一种保护端侧隐私的端云协同训练系统的制作方法
本发明涉及一种保护端侧隐私的端云协同训练系统,属于机器学习技术领域。
背景技术:
联邦学习是一种新兴的人工智能基础技术,其设计目标是在大数据交换时,为保障信息安全、保护终端数据和个人数据隐私、保证合法合规而在多参与方或多计算节点之间开展高效率的机器学习使得逐渐产生了端侧和云侧的区分,进而存在了端云协同训练的思想。
由于用户域数据与开发数据差异较大并且开发训练数据存储部无法覆盖所有用户场景,导致很多未见场景、类别识别错误或不支持。另外由于不同用户数据分布差异较大,统一部署的模型无法满足用户个性化需求进而深度地进行个性化识别模型训练,导致模型更新难度大。事实上,通常所说的云侧提供了充足的存储资源和计算资源,因此端云协同训练便是针对不同用户使用场景进行差异化分析和处理,从而持续提升模型性能。
根据数据去中心化的原则,在设置端云协同训练,用户终端在中心服务器的协调下协同训练模型并且保持训练数据分散的做法减轻了由于传统的集中机器学习和数据科学方法带来的许多系统隐私风险和成本。根据数据中心化原则来协同训练模型的领域研究和引用的角度都引起了ai领域的广泛关注和极大兴趣[1-2]。
如何在保护用户隐私的情况下,仍然能高效稳定的进行模型聚合是端云协同训练进一步研究的难点。现有的直接平均模型权重的端云模型平均法和加密方在根本上都无法在准确的针对用户数据进行有效地保护端侧隐私。
直接平均模型权重的端云模型平均法[3]虽然对于保护用户隐私有很好的效果但是暴力的直接平均算法对于模型权重而言并不是很好的策略。加密法[4-5]虽然在一定程度上能够提高端侧数据的安全性,但端侧信息仍然因为离开了设备而没有从根源上保证用户隐私,此外加密操作还增加了计算复杂度。
[1]杨强,刘洋,陈天健,童咏昕,“联邦学习”。中国计算机学会通信,第14卷,第11期,2018年11月。
[2]杨强,“gdpr对ai的挑战和基于联邦迁移学习的对策”,.中国人工智能学会通信,第8卷,第8期2018年8月。
[3]h.brendanmcmahan,eidermoore,danielramage,andblaiseagüerayarcas.2016.federatedlearningofdeepnetworksusingmodelaveraging.corrabs/1602.05629(2016).arxiv:1602.05629
[4]qiangyang,yangliu,tianjianchen,yongxintong."federatedmachinelearning:conceptandapplications".acmtransactionsonintelligentsystemsandtechnology(tist),volume10issue2,february2019.
[5]jakubkonecny,h.brendanmcmahan,felixx.yu,peterrichtárik,anandatheerthasuresh,anddavebacon.2016.federatedlearning:strategiesforimprovingcommunicationefficiency[7]
技术实现要素:
本发明为解决上述问题,提供一种保护端侧隐私的端云协同训练系统,本发明采用了以下结构:
本发明提供了一种保护端侧隐私的端云协同训练系统,其特征在于,包括:云侧设备以及与该云侧设备相通信连接的端侧设备,其中,云端设备包含云侧数据存储部、云侧自编码部、聚合模型存储部、损失处理部、聚合模型处理部、迭代部以及云侧通信部,端侧设备包含端侧数据存储部、端侧聚合模型存储部以及端侧通信部,端侧数据存储部存储有端侧图像以及相应的端侧标签,端侧聚合模型存储部有基于端侧图像以及端侧数据预先训练得到的端侧聚合模型,云侧数据存储部用于存储云侧图像以及相应的云侧标签,聚合模型存储部存储有至少根据云侧图像预先训练得到的云侧聚合模型,端侧通信部向云侧设备发送端侧聚合模型,云侧通信部接受来自端侧设备发送的端侧聚合模型,云侧自编码部用于将云侧图像以及相应的云侧标签进行处理得到伪图像以及原有的云侧标签,聚合模型处理部将伪图像分别输入端侧聚合模型和云侧聚合模型并处理得到输出端侧聚合模型和输出云侧聚合模型,损失处理部基于图像、伪图像、输出云侧聚合模型以及输出端侧聚合模型进行处理得到相应的多个损失,迭代部利用损失进行反向传播通过反复迭代来更新模型参数得到云侧训练伪图像生成器以及完成端云协同训练的端云聚合模型。其中,伪图像所对应的云侧标签与图像所对应的云侧标签相同。
本发明提供的一种保护端侧隐私的端云协同训练系统,还可以具有这样的技术特征,其中,损失为重构损失、端侧损失、蒸馏损失以及训练损失,分别为:损失处理部根据图像和伪图像计算得到的均方误差为重构损失,损失处理部根据输出端侧聚合模型与云侧标签计算得到的交叉熵为端侧损失,损失处理部根据输出云侧聚合模型与输出端侧聚合模型计算得到的为蒸馏损失,损失处理部根据输出云侧聚合模型与云侧标签计算得到的交叉熵为训练损失,云侧训练伪图像生成器利用重构损失与端侧损失进行反向传播通过反复迭代来更新模型参数得到的,云侧训练聚合模型由利用蒸馏损失与训练损失进行反向传播通过反复迭代来更新模型参数得到的。
本发明提供的一种保护端侧隐私的端云协同训练系统,还可以具有这样的技术特征,其中,当存在多个端侧设备时,聚合模型存储部将当前端云聚合模型作为新的云侧聚合模型进行存储。
本发明提供的一种保护端侧隐私的端云协同训练系统,还可以具有这样的技术特征,其中,利用lenet-5网络的端侧模型通过根据fashion-mnist数据分布的端侧数据存储部进行模型训练,利用lenet-5网络的云侧模型通过利用mnist数据分布的云侧数据存储部进行模型训练。
发明作用与效果
根据本发明的一种保护端侧隐私的端云协同训练系统,由于将预先根据端侧数据训练得到的端侧聚合模型发送到云侧设备中,再将由云侧自编码处理云侧图像得到的伪图像分别输入端侧聚合模型和云侧聚合模型中得到输出端侧聚合模型和输出云侧聚合模型,然后根据基于图像、伪图像、输出云侧聚合模型以及输出端侧聚合模型处理得当多个损失进行反向传播通过反复迭代来更新模型参数得到云侧训练伪图像生成器以及完成端云协同训练的端云聚合模型。因此根据本发明提供的一种保护端侧隐私的端云协同训练系统能够在保护用户隐私的情况下,仍然能高效稳定的进行模型聚合,具有保护用户隐私、聚合效果好、鲁棒性好、泛化能力佳等优点,非常适用于用户设备之间模型聚合、端云协同训练等实际应用。根据不同端侧给云侧提供了充足的存储资源和计算资源,因此端云协同训练便是针对不同用户使用场景进行差异化分析和处理,从而持续提升模型性能。
附图说明
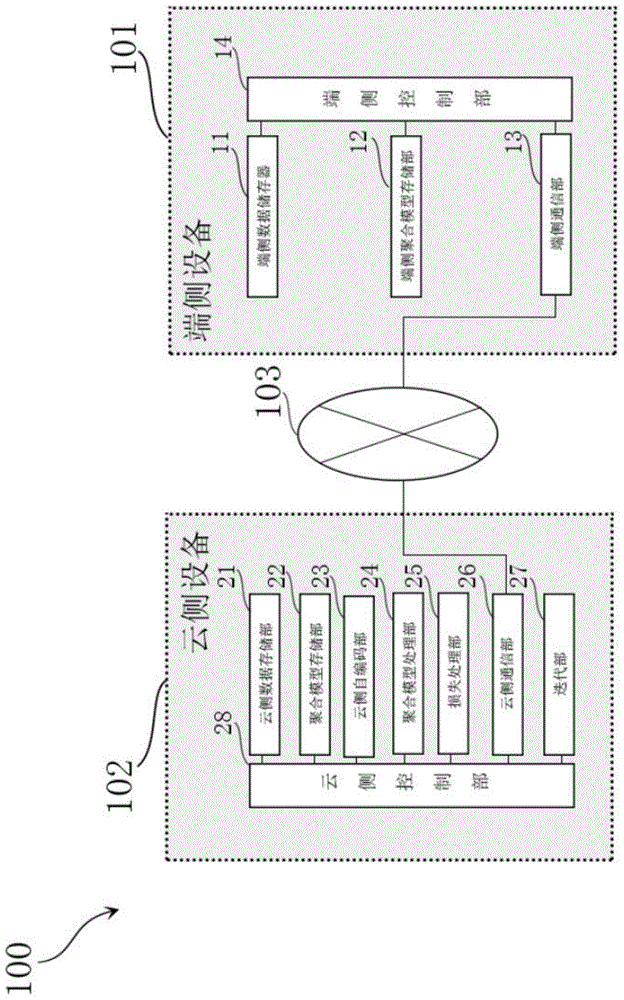
图1是本发明实施例中的一种保护端侧隐私的端云协同训练系统的框架图;
图2是本发明实施例中的一种保护端侧隐私的端云协同训练系统的示意图;
图3是本发明实施例中的一种保护端侧隐私的端云协同训练系统的流程图;以及
图4是本发明实施例中在端云数据分布差异较大情况下的实验结果。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的一种保护端侧隐私的端云协同训练系统作具体阐述。
<实施例>
图1是本发明实施例中的一种保护端侧隐私的端云协同训练系统的框架图。
图2是本发明实施例中的一种保护端侧隐私的端云协同训练系统的示意图。
如图1及图2所示,一种保护端侧隐私的端云协同训练系统100中的包含端侧设备101、云侧设备102以及该端侧设备101与云侧设备102之间的通信通道103。
端侧设备101为存储有相关用户隐私的信息的设备。
其中,端侧设备101可以包括手机、嵌入式设备、npu等。
端侧设备101包含端侧数据存储部11、端侧聚合模型存储部12、端侧通信部13以及用于控制上述各部的端侧控制部14。
端侧数据存储部11存储有携带端侧数据隐私的端侧图像以及相应的端侧标签。
在本实施例中,端侧数据存储部11分布为fashion-mnist数据,包含10类常见物品的图像和标签。
端侧聚合模型存储部12有基于端侧图像预先训练得到的端侧聚合模型。
本实施例中,通过mini-batchsgd的训练方式对于端侧图像进行处理得到端侧聚合模型。端侧聚合模型为lenet-5网络,由单通道图像输入,设置10个输出节点。
在本实施例中,mini-batchsgd的训练过程是将图像分批送入端侧网络中,得到网络输出,将得到的网络输出与数据标签计算交叉熵损失函数并反向传播计算网络各参数的梯度从而更新参数。
端侧通信部13定期向云侧设备102发送端侧聚合模型。
其中端侧通信部13在端侧模型更新完毕,且端侧设备101闲置时(处于充电及联网的夜间时刻)向云侧数据102发送端侧聚合模型。
云侧设备102为根据端侧设备101上传的信息进行处理用以更新模型的设备。
其中,云端设备102包含云侧数据存储部21、聚合模型存储部22、云侧自编码部23、聚合模型处理部24、损失处理部25、云侧通信部26、迭代部27以及用于控制上述各部的云侧控制部28。
云侧数据存储部21用于存储云侧图像以及相应的云侧标签。
在本实施例中,云侧数据存储部21分布为mnist数据,包含10类手写体数字的图像和标签。
聚合模型存储部22存储有至少根据云侧图像预先训练得到的云侧聚合模型。
本实施例中,通过mini-batchsgd的训练方式对于端侧图像进行处理得到端侧聚合模型。云侧聚合模型为lenet-5网络,由单通道图像输入,设置10个输出节点。
云侧自编码部23用于将云侧图像以及相应的云侧标签进行处理得到伪图像以及云侧标签。
其中,云侧自编码部23的结构包含一个编码器和一个解码器,自编码器将输入的原始图像经过编码器得到隐变量,并将隐变量送入解码器得到新的图像。
伪图像所对应的云侧标签与图像所对应的云侧标签相同。
聚合模型处理部24将伪图像和云侧真实图像同时送入聚合模型。
在本实施例中,聚合模型处理部24为一个聚合模型,同时接收云侧真实图像和伪图像,并计算相关损失函数。
损失处理部25基于图像、伪图像、输出云侧聚合模型以及输出端侧聚合模型进行处理得到相应的多个损失。
其中,损失为重构损失、端侧损失、蒸馏损失以及训练损失,分别为:
重构损失为损失处理部25根据图像和伪图像计算得到的均方误差。
端侧损失为损失处理部25根据输出端侧聚合模型与云侧标签计算得到的交叉熵。
蒸馏损失为损失处理部25根据输出云侧聚合模型与输出端侧聚合模型计算得到的。
训练损失为损失处理部25根据输出云侧聚合模型与云侧标签计算得到的交叉熵。
其中,重构损失和端侧损失负责更新云侧伪图像生成器的参数,通过这个损失可以提升云侧伪图像生成器生成的伪样本的质量,从而帮助提升聚合效果;蒸馏损失和训练损失负责更新聚合模型的参数,通过这个损失可以训练聚合模型,一方面使得聚合模型的输出和端侧模型尽量相似,另一方面使得聚合模型学到云侧数据分布。
云侧通信部26接受来自端侧设备101发送的端侧聚合模型。
迭代部27利用损失进行反向传播通过反复迭代来更新模型参数得到云侧训练伪图像生成器以及完成端云协同训练的端云聚合模型。
其中,云侧伪图像生成器在结构上是云侧自编码部23的结构,包含一个编码器和一个解码器。输入为原始图像,经过编码器得到隐变量,随后将隐变量送入解码器得到新的图像,并且云侧训练伪图像生成器通过利用重构损失与端侧损失进行反向传播通过反复迭代来更新模型参数得到的。
云侧训练聚合模型利用蒸馏损失与训练损失进行反向传播通过反复迭代来更新模型参数得到的。
当存在多个端侧设备101时,聚合模型处理部24将当前端云聚合模型作为新的云侧聚合模型进行存储,由此循环往复以融合。
图3是本发明实施例中的一种保护端侧隐私的端云协同训练系统100的流程图。
如图3所示,一种保护端侧隐私的端云协同训练系统100的流程包含如下步骤:
步骤1,由端侧通信部13向云侧设备101发送端侧聚合模型,然后进入步骤2。
步骤2,由云侧通信部22接受来自端侧设备101发送的端侧聚合模型,然后进入步骤3。
步骤3,云侧图像以及相应的云侧标签经过云侧自编码部23处理得到伪图像以及原有的云侧标签,然后进入步骤4。
步骤4,将伪图像由聚合模型处理部25分别输入端侧聚合模型和云侧聚合模型并处理得到输出端侧聚合模型和输出云侧聚合模型,然后进入步骤5。
步骤5,根据图像、伪图像、输出云侧聚合模型以及输出端侧聚合模型经损失处理部26处理得到相应的多个损失,然后进入步骤6。
步骤6,迭代部27利用损失进行反向传播通过反复迭代来更新模型参数得到云侧训练伪图像生成器以及完成端云协同训练的端云聚合模型,结束流程。
图4是本发明实施例中在端云数据分布差异较大情况下的实验结果。
如图4所示,端侧模型通过lenet-5网络利用根据fashion-mnist数据分布的端侧数据存储部11进行模型训练,训练完毕后的端侧模型在根据fashion-mnist数据分布的端侧数据存储部11上具有99.1%的准确率,而在mnist数据分布集上只有25.7%的准确率,因此平均准确率只有61.4%。
云侧模型通过lenet-5网络利用mnist数据分布进行模型训练,训练完毕后的端侧模型在mnist数据分布集上具有98.9%的准确率,而在fashion-mnist数据分布集上只有24.2%的准确率,因此平均准确率只有62.2%。
完成端云协同训练的端云聚合模型在云侧mnist分布中拥有88.4%的准确率,在端侧fashion-mnist分布中拥有67.1%的准确率,因此平均准确率为78.1%,较之端侧模型有较好的提升。
实施例作用与效果
根据本发明的一种保护端侧隐私的端云协同训练系统,由于将预先根据端侧数据训练得到的端侧聚合模型发送到云侧设备中,再将由云侧自编码处理云侧图像得到的伪图像分别输入端侧聚合模型和云侧聚合模型中得到输出端侧聚合模型和输出云侧聚合模型,然后根据基于图像、伪图像、输出云侧聚合模型以及输出端侧聚合模型处理得当多个损失进行反向传播通过反复迭代来更新模型参数得到云侧训练伪图像生成器以及完成端云协同训练的端云聚合模型。因此根据本发明提供的一种保护端侧隐私的端云协同训练系统能够在保护用户隐私的情况下,仍然能高效稳定的进行模型聚合,具有保护用户隐私、聚合效果好、鲁棒性好、泛化能力佳等优点,非常适用于用户设备之间模型聚合、端云协同训练等实际应用。
另外,实施例中,加入重构损失的概念能够使得伪图像和图像具有一定的相似度从而能够加速伪样本生成器的训练速度。加入端侧损失的概念使得生成的伪样本在端侧网络中能得到正确且评分较高的输出。加入蒸馏损失的概念使得云侧聚合模型和端侧聚合模型具有相似的输出。加入训练损失的概念避免了云侧聚合模型与端侧网络越来越相似但并没有学习到云侧的信息导致无法达不到模型聚合的目的。针对在数据处理时可能会出现的损失,本发明通过迭代的方法拉近用户域数据与开发数据差异、减少未见场景未见类别、识别错误以及识别不支持的情况发生,从而使得开发训练数据存储部覆盖大多数用户场景。
另外,实施例中,云侧训练伪图像生成器根据输入的图像进行处理从而会获得具有与原图像具有相同标签的伪图像,由于伪图像与原图像本质上不是相同的图像,因此该伪图像在表达与原图像相同标签的同时,能够对原图像中包含的隐私数据起到保护作用。端云聚合模型在迭代的过程中学习到如何针对不同的图像进行处理得到既能表达并保护隐私数据,又能融合端云模型的聚合模型。
另外,实施例中,当存在多个端侧设备时,在计算损失和模型时,计算对象均包含上一个云侧聚合模型,因此使得统一部署的模型能够满足用户个性化需求进而深度地进行个性化识别模型训练,使得模型更新难度减小,针对不同用户使用场景进行差异化分析和处理,从而持续提升模型性能,根据不同端侧给云侧提供了充足的存储资源和计算资源,因此端云协同训练便是针对不同用户使用场景进行差异化分析和处理,从而持续提升模型性能。
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
- 还没有人留言评论。精彩留言会获得点赞!