一种面向大规模矢量场数据处理方法与流程
本发明涉及一种面向大规模矢量场数据处理方法,属于高性能计算框架领域。
背景技术:
在信息时代,传感器以及信息技术快速发展,矢量场数据以及其应用需求随之快速增长,针对大规模矢量场数据的实时计算也面临着越来越高的性能需求。以风场数据在气象领域中的应用为例,数据由广泛分布的风速风向传感器采集获取,在多个区域的气象部门进行同步汇总,在统一的云计算环境下进行分析计算,最终用来分析风场结构,进行台风预警等,但是面对巨大的数据量,目前气象部门对这些数据的应用仍然面临着分钟级的延迟。同样的,在海洋科学中,洋流数据可用于分析洋流对气候的影响,在数据处理性能上也面临着相同的问题。
矢量场数据有着很广泛的应用。例如,对风场和海流数据的分析可以预测台风、海啸等自然灾害,及时发出预警信息便于公民及时做出防范措施,保证公民的生命安全,减少人们的财产损失。如果对这些数据的分析利用不够及时,数据的实用价值也会相应降低,因此,研究大规模矢量场数据的高性能计算具有十分重要的现实意义。
现有大规模矢量场数据计算方法将大规模矢量场数据分为细尺度数据块,并且将细尺度数据块随机传输到不同的节点且进行计算,但矢量场数据具有空间关联性,即计算某一矢量场数据时,需要使用该矢量场数据在空间上邻近的矢量场数据,大量增加了矢量场数据的计算量,同时增加了大量的通信开销。
技术实现要素:
为了解决所述现有技术中的技术问题,本发明提供了一种面向大规模矢量场数据高性能计算框架,该框架降低了矢量场数据的空间关联性导致的大量数据计算,同时该框架提升了输出的数据流的单一性和完整性。
实现本发明目的的技术方案为,一种面向大规模矢量场数据处理方法,该方法至少包括以下步骤:
(1)将大规模矢量场数据进行等分,且将等分后形成的每个分矢量场数据再次等分,重复上述步骤,直至等分次数达到矢量场数据的维数数值,最终等分后形成子区域,按子区域数据的位置按序进行编码;
(2)设定最大合并数,读取所有子区域数据,根据最大合并数依次将子区域数据按编码值由小至大依次合并成区域块;
(3)根据数据块的形成先后进行编码,读取数据块且根据数据块的编码通过哈希映射将数据块分配至相应分区,将空间上邻近的数据块分配到同一分区;
所用哈希映射公式为
式中a为分区数,c为数据块的编码数,m为分区总数,
(4)利用流数据阀门检验数据块单一性和完整性;具体步骤如下:
1)根据数据块的编码数值设置不同的缓冲区;
2)依次按编码数值将数据块分配至相应的缓冲区内且判断待分配的数据块是否与缓冲区内某一数据块相同,若相同则将该数据块替代缓冲区内与之相同的数据块,若不同则将该数据块添加至相应的缓冲区内;
3)判断缓冲区内数据块中数据是否完整,若完整则输出该数据快,若不完整则不输出该数据块;
(5)对数据块进行迭代计算,即始终使用上一次计算的结果数据进行计算,且将计算后的数据块合并形成数据流输出。
对上述技术方案的进一步改进为:所述等分为十字形均等切分。
且步骤(1)中所述子区域数据的编码按00、01、10、11从左到右,自上而下依次标注,进一步等分后的子区域数据的编码,保留原有标注且按上述规则增加后缀标注。
且步骤1)所述缓冲区仅存储相同编码前缀的数据块。
且步骤2)所述数据块数据结构为键值名、数据类型、键值。
且步骤2)所述待分配的数据块是否与缓冲区内某一数据块相同的具体方法为:判断待分配的数据块与缓冲区内数据块中键值是否相同。
且步骤3)所述判断缓冲区内数据块中数据是否完整的具体方法为:依次检查数据块的键值中所有最小单元区域是否含有数据值,若全部含有,则该数据块中数据完整,反之,则该数据块中数据不完整。
由上述技术方案可知,本发明提供的面向大规模矢量场数据处理方法,将大规模矢量场数据进行等分,且将等分后形成的每个分矢量场数据再次等分,重复上述步骤,直至等分次数达到矢量场数据的维数数值,最终等分后形成子区域,按子区域数据的位置按序进行编码;从而降低了大规模矢量场数据的数据规模,同时降低了数据的通信的复杂程度;
同时读取指定范围内所有子区域数据,且将其合并成数据块,从而不需对整个大规模矢量场数据进行查找,增加了数据传输效率。
且该方法读取数据块且根据数据块的编码通过哈希映射将数据块分配至相应分区,该分配方式将空间上邻近的数据块分配到同一分区,不需重新寻找数据块在空间上邻近的数据块,提高了迭代计算的效率;
且流数据阀门依次按编码数值将数据块分配至相应的缓冲区内且判断待分配的数据块是否与缓冲区内数据块相同,若相同则将该数据块替代缓冲区内与之相同的数据块,若不同则将该数据块添加至相应的缓冲区内;和判断缓冲区内数据块中数据是否完整,若完整则输出该数据快至数据流,若不完整则不输出该数据快;该流数据阀门排除了重复和缺失信息的数据块,将单一且完整的数据块输出至数据流,保证了数据流的单一性和完整性。
附图说明
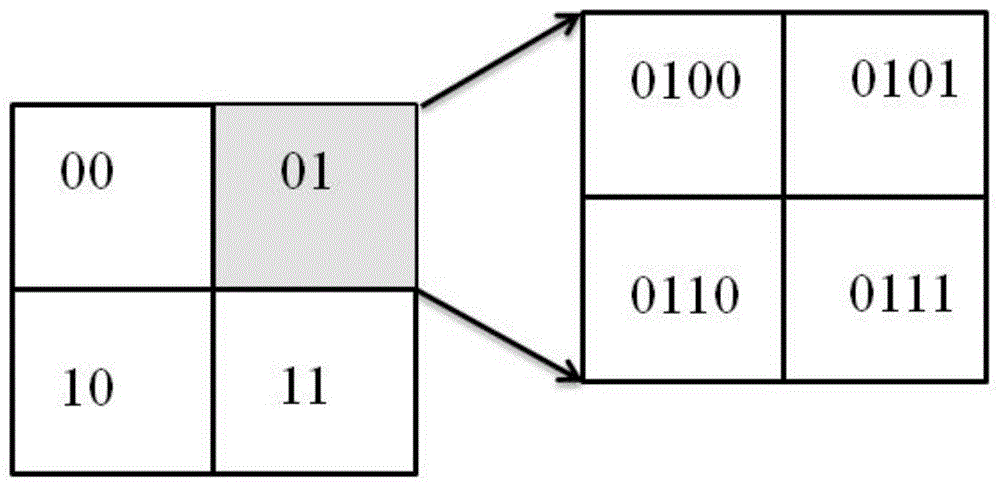
图1为本发明的数据划分与编码示意图;
图2为本发明的节点分配示意图;
图3为本发明的数据块输出流程示意图;
具体实施方式
下面结合附图和实施例对本发明进行详细具体说明,本发明的内容不局限于以下实施例。
参考图1,本发明提供的面向大规模矢量场数据处理方法,该方法包括以下步骤:
将大规模矢量场数据进行等分,且将等分后形成的每个分矢量场数据再次等分,重复上述步骤,直至等分次数达到矢量场数据的维数数值,最终等分后形成子区域,按子区域数据的位置按序进行编码;本实施例中具体切分规则为:将大规模矢量场数据根据十字形均等切分,且将切分后的大规模矢量场数据进一步切分,重复该切分步骤,直至切分数量达到数据维数。
本实施例中具体编码规则为:子区域数据的编码按00、01、10、11从左到右,自上而下依次标注,进一步切分后的子区域数据的编码,保留原有标注且按上述规则增加后缀标注,例如,第一次切分后的子区域数据的编码为00、01、10、11,第二次切分后的子区域数据的编码为0000、0001、0010、0011、0100、0101……。
从而降低了大规模矢量场数据的数据规模,同时降低了数据的通信的复杂程度;
(2)设定最大合并数,最大合并数小于子区域数量,读取所有子区域数据,根据最大合并数依次将子区域数据按编码值由小至大依次合并成区域块。该步骤到指定位置读取子区域数据,然后按照编码把一段连续的子区域数据从存储空间读出,合并成一个数据块的形式发出,从而不需对整个大规模矢量场数据进行查找,增加了数据传输效率,保证数据以最高效的形式进入数据流。
参考图2,根据数据块的形成先后进行编码,读取数据块且根据数据块的编码通过哈希映射将数据块分配至相应分区,将空间上邻近的数据块分配到同一分区;
所用哈希映射公式为
式中a为分区数,c为数据块的编码数,m为分区总数,
例如现在有编码0-9的10个数据块,计算集群中包含0-2三个分区,按以上映射关系,分区0上分配到的数据块为(0,1,2,9),分区1上分配到的数据块为(3,4,5),分区2上分配到的数据块为(6,7,8)。
该步骤针对矢量场数据的空间关联性,将空间上邻近的数据块分配到同一分区,不需重新寻找数据块在空间上邻近的数据块,提高了迭代计算的效率;
(4)利用流数据阀门检验数据块单一性和完整性;具体步骤如下:
1)根据数据块的编码数值设置不同的缓冲区;其中缓冲区仅存储相同编码前缀的数据块;
2)参考图3,依次按编码数值将数据块分配至相应的缓冲区内且判断待分配的数据块是否与缓冲区内某一数据块相同,若相同则将该数据块替代缓冲区内与之相同的数据块,若不同则将该数据块添加至相应的缓冲区内;本实施例中数据块数据结构为键值名、数据类型、键值,且判断所述待分配的数据块是否与所述缓冲区内数据块相同具体方法为:判断待分配的数据块与缓冲区内数据块中键值是否相同。
3)判断缓冲区内数据块中数据是否完整,若完整则输出该数据快,若不完整则不输出该数据快,本实施例中判断缓冲区内数据块中数据是否完整的具体方法为:依次检查数据块的键值中所有最小单元区域是否含有数据值,若全部含有,则该数据块中数据完整,反之,则该数据块中数据不完整。
步骤(2)具体为判断数据块的单一性,步骤(3)具体为判断数据块的完整性。
该流数据阀门排除了重复和缺失信息的数据块,将单一且完整的数据块输出至数据流,保证了数据流的单一性和完整性。
对数据块进行迭代计算,即始终使用上一次计算的结果数据进行计算,且将计算后的数据块合并形成数据流输出。该迭代计算确保不同数据块间的数据可见性,使计算结果更加准确。
- 还没有人留言评论。精彩留言会获得点赞!