一种用于催化重整装置实时工况的监测方法及装置与流程
本发明属于石化工况监测领域,尤其涉及一种用于催化重整装置实时工况的监测方法及装置。
背景技术:
催化重整装置是石油炼化的主要装置之一,其主要过程是通过复杂催化反应将石脑油转化为芳烃和高辛烷值汽油并副产氢气,产品和生产装置大多具有易燃、易爆的特点,保证重整装置平稳安全运行和产品质量,需要对实时监测工况的异常情况,提醒操作人员注意干预,避免发生安全事故。
目前催化重整装置内主要依靠常规dcs监控报警系统进行实时工况监侧,其主要缺陷在于采用固定限制报警,由于固定限制往往是通过人为设定的,若设定不当则会存在大量无效的报警事件,一方面容易形成报警泛滥导致无法在有效时间处理,另一方面大量无效的报警事件会使操作人员放松警惕,忽略掉潜在的危险因素。
技术实现要素:
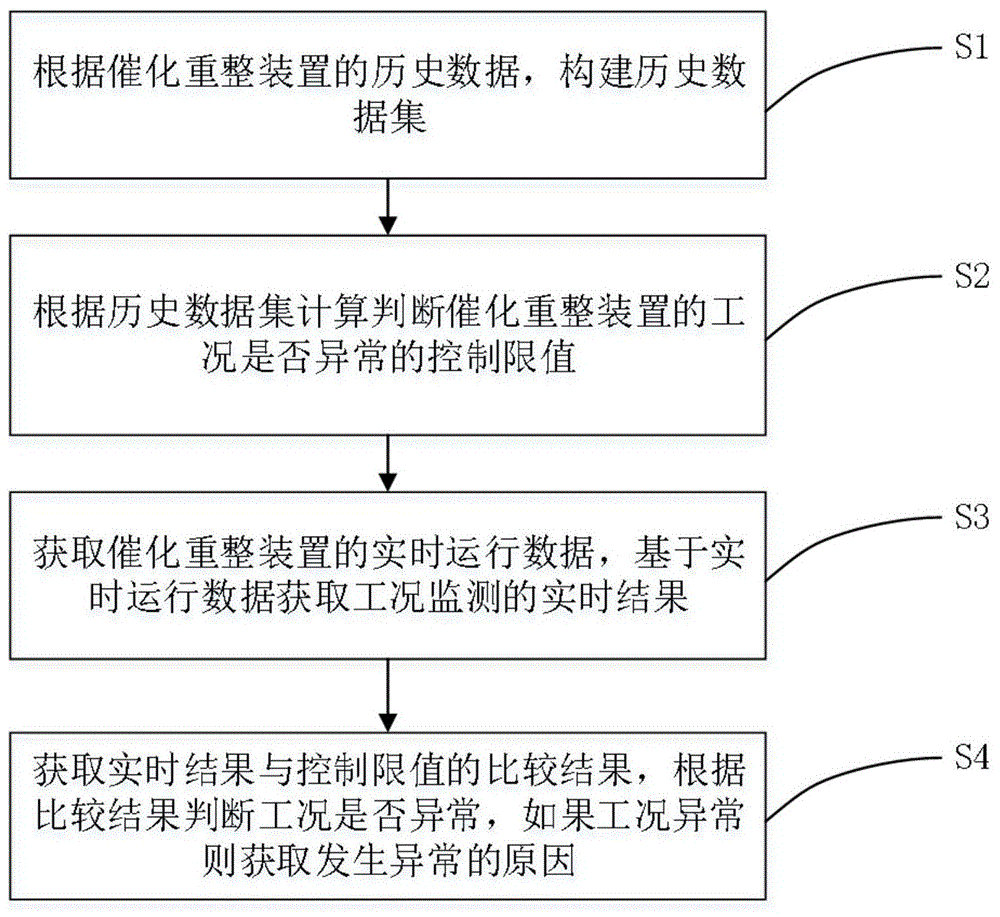
为了解决现有技术中存在的缺点和不足,本发明提出了一种用于催化重整装置实时工况的监测方法,包括:
根据催化重整装置的历史数据,构建历史数据集;
根据历史数据集计算判断催化重整装置的工况是否异常的控制限值;
获取催化重整装置的实时运行数据,基于实时运行数据获取工况监测的实时结果;
获取实时结果与控制限值的比较结果,根据比较结果判断工况是否异常,如果工况异常则获取发生异常的原因。
可选的,所述根据催化重整装置的历史数据,构建历史数据集,包括:
采集各个工艺段的催化重整装置的运行数据,所述运行数据包括反应条件数据、催化重整装置的反应入口处与反应出口处的组分数据;
根据运行数据计算催化重整反应的产品质量参数;
构建包括运行数据和产品质量参数的历史数据集。
进一步的,所述根据运行数据计算催化重整反应后生成的产品质量参数,包括:
获取反应入口处与反应出口处的运行数据,将组分数据输入预先配置的催化反应模型,通过催化反应模型输出组分c的流量参数fc、浓度参数xc以及反应入口处的物料流量fin、反应出口处的石脑油流量fc5+;
通过公式一、公式二以及公式三计算表征催化重整反应质量的产品质量参数,所述产品质量参数包括石脑油c5+的液收率α、石脑油c5+的芳含量β以及反应出口处的辛烷含量ron;
所述产品质量计算模型包括:
ron=∑xcronc=∑xc×(ac+bct+cct2+dct3),c∈c5+公式三;
其中,c为组分名称,c5+表示石脑油中所有组分的集合,a表示石脑油中的芳烃组分的集合,ronc为辛烷组分c的含量,ac、bc、cc以及dc均为计算辛烷组分c的含量的参数,t为物料温度;
所述α、β、ron、ronc、fc、fin、fc5+、xc、t的取值范围均为正数,ac、bc、cc以及dc的取值范围均为实数。
可选的,所述监测方法还包括对历史数据集进行重构处理,所述重构处理的过程包括:
获取由历史数据集中的数据组成的训练矩阵dm×n={d1,d2,…,dm}t∈rm×n,其中n为数据种类的个数,m为采样次数,d1、d2、…、dm为每次采样到的数据,n、m的取值范围均为正整数,d1、d2、…、dm中包含的数据的取值范围均为正数;
对训练矩阵dm×n进行标准化处理,得到处理后的训练矩阵x;
计算标准化处理后的训练矩阵的协方差矩阵s,所述s的计算公式为
计算协方差矩阵s的特征值λi以及λi对应的特征向量pi;
将特征值λi按由大到小的顺序进行排序,根据实际需要确定主元个数k,选取排序后的前k个特征值λi对应的特征向量组成主元投影基向量p=(p1,p2,…,pk);
通过降维重构公式
可选的,所述根据历史数据集计算判断催化重整装置的工况是否异常的控制限值,包括:
基于公式四计算控制限值中的第一控制限值
其中,
cα为标准正态分布的在置信水平α下的阈值;
m为采样次数,fk,m-k;α表示自由度为k和m-k、置信水平为α的f分布的临界值;k、m的取值范围均为大于1的正整数。
可选的,所述获取催化重整装置的实时运行数据,基于实时运行数据获取工况监测的实时结果,包括:
获取催化重整装置在工作中的实时运行数据;
计算实时运行数据的平方预测误差和霍特林t平方分布的值,得到工况监测的实时结果。
可选的,所述获取实时结果与控制限值的比较结果,根据比较结果判断工况是否异常,如果工况异常则获取发生异常的原因,包括:
将平方预测误差与控制限值中的第一控制限值进行比较,将霍特林t平方分布的值与控制限值中的第二控制限值进行比较;
若平方预测误差不大于第一控制限值,且霍特林t平方分布的值不大于第二控制限值,则判定催化重整装置的工况没有异常,否则判定工况出现异常情况;
当出现异常情况时,通过计算各个催化重整装置的重构残差ei构建有向图;
循环遍历有向图中的各个节点,根据遍历结果确定引起异常工况的催化重整装置以及异常工况的传播路径。
进一步的,所述当出现异常情况时,通过计算各个催化重整装置的重构残差ei构建有向图,包括:
通过计算公式
基于预设的阈值t1、t2以及各个重构残差ei,更新有向图中每个节点的状态值si,所述状态值为:
其中,t1、t2的取值范围为正数。
进一步的,所述循环遍历有向图中的各个节点,根据遍历结果确定引起异常工况的催化重整装置以及异常工况的传播路径,包括:
通过对有向图的循环遍历,查找出状态值不为0的节点;
基于所述节点对应的催化重整装置在实际工况中的联动关系,将节点s'i连接得到异常工况的传播路径。
本发明还基于同样的思路提出了一种用于催化重整装置实时工况的监测装置,其特征在于,所述监测装置包括:
数据采集单元:用于根据催化重整装置的历史数据,构建历史数据集;
历史限值单元:用于根据历史数据集计算判断催化重整装置的工况是否异常的控制限值;
实时监测单元:用于获取催化重整装置的实时运行数据,基于实时运行数据获取工况监测的实时结果;
异常判断单元:用于获取实时结果与控制限值的比较结果,根据比较结果判断工况是否异常,如果工况异常则获取发生异常的原因。
本发明提供的技术方案带来的有益效果是:
基于主元分析直接从历史数据中分析计算用于判断工况是否异常的控制限值,并通过构建有向图判断异常工况的原因。相比单纯根据经验设置固定限制的方式,能够更全面快速的判断实时工况的异常情况,并快速确定发生异常情况的原因,提高判断的准确性,避免了固定限制设置不当的弊端。
附图说明
为了更清楚地说明本发明的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提出的一种用于催化重整装置实时工况的监测方法的流程示意图;
图2为实时工况监测的判定流程图;
图3为本发明提出的一种用于催化重整装置实时工况的监测装置的结构框图。
具体实施方式
为使本发明的结构和优点更加清楚,下面将结合附图对本发明的结构作进一步地描述。
实施例一
如图1所示,本发明提出了一种用于催化重整装置实时工况的监测方法,包括:
s1:根据催化重整装置的历史数据,构建历史数据集。
在本实施例中,通过部署的仪表装置以及数据采集装置,采集各个工艺段的催化重整装置的运行数据,所述运行数据包括反应条件数据、催化重整装置的反应入口处与反应出口处的组分数据。再将采集到的数据按照相应的装置位号映射到计算模型中,以便后续对采集到的数据进行处理计算。在采集到运行数据后,首先要对运行数据进行预处理,过滤掉运行数据中的无效数据,如跳表产生的离群数据、由于设备检修或停用而产生的死线数据等。
通过预先配置的催化反应模型,根据运行数据计算催化重整反应中组分c的流量参数fc、浓度参数xc以及反应入口处的物料流量fin、反应出口处的石脑油流量fc5+。在本实施例中,由于催化反应模型仅用于异常检测,故选用复杂度和精度都适中的19集总反应模型作为催化反应模型,集总由c6-c9的直链烷烃、芳烃和环烷烃,p1-p5轻烃和氢气共19中组分组成,简化了异构烷烃,主要保留环烷烃芳构化和直链烷烃成环两类主要反应的特征。具体的计算过程包括:
获取反应入口组成,组成来自在线分析仪,也可以由离线分析或油品组分跟踪计算,得到反应入口处的组分数据;
获取反应操作条件,包括反应压力、温度、氢油比、空速、wait、wabt、各反温降、分离器压力和温度;
根据反应入口处的组分数据和对应反应控制参数模拟得到反应出口处的组分数据。
根据得到的反应入口处、反应出口处的组分数据以及反应条件数据,通过公式一、公式二以及公式三计算表征催化重整反应质量的产品质量参数,所述产品质量参数包括石脑油c5+的液收率y、石脑油c5+的芳含量x以及反应出口处的辛烷含量ron;
所述产品质量计算模型包括:
ron=∑xcronc=∑xc×(ac+bct+cct2+dct3),c∈c5+公式三;
其中,c为组分名称,c5+表示石脑油中所有组分的集合,a表示石脑油中的芳烃组分的集合,ronc为辛烷组分c的含量,ac、bc、cc以及dc均为计算辛烷组分c的含量的参数,t为物料温度;
所述α、β、ron、ronc、fc、fin、fc5+、xc、t的取值范围均为正数,ac、bc、cc以及dc的取值范围均为实数。
最后,构建包括运行数据和产品质量参数的历史数据集。
直接采集催化重整装置的历史运行数据,并通过历史数据计算得到反映催化重整反应质量的产品质量参数,从催化重整装置的实际历史运行情况出发构建历史数据库,提高了历史数据的准确性和全面性,使历史数据更具有参考价值,便于后续通过历史数据得到更为科学准确的控制限值。
所述监测方法还包括对历史数据集进行重构处理,所述重构处理的过程包括:
获取由历史数据集中的数据组成的训练矩阵dm×n={d1,d2,…,dm}t∈rm×n,其中n为数据种类的个数,m为采样次数,d1、d2、…、dm为每次采样到的数据,n、m的取值范围均为正整数,d1、d2、…、dm中包含的数据的取值范围均为正数;
对训练矩阵dm×n进行标准化处理,得到处理后的训练矩阵x;
计算标准化处理后的训练矩阵的协方差矩阵s,所述s的计算公式为
计算协方差矩阵s的特征值λi以及λi对应的特征向量pi;
将特征值λi按由大到小的顺序进行排序,根据实际需要确定主元个数k,选取排序后的前k个特征值λi对应的特征向量组成主元投影基向量p=(p1,p2,…,pk);
通过降维重构公式
采集催化重整装置的历史数据进行相应的主元处理,通过设置主元个数k筛选出最能反映催化重整装置实时工况的数据,便于后续确定监测工况异常情况的控制限值。
s2:根据历史数据集计算判断催化重整装置的工况是否异常的控制限值。
基于公式四计算控制限值中的第一控制限值
其中,
cα为标准正态分布的在置信水平α下的阈值;
m为采样次数,fk,m-k;α表示自由度为k和m-k、置信水平为α的f分布的临界值;k、m的取值范围均为大于1的正整数;
在本实施例中,第一控制限值
根据历史数据集计算控制限值,相比传统根据经验设置固定阈值的方法,减少无效的报警事件,使异常工况报警的触发条件更符合实际工况,另外还克服了常规dcs监控报警系统在动态写入固定阈值时需要控制网操作权限的安全风险。
至此完成所述监测方法中的控制限值训练的阶段,如图2所示,包括:
首先,获取历史运行数据并进行数据预处理。再调用催化反应模型计算表征催化重整反应质量的产品质量参数,由得到的产品质量参数与历史数据共同组成历史数据集。对历史数据集进行主元特征提取,得到标准矩阵x。通过设置主元个数k提取出最能反映工况的特征值对应的特征向量,组成主元投影基向量p并对p进行降维重构处理,从而达到既保留了最能反映工况的数据又减少了需要处理的数据量的效果,最后根据上述处理后的数据计算得到控制限值。
s3:获取催化重整装置的实时运行数据,基于实时运行数据获取工况监测的实时结果。
如图2所示,在实时监测的阶段,首先获取实时运行数据并进行数据预处理;
与控制限值训练阶段相同,在实时监测阶段同样调用催化反应模型计算表征催化重整反应质量的产品质量参数,并对产品质量参数与实时运行数据共同组成的实时数据集进行主元特征提取,通过设置主元个数k提取出最能反映工况的特征值对应的特征向量,组成主元投影基向量p并对p进行降维重构处理。通过计算实时运行数据的平方预测误差和霍特林t平方分布的值,得到工况监测的实时结果。
通过监测模型计算实时运行数据的平方预测误差spe和霍特林t平方分布的值t2,得到工况监测的实时结果。
所述平方预测误差spe和霍特林t平方分布t2的计算方法如下:
spe=||(i-ppt)x||2;
其中,pt为主元投影基向量p的转置。
t2=xtpλ-1ptx;
其中,λ-1为特征值λi组成的对角矩阵;xt为标准矩阵x的转置。
由于大部分装置数据都很难直接采集到异常标签,或者异常标签数量过少,无法建模。在这种情况下,本发明使用基于主元分析的平方预测误差(squaredpredictionerror,spe)和霍特林t平方分布(hotelling'st2,t2)来进行无监督的情况下的异常检测。无监督的异常检测一方面可以在没有异常标签的情况下监测装置运行状况,另一方面也可以为本发明积累标签数据训练有监督的异常检测模型。无监督的异常控制限值是基于统计学的正常数据分布,需要指定置信水平α。
所述spe侧重于判断数据之间的异常关系,所述t2侧重于判断具体的数据本身是否异常。以spe和t2作为异常工况的判定特征,实现准确及时的实时工况监测。
s4:获取实时结果与控制限值的比较结果,根据比较结果判断工况是否异常,如果工况异常则获取发生异常的原因。
如图2所示,判断实时结果是否超限,若未超过控制限值,则返回实时监测阶段的起始步骤,进入下一个监测循环。若超过控制限值,则计算残差状态,通过计算各个催化重整装置的重构残差ei构建有向图,然后遍历有向图,输出根因异常路径,再进行下一次监测。具体包括:
将平方预测误差spe与控制限值中的第一控制限值
若
当出现异常情况时,通过计算各个催化重整装置的重构残差ei构建有向图;
循环遍历有向图中的各个节点,根据遍历结果确定引起异常工况的催化重整装置以及异常工况的传播路径。
其中,当出现异常情况时,通过计算各个催化重整装置的重构残差ei构建有向图,包括:
通过计算公式
基于预设的阈值t1、t2以及各个重构残差ei,更新有向图中每个节点的状态值si,所述状态值包括:
通过对有向图的循环遍历,查找出状态值不为0的节点;
基于所述节点对应的催化重整装置在实际工况中的联动关系,将节点s'i连接得到异常工况的传播路径。所述联动关系预先存储在本地数据库中,包含各个催化重整装置之间运行状态的联动,例如装置a的运行状态变化时,装置b的运行状态就会随之变化,即装置a与装置b具有联动关系。
通过有向图实现异常工况的快速诊断,用重构残差来表述与正常工况的偏差,残差大于阈值t1即为偏高,小于阈值t2即为偏低,在[t2,t1]之间即为正常。
以有向图的方式向操作人员推送实时工况的异常信息,使操作人员能够根据有向图提供的异常路径快速定位出现异常的工艺段及设备,进而实现对异常工况的快速响应。另一方面也能通过有向图展示异常原因,帮助经验不足的操作人员分析和处理异常。
实施例二
如图3所示,本发明还提出了一种用于催化重整装置实时工况的监测装置5,包括:
数据采集单元51:用于根据催化重整装置的历史数据,构建历史数据集;
历史限值单元52:用于根据历史数据集计算判断催化重整装置的工况是否异常的控制限值;
实时监测单元53:用于获取催化重整装置的实时运行数据,基于实时运行数据获取工况监测的实时结果;
异常判断单元54:用于获取实时结果与控制限值的比较结果,根据比较结果判断工况是否异常,如果工况异常则获取发生异常的原因。
在本实施例中,数据采集单元51具体用于:通过部署的仪表装置以及数据采集装置,采集各个工艺段的催化重整装置的运行数据,所述运行数据包括反应条件数据、催化重整装置的反应入口处与反应出口处的组分数据。再将采集到的数据按照相应的装置位号映射到计算模型中,以便后续对采集到的数据进行处理计算。在采集到运行数据后,首先要对运行数据进行预处理,过滤掉运行数据中的无效数据,如跳表产生的离群数据、由于设备检修或停用而产生的死线数据等。
通过预先配置的催化反应模型,根据运行数据计算催化重整反应中组分c的流量参数fc、浓度参数xc以及反应入口处的物料流量fin、反应出口处的石脑油流量fc5+。在本实施例中,由于催化反应模型仅用于异常检测,故选用复杂度和精度都适中的19集总反应模型作为催化反应模型,集总由c6-c9的直链烷烃、芳烃和环烷烃,p1-p5轻烃和氢气共19中组分组成,简化了异构烷烃,主要保留环烷烃芳构化和直链烷烃成环两类主要反应的特征。具体的计算过程包括:
获取反应入口组成,组成来自在线分析仪,也可以由离线分析或油品组分跟踪计算,得到反应入口处的组分数据;
获取反应操作条件,包括反应压力、温度、氢油比、空速、wait、wabt、各反温降、分离器压力和温度;
根据反应入口处的组分数据和对应反应控制参数模拟得到反应出口处的组分数据。
根据得到的反应入口处、反应出口处的组分数据以及反应条件数据,通过公式一、公式二以及公式三计算表征催化重整反应质量的产品质量参数,所述产品质量参数包括石脑油c5+的液收率y、石脑油c5+的芳含量x以及反应出口处的辛烷含量ron;
所述产品质量计算模型包括:
ron=∑xcronc=∑xc×(ac+bct+cct2+dct3),c∈c5+公式三;
其中,c为组分名称,c5+表示石脑油中所有组分的集合,a表示石脑油中的芳烃组分的集合,ronc为辛烷组分c的含量,ac、bc、cc以及dc均为计算辛烷组分c的含量的参数,t为物料温度;
所述α、β、ron、ronc、fc、fin、fc5+、xc的取值范围均为正数,ac、bc、cc以及dc的取值范围均为实数。
最后,构建包括运行数据和产品质量参数的历史数据集。
直接采集催化重整装置的历史数据,并通过历史数据计算得到反映催化重整反应质量的产品质量参数,从催化重整装置的实际历史运行情况出发构建历史数据库,提高了历史数据的准确性和全面性,使历史数据更具有参考价值,便于后续通过历史数据得到更为科学准确的控制限值。
所述监测装置5还包括数据重构装置,用于对历史数据集进行重构处理,具体用于:
获取由历史数据集中的数据组成的训练矩阵dm×n={d1,d2,…,dm}t∈rm×n,其中n为数据种类的个数,m为采样次数,d1、d2、…、dm为每次采样到的数据,n、m的取值范围均为正整数,d1、d2、…、dm中包含的数据的取值范围均为正数;
对训练矩阵dm×n进行标准化处理,得到标准矩阵x;
计算标准化处理后的训练矩阵的协方差矩阵s,所述s的计算公式为
计算协方差矩阵s的特征值λi以及λi对应的特征向量pi;
将特征值λi由大到小排序,确定主元个数k,根据实际需要选取排序后的前k个特征值对应的特征向量,组成主元投影基向量p=(p1,p2,…,pk);
通过降维重构公式
采集催化重整装置的历史数据进行相应的主元处理,通过设置主元个数k筛选出最能反映催化重整装置实时工况的数据,便于后续确定监测工况异常情况的控制限值。
历史限值单元52具体用于:基于公式四计算控制限值中的第一控制限值
其中,
cα为标准正态分布的在置信水平α下的阈值;
m为采样次数,fk,m-k;α表示自由度为k和m-k、置信水平为α的f分布的临界值;k、m的取值范围均为大于1的正整数;
在本实施例中,第一控制限值
根据历史数据集计算控制限值,相比传统根据经验设置固定阈值的方法,减少无效的报警事件,使异常工况报警的触发条件更符合实际工况,另外还克服了常规dcs监控报警系统在动态写入固定阈值时需要控制网操作权限的安全风险。
实时监测单元53具体用于:
通过监测模型计算实时运行数据的平方预测误差spe和霍特林t平方分布的值t2,得到工况监测的实时结果。
所述平方预测误差spe和霍特林t平方分布t2的计算方法如下:
spe=||(i-ppt)x||2;
其中,pt为主元投影基向量p的转置。
t2=xtpλ-1ptx;
其中,λ-1为特征值λi组成的对角矩阵;xt为标准矩阵x的转置。
由于大部分装置数据都很难直接采集到异常标签,或者异常标签数量过少,无法建模。在这种情况下,本发明使用基于主元分析的平方预测误差(squaredpredictionerror,spe)和霍特林t平方分布(hotelling'st2,t2)来进行无监督的情况下的异常检测。无监督的异常检测一方面可以在没有异常标签的情况下监测装置运行状况,另一方面也可以为本发明积累标签数据训练有监督的异常检测模型。无监督的异常控制限值是基于统计学的正常数据分布,需要指定置信水平α。
所述spe侧重于判断数据之间的异常关系,所述t2侧重于判断具体的数据本身是否异常。以spe和t2作为异常工况的判定特征,实现准确及时的实时工况监测。
异常判断单元54具体用于:将平方预测误差spe与控制限值中的第一控制限值
若
当出现异常情况时,通过计算各个催化重整装置的重构残差ei构建有向图;
循环遍历有向图中的各个节点,根据遍历结果确定引起异常工况的催化重整装置以及异常工况的传播路径。
其中,当出现异常情况时,通过计算各个催化重整装置的重构残差ei构建有向图,包括:
通过计算公式
基于预设的阈值t1、t2以及各个重构残差ei,更新有向图中每个节点的状态值si,所述状态值包括:
通过对有向图的循环遍历,查找出状态值不为0的节点;
基于所述节点对应的催化重整装置在实际工况中的联动关系,将节点s'i连接得到异常工况的传播路径。所述联动关系预先存储在本地数据库中,包含各个催化重整装置之间运行状态的联动,例如装置a的运行状态变化时,装置b的运行状态就会随之变化,即装置a与装置b具有联动关系。
通过有向图实现异常工况的快速诊断,用重构残差来表述与正常工况的偏差,残差大于阈值t1即为偏高,小于阈值t2即为偏低,在[t2,t1]之间即为正常。
以有向图的方式向操作人员推送实时工况的异常信息,使操作人员能够根据有向图提供的异常路径快速定位出现异常的工艺段及设备,进而实现对异常工况的快速响应。另一方面也能通过有向图展示异常原因,帮助经验不足的操作人员分析和处理异常。
上述实施例中的各个序号仅仅为了描述,不代表各部件的组装或使用过程中的先后顺序。
以上所述仅为本发明的实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!