使用相异训练源训练分类模型及应用其的推论引擎的制作方法
1.本发明是有关于训练包括神经网络的分类引擎,且特别是有关于一种应用于具有多个对象类别且分布不均匀的训练数据。
背景技术:
2.本部分讨论的主题不应仅由于在本部分中被提及而被认为是现有技术。类似地,本部分中提到的问题或与主题有关并提供作为技术背景的问题不应被认为是现有技术中提到的。本部分中的主题仅表示不同的方法,其本身也可以对应于实现所要求保护的技术。
3.深度神经网络是一种人工神经网络(ann),其使用多个非线性和复杂的转换层依次对高阶特征进行建模。深度神经网络通过后向传播提供反馈,其携带观察的和预测的输出之间的差异,以调整参数。随着大量训练数据集的可用性、平行和分布式计算的功能以及复杂的训练算法,深度神经网络已快速发展。深度神经网络促进了许多领域的重大进步,例如计算器视觉、语音识别和自然语言处理。
4.卷积神经网络(cnn)和递归神经网络(rnn)可以配置为深度神经网络。卷积神经网络通过包含卷积层、非线性层和池化层的架构,在影像辨识方面的应用很成功。递归神经网络被设计为通过在感知器、长短期记忆单元和门循环单元等区块之间建立循环连接来使用输入数据的顺序信息。此外,针对有限的背景信息还提出了许多其他新兴的深度神经网络,例如深度时空神经网络、多维递归神经网络和卷积自动编码器。
5.训练深度神经网络的目标是优化每一层的权重参数,其逐步将较简单的特征组合为复杂的特征,以便可以从数据中学习最合适的层次表示。优化程序的单一循环如下。首先,给定一训练数据集,通过前向传递依序计算每个层中的输出,并通过网络向前传播函数信号。在最终输出层中,目标损失函数测量推论的输出与给定标签之间的误差。为了使训练误差最小化,通过后向传递使用炼式规则后向传播误差信号,并计算整个神经网络中所有权重的梯度。最后,使用基于随机梯度下降的优化算法更新权重参数。批次梯度下降对每个完整数据集执行参数更新,而随机梯度下降可通过为每个小型数据集执行更新来提供随机近似值。目前有多种优化算法是根据随机梯度下降法所发展出来的。例如,adagrad和adam训练算法执行随机梯度下降,同时基于对每个参数分别进行更新频率和梯度矩,来适时地修改学习速率。
6.在机器学习中,包括ann的分类引擎是使用根据要被分类引擎识别的多个类别所标记的对象的数据库来训练。在某些数据库中,要识别的不同的每个类别中的对象数量可能有很大的差异。对象在类别中的不均匀分布可能会导致学习算法失衡,从而导致某些类别的对象识别的性能下降。解决此问题的一种方法是使用越来越大的训练集,以使失衡趋于平稳,或者包括足够数量的稀有类别的对象。这将导致这些庞大的训练集需要大量的计算资源才能应用于分类引擎的训练。
7.因此需要提供一种技术,使用大小合理的标记对象的数据库来改善分类引擎的训练。
技术实现要素:
8.本发明是有关于一种计算器实现的方法,该方法改善了用于训练包括人工神经网络的分类引擎的计算器实现技术。
9.根据本发明的一实施例,提出一种采用本文所述的技术,以通过在制造过程中检测并分类集成电路组件中的缺陷来改善集成电路的制造。
10.技术大致上包括迭代程序,其使用训练数据源训练ann模型或其他分类引擎模型,其中训练数据源可以包括多个对象,例如影像、音频数据、文字和其他类型的信息,其可以单独使用,也可以多种组合使用,这些对象可以使用大量的类别进行分类,而产生分布不均的情况。迭代程序包括从训练数据源中选择训练数据的小样本,使用该样本训练模型,在训练数据的较大样本上以使用模型的推论模式,以及检查推论结果。评估结果以确定模型是否令人满意,如果模型不符合指定的标准,则重复迭代程序中的采样、训练、推论和检查结果的循环(stir循环),直到满足标准为止。
11.本文描述的技术能够使用较小的训练数据源来训练复杂的分类引擎,并能够有效地使用计算资源,同时克服了由于依赖小型训练数据源而引起的不稳定性。
12.为了对本发明的上述及其他方面有更佳的了解,下文特举实施例,并配合附图详细说明如下:
附图说明
13.图1绘示本发明所述的迭代训练算法的简化图。
14.图2a、2b、2c、2d、2e、2f绘示依照本发明一实施例的迭代训练算法的各个阶段。
15.图3绘示类似于图2a至2f所示的迭代训练算法的一实施例的流程图。
16.图4a、4b、4c、4d、4e、4f绘示依照本发明另一实施例的迭代训练算法的各个阶段。
17.图5绘示类似于第4a至4f图所示的迭代训练算法的另一实施例的流程图。
18.图6包括示出训练源分类的表,该表用于解释在第一训练子集之后选择训练子集的技术。
19.图7a和7b绘示根据本发明用于选择训练子集的一替代技术的迭代训练算法的阶段。
20.图8绘示集成电路制造过程中使用如本发明所述的方法训练的分类引擎的简化图。
21.图9是由系统执行的计算器系统的图形用户接口的图像,该系统被配置为在初始阶段执行本发明所述的训练程序。
22.图10是由系统执行的计算器系统的图形用户接口的图像,该系统被配置为在后续阶段执行本发明所述的训练程序。
23.图11是计算器系统的简化方块图,该计算器系统被配置为执行本发明所述的训练程序。
24.【符号说明】
25.10~14,300~312,500~512:步骤
26.20:源数据集
27.60:处理站x
28.61:检查工具
29.62:处理站x+1
30.63:分类引擎(ann模型m)
31.600:对角区域
32.601,602:区域
33.1200:计算器系统
34.1210:储存子系统
35.1222:存储器子系统
36.1232:只读存储器
37.1234:随机存取存储器
38.1236:文件储存子系统
39.1238:用户接口输入设备
40.1255:总线子系统
41.1272:中央处理单元
42.1274:网络接口
43.1276:用户接口输出装置
44.1278:深度学习处理器(图形处理单元、现场可编程门阵列、粗粒度可重构架构)
45.s:源数据集
46.se1:第一评估子集
47.se2:第二评估子集
48.se(n+1),se(n+2):评估子集
49.st1:第一训练子集
50.st2:第二训练子集
51.st3:第三训练子集
52.st+,st-:物件
53.er1:第一错误子集
54.er2:第二错误子集
55.er3:第三错误子集
56.er(n),er(n+1):错误子集
57.b1~b4:区块
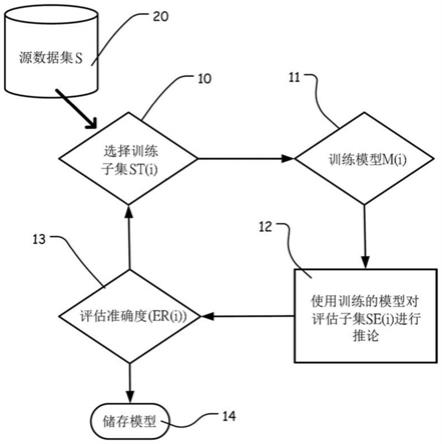
58.m1,m2,m3:模型
具体实施方式
59.第1至11图提供了对本技术的实施例的详细描述。
60.图1绘示一个处理循环(stir循环),其能够依靠小的训练源,以迭代方式学习每个现有循环中的错误。
61.在图1中,计算器系统存取一数据库,该数据库储存标记的训练对象的源数据集s 20,其可用于训练一分类引擎。该循环通过从数据集s中选择训练子集st(i)10开始,该训练子集st(i)10基本上小于整个数据集s(20)。计算器系统使用训练子集st(i)10训练模型m
(i)11,其包括分类引擎使用的参数和系数。接着,推论引擎使用模型m(i)11对源数据集s(20)的评估子集se(i)12中的对象进行分类。基于模型m(i)11评估推论结果,并在评估子集se(i)12中识别分类错误的对象的一错误子集er(i)13。然后,将错误子集er(i)13的大小和特性与预定参数进行比较,其表示模型m(i)11在分类的类别上的性能。如果模型m(i)11满足参数,则将其保存以供领域中的推论引擎使用(14)。如果模型m(i)11不满足参数,则循环返回以选择下一循环的训练子集。循环会迭代进行,直到满足参数并开发出最终模型为止。
62.图2a至2f绘示本发明所述的训练算法的各个阶段。在图2a中,存取部分的源数据集s以选择第一训练子集st(1),并且存取部分的源数据集s(不包括第一训练子集)以当作第一评估子集se(1)使用。第一训练子集st(1)可以是源数据集s的1%或更少。
63.使用st(1)产生模型m(1),并使用模型m(1)对第一评估子集se(1)中的对象进行分类。
64.如图2b所示,在第一评估子集中识别模型m(1)分类错误的对象的一错误子集er(1)。
65.如图2c所示,存取部分的错误子集er(1)以当作第二训练子集st(2)使用。st(2)可以包括部分或全部的错误子集er(1)。
66.使用st(1)和st(2)产生模型m(2),并使用模型m(2)对第二评估子集se(2)中(不包括st(1)和st(2))的对象进行分类。
67.如图2d所示,在第二评估子集中识别模型m(2)分类错误的对象的一错误子集er(2)。对于i=2的训练子集st(i),可以包括错误子集er(1)中不到一半的对象。
68.如图2e所示,存取部分的错误子集er(2)以当作第三训练子集st(3)使用。st(3)可以包括部分或全部的错误子集er(2)。
69.使用st(1)、st(2)和st(3)产生模型m(3),并使用模型m(3)对第三评估子集se(3)中(不包括st(1)、st(2)和st(3))的对象进行分类。
70.如图2f所示,在第三评估子集中识别模型m(3)分类错误的对象的一错误子集er(3)。在此实施例中,错误子集er(3)小,且模型m(3)可在领域中使用。此程序可以迭代地被执行,直到分类错误的比例达到满意点,例如小于10%或小于1%,可依据训练模型的使用而定。
71.图3是类似于图2a至2f所示的训练算法的流程图,其可在计算器系统中执行。
72.此算法开始于存取训练数据的源数据集s(300)。对于索引(i)=1的一第一循环,从集合s获取一训练子集st(1)(301)。使用训练子集st(1)训练一分类引擎的一模型m(1)(302)。接着,存取源数据集s的评估子集se(1)(303)。使用模型m(1)对评估子集进行分类,并在评估子集中识别模型m(1)分类错误的对象的一错误子集er(1)(304)。
73.在第一个循环之后,索引(i)递增(305),并且迭代的下一循环开始。下一循环包括选择训练子集st(i),该训练子集st(i)包括前一循环中的部分的错误子集er(i-1)(306)。接着,使用(i)从1到(i)的组合st(i)来训练模型m(i),其包括当前循环和所有现有循环的训练子集(307)。选择当前循环的一评估子集se(i),其不包括当前循环和所有现有循环的训练子集(308)。使用模型m(i),对评估子集se(i)进行分类,并识别当前循环的模型m(i)的错误子集er(i)(309)。通过一成功模型的预期参数,评估当前循环的错误子集er(i)(310)。如果评估满足条件(311),则储存当前循环的模型m(i)(312)。在步骤311,如果评估不满足
条件,则算法循环将返回至步骤305以递增索引(i),然后重复该循环,直到提供一最终模型为止。
74.图4a至4f绘示用于训练分类引擎的一可选的程序,该程序包括对源数据集进行分区的步骤。如图4a所示,源数据集s被分为区块b1至b4,其可以是源数据集s中对象的非重迭区块b1至b4。在一实施例中,源数据集s可以包括类别c1的10000个缺陷和类别c2的98个缺陷。可以按照在类别中保持相对数量的方式选择区块。如此,在此实施例中分为10个区块,每个区块中的选择的对象包括类别c1中大约10%的缺陷(大约100个)和类别c2中大约10%的缺陷(大约10个)。如果分布不均匀,则模型效能可能会下降。例如,如果一类别的对象在短时间间隔内出现,并且训练数据集中的对象仅按时间间隔进行分区,则该类别可能会不合理的分在一个区块或两个区块中。
75.图4b绘示存取第一区块b1的对象以提供第一训练子集st1,该第一训练子集st1所包含的对象远少于第一区块中的所有对象。使用第一训练子集st1来训练模型m1。st1可以仅包括训练数据集s的一小部分,例如小于1%。
76.如图4c所示,将第一模型m1应用于第一评估子集se1,该第一评估子集se1包括第二区块b2中的部分或全部的对象,以及在第一评估子集中se1中识别第一模型m1分类错误的对象的一第一错误子集er1。
77.图4d绘示从第一错误子集er1中的对象中选择第二训练子集st2,并与第一训练子集(箭头上的+表示)组合使用以开发模型m2。st2可以包括er1中的部分或全部的对象。
78.如图4e所示,将模型m2应用于第二评估子集se2,该第二评估子集se2包括第三区块b3中的部分或全部的对象。在第二评估子集se2中识别第二模型m2分类错误的对象的一第二错误子集er2。且,识别出第三训练子集st3,其包括第二错误子集er2中的部分或全部的对象。使用第一、第二和第三训练子集,训练第三模型m3。
79.如图4f所示,将第三模型m3应用于第三评估子集se3,该第三评估子集se3包括第四区块b4中的部分或全部的对象。识别出第三错误子集er3,该第三错误子集er3包括第三评估子集se3中模型m3分类错误的对象。在此实施例中,第三错误子集er3非常小,代表模型m3可以当作最终模型。
80.图5是类似于图4a至4f所示的训练算法的流程图,其可在计算器系统中执行。
81.此算法开始于存取训练数据的源数据集s,并将其分为非重迭区块b(i)(500)。对于索引(i)=1的第一循环,获取训练子集st(1),该训练子集st(1)包括来自区块b(i)的少量物件(501)。使用训练子集st(1)训练分类引擎的模型m(1)(502)。接着,获取评估子集se(1),该评估子集se(1)包括来自源数据集s的区块b2中的部分或全部的对象(503)。使用模型m(1)对评估子集se(1)进行分类,并在评估子集se(1)中识别模型m(1)分类错误的对象的一错误子集er(1)(504)。
82.在第一循环之后,索引(i)递增(505),并且迭代的下一循环开始。下一个循环包括选择一训练子集st(i),该训练子集st(i)包括前一循环中的部分的错误子集er(i-1)(506)。接着,使用(i)从1到(i)的组合st(i)来训练模型m(i),其包括当前循环和所有现有循环的训练子集(507)。选择当前循环的一评估子集se(i),其包括来自下一区块b(i+1)的部分或全部的对象,并且不包括当前循环和所有现有循环的训练子集(508)。使用模型m(i),对评估子集se(i)进行分类,并识别当前循环的模型m(i)的错误子集er(i)(509)。通过
一成功模型的预期参数,评估当前循环的错误子集er(i)(510)。如果评估满足条件(511),则储存当前循环的模型m(i)(512)。在步骤511,如果评估不满足条件,则算法循环将返回至步骤505以递增索引(i),然后重复该循环,直到提供一最终模型为止。
83.在上述两个可选方案中,选择初始训练子集st1,以使其比训练数据集s小很多。例如,可以将少于1%的训练数据集s用作初始训练子集st1,以训练第一模型m1。这具有提高训练程序效率的效果。初始训练子集的选择可以应用随机选择技术,以使训练子集中类别的对象的分布近似于源训练数据集s中的分布。但是,在某些情况下,训练数据集s包括多个类别的对象分布不均匀的情况。举例来说,具有类别c1至c9,其数据集s可能具有如下的对象分布:
84.c1:125600
85.c2:5680
86.c3:4008
87.c4:254
88.c5:56
89.c6:32
90.c7:14
91.c8:7
92.c9:2
93.在该分布下,使用类似于该分布的训练子集的训练算法仅能产生对前三个类别c1、c2和c3表现良好的模型。
94.为了提高效能,可以根据分布平衡程序选择初始训练子集。例如,选择初始训练子集的方法可为对要训练的类别设置参数。在一种方法中,参数可以包括每个类别中对象的最多数量。在此方法中,训练子集可以被限制为例如每个类别最多50个对象,如此一来,以上述的例子来说,类别c1至c5限制为50个对象,而类别c6至c9则保持不变。
95.另一个参数可以是每个类别中对象的最少数量,并与上面讨论的最多数量结合使用。例如,如果最小值设置为5,则类别c6至c8被包括在内,而类别c9被忽略。如此,该训练子集包括类别c1至c5中的各50个对象、类别c6中的32个对象、类别c7中的14个对象和类别c8中的7个对象,总共303个物件。值得注意的是,因为初始训练子集st1很小,所以可预期的,错误子集的大小相对较大。例如,模型m1的正确率可以约为60%。训练程序需要额外的训练数据来解决40%的错误分类。
96.可以设置一程序以选择第二训练子集st2,使得st1的50%>st2>st1的3%。类似地,对于第三训练子集,(st1+st2)的50%>st3>(st1+st2)的3%,依此类推使用3%到50%之间的相对大小的范围直到最终训练子集stn。
97.相对大小的范围建议在5%和20%之间。
98.额外的训练子集st2到stn中的对象也可以多种方式选择。在一实施例中,使用随机选择从对应的错误子集中选择额外的训练子集。在这种随机方法中,训练子集的大小和分布与其选择的错误子集的对象大小和对象分布一样。此方法的风险在于,在训练子集中某些类别的信号可能很小。
99.在另一种方法中,根据一类别感知程序选择对象。例如,训练子集可包括每个类别
中对象的最多数量。例如,一特定循环的最大值可能是每个类别20个对象,其中少于20个对象的类别则全部包含在内。
100.在另一种方法中,可以随机选择部分对象,而某些对象可以通过类别感知程序来选择。
101.图6绘示可以在计算器系统中使用的图形用户接口,该计算器系统被配置为如本发明所述在每个循环中进行训练以选择下一个训练子集。在接口中,显示一表格,该表格具有多个列,其对应至对象类别c1至c14的参考标准(ground truth)分类的计数,列「总数」为对应的行的总和,列「精确率」为推论引擎的测量精确率,其表示所有类别中正确分类的百分比,以及列「来源」表示用以形成推论引擎中的模型的训练数据源中对象的数量。此表格具有多个行,其对应至每个对象类别中推论引擎使用该模型分类的对象数量,行「总数」表示对应的列的对象总数,行「召回率」表示每个类别中正确分类的百分比。
102.因此,标记为c1的行正确地分类了946个对象、并将c2中的8个对象错误地分类为c1、c4中的3个对象错误地分类为c1、c5中的4个对象错误地分类为c1,依此类推。标记为c1的列显示946个c1对象被正确的分类、5个c1对象被分类为c2、4个c1物件被分类为c3、10个c1物件被分类为c4,依此类推。
103.对角区域600包括正确的分类。区域601和602包括错误子集。
104.此处的示例显示了几个循环之后的结果,此示例是使用具有1229个分类对象的训练源,其来自如上所述的多个循环的训练子集的组合,以产生模型,该模型对评估子集的1570个对象中的1436个对象进行正确的分类。因此,此阶段的错误子集相对较小(134个错误)。在更早的循环中,错误子集可能更大。
105.为了选择下一个训练子集,该程序可以从区域601和602中选择对象的随机组合。如此,要向1229个对象的训练子集中增加约5%的对象(62个对象),错误子集的大约一半(134/2=77个对象)可以被识别作为下一训练子集,并将其与来自现有循环的训练子集进行组合。当然,如果需要,可以更精确地选择对象的数量。
106.为了使用类别感知程序选择下一训练子集,本发明提供了两种可选的方法。
107.第一,如果模型的目的是在所有类别上提供更高的精确度,则可以将每一行中分类错误的对象数量(例如10个)包含在训练子集中,其中少于10个分类错误的对象要全部包含在训练子集中。此处的c10在该行中有2个分类错误的对象要包含在当前循环的训练子集中。
108.第二,如果模型的目的是在一特定类别上提供更高的召回率,则可以将每一列中分类错误的对象数量(例如10个)包含在训练子集中,其中少于10个分类错误的对象要全部包含在训练子集中。此处的c10在该列中有10个分类错误的对象要包含在当前循环的训练子集中。
109.在一方法中,随机选择方法被应用在第一及其他早期的循环,混合方法被应用在中间的循环,以及类别感知方法被应用在错误子集小的最后循环中。
110.在一些实施例中,可以应用如图7a及7b所示的方法。请参考图6,在表格中显示的示例中,类别c11至c14中的对象很少。模型稳定性可能很差,尤其是对于这些类别中的分类。因此,在选择一特定循环的训练子集时,可以将分类正确的对象(真阳性)增加到训练子集中。例如,为了达到10个对象数量的目标,此方法可以将类别c12的三个真阳性对象增加
到训练子集,将类别c13的两个真阳性对象增加到训练子集,并将类别c14的一个真阳性对象增加到训练子集。
111.图7a绘示一训练子集st(n+1)的选择,其是从一评估子集se(n+1)中使用模型m(n)所产生的一错误子集er(n)中选择,使用来自错误子集er(n)的部分的对象(st-)以及来自评估子集se(n+1)的部分的分类正确的对象(st+)。图7b绘示下一循环中使用的对象,训练子集st(n+2)是从一评估子集se(n+2)中使用模型m(n+1)所产生的一错误子集er(n+1)中选择,使用来自错误子集er(n+1)的部分的对象(st-)以及来自评估子集se(n+2)的部分的分类正确的对象(st+)。
112.在制造生产线中获取的机体电路组件上的缺陷影像可以被分为许多类别。对于一特定的制造过程,这些缺陷的数量差异很大,因此训练数据的分布不均匀,且包含的数据量大。本文描述的技术的一实施例可以用于训练一ann以识别和分类这些缺陷,进而改善制造过程。
113.缺陷存在多种类型,且具有相似形状的缺陷可能源于不同的缺陷来源。例如,如果缺陷影像的出现是由上一层或下一层的问题所造成的,则图案的一部分就不会在类别中出现。例如,当前层之后的层中可能存在例如嵌入缺陷或孔状裂痕之类的问题。但在不同类别的影像中消失的图案可能是当前层中出现的问题。因此,希望建立一种可以对所有类型的缺陷进行分类的神经网络模型。
114.我们需要监视在线过程中的缺陷,以评估在线产品的稳定性和质量,或制造工具的寿命。
115.图8绘示制造生产线的简化图,其包括处理站60、影像传感器61和处理站62的。在此生产线中,集成电路晶圆被输入到处理站x,并进行诸如沉积或蚀刻的处理,并输出到影像传感器61。从影像传感器将晶圆输入到处理站x+1,在此处进行诸如沉积、蚀刻或封装的处理。然后,将晶圆输出到下一阶段。来自影像传感器的影像被提供给分类引擎,该分类引擎包括根据本文描述的技术所训练的ann,其可识别并分类晶圆中的缺陷。分类引擎也可以接收制造过程中其他阶段的影像。具有影像传感器的检查工具61感测出的晶圆中关于缺陷的信息,该信息可以用于改善制造过程,例如通过调整在处理站x或在其他处理站执行的程序。
116.图9及10绘示由一计算器系统执行的一图形用户接口,该计算器系统被配置为执行本发明所述的训练程序。在图9中,在图形用户接口上显示五个区块。「原始数据库」区块包括类别列表以及每个类别中对象的数量。接口驱动程序可以通过分析训练数据集s自动在此区块增加数据。第二区块(第一资料提取)包括与每个类别关联的字段,其可以通过使用者直接输入或响应用于对应的错误子集的参数来增加此区块的资料,以设置在第一训练子集st1中每个类别要使用的对象数量。第三区块(第二资料提取)包括与每个类别关联的字段,其可以通过使用者直接输入或响应用于对应的错误子集的参数来增加此区块的资料,以设置在第二训练子集st2中每个类别要使用的对象数量。第四区块(第三资料提取)包括与每个类别关联的字段,其可以通过使用者直接输入或响应用于对应的错误子集的参数来增加此区块的资料,以设置在第三训练子集st3中每个类别要使用的对象数量。第五区块(请选择计算模型)包括一个下拉选单,用于选择哪一种ann结构的模型要被训练,此处显示了一个名为「cnn」的示例。图形用户接口还包括「执行」的按钮部件,当选择该按钮部件时,
将使用通过界面提供的参数来执行此程序。
117.图10绘示图9的图形用户接口,其中第二至第四区块的内容被填入,在此示例中,第二至第四区块的内容对应于在后续循环中使用的训练数据,包括训练子集st1、st2和st3的组合。
118.本文描述了由配置为执行训练程序的一计算器所执行的多个流程图。这些流程可使用处理器编程来实现,该处理器通过储存在可由计算器系统存取的存储器的计算器程序来编程,且可由处理器、包括现场可编成集成电路的专用逻辑硬件、以及专用逻辑硬件和计算器程序的组合所执行。对于本文中的所有流程图,可理解的是,在不影响所实现的功能的情况下,步骤可以组合、平行执行或以不同顺序执行。在某些情况下,如读者所理解的,若仅进行某些其他更改的情况下,步骤的重新安排也可以获得相同的结果。在其他情况下,如读者所理解的,若仅满足某些条件时,步骤的重新安排才能实现相同的结果。此外,应当理解的是,本文的流程图仅示出了与理解本发明有关的步骤,且应理解的是,可以在本文示出的步骤之前、之后和之间执行多个额外步骤用于完成其他功能。
119.如本文所使用的,集合的子集不包括空子集的退化情况及包括该集合所有成员的子集。
120.图11是计算器系统1200的简化方块图,在一网络中的该计算器系统中的一个或多个可以被编程以实现本发明所揭露的技术。计算器系统1200包括一个或多个中央处理单元(cpu)1272,其通过总线子系统1255与多个周边装置进行通信。这些周边装置可以包括储存子系统1210,例如存储器装置和文件储存子系统1236、用户接口输入设备1238、用户接口输出装置1276和网络接口子系统1274。输入和输出装置允许用户与计算器系统1200进行互动。网络接口子系统1274提供一接口以连接到外部网络,其包括到其他计算器系统中的对应接口装置的接口。
121.用户接口输入设备1238可以包括键盘;定位装置,例如鼠标、轨迹球、触摸板或图形输入板;扫描机;包含在显示器中的触摸面板;音频输入设备,例如语音识别系统和麦克风;和其他类型的输入设备。通常,术语「输入设备」的使用旨在包括所有可能的装置类型以及将信息输入至计算器系统1200的方式。
122.用户接口输出装置1276可以包括显示器子系统、打印机、传真机或诸如声音输出装置的非可视化显示。显示器子系统可以包括led显示器、阴极射线管(crt)、诸如液晶显示器(lcd)的平板装置、投影装置或用于产生可见影像的其他装置。显示器子系统还可以提供非可视化显示,例如声音输出装置。通常,术语「输出装置」的使用旨在包括所有可能的装置类型以及用于将信息从计算器系统1200输出到用户或另一机器或计算器系统的方式。
123.储存子系统1210储存编程和数据结构,其提供本文所述的部分或全部的模块和方法的功能,以训练ann的模型。这些模型通常应用于深度学习处理器1278所执行的ann中。
124.在一种实现中,使用深度学习处理器1278来实现神经网络,深度学习处理器1278可以是可配置和可重新配置的处理器、现场可编程门阵列(fpga)、专用集成电路(asic)和/或粗粒度可重构架构(cgra)和图形处理单元(gpu)及其他已配置的装置。深度学习处理器1278可以由深度学习云平台托管,例如google cloud platform
tm
、xilinx
tm
和cirrascale tm
。深度学习处理器1278的示例包括google的tensor processing unit(tpu)
tm
,机架式解决方案例如gx4 rackmount series
tm
、gx149 rackmount series
tm
、nvidia dgx-1
tm
,
microsoft的stratix v fpga
tm
,graphcore的智能处理器单元(ipu)
tm
,具有snapdragon处理器
tm
的高通公司的zeroth platform
tm
,nvidia的volta
tm
,nvidia的drive px
tm
,nvidia的jetson tx1/tx2 module
tm
,英特尔的nirvana
tm
,movidius vpu
tm
,富士通dpi
tm
,arm的dynamiciq
tm
,ibm truenorth
tm
等。
125.在储存子系统1210中使用的存储器子系统1222可以包括多个存储器,包括用于在程序执行期间储存指令和数据的主要随机存取存储器(ram)1234,和储存固定指令的只读存储器(rom)1232。文件储存子系统1236可以为程序和数据文件(包括图1、3和5所述的程序和数据文件)提供永久储存,并且可以包括硬盘机、软盘驱动器以及相关的可移除媒体、cd-rom、光驱或可移除媒体盒式磁带。实现某些功能的模块可储存在储存子系统1210的文件储存子系统1236中或处理器可存取的其他机器中。
126.总线子系统1255提供了一种机制,该机制用于使计算器系统1200的各个组件和子系统互相通信。尽管总线子系统1255仅示出为单个总线,但是总线子系统可以使用多个总线。
127.计算器系统1200本身可以是各种类型的,包括个人计算器、可携式计算器、工作站、计算器终端、网络计算器、电视、大型计算机、服务器场、广泛分布的一组松耦合网络计算器或任何其他数据处理系统或用户装置。由于计算器和网络不断变化的特性,图11中所示的计算器系统1200的描述仅作为一特定示例,其目的是用于说明本发明的优选实施例。与图11所示的计算器系统相比,计算器系统1200的其他配置方式可能具有更多或更少的组件。
128.本文描述的技术的实施例包括计算器程序,其储存在可由计算器存取和读取的非瞬时计算器可读取媒体的存储器上,包括例如图1、3和5描述的程序和数据文件。
129.综上所述,虽然本发明已以实施例揭露如上,然其并非用以限定本发明。本发明所属技术领域中普通技术人员,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当以的权利要求所界定的为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1