一种基于视频识别的行为分析与微表情分析方法与流程
本发明涉及公共安全技术领域,具体涉及一种基于视频识别的行为分析与微表情分析方法。
背景技术:
行为分析由美国心理学家亨特提出,他的观点认为,心理学已由争论心理学是什么和是怎样的思辨时代进入了实验时代,心理学已走上了客观地研究人类行为的道路。心理学应当努力地描述和解释、预测和控制有机体对外在的,主要是社会环境的外显行为。他同其他的行为主义者一样,力求避免应用带有心灵色彩的术语。他认为“心理学”一词源自古希腊的“灵魂”一词,也就是所谓的“心灵”。所以他杜撰“人类行为学”一词来取代心理学;
而微表情相比于人类的行为来说,更加难以察觉,通常甚至清醒的作表情的人和观察者都察觉不到。在实验里,只有10%的人察觉到。比起人们有意识做出的表情,“微表情”更能体现人们真实的感受和动机。虽然人们会忽略“微表情”,但是人的大脑依然受其影响,改变对别人表情的理解。所以如果某人很自然地表现“高兴”的表情,且其中不含有“微表情”,就能断定这人是高兴的。但是如果其间有“嗤笑”的“微表情”闪现,就算你没有刻意去察觉,你会更倾向于认为这张“高兴”的面孔是“狡猾的”或“不可信的”。
另外,除了指短暂的表情外,微表情在应用上更倾向于指代那些被抑制的表情。譬如说在明显悲伤的情况下,某人表现出大部分悲痛的表情,嘴角却抑制不住地上翘。这时,这个人明显希望表现出悲伤的情绪,但是却不由自主的出现了微笑的微表情。由于自身理性的抑制,表现的不明显抑或较为短暂。类似这样的差异在微表情分析中更为常用。
在看守所、宾馆、会议室和车间等公共场所,人流较多,往往容易发生一些治安问题,而通过现场布置公安工作人员将消耗大量公安民警资源,目前大都采用视频监控,通过视频摄像头对监控区域的人物进行行为识别,判断人物行为,进行公共治安管理或者,但现有技术中通过视频流量画面获取人物行为和表情识别不够精确,成本往往较高,同时适配场景较少,无法适用多种场景。
因此,发明一种基于视频识别的行为分析与微表情分析方法很有必要。
技术实现要素:
为此,本发明提供一种基于视频识别的行为分析与微表情分析方法,通过设置获取行为事件信息样本和表情信息样本方法,以及识别行为事件信息和表情信息方法,从而基于视频识别行为分析与微表情分析,本发明方法识别通过建模工具建模得出相关行为时间信息和表情信息,相较于传统的通过视频流量画面获取,准确度较高,操作流程较为优化简洁,识别成本较低,并且系统设定较为灵活,增大了本发明适用场景范围,使用度较广,以解决现有技术中通过视频流量画面获取人物行为和表情,识别不够精确,成本往往较高,同时适配场景较少,无法适用多种场景的问题。
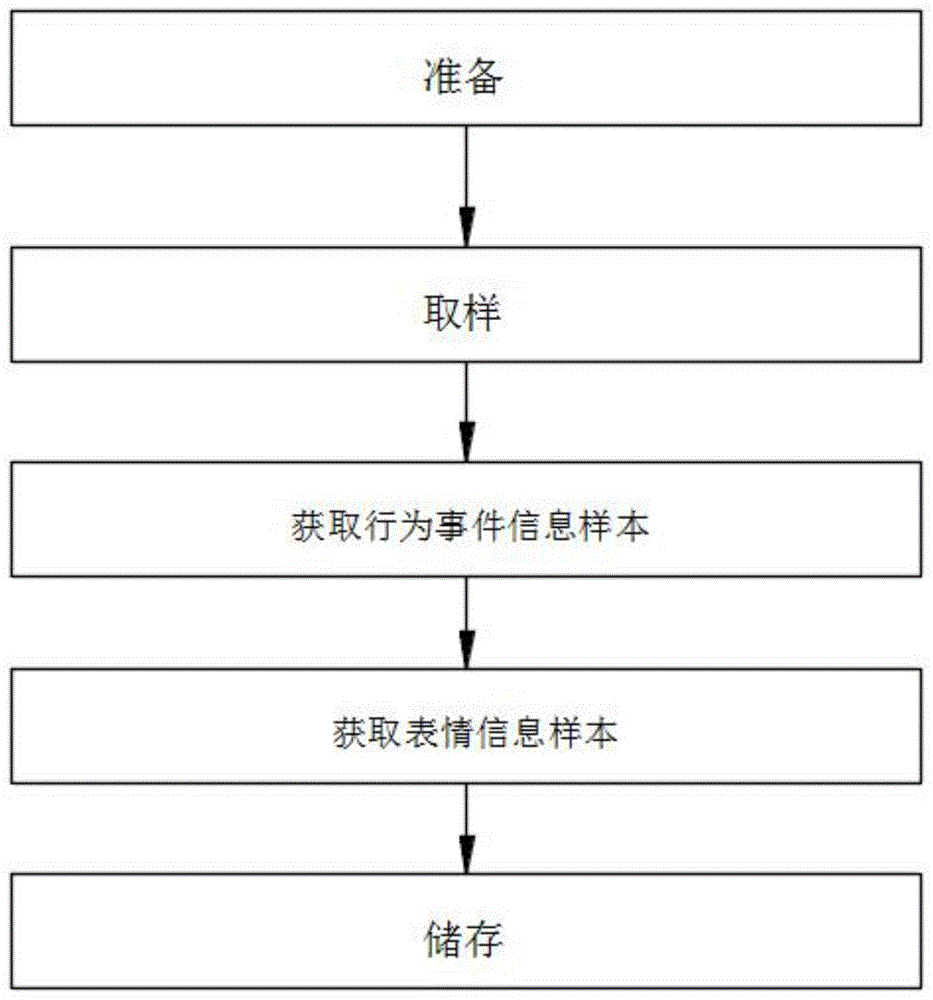
为了实现上述目的,本发明提供如下技术方案:一种基于视频识别的行为分析与微表情分析方法,包括以下获取行为事件信息样本和表情信息样本步骤:
s1,准备:布置安装取样摄像头;
s2,取样:提取摄像头拍摄的视频流量;
s3,获取行为事件信息样本:根据拍摄的视频流量中人物的肢体动作,通过建模工具进行行为规则建模,获得相应的行为事件信息样本;
s4,获取表情信息样本:根据拍摄的视频流量中人物的人脸,通过建模工具进行表情规则建模,获得相应的表情信息样本;
s5,储存:将获得的行为事件信息样本和表情信息样本储存至识别库中备用。
优选的,还包括以下识别行为事件信息和表情信息步骤:
a,准备:将摄像头安装到需要进行识别的区域场所;
b,取样:提取摄像头拍摄的视频流量;
c,行为事件信息比对:根据拍摄的视频流量中人物的肢体动作,通过建模工具进行行为规则建模,获得相应的行为事件信息,并与识别库中储存的行为事件信息样本进行比对;
d,表情信息比对:根据拍摄的视频流量中人物的人脸,通过建模工具进行表情规则建模,获得相应的表情信息,并与识别库中储存的表情信息样本进行比对;
e,判断:经过比对后得出对比结果,判断视频流量中人物是否进行特定行为事件或具有特定表情;
f,识别:结合对比出的行为事件信息和表情信息,判断识别人物心理状态;
g,报警:若识别的人物心理状态被判断为特定状态,立即通过服务器进行报警。
优选的,所述s3中行为事件信息样本中的行为事件包括:打架行为、倒地行为、求救行为、聚众行为、徘徊行为、滞留行为、攀爬行为、闯入行为、警戒行为、离岗行为、睡岗行为、缺岗行为、传递行为、逆行行为、离开行为、攀高行为、离床行为、独处行为、尾随行为和入厕超时。
优选的,所述建模工具为tensorflow或opencv。
优选的,所述s4中表情信息样本中的表情信息包括:哭泣、微笑、大笑、沮丧、悲伤、思考、冷酷、气愤、严肃、惊愕、痛苦和害怕。
优选的,所述需要进行识别的区域场包括:看守所、宾馆、会议室和车间。
优选的,所述心理状态包括:疲劳、紧张、轻松、忧伤、喜悦、抑郁、自杀和暴力等。
优选的,所述特定行为事件可根据实际使用场景下,从行为事件中挑选后再单独特定设置。
优选的,所述特定表情可根据实际使用场景下,从而表情信息中挑选后再单独设定。
优选的,所述特定心理状态可根据实际使用场景下,从心理状态中挑选后再单独设定。
本发明的有益效果是:
本发明通过设置由准备、取样、获取行为事件信息样本、获取表情信息样本和储存等步骤构成的获取行为事件信息样本和表情信息样本方法,以及由准备、取样、行为事件信息比对、表情信息比对、判断、识别和报警等步骤构成的识别行为事件信息和表情信息方法,从而基于视频识别行为分析与微表情分析,本发明方法识别通过建模工具建模得出相关行为时间信息和表情信息,相较于传统的通过视频流量画面获取,准确度较高,操作流程较为优化简洁,识别成本较低,并且系统设定较为灵活,增大了本发明适用场景范围,使用度较广。
附图说明
图1为本发明提供的获取行为事件信息样本和表情信息样本步骤基本框图;
图2为本发明提供的识别行为事件信息和表情信息步骤基本框图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
参照附图1-2,本发明提供的一种基于视频识别的行为分析与微表情分析方法,包括以下获取行为事件信息样本和表情信息样本步骤:
s1,准备:布置安装取样摄像头;
s2,取样:提取摄像头拍摄的视频流量;
s3,获取行为事件信息样本:根据拍摄的视频流量中人物的肢体动作,通过建模工具进行行为规则建模,获得相应的行为事件信息样本,行为事件包括:打架行为、倒地行为、求救行为、聚众行为、徘徊行为、滞留行为、攀爬行为、闯入行为、警戒行为、离岗行为、睡岗行为、缺岗行为、传递行为、逆行行为、离开行为、攀高行为、离床行为、独处行为、尾随行为和入厕超时;
s4,获取表情信息样本:根据拍摄的视频流量中人物的人脸,通过建模工具进行表情规则建模,获得相应的表情信息样本,表情信息包括:哭泣、微笑、大笑、沮丧、悲伤、思考、冷酷、气愤、严肃、惊愕、痛苦和害怕;
s5,储存:将获得的行为事件信息样本和表情信息样本储存至识别库中备用;
进一步地,还包括以下识别行为事件信息和表情信息步骤:
a,准备:将摄像头安装到需要进行识别的区域场所,需要进行识别的区域场包括:看守所、宾馆、会议室和车间;
b,取样:提取摄像头拍摄的视频流量;
c,行为事件信息比对:根据拍摄的视频流量中人物的肢体动作,通过建模工具进行行为规则建模,获得相应的行为事件信息,并与识别库中储存的行为事件信息样本进行比对;
d,表情信息比对:根据拍摄的视频流量中人物的人脸,通过建模工具进行表情规则建模,获得相应的表情信息,并与识别库中储存的表情信息样本进行比对;
e,判断:经过比对后得出对比结果,判断视频流量中人物是否进行特定行为事件或具有特定表情,所述特定行为事件可根据实际使用场景下,从行为事件中挑选后再单独特定设置,所述特定表情可根据实际使用场景下,从而表情信息中挑选后再单独设定;
f,识别:结合对比出的行为事件信息和表情信息,判断识别人物心理状态,所述心理状态包括:疲劳、紧张、轻松、忧伤、喜悦、抑郁、自杀和暴力等;
g,报警:若识别的人物心理状态被判断为特定状态,立即通过服务器进行报警,所述特定心理状态可根据实际使用场景下,从心理状态中挑选后再单独设定;
进一步地,所述建模工具为tensorflow或opencv,tensorflowtm是一个基于数据流编程的符号数学系统,被广泛应用于各类机器学习算法的编程实现,其前身是谷歌的神经网络算法库distbelief,opencv是一个基于bsd许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在linux、windows、android和macos操作系统上,它轻量级而且高效,由一系列c函数和少量c++类构成,同时提供了python、ruby、matlab等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法;
以上所述,仅是本发明的较佳实施例,任何熟悉本领域的技术人员均可能利用上述阐述的技术方案对本发明加以修改或将其修改为等同的技术方案。因此,依据本发明的技术方案所进行的任何简单修改或等同置换,尽属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!