一种Spark分区负载均衡方法与流程
本发明涉及大数据技术领域,尤其涉及一种spark分区负载均衡方法。
背景技术:
随着大数据时代的到来,各种网络技术的兴起,信息数据急剧膨胀,传统的处理和存储系统已难以应对海量数据,而对于目前流行的hadoop和spark等大数据分析平台,数据倾斜对其性能造成了严重的影响。目前解决数据倾斜问题大部分都是基于hadoop平台研究,对于spark平台的数据倾斜问题研究相对较少。在spark中,将shuffle之前的阶段称为map阶段,之后的阶段称为reduce阶段。然而,默认的spark分区算法在数据分布不均匀时,在执行shuffle操作后就会出现数据倾斜。现存的对数据倾斜的解决方案都是通过增加额外的抽样操作来分析并统计中间<key,value>对信息,然后再对reduce任务的负载进行预测,该类型的方法在一定程度上能够缓解数据倾斜的问题,但会造成开销过大,增加spark平台的运行时间、浪费集群的资源的问题。因此,如何既能够使spark的分区负载更均衡,缓解数据倾斜的问题,又能够缩短应用程序完成的时间,是亟需解决对的技术问题。
技术实现要素:
本发明实施例提供了一种基于线性回归分区预测的负载均衡方法及装置,以解决在spark中,现有的对数据倾斜的解决方案导致应用程序运行时间过长的技术问题,以实现既能够使spark的分区负载更均衡,缓解数据倾斜的问题,又能够缩短应用程序完成的时间。
本发明实施例提供一种spark分区负载均衡方法,包括
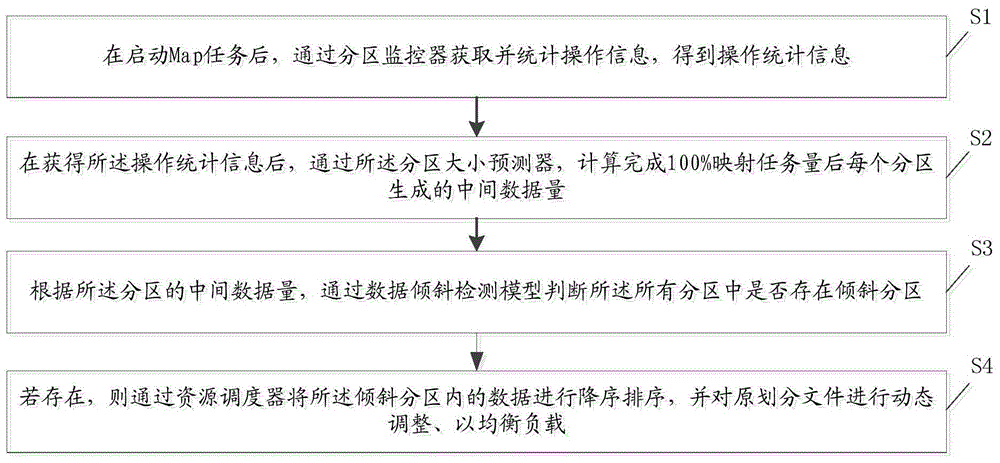
在启动map任务后,通过分区监控器获取并统计操作信息,得到操作统计信息;
在获得所述操作统计信息后,通过所述分区大小预测器,计算完成100%映射任务量后每个分区生成的中间数据量;
根据所述分区的中间数据量,通过数据倾斜检测模型判断所述所有分区中是否存在倾斜分区;
若存在,则通过资源调度器将所述倾斜分区内的数据进行降序排序,并对原划分文件进行动态调整、以均衡spark分区负载。
优选地,所述在启动map任务后,通过分区监控器获取操作信息,具体为:
worker向master发送心跳消息,当master收到worker心跳信息时,分别获取每一个reduce任务的操作信息;所述操作信息包括:已处理数据占总数据集的百分比和已完成的map任务为所述reduce任务所产生的子分区的总和;其中,已处理数据占总数据集的百分比随着spark应用程序的运行而变化。
优选地,所述在获得所述操作统计信息后,通过所述分区大小预测器,计算完成100%映射任务量后每个分区生成的中间数据量,包括:
当map任务完成时,所述已完成的map任务为所述reduce任务所产生的子分区的总和为所述reduce任务的负载;
通过线性回归方程确定所述已处理数据占总数据集的百分比和所述已完成的map任务为所述reduce任务所产生的子分区的总和之间的相关系数;
根据所述每一个reduce任务的相关系数,预测每一个所述reduce任务的负载。
优选地,所述根据所述分区的中间数据量,通过数据倾斜检测模型判断所述分区中是否存在倾斜分区,具体为:
采用倾斜检测算法判断负载最大的的reducer节点是否过载,若过则,则为倾斜分区。
优选地,当所述map任务执行完毕时,对于任意一个reduce任务,已完成的map任务为所述reduce任务所产生的子分区的总和表示为:
其中,αj和βj为相关系数,
优选地,当map任务执行完毕时,计算出αj和βj后,将dl=100%带入
优选地,所述数据倾斜检测模型为:
其中,fod为所有集群集合的总体偏差,σ为初始集群集合的数据倾斜范围;
当fod≤w数据倾斜程度略有倾斜,fod≥w时,数据的倾斜程度很大;其中,w为预先设置。
相比于现有技术,本发明实施例的有益效果在于,本发明实施例通过在启动map任务后,通过分区监控器获取并统计操作信息,得到操作统计信息;在获得所述操作统计信息后,通过所述分区大小预测器,计算完成100%映射任务量后每个分区生成的中间数据量;根据所述分区的中间数据量,通过数据倾斜检测模型判断所述所有分区中是否存在倾斜分区;若存在,则通过资源调度器将所述倾斜分区内的数据进行降序排序,并对原划分文件进行动态调整、以均衡spark分区负载。本发明实施例既能够使spark的分区负载更均衡,缓解数据倾斜的问题,又能够缩短应用程序完成的时间。
附图说明
图1是本发明实施例中的spark分区负载均衡方法地流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明实施例提供一种负载均衡方法,包括
s1、在启动map任务后,通过分区监控器获取并统计操作信息,得到操作统计信息;
s2、在获得所述操作统计信息后,通过所述分区大小预测器,计算完成100%映射任务量后每个分区生成的中间数据量;
s3、根据所述分区的中间数据量,通过数据倾斜检测模型判断所述所有分区中是否存在倾斜分区;
s4、若存在,则通过资源调度器将所述倾斜分区内的数据进行降序排序,并对原划分文件进行动态调整、以均衡spark分区负载。
在本发明实施例中,分区监控器是基于线性回归分区预测的负载均衡机制sp-lrp(sparkloadbalancingmechanismbasedonlinearregressionpartition)中的一个重要组件,每个worker节点定期向master发送心跳信息,以确保其可用性并更新给定应用程序的运行任务的状态。相比于现有述技术,本发明在map任务运行过程中,扩展了心跳机制,即增加了获取操作信息,并通过操作信息预测分区大小,能尽量减小reduce阶段的等待时间,相比于采用抽样算法实现负载均衡,本发明能够够缩短应用程序完成的时间。
在步骤s1中,所述在启动map任务后,通过分区监控器获取操作信息,具体为:
worker向master发送心跳消息,当master收到worker心跳信息时,分别获取每一个reduce任务的操作信息;所述操作信息包括:已处理数据占总数据集的百分比和已完成的map任务为所述reduce任务所产生的子分区的总和;其中,已处理数据占总数据集的百分比随着spark应用程序的运行而变化。
在步骤s2中,所述在获得所述操作统计信息后,通过所述分区大小预测器,计算完成100%映射任务量后每个分区生成的中间数据量,包括:
当map任务完成时,即完成100%映射任务后,所述已完成的map任务为所述reduce任务所产生的子分区的总和为所述reduce任务的负载;
通过线性回归方程确定所述已处理数据占总数据集的百分比和所述已完成的map任务为所述reduce任务所产生的子分区的总和之间的相关系数;
根据所述每一个reduce任务的相关系数,预测每一个所述reduce任务的负载。
其中,当所述已处理数据占总数据集的百分比大于预设的阈值时,则表示所述map任务已完成,触发负载估计;所述阈值为控制因子,用于控制训练数据集的大小。
在步骤s2中,当所述map任务执行完毕时,对于任意一个reduce任务,已完成的map任务为所述reduce任务所产生的子分区的总和表示为:
其中,αj和βj为相关系数,
基于线性回归的分区预测算法如下表1所示:
表1基于线性回归的分区预测算法
在步骤s3中,所述根据所述分区的中间数据量,通过数据倾斜检测模型判断所述分区中是否存在倾斜分区,具体为:
采用倾斜检测算法判断负载最大的的reducer节点是否过载,若过载,则为倾斜分区。
当map任务执行完毕时,计算出αj和βj后,将dl=100%带入
在本发明实施例中,所述数据倾斜检测模型为:
其中,fod为所有集群集合的总体偏差,σ为初始集群集合的数据倾斜范围;
当fod≤w数据倾斜程度略有倾斜,fod≥w时,数据的倾斜程度很大;其中,w为预先设置,
在一优选的实施例中,假设map任务i为reduce任务j产生的子分区为pi,j,n为map任务的个数,那么,reduce任务j(j∈[1,m])的负载可以通过公式(4-3)表示:
在步骤s4中,资源调度器的主要思想是将倾斜数据分配给当前负载最小的reducer。分区中的key按降序排序,将最大的key标记为1,其余key标记为0。每个集群的分配完成后,根据所有reducer当前剩余容量,再次按降序排序,重复上述集群分配过程。
以下是资源调度器分配算法如表2所示:
表2资源调度器分配算法
相比于现有技术,本发明实施例的有益效果在于,本发明实施例通过在启动map任务后,通过分区监控器获取并统计操作信息,得到操作统计信息;在获得所述操作统计信息后,通过所述分区大小预测器,计算完成100%映射任务量后每个分区生成的中间数据量;根据所述分区的中间数据量,通过数据倾斜检测模型判断所述所有分区中是否存在倾斜分区;若存在,则通过资源调度器将所述倾斜分区内的数据进行降序排序,并对原划分文件进行动态调整、以均衡spark分区负载。本发明实施例既能够使spark的分区负载更均衡,缓解数据倾斜的问题,又能够缩短应用程序完成的时间。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!