一种文本解释生成方法及系统与流程
本发明涉及人工智能技术领域,特别是涉及一种文本解释生成方法及系统。
背景技术:
随着芯片与人工智能技术的迅速发展,为自主救援机器人行为控制提供多方面的支持。但是,自主救援机器人的发展仍处在初期阶段,其工作过程中仍然需要现场或者远程人为干涉,自主控制技术作为机器人的指挥中心,起到了非常重要的作用。人工智能作为自动控制技术的一种,得到了快速发展,在模型的准确率不断提升的同时,模型的复杂程度也同步提高。
目前,基于深度增强学习网络模型的文本可解释性研究方法中主要存在以下问题:(1)趋于复杂的模型逻辑对模型使用者而言以黑盒形式工作,模型内部的逻辑对使用者不可见,导致使用者难以理解模型内部的逻辑,因此当模型不能按照预期工作时难以回溯问题出现的原因,影响模型使用者对模型的理解与信任,从而影响模型使用者对模型的指导,降低人机协作的效果。(2)机器人作为一种可由模型控制的智能体,其行为逻辑忠实于预设逻辑或者前期训练数据中的规律。然而由于数据的客观逻辑与具有先验知识的人类逻辑具有一定的偏差,导致数据中呈现出来的客观规律并不完全与模型使用者的主观逻辑一致。当不一致出现时,模型使用者不可避免的对可控制智能体的行为与可靠性产生质疑,导致模型使用者与可控智能体协作有效性降低。一些学者提出基于对象的显著图像对增强学习决策过程进行解释,结果表明该显著图像能够提升被测试者对模型的理解,但由于图像解释具有一定的模糊性和歧义性,容易导致使用者对可控智能体行为的理解存在偏差,从而导致任务的失败。
技术实现要素:
本发明的目的是提供一种文本解释生成方法及系统,采用自然语言对模型进行解释,降低了图像解释的模糊性,使模型的决策过程更容易被控制者理解。
为实现上述目的,本发明提供了如下方案:
一种文本解释生成方法,包括:
获取实际场景图片以及场景中的非可控智能体;所述非可控智能体为强化学习模型不能控制的对象;
根据非可控智能体对可控智能体的影响程度确定非可控智能体的优先级;所述可控智能体为所述强化学习模型能够控制的对象;
在关注区域内选取按优先级由高到低顺序排列的前n类非可控智能体,并对所述前n类非可控智能体采用语言模板生成文本解释;
判断生成的文本解释是否正确;若正确则返回步骤“获取实际场景图片以及场景中的非可控智能体”,否则,提取所述实际场景图片中的特征信息,并对所述特征信息采用训练好的gru模型进行文本解释。
可选的,所述根据非可控智能体对可控智能体的影响程度确定非可控智能体的优先级,具体包括:
获取强化学习模型在场景中选择的行为;
根据所述行为计算非可控智能体的平均得分以及遮挡一类非可控智能体后的得分;
将所述遮挡一类非可控智能体后的得分与所述平均得分的差值确定为遮挡的这类非可控智能体的重要程度;
将各类非可控智能体的重要程度按由大到小顺序排列,得到非可控智能体由高到低的优先级。
可选的,所述对所述前n类非可控智能体采用语言模板生成文本解释,具体包括:
确定非可控智能体与可控智能体的相对位置;
根据所述相对位置和可控智能体相对于非可控智能体的行为,按照非可控智能体的优先级的顺序采用语言模板分别对所述前n类非可控智能体进行文本解释。
可选的,所述提取所述实际场景图片中的特征信息,并对所述特征信息采用训练好的gru模型进行文本解释,具体包括:
获取实际可控智能体图片和实际显著性图片;所述实际显著性图片为包括可控智能体和前n类非可控智能体的图片;
分别对所述实际场景图片、所述实际可控智能体图片和所述实际显著性图片进行编码,得到实际场景特征信息、实际可控智能体特征和实际显著性图像特征;
将所述实际场景特征信息、所述实际可控智能体特征和所述实际显著性图像特征输入训练好的gru模型,生成文本解释。
可选的,所述训练好的gru模型,具体训练过程包括:
获取文本解释中的词汇表;所述词汇表中包括多个词汇;
采用卷积法提取所述词汇的潜在特征;
根据所述词汇的潜在特征和gru模型的隐藏层参数确定分布在训练场景特征信息、训练可控智能体特征和训练显著性图像特征的注意力;所述训练场景特征信息、所述训练可控智能体特征和所述训练显著性图像特征通过对训练场景图片、训练可控智能体图片和训练显著性图片进行编码得到;
根据所述注意力、所述词汇的潜在特征、所述训练场景特征信息、所述训练可控智能体特征和所述训练显著性图像特征确定gru模型的输入门;
根据gru模型的输入门和gru模型的隐藏层参数分别确定gru模型的重置门和gru模型的更新门;
根据所述输入门、所述重置门、所述更新门和所述gru模型的隐藏层参数确定gru模型的输出门;
根据所述输出门确定输出的文本描述信息;
根据所述输出的文本描述信息采用公式
以最小化所述损失函数为目标对gru模型中的参数进行优化,得到训练好的gru模型。
本发明还提供一种文本解释生成系统,包括:
场景获取模块,用于获取实际场景图片以及场景中的非可控智能体;所述非可控智能体为强化学习模型不能控制的对象;
非可控智能体的优先级确定模块,用于根据非可控智能体对可控智能体的影响程度确定非可控智能体的优先级;所述可控智能体为所述强化学习模型能够控制的对象;
基于语言模板的文本解释模块,用于在关注区域内选取按优先级由高到低顺序排列的前n类非可控智能体,并对所述前n类非可控智能体采用语言模板生成文本解释;
判断模块,用于判断生成的文本解释是否正确;若正确则执行所述场景获取模块,否则,执行基于学习的文本解释模块;
基于学习的文本解释模块,用于提取所述实际场景图片中的特征信息,并对所述特征信息采用训练好的gru模型进行文本解释。
可选的,所述非可控智能体的优先级确定模块,具体包括:
行为获取单元,用于获取强化学习模型在场景中选择的行为;
得分计算单元,用于根据所述行为计算非可控智能体的平均得分以及遮挡一类非可控智能体后的得分;
非可控智能体得分确定单元,用于将所述遮挡一类非可控智能体后的得分与所述平均得分的差值确定为遮挡的这类非可控智能体的重要程度;
优先级确定单元,用于将各类非可控智能体的重要程度按由大到小顺序排列,得到非可控智能体由高到低的优先级。
可选的,所述基于语言模板的文本解释模块,具体包括:
相对位置确定单元,用于确定非可控智能体与可控智能体的相对位置;
基于语言模板的文本解释单元,用于根据所述相对位置和可控智能体相对于非可控智能体的行为,按照非可控智能体的优先级的顺序采用语言模板分别对所述前n类非可控智能体进行文本解释。
可选的,所述基于学习的文本解释模块,具体包括:
图片获取单元,用于获取实际可控智能体图片和实际显著性图片;所述实际显著性图片为包括可控智能体和前n类非可控智能体的图片;
编码单元,用于分别对所述实际场景图片、所述实际可控智能体图片和所述实际显著性图片进行编码,得到实际场景特征信息、实际可控智能体特征和实际显著性图像特征;
基于学习的文本解释单元,用于将所述实际场景特征信息、所述实际可控智能体特征和所述实际显著性图像特征输入训练好的gru模型,生成文本解释。
可选的,所述基于学习的文本解释单元,具体包括:
gru模型训练子单元,用于获取文本解释中的词汇表;所述词汇表中包括多个词汇;
采用卷积法提取所述词汇的潜在特征;
根据所述词汇的潜在特征和gru模型的隐藏层参数确定分布在训练场景特征信息、训练可控智能体特征和训练显著性图像特征的注意力;所述训练场景特征信息、所述训练可控智能体特征和所述训练显著性图像特征通过对训练场景图片、训练可控智能体图片和训练显著性图片进行编码得到;
根据所述注意力、所述词汇的潜在特征、所述训练场景特征信息、所述训练可控智能体特征和所述训练显著性图像特征确定gru模型的输入门;
根据gru模型的输入门和gru模型的隐藏层参数分别确定gru模型的重置门和gru模型的更新门;
根据所述输入门、所述重置门、所述更新门和所述gru模型的隐藏层参数确定gru模型的输出门;
根据所述输出门确定输出的文本描述信息;
根据所述输出的文本描述信息采用公式
以最小化所述损失函数为目标对gru模型中的参数进行优化,得到训练好的gru模型。
与现有技术相比,本发明的有益效果是:
本发明提出了一种文本解释生成方法及系统,获取实际场景图片以及场景中的非可控智能体,根据非可控智能体对可控智能体的影响程度确定非可控智能体的优先级;在关注区域内选取按优先级由高到低顺序排列的前n类非可控智能体,并对前n类非可控智能体采用语言模板生成文本解释;若生成的文本解释不正确,则提取实际场景图片中的特征信息,并对特征信息采用训练好的gru模型进行文本解释。本发明采用了自然语言对模型进行解释,降低了图像解释的模糊性,使模型的决策过程更容易被控制者理解,并且在可控智能体或者非可控智能体识别不准确导致强化学习模型则不能工作时,能够隐式的获取场景中的潜在特征,潜在特征能够体现可控智能体与非可控智能体的相关信息,提高了文本解释规则的可泛化性与灵活性。
另外,强化学习模型还可用来预测下一步的行为解释,这一信息可以辅助模型使用者提前了解可控智能体的行为。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中文本解释生成方法流程图;
图2为本发明实施例中基于规则的文本解释生成过程示意图;
图3为本发明实施例中基于学习的文本解释生成流程图;
图4为本发明实施例中虚拟场景中非可控智能体与可控智能体的相对位置示意图;
图5为本发明实施例中对输入数据编码流程图;
图6为本发明实施例中文本解释生成系统结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种文本解释生成方法及系统,采用自然语言对模型进行解释,降低了图像解释的模糊性,使模型的决策过程更容易被控制者理解。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
实施例
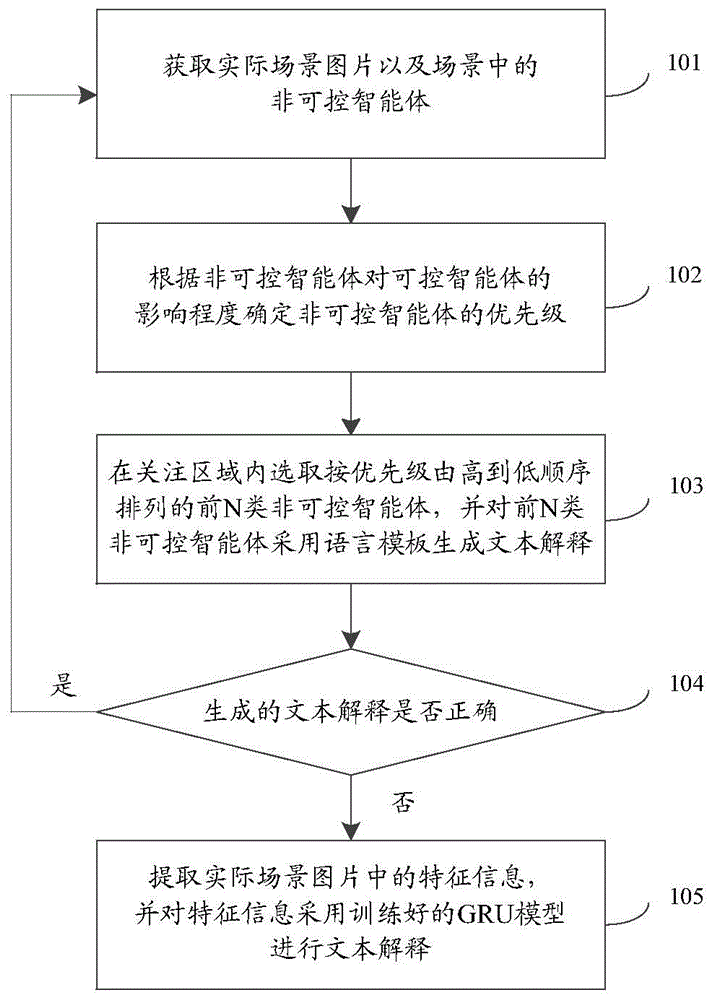
图1为本发明实施例中文本解释生成方法流程图,如图1所示,一种文本解释生成方法,包括:
步骤101:获取实际场景图片以及场景中的非可控智能体;非可控智能体为强化学习模型不能控制的对象。
步骤102:根据非可控智能体对可控智能体的影响程度确定非可控智能体的优先级;可控智能体为强化学习模型能够控制的对象。
步骤102,具体包括:
获取强化学习模型在场景中选择的行为;
根据行为计算非可控智能体的平均得分以及遮挡一类非可控智能体后的得分;
将遮挡一类非可控智能体后的得分与平均得分的差值确定为遮挡的这类非可控智能体的重要程度;
将各类非可控智能体的重要程度按由大到小顺序排列,得到非可控智能体由高到低的优先级。
步骤103:在关注区域内选取按优先级由高到低顺序排列的前n类非可控智能体,并对前n类非可控智能体采用语言模板生成文本解释。
步骤103,具体包括:
确定非可控智能体与可控智能体的相对位置;
根据相对位置和可控智能体相对于非可控智能体的行为,按照非可控智能体的优先级的顺序采用语言模板分别对前n类非可控智能体进行文本解释。
步骤104:判断生成的文本解释是否正确;若正确则返回步骤101,否则,执行步骤105。
步骤105:提取实际场景图片中的特征信息,并对特征信息采用训练好的gru模型进行文本解释。
步骤105,具体包括:
获取实际可控智能体图片和实际显著性图片;实际显著性图片为包括可控智能体和前n类非可控智能体的图片;
分别对实际场景图片、实际可控智能体图片和实际显著性图片进行编码,得到实际场景特征信息、实际可控智能体特征和实际显著性图像特征;
将实际场景特征信息、实际可控智能体特征和实际显著性图像特征输入训练好的gru模型,生成文本解释。
其中,训练好的gru模型,具体训练过程包括:
获取文本解释中的词汇表;词汇表中包括多个词汇;
采用卷积法提取词汇的潜在特征;
根据词汇的潜在特征和gru模型的隐藏层参数确定分布在训练场景特征信息、训练可控智能体特征和训练显著性图像特征的注意力;训练场景特征信息、训练可控智能体特征和训练显著性图像特征通过对训练场景图片、训练可控智能体图片和训练显著性图片进行编码得到;
根据注意力、词汇的潜在特征、训练场景特征信息、训练可控智能体特征和训练显著性图像特征确定gru模型的输入门;
根据gru模型的输入门和gru模型的隐藏层参数分别确定gru模型的重置门和gru模型的更新门;
根据输入门、重置门、更新门和gru模型的隐藏层参数确定gru模型的输出门;
根据输出门确定输出的文本描述信息;
根据输出的文本描述信息采用公式
以最小化损失函数为目标对gru模型中的参数进行优化,得到训练好的gru模型。
图2为基于规则的文本解释生成过程示意图,图3为基于学习的文本解释生成流程图。如图2-3所示,本发明提供的文本解释生成方法是一种基于深度增强学习网络模型的文本可解释性方法,具体步骤如下:
(1)获取选定场景描述信息;
选定场景的描述信息包括场景图片im、场景中的非可控智能体o和强化学习模型m。场景中的非可控智能体指场景中模型不能控制的对象,比如救援任务中的场景元素:道路、建筑等。其中非可控智能体又分为积极非可控智能体与消极非可控智能体。
积极非可控智能体:指对可控智能体的目标具有辅助作用的非可控智能体,比如救援场景中完整的道路、楼梯等。
消极非可控智能体:指对可控智能体的目标具有阻碍作用的非可控智能体,比如救援场景中损坏的道路、断裂的楼梯等。
(2)计算非可控智能体的得分;
本发明的研究过程基于吃豆人虚拟场景,假设虚拟场景当前的状态记为s,首先初始化目标中场景的非可控智能体得分,然后利用强化学习模型自动在虚拟场景中选择行为,记录在虚拟场景中的平均得分q(s,α)。在目标场景中去掉非可控智能体o,记为so,利用强化学习模型自动在虚拟场景中选择行为,记录得分q(so,α)。通过计算目标非可控对象对当前虚拟场景状态的影响为两个累积得分的差值更新非可控智能体的得分w:
w=q(so,α)-q(s,α)
其中,w表示当前虚拟场景状态中去掉目标非可控对象后的得分差。若w为负值,则表示目标非可控对象对虚拟场景得分起正面作用,值越低表明影响越大;若w为正值,则表示目标非可控对象对虚拟场景得分起负面作用,值越高表明影响越大。
(3)对非可控智能体的得分排序并同质化;
本发明选取的虚拟场景中只有吃豆人为可控智能体,虚拟场景中的豆子、樱桃、能量药丸、鬼怪、可食用鬼怪均为非可控智能体。场景中的非可控智能体记为o={o1,o2,…,on}。其中,虚拟场景中的豆子、樱桃、能量药丸与可食用鬼怪为积极非可控智能体,若可控智能体吃豆人食用积极非可控智能体,则可累积得分;鬼怪为消极非可控智能体,若吃豆人遇到消极非可控智能体,则丢失性命。豆子与能量药丸位置固定,樱桃、可食用鬼怪与鬼怪位置会发生变化。基于此,虚拟场景中吃豆人为了尽量多的累计得分,行为表现为追逐积极非可控智能体,同时躲避消极非可控智能体。该虚拟场景下非可控智能体对可控智能体的影响力具有以下规律:
对于积极非可控智能体豆子、能量药丸、樱桃、可食用鬼怪,其影响力w的期望为负值,即积极非可控智能体的消失将会导致最终累积得分的损失。
对于消极非可控智能体鬼怪,其影响力w的期望为正值,即消极非可控智能体的消失将会导致最终累积得分的提升。
(4)选取非可控智能体关注区域内得分最大的四个非可控智能体
首先,设置非可控对象描述优先级:
优先级的设定由非可控智能体对可控智能体的影响力决定。比如救援场景中先近后远、先重要后次要等原则。在选取的虚拟场景中:鉴于积极非可控对象在虚拟场景中的得分设置,对积极非可控对象设置优先级为可食用鬼怪、樱桃、能量药丸与豆子;由于吃豆人遇到鬼怪会直接丧失性命,因此鬼怪的优先级高于其他非可控智能体。
然后,设置关注区域:
可控智能体的行为受视野范围内的非可控智能体的影响,视野范围外的元素不进行描述。可控智能体的行为受非可控智能体位置的影响,因此设置关注区域,对在距离可控智能体一定范围内的信息进行描述。
另外,解释的准确性影响解释的说服力,为提高文本解释的说服力对场景中有限数量的非可控智能体进行描述。描述规则如下:
关注区域:设定关注区域表示为d,非可控智能体与可控智能体之间的直线距离记为d。若非可控智能体在可控智能体的关注范围内,则表达为d<d,在生成的文本解释中只对距离可控智能体一定范围内的对象进行描述。在关注区域内的非可控智能体记为
关注区域内注意力分布:设定非可控智能体的优先级为p={ρ1,ρ2,ρ3,ρ4,ρ5,...,ρn},其中ρ1>ρ2>ρ3>ρ4>ρ5>…>ρn。按照优先级顺序分配注意力,在吃豆人虚拟场景中,非可控智能体的优先级顺序依次为:鬼怪(ρ1)、可食用鬼怪(ρ2)、樱桃(ρ3)、能量药丸(ρ4)、豆子(ρ5)。
相对位置:设定相对位置为
在选取的吃豆人虚拟场景中,规定解释中最多对四类非可控智能体进行描述。
(5)选择所需要的语言模板;
语言风格的设计需要符合人类阅读习惯,使描述内容自然通顺容易被理解。基于上述出发点,首先对可控智能体的行为进行解释,其次解释可控智能体的行为动机,最后介绍可控智能体的反常行为原因。
可控智能体的行为目标为接近积极非可控智能体并规避消极非可控智能体。但是在现实场景中会出现行为与目的不一致的情形,比如可控智能体为了躲避消极非可控智能体而不得不远离积极非可控智能体,或者为了追逐积极非可控智能体而不得不靠近消极非可控智能体。
因此,设定特定场景中可控智能体的行为分类记为ψ={ψ1,ψ2}两类。
ψ1:可控智能体行为与期望保持一致,记为类别#1。
ψ2:可控智能体行为与期望相反,记为类别#2。
两类行为在实际场景中相互约束,可独立存在,也可同时存在。在进行语言解释时综合考虑两种类型的行为,对可控智能体的行为进行解释。
在本发明选定的吃豆人的虚拟场景中,首先描述吃豆人的移动方向,其次按照优先级解释类别#1中的非可控智能体,然后解释类别#2中非可控智能体。据此设计语言模板,记「·」为可重复内容,{·}表示可选内容,可选内容{与}用来保证描述多组可控智能体时的语言流畅性。
假设设定语言模板记为γ={γ1,γ2,γ3,γ4,...,γn}。该虚拟场景下语言模板包括如下内容:
γ1:非可控智能体「{与}{非可控智能体名称}」引起了吃豆人的注意
γ2:吃豆人向{移动方向}移动以便食用「{与}{相对方位}的{数量}个{非可控智能体名称}」
γ3:吃豆人向{移动方向}移动以便躲避「{与}{相对方位}的{数量}个鬼怪」
γ4:结果,吃豆人不得不{远离/靠近}「{与}{相对方位}的{数量}个{非可控智能体名称}」。
在救援场景中,需要依据待解释模型与场景设计具体的语言模板,以达到想模型控制者解释模型行为的目的。
(6)当可控智能体或者非可控智能体识别不准确时,选用基于学习机制的文本解释模型;
基于规则的文本解释模型能够准确的生成解释,但是当可控智能体或者非可控智能体识别不准确时,该模型则不能工作,因此该模型缺乏泛化性与灵活性。基于学习机制的文本解释模型能够隐式的获取场景中的潜在特征,这些特征包括可控智能体与非可控智能体的相关信息,在一定程度上弥补前期非可控智能体识别不准确而造成的不能利用规则生成文本的问题,可提高文本解释规则的可泛化性。另外,学习模型还可用来预测下一步的行为解释,这一信息可以辅助模型使用者提前了解可控智能体的行为。
(7)获取选定场景描述信息,训练基于学习机制的文本解释生成模型;
在吃豆人的虚拟场景中,训练模型需要获取的数据包括场景图片im、可控智能体图片ip、显著性图片is与文本解释。
(8)对输入数据进行编码;
场景编码器将输入数据进行编码,挖掘场景中内部对象的因果关系,为文本生成过程提供输入数据。模型首先会随机初始化给定场景编码器和文本解码器,然后批量组织训练数据。对输入数据编码流程图如图5所示。
令
i′m=fm(im|wm,bm)
其中,i′m表示场景信息处理结果,wm和bm表示计算过程中参与计算的参数。函数fm包含两层卷积操作,以及每层卷积后追加的relu激活与bn(batchnormalization)计算。卷积操作中卷积核的尺寸为10×10,步长为1。10×10的卷积核尺寸相对于alexnet、resnet、vgg中的卷积核尺寸而言较大,该卷积核能够凸显相似图片中的不同点,使不同点多次出现在相邻窗口中,相对放大图像中的不同点。
i′p=fp(ip|wp,bp)
其中i′p表示吃豆人信息处理结果,wp与bp表示该处理过程中参与计算的参数。函数fp包含两层卷积操作,以及每层卷积后追加的最大池化层。此处卷积核尺寸为10×10,步长为1,池化操作核尺寸为2×2。
i′s=fs(is|ws,bs)
其中,i′s表示显著性图像处理结果,w与bs分别表示该处理过程中参与计算的参数。fs与fp具有类似的操作,即卷积与池化操作,对应的卷积核与池化核尺寸分别为10×10与2×2。
虚拟场景文本编码器对虚拟场景进行编码,隐式获取虚拟场景中的可控智能体、积极非可控智能体、消极非可控智能体的特征信息,为虚拟场景文本解码器提供数据支持。
(9)虚拟场景文本解码;
文本解码器旨在对可控智能体所处的场景进行描述,获取虚拟场景编码器的输出数据进行解码。在解码器中使用注意力机制选择生成文字所需要的场景特征、可控智能体特征、以及显著性图像特征,根据选取的内容生成具有可读性的流畅文本解释。文本解码器中用到三个函数,该三个函数分别为softmax计算,记为η(·);sigmoid激活,记为σ(·);relu激活,记为ρ(·)。
令v={v1,..,vi,..,vn}表示文本解释中的词汇表,n表示词汇表中词汇的数量。每个词汇均表示为独热向量,即vi∈{0,1}n。
其中,
at=η(wa·[ht-1,ct])
gt=ρ(wg·[ct,at*[i′m,i′ρ,i′s]])
其中,wa和wg分别是softmax和relu函数计算过程中的初始权重。使用注意力选择之后的场景特征、可控智能体特征、以及显著性图像特征。gt是gru计算的输入数据,即输入门,gru中的门操作过程为:
rt=σ(wr·[ht-1,gt])
zt=σ(wz·[ht-1,gt])
其中,wr、wz与
yt=η(wy·ht)
其中,输出的文本描述信息
(10)最小化损失值,优化编码器和解码器的参数;
损失函数为交叉熵损失,具体如下:
其中,l表示损失函数,n表示词汇表中词汇的数量,t表示词汇,dv表示词汇维度,vti表示选取词汇的标记中第i个元素,yti表示输出的文本描述信息中第i个元素。
模型训练的目标为最小化该损失函数。损失函数的值最小化之后得到的即为训练好的编码器和解码器。
虚拟场景文本解码器包括gru与注意力机制两个计算模块。gru模块控制文字序列生成过程,注意力机制选择文本生成所需要的特征,两个模块协同工作。
(11)获取选定场景描述信息测试基于学习机制的文本解释生成模型;
在吃豆人的虚拟场景中,测试模型获取的数据包括场景图片im、可控智能体图片ip、显著性图片is和训练好的场景编码器模型以及文本解码器模型。
(12)生成选定场景的文本解释。
图6为本发明实施例中文本解释生成系统结构图。如图6所示,一种文本解释生成系统,包括:
场景获取模块201,用于获取实际场景图片以及场景中的非可控智能体;非可控智能体为强化学习模型不能控制的对象;
非可控智能体的优先级确定模块202,用于根据非可控智能体对可控智能体的影响程度确定非可控智能体的优先级;可控智能体为强化学习模型能够控制的对象;
非可控智能体的优先级确定模块202,具体包括:
行为获取单元,用于获取强化学习模型在场景中选择的行为;
得分计算单元,用于根据行为计算非可控智能体的平均得分以及遮挡一类非可控智能体后的得分;
非可控智能体得分确定单元,用于将遮挡一类非可控智能体后的得分与平均得分的差值确定为遮挡的这类非可控智能体的重要程度;
优先级确定单元,用于将各类非可控智能体的重要程度按由大到小顺序排列,得到非可控智能体由高到低的优先级。
基于语言模板的文本解释模块203,用于在关注区域内选取按优先级由高到低顺序排列的前n类非可控智能体,并对前n类非可控智能体采用语言模板生成文本解释;
基于语言模板的文本解释模块203,具体包括:
相对位置确定单元,用于确定非可控智能体与可控智能体的相对位置;
基于语言模板的文本解释单元,用于根据相对位置和可控智能体相对于非可控智能体的行为,按照非可控智能体的优先级的顺序采用语言模板分别对前n类非可控智能体进行文本解释。
判断模块204,用于判断生成的文本解释是否正确;若正确则执行场景获取模块,否则,执行基于学习的文本解释模块;
基于学习的文本解释模块205,用于提取实际场景图片中的特征信息,并对特征信息采用训练好的gru模型进行文本解释。
基于学习的文本解释模块205,具体包括:
图片获取单元,用于获取实际可控智能体图片和实际显著性图片;实际显著性图片为包括可控智能体和前n类非可控智能体的图片;
编码单元,用于分别对实际场景图片、实际可控智能体图片和实际显著性图片进行编码,得到实际场景特征信息、实际可控智能体特征和实际显著性图像特征;
基于学习的文本解释单元,用于将实际场景特征信息、实际可控智能体特征和实际显著性图像特征输入训练好的gru模型,生成文本解释。
基于学习的文本解释单元,具体包括:
gru模型训练子单元,用于获取文本解释中的词汇表;词汇表中包括多个词汇;
采用卷积法提取词汇的潜在特征;
根据词汇的潜在特征和gru模型的隐藏层参数确定分布在训练场景特征信息、训练可控智能体特征和训练显著性图像特征的注意力;训练场景特征信息、训练可控智能体特征和训练显著性图像特征通过对训练场景图片、训练可控智能体图片和训练显著性图片进行编码得到;
根据注意力、词汇的潜在特征、训练场景特征信息、训练可控智能体特征和训练显著性图像特征确定gru模型的输入门;
根据gru模型的输入门和gru模型的隐藏层参数分别确定gru模型的重置门和gru模型的更新门;
根据输入门、重置门、更新门和gru模型的隐藏层参数确定gru模型的输出门;
根据输出门确定输出的文本描述信息;
根据输出的文本描述信息采用公式
以最小化损失函数为目标对gru模型中的参数进行优化,得到训练好的gru模型。
对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!