多源异构数据融合汇聚方法与流程
本发明涉及情报侦查数据融合领域,特别是一种多源异构数据融合汇聚方法。
背景技术:
情报侦查系统、业务系统由于建设时间不同、技术发展程度不同,导致数据标准不统一、字段类型不一致、数据质量不过关、数据库技术不统一等诸多问题;系统间数据分散,信息孤岛现象普遍存在,无法形成情报数据合力。线索关联度不高、数据使用复杂,往往无从下手,同时各系统之间同类数据无法统一,为了对某一种类或某个字段对应的数据进行比对分析处理和数据分析处理。往往需要横跨多个系统。为了破解此难题,目前传统的做法是是使用etl工具对数据进行综合治理,根据来源数据的特点和目标结构直接做映射,汇聚多个数据来源的数据,在汇聚数据的基础上对汇聚数据进行二次处理。
该技术手段虽然一定程度解决了数据融合问题,部分解决了自动化抽取、清洗、导入的问题,但是该方案的设计思路并没有结合情报侦查业务需求,无法与布控比对、数据标签、情报发现等侦查工作模式紧密融合,同时etl工具的数据汇聚任务往往由数据运维人员指定运行主机,人工参与程度高,很难满足时效性问题,对于通道队列类数据,无法实时获取队列数据,数据实时利用程度不高。
技术实现要素:
本发明旨在提供适用于情报侦查领域的一种多源异构数据融合汇聚方法,以解决传统的etl工具无法与侦查业务紧密相连,不能对海量轨迹数据进行实时分析处理的问题,以实现对在多源异构数据融合同时与情报侦查工作紧密结合,实现海量实时多源异构数据汇聚融合分析的应用场景。
为解决上述技术问题,本发明所采取的技术方案如下:
一种多源异构数据融合汇聚方法,包括以下具体步骤:
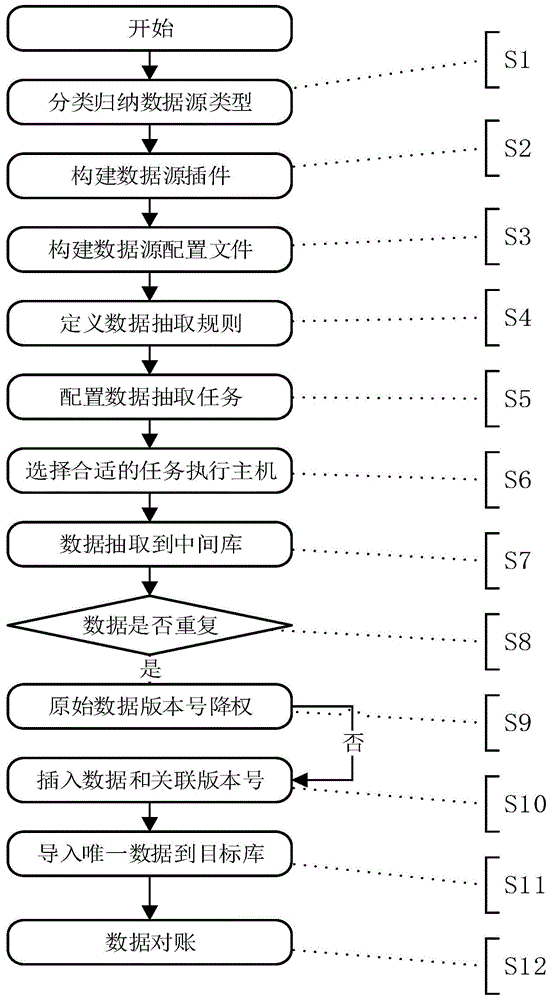
s1、分类归纳数据源类型,其中包括关系性数据源,非关系性数据源,文件类数据源,关系性数据源;
s2、对访问方式相近的数据源进行统一包装,将数量繁多的数据源包装为少量具有统一访问方式的数据源访问接口,访问接口分为关系型数据接口、非关系型数据接口、文件型数据接口、实时队列数据接口四大类接口插件;
s3、根据不同类型接口访问方式,对外提供相关配置信息,包括数据源的地址、数据源账密、数据格式、数据处理方式、任务名;
s4、定义数据抽取的时间规则,规则包括时间规则和抽取规则,时间规则包括年,月,周,日,时,分,秒;抽取规则包括增量抽取、全量抽取、实时抽取;
s5、根据配置文件和数据抽取规则生成数据抽取任务;
s6、数据抽取任务在所有部署数据源接口插件的主机的列表内,选择资源利用率最低的主机来执行数据抽取任务;
s7、数据抽取任务抽取的数据需要先抽取到中间库
s8、数据抽取到中间库的过程中,数据抽取任务根据数据主键确定数据是否唯一存在;
s9、数据抽取任务发现本条数据不唯一,对上一条重复数据的版本号修改为数据插入时间和主键组合的唯一值;
s10、数据抽取任务发现本条数据不重复,则直接插入本条数据,将数据的版本号标记为01,同时记录数据插入时间;
s11、将中间库中不同来源的数据抽取到目标库中,并将版本不为01的数据抽取到目标库对应的历史数据表中;
s12、根据数据抽取任务的开始时间和截止时间统计来源数据的数据总量和目标数据的数据总量,根据数据总量确定数据抽取任务是否执行成功。
进一步优化技术方案,所述步骤s2中,所述实时队列数据获取插件能够获取kafka、redis、activemq队列的数据。
进一步优化技术方案,所述步骤s2中,所述关系型数据接口插件内包含oracle数据源、mysql数据源、postgre数据源、sybase数据源;非关系型数据接口插件内包含mongodb数据源、hbase数据源、elasticsearch数据源;文件型数据接口插件内包含本地文件数据源、ftp文件数据源、hdfs文件数据源;采用java开发技术使用策略模式和模板设计方法对几大类数据接口插件进行封装,插件可以根据配置信息,根据配置的策略模式调用具体的数据源访问方法,采用策略模式是为了减少相同类型插件相同工作的重复开发。
进一步优化技术方案,所述步骤s3中,数据格式包括表类型和文件类型,表类型描述包括表中文名、表英文名、字段中文名、字段英文名;文件类型描述包括文件列分割符、行分隔符、列含义。
进一步优化技术方案,所述步骤s3中,数据处理方式包括数据清洗、数据质量效验、核心数据提取、数据比对、数据对标、文本实体识别、图像重点物品分类。
进一步优化技术方案,配置数据融合任务时,数据处理方式的顺序为数据质量效验、数据清洗、数据对标、核心数据提取、数据比对、文本实体识别、图像重点物品分类。
进一步优化技术方案,数据质量效验为对源头数据的质量合规性做检查,用户选定源头数据的格式,系统会根据预定义的格式采用正则表达式的方式确定源头数据是否符合要求,不符合要求的数据直接丢弃,系统记录丢弃数据日志,同时记录丢弃原因。
进一步优化技术方案,数据清洗是在数据质量效验数据符合要求,对数据进一步处理,用户指定数据清洗规则,清洗规则包括截取、合并、拆分。
进一步优化技术方案,用户指定需要对标的字段,系统根据数据清洗后的字段与系统标识库中的字典进行比对,替换原始数据为标准字典数据。
进一步优化技术方案,用户指定需要数据提取的字段,指定需要提取的数据内容,包括身份证件、手机号码、车牌号码、邮箱、虚拟身份、imei、车架号,系统根据指定数据提取内容使用正则表达式效验数据中是否包含指定格式数据,检测到指定格式数据,进行内容提取。
进一步优化技术方案,用户指定需要数据比对的字段,指定比对的类型,包括身份证类型、手机号类型、车牌号类型,系统使用http协议将待比对的数据和比对类型发送到指定的url,效验数据是否命中,系统记录比对命中的数据。
进一步优化技术方案,对非格式化的文本数据,用户指定待提取实体的字段,系统在指定文本数据中提取实体信息包括姓名、地点、时间、组织实体,并记录实体之间的关系。
进一步优化技术方案,对非格式化的文本数据,用户指定待提取实体的字段,系统在指定文本数据中提取实体信息包括姓名、地点、时间、组织实体,并记录实体之间的关系。
进一步优化技术方案,对图像类的图像数据,用户指定待分类的字段,指定分类提取目标,目标包括涉黄、涉毒、涉爆、涉敏感,系统基于tensorflow框架使用ssd模型预训练相关物品识别分类模型,根据输入的图片信息使用预训练模型进行预测,系统记录涉重点分类图片。
进一步优化技术方案,所述步骤s4中,抽取规则包括增量抽取、全量抽取和实时抽取,指定抽取规则为实时抽取,自动失效定时任务,需要用户手动停止实时抽取任务。
进一步优化技术方案,所述步骤s9中,数据汇聚融合使用批量插入的方式向中间库中插入数据,遇到唯一性错误,系统修改数据插入方式为单条插入,再次遇到插入错误,更新重复数据版本号后,再次插入数据。
由于采用了以上技术方案,本发明所取得技术进步如下:
本发明主要应用于如何通过对不同数据源的访问方式进行归纳总结,对访问方式相近的数据源进行统一包装,将数量繁多的数据源包装为少量具有统一访问方式的数据源访问接口,采用插件的方式对不同异构数据源的数据进行提取,能够根据需要对不同类型数据源的提取进行横向扩展,采用配置的方式抽取不同数据源的数据,解决数据抽取工作重复开发的问题;同时本发明能够根据预先配置的规则对数据进行二次处理,并记录处理后的结果,方便运维人员及时发现数据质量问题,能够快速响应需求变化,通过配置的数据比对规则和数据提取规则等满足侦查研判中和重点人员进行比对的要求,建立重点实体库、发现犯罪实体之间的关系,找出涉黄、涉爆、涉毒的重点物品等。本发明通过配置统一的中间库能够临时存储已抽取的数据能够根据时间键和主键去除重复数据,防止任务失败时抽取大量重复的数据。同时本发明依托时间节点的方式能够在多源异构数据汇聚任务完成后判断对账数据是否一致,并及时通知运维人员,防止由于程序bug和人为因素造成的数据丢失。
本发明基于大数据、微服务等新技术,充分利用微服务架构体系的优势,通过插件开发、独立部署的模式,构建基于统一访问方式的多源异构数据汇聚融合方式,通过对不同类型数据源数据的汇聚,为政府部门,执法部门、企事业单位提供快速构建数据仓库的应用场景。
附图说明
图1为本发明实施例提供的多源异构数据融合汇聚方法的流程图。
具体实施方式
下面将结合附图和具体实施例对本发明进行进一步详细说明。
参见图1所示,本实施例提供的多源异构数据融合汇聚方法,包括以下具体步骤:
s1、分类归纳数据源类型,其中包括关系性数据源,非关系性数据源,文件类数据源,关系性数据源;
s2、对访问方式相近的数据源进行统一包装,将数量繁多的数据源包装为少量具有统一访问方式的数据源访问接口,访问接口大致分为关系型数据接口、非关系型数据接口、文件型数据接口三大类接口插件;
此步骤中,访问接口插件类型包括关系型数据接口、非关系型数据接口、文件型数据接口、实时队列数据获取插件,实时队列数据获取插件能够获取kafka、redis、activemq等队列的数据,数据源类型包括,oracle、mysql、postgre、sybase、mogodb、hbase、elasticsearch、本地文件、hdfs、ftp;
s3、根据不同类型接口对外提供相关配置信息,包括数据源类型、数据源的地址、数据源账密、数据格式、数据处理方式、任务名;
此步骤s3中数据格式包括表类型和文件类型,表类型描述包括表中文名、表英文名、字段中文名、字段英文名;文件类型描述包括文件列分割符、行分隔符、列含义。数据处理方式包括数据清洗、数据质量效验、核心数据提取、数据比对、数据对标、文本实体识别、图像重点物品分类。配置数汇聚融合任务时,数据处理方式的顺序为数据质量效验、数据清洗、数据对标、核心数据提取、数据比对、文本实体识别、图像重点物品分类。数据质量效验为对源头数据的质量合规性做检查,用户选定源头数据的格式,系统会根据预定义的格式采用正则表达式的方式确定源头数据是否符合要求,不符合要求的数据直接丢弃,系统记录丢弃数据日志,同时记录丢弃原因。数据清洗是在数据质量效验数据符合要求,对数据进一步处理,用户指定数据清洗规则,清洗规则包括截取、合并、拆分。数据清洗是在数据质量效验数据符合要求,对数据进一步处理,用户指定数据清洗规则,清洗规则包括截取、合并、拆分。用户指定需要对标的字段,系统根据数据清洗后的字段与系统标识库中的字典进行比对,替换原始数据为标准字典数据。用户指定需要数据提取的字段,指定需要提取的数据内容,包括身份证件、手机号码、车牌号码、邮箱、虚拟身份、imei、车架号,系统根据指定数据提取内容使用正则表达式效验数据中是否包含指定格式数据,检测到指定格式数据,进行内容提取。用户指定需要数据比对的字段,指定比对的类型,包括身份证类型、手机号类型、车牌号类型,系统使用http协议将待比对的数据和比对类型发送到指定的url,效验数据是否命中,系统记录比对命中的数据。对非格式化的文本数据,用户指定待提取实体的字段,系统在指定文本数据中提取实体信息包括姓名、地点、时间、组织实体,并记录实体之间的关系。对非格式化的文本数据,用户指定待提取实体的字段,系统在指定文本数据中提取实体信息包括姓名、地点、时间、组织实体,并记录实体之间的关系。对图像类的图像数据,用户指定待分类的字段,指定分类提取目标,目标包括涉黄、涉毒、涉爆、涉敏感,系统基于tensorflow框架使用ssd模型预训练相关物品识别分类模型,根据输入的图片信息使用预训练模型进行预测,系统记录涉重点分类图片。
s4、定义数据抽取的时间规则,规则包括时间规则和抽取规则,时间规则包括年,月,周,日,时,分,秒;抽取规则包括增量抽取和全量抽取;
在此步骤中,抽取规则包括增量抽取、全量抽取和实时抽取,指定抽取规则为实时抽取,自动失效定时任务,需要用户手动停止实时抽取任务;
s5、根据配置文件和数据抽取规则生成数据抽取任务;
s6、数据抽取任务在所有部署数据源接口插件的主机的列表内,选择资源利用率最低主机来执行数据抽取任务;
s7、数据抽取任务抽取的数据需要先抽取到中间库
s8、数据抽取到中间库的过程中,数据抽取任务根据数据主键确定数据是否唯一存在;
s9、数据抽取任务发现本条数据不唯一,对上一条重复数据的版本号修改为数据插入时间和主键组合的唯一值;
此步骤中,数据汇聚融合使用批量插入的方式向中间库中插入数据,遇到唯一性错误,系统修改数据插入方式为单条插入,再次遇到插入错误,更新重复数据版本号后,再次插入数据。
s10、数据抽取任务发现本条数据不重复,则直接插入本条数据,将数据的版本号标记为01,同时记录数据插入时间;
s11、将中间库中不同来源的数据抽取到目标库中,并将版本不为01的数据抽取到目标库对应的历史数据表中;
s12、根据数据抽取任务的开始时间和截止时间统计来源数据的数据总量和目标数据的数据总量,根据数据总量确定数据抽取任务是否执行成功。
以上实施例仅为充分公开而非限制本发明,凡基于本发明的创作主旨、无需经过创造性劳动即可等到的等效技术特征的替换,应当视为本申请揭露的范围。
- 还没有人留言评论。精彩留言会获得点赞!