本发明属于人脸动态表情识别领域,尤其涉及一种基于人脸特征点数据增强的动态表情识别方法。
背景技术:
面部表情识别(facialexpressionrecognition),以下简称fer。
面部表情的研究始于19世纪。1872年,达尔文在他著名的论著《人类和动物的表情(theexpressionoftheemotionsinanimalsandman,1872)》中阐述了人的面部表情和动物的面部表情之间的联系和区别。1971年,ekman和friesen对现代人脸表情识别做了开创性的工作,他们研究了人类的6种基本表情(即高兴、悲伤、惊讶、恐惧、愤怒、厌恶),确定识别对象的类别,并系统地建立了由上千幅不同表情组成的人脸表情图像数据库,细致的描述了每一种表情所对应的面部变化,包括眉毛、眼睛、嘴唇等等是如何变化的。1978年,suwa等人对一段人脸视频动画进行了人脸表情识别的最初尝试,提出了在图像序列中进行面部表情自动分析。20世纪90年代开始,由k.mase和a.pentland使用光流来判断肌肉运动的主要方向,使用提出的光流法进行面部表情识别之后,自动面部表情识别进入了新的时期。
在发展过程中,fer从传统的静态图像识别扩展到动态序列识别。特征提取也由传统的方法扩展到深度学习方法。识别准确度也因此越来越高。但也越发突显出一个问题,数据不足。针对静态图像识别,单一帧的数据增强方法已经很完善,但针对动态序列,由于其在时空上连续的特性,如果直接在序列中加入某一帧图片,会使其前后不连续,所以增强动态序列的表情数据也逐渐走入大家视野。
技术实现要素:
为解决以上现有技术的问题,本发明提出了一种基于人脸特征点数据增强的动态表情识别方法,该方法包括:实时获取人脸数据,将获取的人脸数据输入到训练好的3cnn模型中,得到该人脸动态表情识别结果;所述训练好的3cnn模型的获取包括:获取原始人脸数据集,对原始人脸数据集进行预处理,得到人脸数据训练集;将人脸数据训练集输入到构建好的3cnn模型中进行模型训练,得到训练好的3cnn模型;
所述得到人脸数据训练集的过程包括:
s1:对获取的原始人脸数据集进行人脸对齐以及面部特征点标记处理;
s2:选择面部特征变化大的特征点;
s3:根据选择的特征点构建轨迹矩阵;将各个轨迹矩阵进行组合,得到原始轨迹图;
s4:采用随机因子对轨迹矩阵进行微调处理,得到新的轨迹矩阵;将新的轨迹矩阵进行组合,得到新的轨迹图,将原始人脸数据集、原始轨迹图和新的轨迹图作为人脸数据训练集。
优选的,对获取的原始人脸数据集进行人脸对齐以及面部特征点标记处理过程包括:
s11:采用viola-jones人脸检测算法对原始人脸数据集进行人脸检测;对检测后的人脸数据进行去背景以及去除非面部区域处理,得到人脸边界框;
s12:根据人脸边界框对原始人脸数据集中的动态序列的每一帧图像进行裁剪,得到面部区域;
s13:对得到的面部区域进行几何归一化处理,得到新的面部区域;
s14:对新的面部区域的特征点进行标记,得到具有特征点的图像;将各个特征点的位置坐标进行保存。
优选的,选择面部特征变化大的特征点的过程包括:
s21:将特征点图像的各个特征点划分为眉毛、眼睛、鼻子以及嘴四组;
s22:分别计算相同组内的各个特征点变化量;
s23:选择各个组中特征变化量大的特征点。
进一步的,计算相同组内的各个特征点变化量的公式为:
优选的,构建轨迹矩阵与原始轨迹图的过程包括:
s31:对获取的特征点进行编号处理,用(x,y)表示图像中特征点的位置坐标,即特征点a1的坐标为a1(x1,y1)a1(x2,y2)…a1(xm,ym),其中(x,y)的下标表示图像的帧,m表示峰值帧在动态序列的第m帧;
s32:根据每个特征点的坐标计算每个特征点的偏移量;
s33:根据各个特征点的偏移量计算轨迹矩阵的斜率k;
s34:根据斜率k求出轨迹矩阵;
s35:将求出的轨迹矩阵进行组合,得到原始轨迹图。
优选的,对轨迹矩阵进行微调处理的过程包括:
s41:定义随机因子为(a,b),其中a,b均为随机生成的且满足均值为0、方差为1的标准正态分布的小数;
s42:采用随机因子对各个特征点的坐标进行微调;
s43:根据微调后的特征点坐标重新计算新的斜率,根据新斜率求出新的轨迹矩阵;
s44:将求出的新轨迹矩阵进行组合,得到新的轨迹图。
优选的,3cnn模型包括:3个训练不同数据的卷积神经网络层以及1个分类层。
进一步的,第一卷积神经网络层和第二卷积神经网络层用于提取静态图像的面部表情特征;第三卷积神经网络层用于提取特征点随表情变化的变化特征;分类层用于将三个神经网络提取的特征进行合并以及表情分类处理。
优选的,进行模型训练的过程包括:
步骤1:将训练集中的初始帧经灰度归一化处理后输入到3cnn模型的第一卷积神经网络层中;初始帧图像依次经过卷积层、卷积层、池化层、卷积层、池化层、卷积层以及池化层,得到特征信息;将提取的特征信息转化为一维向量;
步骤2:将训练集中的峰值帧经灰度归一化处理后输入到3cnn模型的第二卷积神经网络层中;峰值帧图像依次经过卷积层、卷积层、池化层、卷积层、池化层、卷积层以及池化层,得到特征信息;将提取的特征信息转化为一维向量;
步骤3:将训练集中的轨迹图输入到3cnn模型的第三卷积神经网络层中;输入的轨迹图经过编码层,使数据范围调整到[0,1]之间,将调整后的轨迹图依次经过卷积层、卷积层、池化层、卷积层、池化层、卷积层以及池化层,得到特征信息;将提取的特征信息转化为一维向量;
步骤4:将步骤1、步骤2以及步骤3输出的一维向量进行合并处理,将合并后的数据输入到分类层中,预测表情;
步骤5:将预测的表情与实际标签进行对比,通过误差反向传播算法不断训练3cnn模型,完成模型的训练。
本发明通过对原始的人脸数据进行增强处理,增加了样本数量,使得在训练卷积神经网络模型时有足够的数据对模型进训练,保证了最终得到的识别结果更精确;本发明通过对卷积神经网络模型进行优化处理,即采用多个卷积神经网络模型对数据分别进行静态特征提取和动态特征提取,再将提取的特征进行合并,使卷积神经网络模型在进行模型训练时,训练的结果更精确。
附图说明
图1为本发明的动态表情识别方法整体系统的流程图;
图2为本发明的3cnn网络模型示意图;
图3为本发明的特征点微调前后的对比图;
图4为本发明的cnn的网络结构及数据流大小。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将结合附图,对本发明实施例中的技术方案进行清楚、完整地描述,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在不付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
将人脸表情分成7个类别,分别为:0-生气、1-厌恶、2-害怕、3-高兴、4-伤心、5-惊讶、6-中性。由于数字编码之间存在天然的大小关系,会迫使模型学习这种不必要的约束,造成模型训练误差。为消除此种误差,本文中的标签采用onehot编码;选取初始表情到峰值表情之间7帧表情程度逐渐增强的图像,将该7帧图像构成一个动态表情类别中的一个样本;将经过多个相同表情类别选取的样本组成一个表情类别的训练数据,并给定标签;将训练数据中的人脸尺寸归一化到48*48像素大小。
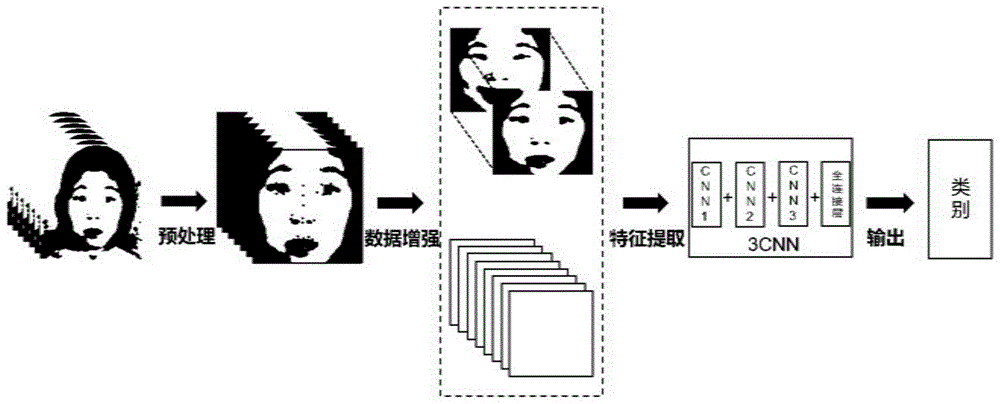
一种基于人脸特征点数据增强的动态表情识别方法,如图1所示,该方法包括:实时获取人脸数据,将获取的人脸数据输入到训练好的3cnn模型中,得到该人脸动态表情识别结果;所述训练好的3cnn模型的获取包括:获取原始人脸数据集,对原始人脸数据集进行预处理,得到人脸数据训练集;所述人脸数据训练集包括原始人脸数据集、原始轨迹图和新的轨迹图;将人脸数据训练集输入到构建好的3cnn模型中进行模型训练,得到训练好的3cnn模型;其中,3cnn表示三个联合的卷积神经网络。
所述进行模型训练时,将原始人脸数据集中的表情数据和其对应的一个轨迹图输入到模型中进行模型的单次训练。多个轨迹图与一个表情数据对应,组成了多次模型训练。
对原始人脸数据集进行预处理,增加了训练样本,提高了人脸动态表情识别的精度。
对原始人脸数据集进行预处理的过程包括:
s1:对获取的原始人脸数据集进行人脸对齐以及面部特征点标记处理;
s11:人脸对齐;采用opencv中基于viola-jones人脸检测算法进行人脸检测。通过使用opencv加载haar分类器,读入动态序列解码后的7帧图像,调用haar函数对人脸进行检测,得到人脸边界框。所述得到人脸边界框包括:对检测后的人脸数据进行去背景以及去除非面部区域处理。
s12:根据人脸边界框对原始人脸数据集中的动态序列的每一帧图像进行裁剪,得到面部区域;将剪裁后的图像重新缩放为48*48。
s13:对得到的面部区域进行几何归一化处理,得到新的面部区域。
所述几何归一化处理包括:选取人脸关键部位,如眼睛、鼻子、嘴巴等,使用仿射映射将人脸的面部特征进行统一标准。
s14:基于步骤s13的处理结果,读取数据源中的每一帧图像,使用python中的dlib库官方训练好的模型进行特征点标记,得到标记有特征点的图像,并将各个特征点的位置坐标保存。
优选的,人脸的特征点数量为68个。
s2:选择面部特征变化大的特征点。
s21:将特征点图像的各个特征点划分为眉毛、眼睛、鼻子以及嘴四组,组号分别为1,2,3,4;并计算各部位特征点比例。
优选的,由于面部外围轮廓在表情变化时变化不明显,因此将其17个特征点排除在外。在剩下的51个特征点中,眼睛、眉毛、鼻子、嘴唇上各有12、10、9、20个特征点,比例近似为1:1:1:2。
s22:分别计算相同组内的各个特征点变化量。
计算相同组内的各个特征点变化量的公式为:
其中,dpq表示第p组的第q个特征点的各帧与第一帧的位置差异之和,pq表示第p组的第q个特征点,i表示第i帧图像,j表示第j帧图像,表示第p组的第q个特征点在第j帧图像中的位置横坐标,表示第p组的第q个特征点在第j帧图像中的位置纵坐标。
s23:选择各个组中特征变化量大的特征点;所述选择各组中的特征点的比例为眉毛:眼睛:鼻子:嘴=1:1:1:2。
优选的,根据步骤s21各部位特征点比例对人脸特征点进行选取,选取的人脸特征点的个数为30,即选取的特征点包括前6个眉毛特征点、前6个眼睛特征点、前6个鼻子特征点以及前12个嘴巴特征点。
s3:根据选择的特征点构建轨迹矩阵;将各个轨迹矩阵进行组合,得到原始轨迹图。
s31:对获取的特征点进行编号处理,所述特征点在图像中的位置坐标用(x,y)表示,即特征点a1的坐标就是a1(x1,y1)a1(x2,y2)…a1(x7,y7),其中(x,y)的下标表示图像的帧。
进行编号处理的过程为:按照特征点在人脸的部位将30个变化较大的特征点进行编号,所述编号为:a1,a2…a30;其中a1~a6表示眉毛、a7~a12表示眼睛、a13~a18表示鼻子、a19~a30表示嘴巴。优选的,对上述每组特征点的编号都按照其在面部从左到右的扫描顺序进行编号。
s32:根据每个特征点的坐标计算相应特征点的偏移量;其中偏移量为特征点在两帧图像中的坐标变化量;计算公式为:
其中,i表示第i帧图像,j表示第j帧图像,o表示第o个特征点,表示特征点o的横坐标变化量,表示特征点o的纵坐标变化量。上述表达式中求出的是特征点ao的第i帧图像和第j帧图像的偏移量
s33:根据各个特征点的偏移量计算轨迹矩阵的斜率k。
所述斜率表示两点之间连线的倾斜程度;因此斜率中隐含特征点的变化特征;计算公式为:
其中,表示两点之间的斜率。
对于斜率不存在和斜率无穷大的两种情况,将0作为斜率不存在时的k值,将∞作为斜率无穷大时的k值。特别说明:在第三个卷积网络的编码层阶段-∞会转化为0,+∞会转化为1。
s34:根据斜率k求出轨迹矩阵。
轨迹矩阵的大小为7×7,并且主对角线上的值都为0;轨迹矩阵记录了特征点每两帧图像之间(包括同一帧图像之间)的斜率。轨迹矩阵样式如下:
其中,o表示的是第o个特征点,轨迹矩阵符号定义为m。
s35:将求出的轨迹矩阵进行组合,得到原始轨迹图。
由于人脸数据集中包含30个特征点,所以得到30个轨迹矩阵,将这30个轨迹矩阵按照一定的顺序组合成一个矩阵。
组合方式包括:将代表眉毛的所有轨迹矩阵作为新矩阵的第一行元素,其中30个特征点轨迹矩阵中包含6个眉毛特征点轨迹矩阵;将代表眼睛的所有轨迹矩阵作为新矩阵的第二行元素,其中30个特征点轨迹矩阵中包含6个眼睛特征点轨迹矩阵;将代表鼻子的所有轨迹矩阵作为新矩阵的第三行元素,其中30个特征点轨迹矩阵中包含6个鼻子特征点轨迹矩阵;将剩余的12个嘴特征点轨迹矩阵平均分为两部分,其中一部分作为新矩阵的第四行元素,另一部分作为新矩阵的第五行元素;所述新矩阵的每一行元素的排列顺序均为该组特征按从左到右扫描的顺序进行排列。
组合的结果为:
其中,m1~m6表示眉毛特征点轨迹矩阵,m7~m12表示眼睛特征点轨迹矩阵,m13~m18表示鼻子特征点轨迹矩阵,m19~m30表示嘴特征点轨迹矩阵,组合后的轨迹矩阵大小为[35,42],命名为轨迹图,符号定义为g。
所述轨迹矩阵中的每一条数据记录的是特征点每两帧的变化,即轨迹矩阵记录了特征点伴随表情变化而变化的信息,因此轨迹图可以近似代表人脸表情变化。
s4:采用随机因子对轨迹矩阵进行微调处理,得到新的轨迹矩阵,将新的轨迹矩阵进行组合,得到新的轨迹图,将原始人脸数据集、原始轨迹图和新的轨迹图作为人脸数据训练集。
s41:定义的随机因子为(a,b),其中a,b均为随机生成的且满足均值为0、方差为1的标准正态分布的小数。
s42:采用随机因子对各个特征点的坐标进行微调;微调特征点坐标的计算公式为:
其中,i表示第i帧图像,o表示的是第o个特征点,表示对横坐标进行微调的值,表示对纵坐标进行微调的值。上述表达式中求出的是特征点ao在第i帧图像中经过微调后的坐标,其中初始帧和峰值帧特征点的位置不做修改。修改后特征点的坐标为:
ao(x1,y1)a2(x2+a2,y2+b2)…ao(x6+a6,y6+b6)ao(x7,y7)
s43:根据微调后的特征点坐标重新计算新的斜率,根据新斜率求出新的轨迹矩阵。
如图3所示,通过对出现的特征点进行微调处理,微调后特征点的变化轨迹与微调前的变化轨迹相比有一定的变化,但是变化在合理的范围之内;所述合理范围包括:微调后的特征点变化轨迹满足面部表情动作合理性。
s44:重复步骤s41、步骤s42以及步骤s43;由于随机因子是随机的,通过随机因子微调特征点坐标可以得到大量的轨迹图。所述轨迹图的符号用gt表示,t表示第t个轨迹图。
通过采用步骤s4的方法对数据进行处理,可以大幅度增加所有表情样本的特征变化轨迹数据,相当于一组表情样本对应了多组变化轨迹,为后续深度神经网络模型的训练解决了数据不足的问题。如图2所示,所述神经网络模型包括:3个训练不同数据的卷积神经网络模型以及1个分类层。3个卷积神经网络模型单次训练的数据是一组表情数据和其对应的一个轨迹图。其中,第一个卷积神经网络模型提取初始帧所包含的表情静态特征;第二卷积神经网络模型提取峰值帧所包含的表情静态特征;第三卷积神经网络模型提取表情的动态特征;合并静态特征和动态特征,使模型能更加精确的识别人脸动态表情;从而达到更好的训练效果。
如图4所示,第一卷积神经网络的结构依次为核为1*1的卷积层1,步长为1;核为5*5的卷积层2,步长为1,并在卷积前填充2层0像素;核为3*3的池化层1,步长为2;核为3*3的卷积层3,步长为1,并在卷积前填充1层0像素;核为3*3的池化层2,步长为2;核为5*5的卷积层4,步长为1,并在卷积前填充2层0像素;核为3*3的池化层3,步长为2。在所有层中核的个数均为32;池化层均采取最大池化策略。输入数据是大小为48*48的某一类型表情的初始帧,提取初始帧的表面信息;输出数据是大小为[800,1]的一维向量。
第二卷积神经网络结构与第一神经网络结构相同。输入数据是大小为48*48的某一类型表情的峰值帧,提取峰值帧的表面信息;输出数据是大小为[800,1]的一维向量。
优选的,初始帧与峰值帧在作为网络输入数据之前,其灰度值先归一化为[0,1]。
第三卷积神经网络结构依次为:使用sigmoid函数的编码层,该编码层的作用是将数据范围调整到[0,1]之间;32个核为1*1的卷积层1,步长为1;32个核为5*5的卷积层2,步长为1,并在卷积前填充2层0像素;32个核为3*3的池化层1,步长为2;32个核为3*3的卷积层3,步长为1,并在数据进行卷积前填充1层0像素;32个核为3*3的池化层2,步长为2;64个核为5*5的卷积层4,步长为1,并在数据进行卷积前填充2层0像素;64个核为3*3的池化层3,步长为2。池化层均采取最大池化策略。输入数据为轨迹图,用以提取特征点的变化特征;输出数据是大小为[768,1]的一维向量。
分类层包括4个全连接层,所述4个连接层包括2368个神经元的第一全连接层、1024个神经元的第二全连接层、512个神经元的第三全连接层以及7个神经元的softmax层。
进行卷积神经网络模型训练的过程包括:
将输入神经网络进行模型训练的人脸数据训练集分为三个部分:初始帧、峰值帧和轨迹图。初始帧和峰值帧分别代表一个动态表情的开始和结束;轨迹图刻画的是动态表情的中间过程。固定了动态表情的开始和结束,采用不同的轨迹图来表示中间的动态过程,代表了一个表情的多种实现方式,即一个人从面无表情到微笑,中间转变的过程中多种多样,面部表情变化也有多种多样。
步骤1:将训练集中的初始帧经灰度归一化为[0,1]后输入到3cnn模型的第一卷积神经网络层中;初始帧图像依次经过卷积层、卷积层、池化层、卷积层、池化层、卷积层以及池化层,得到特征信息;池化层均采取最大池化策略。输入的初始帧图像大小为48*48,提取初始帧的表面信息;输出大小为[800,1]的一维向量。
步骤2:将训练集中的峰值帧经灰度归一化为[0,1]后输入到3cnn模型的第二卷积神经网络层中;峰值帧图像依次经过卷积层、卷积层、池化层、卷积层、池化层、卷积层以及池化层,得到特征信息;将提取的特征信息转化为一维向量。输入的峰值帧图像大小为48*48,提取峰值帧的表面信息;输出大小为[800,1]的一维向量。
步骤3:将训练集中的轨迹图输入到3cnn模型的第三卷积神经网络层中;输入的轨迹图经过编码层,将数据范围调整到[0,1]之间,将调整后的数据依次经过卷积层、卷积层、池化层、卷积层、池化层、卷积层以及池化层,得到特征信息;将提取的特征信息转化为一维向量。池化层均采取最大池化策略。输入数据为轨迹图,用以提取特征点的变化特征;输出大小为[768,1]一维向量。
步骤4:将步骤1、步骤2以及步骤3输出的一维向量合并成一个新的一维向量,符号定义为z,大小为[2368,1],合并后的向量可表示出特征点的变化特征和表情外观特征与表情种类之间的关系。
步骤5:将合并后的新的一维向量输入到分类层中,得到7种动态表情的概率,对得到的概率进行sampling操作,找出概率最大值,并设为1,其他均为0,输出为7种可能性结果,该结果为最终预测的表情。所述输出的结果包括:[predict]=[1,0,0,0,0,0,0]或[0,1,0,0,0,0,0]或[0,0,1,0,0,0,0]或[0,0,0,1,0,0,0]或[0,0,0,0,1,0,0]或[0,0,0,0,0,1,0]或[0,0,0,0,0,0,1]。
步骤6:将预测的表情类别与实际标签进行对比,通过误差反向传播算法不断训练卷积神经网络模型;完成模型训练。
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。