一种检测kafka集群中leader进程的可用状态装置,首先根据预置检测方法,监控数据磁盘的读写状态,如果读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息,如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息,如果查找结果为是,或者捕获第二预置异常状态信息,则生成leader进程的不可用状态告警信息,以便于运维人员对kafka集群进行维护。与现有技术相比,本发明实施例通过独立运行的kafka集群插入检测kafka集群中leader进程的可用状态的方法,在不影响现有kafka集群运行的前提下,如果leader进程处于不可用状态,可以通过查找kafka集群日志中的异常状态信息,或者在磁盘测试程序运行是捕获异常状态信息,进而确定提前发现leader进程的不可用状态,以使得运维人员可以尽早开始维护kafka集群,保障kafka集群的正常运行。
根据本发明一个实施例提供了一种计算机存储介质,所述计算机存储介质存储有至少一可执行指令,该计算机可执行指令可执行上述任意方法实施例中的检测kafka集群中leader进程的可用状态方法。
图5示出了根据本发明一个实施例提供的一种计算机设备的结构示意图,本发明具体实施例并不对计算机设备的具体实现做限定。
如图5所示,该计算机设备可以包括:处理器(processor)502、通信接口(communicationsinterface)504、存储器(memory)506、以及通信总线508。
其中:处理器502、通信接口504、以及存储器506通过通信总线508完成相互间的通信。
通信接口504,用于与其它设备比如客户端或其它服务器等的网元通信。
处理器502,用于执行程序510,具体可以执行上述检测kafka集群中leader进程的可用状态方法实施例中的相关步骤。
具体地,程序510可以包括程序代码,该程序代码包括计算机操作指令。
处理器502可能是中央处理器cpu,或者是特定集成电路asic(applicationspecificintegratedcircuit),或者是被配置成实施本发明实施例的一个或多个集成电路。计算机设备包括的一个或多个处理器,可以是同一类型的处理器,如一个或多个cpu;也可以是不同类型的处理器,如一个或多个cpu以及一个或多个asic。
存储器506,用于存放程序510。存储器506可能包含高速ram存储器,也可能还包括非易失性存储器(non-volatilememory),例如至少一个磁盘存储器。
程序510具体可以用于使得处理器502执行以下操作:
根据预置检测方法,监控数据磁盘的读写状态;
如果所述读写状态异常,则查找kafka集群日志中是否包括第一预置异常状态信息;
如果查找结果为否,则暂停正在运行的leader进程,导入并执行磁盘测试程序,并捕获第二预置异常状态信息;
如果查找结果为是,或者捕获所述第二预置异常状态信息,则生成所述leader进程的不可用状态告警信息,以便于运维人员对所述kafka集群进行维护。
显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!