一种基于kafka的生产消费同一数据的有序处理方法及系统与流程
本发明涉及数据处理技术领域,更具体的说,本发明涉及一种基于kafka的生产消费同一数据的有序处理方法及系统。
背景技术:
kafka是一个分布式流平台,通过解耦数据流,可做到在需要时使用数据。在不需要缓慢集成的情况下,kafka可将延迟(或每个数据点加载所需的时间)减少到仅10毫秒(与其他集成相比减少约10倍或更多),以此保障其低延迟、高吞吐的性能,即kafka可实时地提供数据。
kafka也具备高横向扩展性,支持分布式部署,每一条消息都有一个topic,每个topic对应多个partition分区,消费端均采用多线程消费。任何同一partition分区的消息处理后并提交offset,可以确定一条在该partition分区下的唯一消息,在partition分区下面可保证有序性,但对于topic不能确保消息的有序性。
同一业务主键的增删改操作会在kafka上产生多条数据,这些数据会被随机(kafka默认机制)发送到不同的partition分区中,最终会被不同的线程消费,而线程消费的效率往往是无法控制,就会导致不同partition分区中的消息被无序的消费,可能生产端明明是先插入在更新最后删除的,最后落地消费顺序成了先删除后更新在插入,这样就会明显的产生跟源端数据不一致的情况,导致业务处理上面出现无法预期的严重后果。
技术实现要素:
为了克服现有技术的不足,本发明提供一种基于kafka的生产消费同一数据的有序处理方法及系统,能够确保相同的业务主键有序推送,消费端有序消费,确保数据被顺序消费。
本发明解决其技术问题所采用的技术方案是:一种基于kafka的生产消费同一数据的有序处理方法,其改进之处在于:该方法包括kafka生产端有序推送的步骤和kafka消费端有序消费的步骤,其中,kafka生产端有序推送的步骤包括:
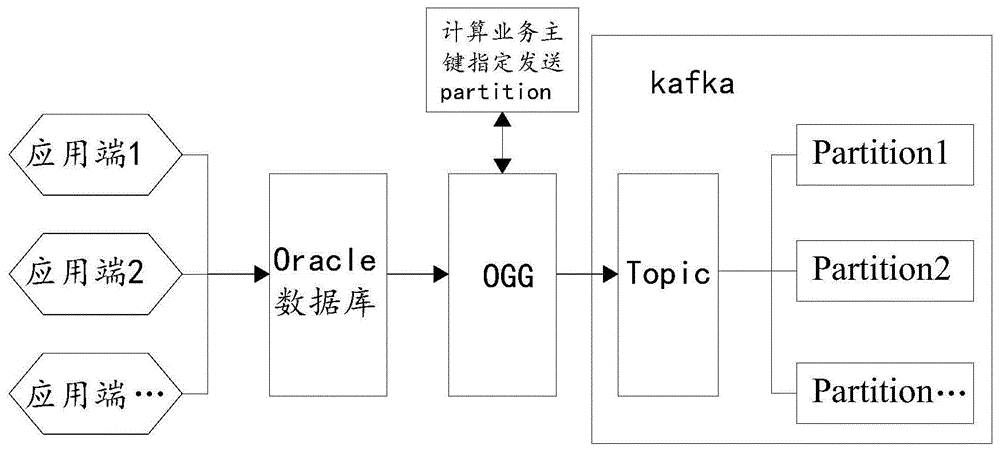
s1、多个应用端按事务提交消息到oracle数据库,ogg同步程序监控oracle数据库的消息变化,将监控到的消息队列,按事务分配ogg同步程序上的不同进程处理;
s2、重写ogg的处理逻辑,得到业务主键对应的partition分区数n;
s3、重写发送的自定义分区,将同一业务主键计算的n值发送到对应的第n个partition分区中;
s4、同一个ogg线程处理同一个事务,一个事务中的数据发送到固定的partition分区上;
kafka保证单独的partition分区数据有序性,通过步骤s3中的自定义分区处理后生产的数据和消费队列在kafka上是全局有序的。
进一步的,所述的kafka消费端有序消费的步骤包括:
s5、消费端连接至kafka,批量拉取对应topic的消息队列;
s6、起多线程消费,线程数与对应topic的partition分区数据相同;
s7、由于partition分区中的消息队列为有序的,因此消费端的单线程消费也是有序的。
进一步的,所述的步骤s1中,ogg同步程序将消息队列,按事务平均分配ogg同步程序上的不同进程处理。
进一步的,所述的步骤s3中,得到业务主键对应的partition分区数n包括以下的步骤:
获取topic中的partition分区总数,记为x值,将拿到的消息中的业务主键进行hash算法,将得到的hash值取绝对值得到y值,则业务主键对应的partition分区数n:n=y%x。
另一方面,本发明还提供了一种基于kafka的生产消费同一数据的有序处理系统,其改进之处在于,该系统包括有应用端、oracle数据库、ogg、partition分区以及消费端;
多个应用端连接在oracle数据库上,应用端按事务提交消息到oracle数据库中,ogg同步程序监控oracle数据库的消息变化,将监控到的消息队列,按事务分配ogg同步程序上的不同进程处理;
kafka内部按topic划分多个partition分区,在重写ogg的处理逻辑后,得到业务主键对应的partition分区数n,并重写发送的自定义分区,将同一业务主键计算的n值发送到对应的第n个partition分区中;
所述消费端包括有多个线程,每个线程均连接至kafka内部的partition分区,线程数与对应topic的partition分区数据相同。
进一步的,所述业务主键对应的partition分区数n的计算过程如下:
获取topic中的partition分区总数,记为x值,将拿到的消息中的业务主键进行hash算法,将得到的hash值取绝对值得到y值,则业务主键对应的partition分区数n:n=y%x。
本发明的有益效果是:在生产端,相同业务主键信息发送到同一topic下指定的partition分区中,如果partition分区扩容,重新获取partition分区的总数后,根据本发明的算法机制自动分发到指定的partition分区,以确保数据被顺序消费;在消费端,消费进程数配置与partition分区数相同,同一partition分区中的数据相当于单线程消费,确保消费有序性;因此,确保相同的业务主键有序推送,消费端有序消费;解决同一事务多个消息必须有序才能确保事务的场景。
附图说明
图1为本发明的一种基于kafka的生产消费同一数据的有序处理方法的kafka生产端有序推送的步骤的示意图。
图2为本发明的一种基于kafka的生产消费同一数据的有序处理方法的kafka消费端有序消费的步骤的示意图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
以下将结合实施例和附图对本发明的构思、具体结构及产生的技术效果进行清楚、完整地描述,以充分地理解本发明的目的、特征和效果。显然,所描述的实施例只是本发明的一部分实施例,而不是全部实施例,基于本发明的实施例,本领域的技术人员在不付出创造性劳动的前提下所获得的其他实施例,均属于本发明保护的范围。另外,专利中涉及到的所有联接/连接关系,并非单指构件直接相接,而是指可根据具体实施情况,通过添加或减少联接辅件,来组成更优的联接结构。本发明创造中的各个技术特征,在不互相矛盾冲突的前提下可以交互组合。
参照图1所示,本发明揭示了一种基于kafka的生产消费同一数据的有序处理方法,具体的,该方法包括kafka生产端有序推送的步骤和kafka消费端有序消费的步骤,通过kafka生产端有序推送的步骤,保证了相同的业务主键有序推送;通过kafka消费端有序消费的步骤,保证了消费端有序消费,从而解决同一事务多个消息必须有序才能确保事务的场景。
结合图1所示,对于kafka生产端有序推送的步骤,本发明提供了一具体实施例,其步骤如下:
s1、多个应用端按事务提交消息到oracle数据库,ogg同步程序监控oracle数据库的消息变化,将监控到的消息队列,按事务平均分配ogg同步程序上的不同进程处理;
s2、重写ogg的处理逻辑,得到业务主键对应的partition分区数n;
在本实施例中,得到业务主键对应的partition分区数n包括以下的步骤:获取topic中的partition分区总数,记为x值,将拿到的消息中的业务主键进行hash算法,将得到的hash值取绝对值得到y值,则业务主键对应的partition分区数n:n=y%x。
s3、重写发送的自定义分区,将同一业务主键计算的n值发送到对应的第n个partition分区中;
根据本发明的算法机制自动分发到指定的partition分区,以确保数据被顺序消费;
s4、同一个ogg线程处理同一个事务,一个事务中的数据发送到固定的partition分区上;
kafka保证单独的partition分区数据有序性,通过步骤s3中的自定义分区处理后生产的数据和消费队列在kafka上是全局有序的。
结合图2所示,对于kafka消费端有序消费的步骤,本发明提供了一具体实施例,其步骤如下:
s5、消费端连接至kafka,批量拉取对应topic的消息队列;
s6、起多线程消费,线程数与对应topic的partition分区数据相同;
s7、由于partition分区中的消息队列为有序的,因此消费端的单线程消费也是有序的。
在消费端,消费进程数配置与partition分区数相同,同一partition分区中的数据相当于单线程消费,确保消费有序性。
另外,参照图1、图2所示,本发明还提供了一种基于kafka的生产消费同一数据的有序处理系统,该系统包括有应用端、oracle数据库、ogg、partition分区以及消费端;多个应用端连接在oracle数据库上,应用端按事务提交消息到oracle数据库中,ogg同步程序监控oracle数据库的消息变化,将监控到的消息队列,按事务平均分配ogg同步程序上的不同进程处理;kafka内部按topic划分多个partition分区,在重写ogg的处理逻辑后,得到业务主键对应的partition分区数n,并重写发送的自定义分区,将同一业务主键计算的n值发送到对应的第n个partition分区中;本实施例中,所述业务主键对应的partition分区数n的计算过程如下:获取topic中的partition分区总数,记为x值,将拿到的消息中的业务主键进行hash算法,将得到的hash值取绝对值得到y值,则业务主键对应的partition分区数n:n=y%x。所述消费端包括有多个线程,每个线程均连接至kafka内部的partition分区,线程数与对应topic的partition分区数据相同。
通过上述的叙述,本发明的一种基于kafka的生产消费同一数据的有序处理方法及系统,在生产端,相同业务主键信息发送到同一topic下指定的partition分区中,如果partition分区扩容,重新获取partition分区的总数后,根据本发明的算法机制自动分发到指定的partition分区,以确保数据被顺序消费;在消费端,消费进程数配置与partition分区数相同,同一partition分区中的数据相当于单线程消费,确保消费有序性;确保相同的业务主键有序推送,消费端有序消费;解决同一事务多个消息必须有序才能确保事务的场景。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!