基于区块链和人工智能的金融预测系统的制作方法
本发明创造涉及金融领域,具体涉及一种基于区块链和人工智能的金融预测系统。
背景技术:
时间序列是各行各业的数据按照不同的时间间隔依次、连续产生的,它们通常包含着丰富且复杂的信息。由于人们需要从时间序列中获取有价值的信息,因此时间序列分析技术应运而生。时间序列分析领域的关键一环是预测,时间序列预测是根据数据的历史规律以及变化趋势,对未来数据的发展状况做出合理的推测。金融时间序列是金融领域中最重要的数据,对这类数据进行分析、预测在金融投资决策与风险管理中具有重要的意义。
技术实现要素:
针对上述问题,本发明旨在提供一种基于区块链和人工智能的金融预测系统。
本发明创造的目的通过以下技术方案实现:
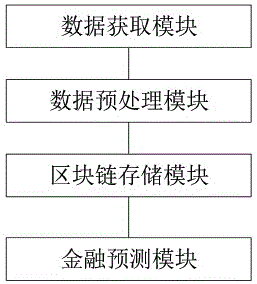
一种基于区块链和人工智能的金融预测系统,包括数据获取模块、数据预处理模块、区块链存储模块和金融预测模块,所述数据获取模块用于获取金融时间序列,并将获取的金融时间序列输入至数据预处理模块进行处理,所述数据预处理模块用于去除所述金融时间序列中的噪声数据,并将预处理后的金融时间序列传输至区块链存储模块进行存储,所述金融预测模块用于从区块链存储模块中调取所述金融时间序列,并根据所述金融时间序列对金融数据的走势进行预测,所述金融预测模块采用bp神经网络对金融时间序列的走势进行预测,采用粒子群算法对金融预测模块采用的bp神经网络的初始权值和阈值进行优化;定义所述粒子群算法采用下列方式进行更新:
vi(t+1)=ωi(t)vi(t)+c1r1(pi(t)-xi(t))+c2r2(g(t)-xi(t))
xi(t+1)=xi(t)+vi(t+1)
式中,ωi(t)表示粒子i在第t次迭代时的惯性权重因子,vi(t+1)和xi(t+1)分别表示粒子i在第(t+1)次迭代时的步长和位置,vi(t)和xi(t)分别表示粒子i在第t次迭代时的步长和位置,c1和c2表示学习因子,r1和r2表示0到1之间的随机数,g(t)表示粒子群在第t次迭代时的全局最优解,p′i(t)表示粒子i在第t次迭代时的局部学习解,且p′i(t)的值采用下列方式确定:
设p(t)表示粒子群中粒子在第t次迭代时的个体最优解的集合,且p(t)={pi(t),i=1,2,...,n},其中,pi(t)表示粒子i在第t次迭代时的个体最优解,n表示粒子群中的粒子数;设m(t)表示设置的粒子群算法在第t次迭代时的局部分类数,且
式中,xl(t)表示粒子l在第t次迭代时的位置,ρ1(pi(t),xl(t))表示第一取值函数,d(pi(t),xl(t))表示个体最优解pi(t)和位置xl(t)之间的欧式距离,当d(pi(t),xl(t))≤d时,则ρ1(pi(t),xl(t))=1,当d(pi(t),xl(t))>d时,则ρ1(pi(t),xl(t))=0,其中,d为给定的距离阈值,且
将集合p(t)中的个体最优解按其局部检测系数的值由小到大进行排序,选取前m(t)个个体最优解作为候选局部学习解,并将选取的m(t)个候选局部学习解组成集合p′(t),粒子群中的粒子在集合p′(t)中选取距离其最近的候选局部学习解作为其对应的局部学习解,即
优选地,定义所述粒子群算法的适应度函数h为:
式中,yu表示第u个训练样本的输出值,ou表示第u个训练样本的目标值,m表示训练样本的个数。
优选地,粒子i在第t次时的惯性权重因子ωi(t)的表达式为:
式中,ωmax和ωmin分别表示最大惯性权重因子和最小惯性权重因子,t表示当前迭代次数,tmax表示最大迭代次数,δi(t)表示粒子i在第t次迭代时的惯性权重调节因子,设xi(t-2)表示粒子i在第(t-2)次迭代时的位置,xi(t-1)表示粒子i在第(t-1)次迭代时的位置,定义αi(t)表示粒子i在第t次迭代时的前进属性值,βi(t)表示粒子i在第t次迭代时的寻优属性值,且
设τi(t)表示在第t次迭代之前且距离第t次迭代最近一次粒子i的惯性权重调节因子等于-1时的迭代次数,则δi(t)的表达式为:
其中,
本发明创造的有益效果:
采用bp神经网络对金融时间序列的走势进行预测,并采用粒子群算法对金融预测模块中采用的bp神经网络的初始权值和阈值进行优化,对传统的粒子群的更新模式进行改进,相较于传统的在粒子的更新过程中令粒子向其个体最优解进行局部学习的方式,本优选实施例仅选取部分较优的个体最优解作为粒子局部学习的解,定义局部分类数m(t)和个体最优解对应的局部检测系数,定义的个体最优解对应的局部检测系统通过综合考虑所述个体最优解的局部邻域中粒子的密度、所述个体最优解对应的停滞次数以及所述个体最优解的适应度函数值确定所述个体最优解成为局部学习解的概率,当所述个体最优解的局部邻域中的粒子的密度较小时,应加强对所述个体最优解的局部邻域的搜索,即增加该个体最优解成为局部学习解的概率,当所述个体最优解的停滞次数较多时,表明该位置具有较大可能性为局部最优解,因此,减小该个体最优解成为局部学习解的概率,当所述个体最优解的适应度函数值较小时,表明该个体最优解越好,因此,增加该个体最优解成为局部学习解的概率;设置的局部分类数的值随着迭代次数的增加而增加,即在迭代前期,在粒子群的个体最优解中选取较少的具有代表性的个体最优解作为粒子局部学习的对象,从而增加了粒子群算法的收敛速度,在粒子群算法的后期,在粒子群的个体最优解中选取较多的具有代表性的个体最优解作为粒子局部学习的对象,从而加强了粒子群算法的局部搜索能力;综上所述,本优选实施例在粒子群算法的更新过程中,引入局部学习解替代传统更新公式中的个体最优解作为粒子局部学习的对象,通过定义的局部分类数和个体最优解对应的局部检测系数选取部分较优的个体最优解作为粒子局部学习的对象,在加速了粒子群算法的收敛速度的同时,保证了粒子群算法的寻优能力;在粒子群算法的惯性权重因子中引入了惯性权重调节因子,当粒子在更新过程中出现返回现象时,将影响粒子群算法的收敛速度,当粒子在更新过程中的个体最优解不变时,表明粒子此时可能陷入了局部最优解,将影响粒子群算法的寻优性能,针对上述两种情况,本优选实施例定义的惯性权重调节因子中引入了粒子在当前迭代时的前进属性值和寻优属性值,所述前进属性值用于衡量粒子在迭代过程中的更新路线,相较于适应度函数值,欧式距离能够有效的反应粒子位置之间的距离关系,通过比较粒子连续三次迭代后的位置以及当前全局最优解之间的距离关系来判断粒子迭代更新后是否向着当前全局最优解的方向前进,当粒子在当前迭代时的位置相较于前一次迭代时的位置距离当前全局最优解的距离更远,并且距离前两次迭代时的位置更近,即表明粒子在更新过程中出现了返回现象,此时,令粒子的前进属性值加1,即粒子的前进属性值记录了粒子在更新过程中出现的返回现象,所述寻优属性值用于衡量粒子在更新过程中的寻优性能,当粒子迭代更新后其个体最优解并没有变化时,表明该粒子可能陷入了局部最优值,此时,令粒子的寻优属性值加1,即粒子的寻优属性值记录了粒子在迭代过程中可能陷入局部最优解的次数,综上所述,粒子的惯性权重调节因子通过粒子的前进属性值和粒子的寻优属性值记录了粒子在迭代更新过程中出现的返回次数和陷入局部最优值的次数,当粒子在更新过程中出现的返回次数和陷入局部最优值的次数的和达到给定的阈值时,则令此时粒子的惯性权重调节因子的值等于-1,即使得粒子此时的惯性权重因子的值较大,从而使得粒子远离当前的位置,当粒子在更新过程中出现的返回次数和陷入局部最优值的次数的和小于给定的阈值时,则此时粒子的惯性权重调节因子的值等于0,即使得粒子仍然按照传统的惯性权重因子值进行迭代更新。
附图说明
利用附图对发明创造作进一步说明,但附图中的实施例不构成对本发明创造的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
图1是本发明结构示意图。
具体实施方式
结合以下实施例对本发明作进一步描述。
参见图1,本实施例的一种基于区块链和人工智能的金融预测系统,包括数据获取模块、数据预处理模块、区块链存储模块和金融预测模块,所述数据获取模块用于获取金融时间序列,并将获取的金融时间序列输入至数据预处理模块进行处理,所述数据预处理模块用于去除所述金融时间序列中的噪声数据,并将预处理后的金融时间序列传输至区块链存储模块进行存储,所述金融预测模块用于从区块链存储模块中调取所述金融时间序列,并根据所述金融时间序列对金融数据的走势进行预测,所述金融预测模块采用bp神经网络对金融时间序列的走势进行预测,采用粒子群算法对金融预测模块采用的bp神经网络的初始权值和阈值进行优化;定义所述粒子群算法采用下列方式进行更新:
vi(t+1)=ωi(t)vi(t)+c1r1(p′i(t)-xi(t))+c2r2(g(t)-xi(t))
xi(t+1)=xi(t)+vi(t+1)
式中,ωi(t)表示粒子i在第t次迭代时的惯性权重因子,vi(t+1)和xi(t+1)分别表示粒子i在第(t+1)次迭代时的步长和位置,vi(t)和xi(t)分别表示粒子i在第t次迭代时的步长和位置,c1和c2表示学习因子,r1和r2表示0到1之间的随机数,g(t)表示粒子群在第t次迭代时的全局最优解,p′i(t)表示粒子i在第t次迭代时的局部学习解,且p′i(t)的值采用下列方式确定:
设p(t)表示粒子群中粒子在第t次迭代时的个体最优解的集合,且p(t)={pi(t),i=1,2,...,n},其中,pi(t)表示粒子i在第t次迭代时的个体最优解,n表示粒子群中的粒子数;设m(t)表示设置的粒子群算法在第t次迭代时的局部分类数,且
式中,xl(t)表示粒子l在第t次迭代时的位置,ρ1(pi(t),xl(t))表示第一取值函数,设d(pi(t),xl(t))表示个体最优解pi(t)和位置xl(t)之间的欧式距离,当d(pi(t),xl(t))≤d时,则ρ1(pi(t),xl(t))=1,当d(pi(t),xl(t))>d时,则ρ1(pi(t),xl(t))=0,其中,d为给定的距离阈值,且
将集合p(t)中的个体最优解按其局部检测系数的值由小到大进行排序,选取前m(t)个个体最优解作为候选局部学习解,并将选取的m(t)个候选局部学习解组成集合p′(t),粒子群中的粒子在集合p′(t)中选取距离其最近的候选局部学习解作为其对应的局部学习解,即
本优选实施例采用粒子群算法对金融预测模块中采用的bp神经网络的初始权值和阈值进行优化,并对传统的粒子群的更新模式进行改进,相较于传统的在粒子的更新过程中令粒子向其个体最优解进行局部学习的方式,本优选实施例仅选取部分较优的个体最优解作为粒子局部学习的解,定义局部分类数m(t)和个体最优解对应的局部检测系数,定义的个体最优解对应的局部检测系统通过综合考虑所述个体最优解的局部邻域中粒子的密度、所述个体最优解对应的停滞次数以及所述个体最优解的适应度函数值确定所述个体最优解成为局部学习解的概率,当所述个体最优解的局部邻域中的粒子的密度较小时,应加强对所述个体最优解的局部邻域的搜索,即增加该个体最优解成为局部学习解的概率,当所述个体最优解的停滞次数较多时,表明该位置具有较大可能性为局部最优解,因此,减小该个体最优解成为局部学习解的概率,当所述个体最优解的适应度函数值较小时,表明该个体最优解越好,因此,增加该个体最优解成为局部学习解的概率;设置的局部分类数的值随着迭代次数的增加而增加,即在迭代前期,在粒子群的个体最优解中选取较少的具有代表性的个体最优解作为粒子局部学习的对象,从而增加了粒子群算法的收敛速度,在粒子群算法的后期,在粒子群的个体最优解中选取较多的具有代表性的个体最优解作为粒子局部学习的对象,从而加强了粒子群算法的局部搜索能力;综上所述,本优选实施例在粒子群算法的更新过程中,引入局部学习解替代传统更新公式中的个体最优解作为粒子局部学习的对象,通过定义的局部分类数和个体最优解对应的局部检测系数选取部分较优的个体最优解作为粒子局部学习的对象,在加速了粒子群算法的收敛速度的同时,保证了粒子群算法的寻优能力。
优选地,定义所述粒子群算法的适应度函数h为:
式中,yu表示第u个训练样本的输出值,ou表示第u个训练样本的目标值,m表示训练样本的个数。
本优选实施例定义的粒子群的适应度函数的值越小,表明粒子的寻优结果越好。
优选地,粒子i在第t次时的惯性权重因子ωi(t)的表达式为:
式中,ωmax和ωmin分别表示最大惯性权重因子和最小惯性权重因子,t表示当前迭代次数,tmax表示最大迭代次数,δi(t)表示粒子i在第t次迭代时的惯性权重调节因子,设xi(t-2)表示粒子i在第(t-2)次迭代时的位置,xi(t-1)表示粒子i在第(t-1)次迭代时的位置,定义αi(t)表示粒子i在第t次迭代时的前进属性值,βi(t)表示粒子i在第t次迭代时的寻优属性值,且
设τi(t)表示在第t次迭代之前且距离第t次迭代最近一次粒子i的惯性权重调节因子等于-1时的迭代次数,则δi(t)的表达式为:
其中,
本优选实施例在粒子群算法的惯性权重因子中引入了惯性权重调节因子,当粒子在更新过程中出现返回现象时,将影响粒子群算法的收敛速度,当粒子在更新过程中的个体最优解不变时,表明粒子此时可能陷入了局部最优解,将影响粒子群算法的寻优性能,针对上述两种情况,本优选实施例定义的惯性权重调节因子中引入了粒子在当前迭代时的前进属性值和寻优属性值,所述前进属性值用于衡量粒子在迭代过程中的更新路线,相较于适应度函数值,欧式距离能够有效的反应粒子位置之间的距离关系,通过比较粒子连续三次迭代后的位置以及当前全局最优解之间的距离关系来判断粒子迭代更新后是否向着当前全局最优解的方向前进,当粒子在当前迭代时的位置相较于前一次迭代时的位置距离当前全局最优解的距离更远,并且距离前两次迭代时的位置更近,即表明粒子在更新过程中出现了返回现象,此时,令粒子的前进属性值加1,即粒子的前进属性值记录了粒子在更新过程中出现的返回现象,所述寻优属性值用于衡量粒子在更新过程中的寻优性能,当粒子迭代更新后其个体最优解并没有变化时,表明该粒子可能陷入了局部最优值,此时,令粒子的寻优属性值加1,即粒子的寻优属性值记录了粒子在迭代过程中可能陷入局部最优解的次数,综上所述,粒子的惯性权重调节因子通过粒子的前进属性值和粒子的寻优属性值记录了粒子在迭代更新过程中出现的返回次数和陷入局部最优值的次数,当粒子在更新过程中出现的返回次数和陷入局部最优值的次数的和达到给定的阈值时,则令此时粒子的惯性权重调节因子的值等于-1,即使得粒子此时的惯性权重因子的值较大,从而使得粒子远离当前的位置,当粒子在更新过程中出现的返回次数和陷入局部最优值的次数的和小于给定的阈值时,则此时粒子的惯性权重调节因子的值等于0,即使得粒子仍然按照传统的惯性权重因子值进行迭代更新。
优选地,所述数据预处理模块用于去除金融时间序列中的噪声数据,设待处理的金融时间序列为f,对金融时间序列f中的金融数据进行依次处理,设f(k)表示金融时间序列f中当前待处理的金融数据,且f(k)表示金融时间序列f中的第k个金融数据,给定数据阈值δf(k),其中,δf(k)可以设置为
设f(a)表示参考数据序列f(k)中的金融数据,且f(a)为金融时间序列f中的第a个金融数据,f(b)表示参考数据序列f(k)中的金融数据,且f(b)表示金融时间序列f中的第b个金融数据,其中,a≠b,则参考数据序列f(k)中的金融数据f(a)和金融数据f(b)满足:|f(a)-f(b)|≤δf(k);
设
(1)当金融数据f(k)满足
其中,θ(k)表示当金融数据f(k)大于等于
选取使得序列检测函数θ(k)=1的最大m的值记为m′;
(2)当金融数据f(k)满足
其中,
选取使得序列检测函数
设f″(k)表示金融数据f(k)的第二参考数据子序列,且
式中,δf(k-m′)表示金融数据f(k-m′)在第一参考数据子序列f′(k)中的标准差,δf(k)表示金融数据f(k)在第一参考数据子序列f′(k)中的标准差,
定义金融数据f(k)在第一参考数据子序列f′(k)和第二参考数据、子序列f″(k)中的第二检测系数为y2(k),且y2(k)的表达式为:
式中,
定义金融数据f(k)在第一参考数据子序列f′(k)和第二参考数据子序列f″(k)中的异常检测函数为y(k),且y(k)的表达式为:
当异常检测函数y(k)的值满足:y(k)≤0时,判定金融数据f(k)为正常金融数据,且金融数据f(k)的值保持不变;当异常检测函数y(k)的值满足:y(k)>0时,判定金融数据f(k)为异常数据,且令
本优选实施例用于去除所述金融时间序列中的噪声数据,对金融时间序列中的金融数据依次进行检测,判断所述金融数据是否为噪声数据,在对所述金融数据进行检测时,给定数据阈值用于确定待检测金融数据的参考数据序列,所述参考数据序列中的任两个金融数据之间的欧式距离都小于等于所述数据阈值,从而保证了参数数据序列中的金融数据的相似性,根据待检测金融数据和参考数据序列中金融数据均值的关系在所述参考数据序列中选取部分金融数据和待检测金融数据组成待检测金融数据的第一参考数据子序列,从而保证了所述第一参考数据子序列走势的统一性,选取第一参考数据子序列中间的部分金融数据组成待检测金融数据的第二参考子序列,当待检测金融数据为正常数据时,确定的第一参考数据子序列和第二参考数据子序列将有着相似的走势,根据该特性,定义所述金融数据在第一参考数据子序列和第二参考数据子序列中的第一检测系数和第二检测系数,所述第一检测系数通过将所述第一参考数据子序列的初始金融数据的标准差和第二参考数据子序列的初始金融数据的标准差、第一参考数据子序列的结尾金融数据的标准差(即待检测金融数据的标准差)和第二参考数据子序列的结尾金融数据的标准差进行比较,判断待检测金融数据的第一参考数据子序列和第二参考数据子序列走势的相似性,所述第二检测系数通过将第一参考数据子序列中金融数据的均值和第二参考数据子序列中金融数据的均值进行比较,从而判断第一参考数据子序列和第二参考数据子序列走势的相似性,定义待检测金融数据对应的异常检测函数,所述异常检测函数通过第一检测系数和第二检测系数比较所述第一参考数据子序列和第二参数数据子序列之间走势的相似性,从而判断待检测金融数据是否为噪声数据,考虑到当第二参考数据子序列的首尾数据距离第一参考数据子序列的首尾金融数据距离越远,第一参考数据子序列和第二参考数据子序列之间走势的相似性减小的情况,本优选实施例在待检测金融数据的异常检测函数中引入了正弦形式的修正系数对第一检测系数进行修正,使得待检测金融数据的异常检测函数能够更加的灵活,从而有效的提高了噪声数据的检测精度。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!