一种基于用户评论识别App关键功能的方法及装置与流程
本发明涉及app功能需求分析领域,具体是涉及一种基于用户评论识别app关键功能的方法及装置。
背景技术:
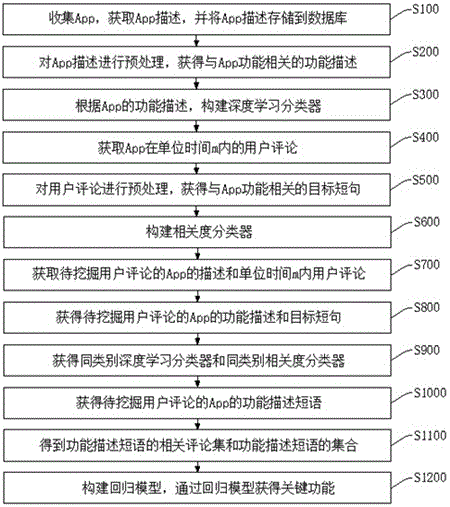
:由于移动应用市场的快速增长和激烈竞争,app想要存活下来必须进行持续更新以挽留老用户和吸引新用户。而用户评论中包含了大量的有用信息,app开发者能通过评论获取用户反馈从而根据这些反馈制定更新方案,进而提升用户满意度。用户评论中包含了大量有用信息,如bug报告、功能请求和功能评估等,这些信息能够有效地帮助app开发者获取下一步更新的需求。然而,热门app每天平均能收到上千条用户评论,对这些评论进行人工分析不仅耗时耗力,而且效率低下。目前,本领域主要通过使用nlp相关的技术来对大量用户评论中的信息进行总结,如使用主题建模技术将用户评论进行聚类和优先级排序,从而识别出最重要的主题。同时,与app功能相关的需求分析也是本领域的重点,其主要通过特征提取、词性标注和语法解析等技术从应用描述或者评论中抽取出功能,然后识别出用户抱怨最多或者最需要改进的功能等。目前这些方法都针对英文,而缺少对于中文的探索。技术实现要素:本发明所要解决的技术问题是提供一种基于appstore用户评论识别app关键功能的方法及装置,该技术方案解决了目前基于用户评论识别app关键功能的方法中缺乏针对中文进行探索这一问题,该方法及装置先预先处理那些只包含与app功能明显无关的词的评论,尽可能地保留了有用评论,同时减少后续分类的工作量,再通过分类器来筛选,彻底将有用评论筛选出来,减少了筛选时产生的误差。解决上述技术问题,本发明提供以下技术方案:提供一种基于用户评论识别app关键功能的方法,包括以下步骤:收集app,获取app描述,并将app描述存储到数据库;根据app描述,去除app描述中的非功能描述,获得与app功能相关的功能描述;根据app的功能描述,构建深度学习分类器;获取app在单位时间m内的用户评论,其中,单位时间m为180天;对用户评论进行纠错处理,过滤纠错后的用户评论中噪声数据,分割过滤后的用户评论,得到与用户评论相关的短句,对短句进行分词处理,去除短句中与app功能无关的词汇,获得与app功能相关的目标短句;构建相关度分类器;确定待挖掘用户评论的app,获取待挖掘用户评论的app的描述和单位时间m内用户评论;对待挖掘用户评论的app的描述和在单位时间m内用户评论进行预处理,获得待挖掘用户评论的app的功能描述和目标短句;根据待挖掘用户评论的app的类别,调取同类别若干app搭建的深度学习分类器和相关度分类器,获得同类别深度学习分类器和同类别相关度分类器;根据同类别深度学习分类器,获得待挖掘用户评论的app的功能描述短语;根据同类别相关度分类器,将待挖掘用户评论的app的功能描述短语和从评论中获取的目标短句进行匹配,获得待挖掘用户评论的app的与功能描述短语相关和不相关的短句,收集与功能描述短语相关的短句,得到功能描述短语的相关评论集和功能描述短语的集合;根据待挖掘用户评论的app的单条功能描述短语的相关评论集(,n为功能描述短语的个数)和功能描述短语的集合构建回归模型,通过回归模型获得关键功能。可选的,根据app描述,去除app描述中的非功能描述,获得与app功能相关的功能描述,具体包括以下步骤:去除对联系方式和订阅信息进行描述的句子以及其后面的句子,获得第一预处理描述;去除第一预处理描述中冗余的标点符号、特殊符号、表情符号和除中文和英文以外的其他字符,得到功能描述。可选的,根据app的功能描述,构建深度学习分类器,具体包括以下步骤:通过pyltp工具对功能描述进行分词、词性标注和依存句法解析,获得功能描述的语法解析树;根据功能描述的语法解析树,抽选出候选短语;对候选短语进行分类,分类为功能描述短语和非功能描述短语,将功能描述短语和非功能描述短语存储到数据库,并基于功能描述短语和非功能描述短语训练深度学习分类器;获得深度学习分类器。可选的,对用户评论进行纠错处理,过滤纠错后的用户评论中噪声数据,分割过滤后的用户评论,得到与用户评论相关的短句,对短句进行分词处理,去除短句中与app功能无关的词汇,获得与app功能相关的目标短句,具体包括以下步骤:通过百度ai开放平台,对用户评论进行纠错处理,得到纠错后用户评论;获取纠错后用户评论,去除纠错后用户评论中的非中文和非英文字符,过滤噪声数据,得到过滤后用户评论;获取过滤后用户评论,通过pyltp工具,将过滤后用户评论进行分句处理,分割成若干短句;通过pyltp工具对短句进行分词,通过停用词表工具,根据停用词表去除短句中停用词,获得目标短句。可选的,根据待挖掘用户评论的app的单条功能描述短语的相关评论集和所有功能描述短语的集合构建回归模型,通过回归模型获得关键功能,具体包括以下步骤:计算待挖掘用户评论的app和每条功能描述短语(,n为功能描述短语个数)在单位时间m内每天收到的情感倾向性评分数目,分别记为和,其中,情感倾向性评分为差评/好评;将作为因变量,所有()作为自变量来构建如下回归模型:其中,是一个常数,是()对应的相关系数;采用后向消除法迭代地过滤出p值最大且大于0.05的自变量并重新建立模型,直到所有剩余自变量的p值都小于0.05为止,与最终剩下的自变量相关的功能即关键功能,并将关键功能按照最终生成模型的相关系数进行排序。进一步的,还提供一种基于用户评论识别app关键功能的装置,包括:app获取模块,用于收集app,获取app描述,并将app描述存储到数据库;第一预处理模块,用于根据app描述,去除app描述中的非功能描述,获得与app功能相关的功能描述;第一构建模块,用于根据app的功能描述,构建深度学习分类器;用户评论获取模块,用于获取app在单位时间m内的用户评论,其中,单位时间m为180天;第二预处理模块,用于对用户评论进行纠错处理,过滤纠错后的用户评论中噪声数据,分割过滤后的用户评论,得到与用户评论相关的短句,对短句进行分词处理,去除短句中与app功能无关的词汇,获得与app功能相关的目标短句;第二构建模块,用于构建相关度分类器;app确定模块,用于确定待挖掘用户评论的app,获取待挖掘用户评论的app的描述和单位时间m内用户评论;第一获取模块,用于待挖掘用户评论的app的描述和在单位时间m内用户评论预处理,获得待挖掘用户评论的app的功能描述和目标短句;调取模块,用于根据待挖掘用户评论的app的类别,调取同类别若干app搭建的深度学习分类器和相关度分类器,获得同类别深度学习分类器和同类别相关度分类器;第二获取模块,用于根据同类别深度学习分类器,获得待挖掘用户评论的app的功能描述短语;第三获取模块,用于根据同类别相关度分类器,将待挖掘用户评论的app的功能描述短语和从评论中获取的目标短句进行匹配,获得待挖掘用户评论的app的与功能描述短语相关和不相关的短句,收集与功能描述短语相关的短句,得到功能描述短语的相关评论集和功能描述短语的集合;第四获取模块,用于根据待挖掘用户评论的app的单条功能描述短语的相关评论集(,n为功能描述短语的个数)和功能描述短语的集合构建回归模型,通过回归模型获得关键功能。可选的,第一预处理模块具体包括:第一预处理单元,用于去除对联系方式和订阅信息进行描述的句子以及其后面的句子,获得第一预处理描述;第二预处理单元,用于去除第一预处理描述中冗余的标点符号、特殊符号、表情符号和除中文和英文以外的其他字符,得到功能描述。可选的,第一构建模块具体包括:第一构建单元,用于通过pyltp工具对功能描述进行分词、词性标注和依存句法解析,获得功能描述的语法解析树;第二构建单元,用于根据功能描述的语法解析树,抽选出候选短语;第三构建单元,用于对候选短语进行分类,分类为功能描述短语和非功能描述短语,将功能描述短语和非功能描述短语存储到数据库,并基于功能描述短语和非功能描述短语训练深度学习分类器;第四构建单元,用于获得深度学习分类器。可选的,第二预处理模块具体包括:第三预处理单元,用于通过百度ai开放平台,对用户评论进行纠错处理,得到纠错后用户评论;第四预处理单元,用于获取纠错后用户评论,去除纠错后用户评论中的非中文和非英文字符,过滤噪声数据,得到过滤后用户评论;第五预处理单元,用于获取过滤后用户评论,通过pyltp工具,将过滤后用户评论进行分句处理,分割成若干短句;第六预处理单元,用于通过pyltp工具对短句进行分词,通过停用词表工具,根据停用词表去除短句中停用词,得到目标短句。可选的,第四获取模块具体包括:计算单元,用于计算待挖掘用户评论的app和每条功能描述短语(,n为功能描述短语个数)在单位时间m内每天收到的情感倾向性评分数目,分别记为和,其中,情感倾向性评分数目为差评/好评;模型建立单元,用于将作为因变量,所有()作为自变量来构建如下回归模型:其中,是一个常数,是()对应的相关系数;滤出单元,用于采用后向消除法迭代地过滤出p值最大且大于0.05的自变量并重新建立模型,直到所有剩余自变量的p值都小于0.05为止,与最终剩下的自变量相关的功能即关键功能,并将关键功能按照最终生成模型的相关系数进行排序。本发明与现有技术相比具有的有益效果是:在本方法及装置中,预先对app描述和用户评论进行处理,去除其中的噪声信息,得到功能描述和目标短句,并构建深度学习分类器和相关度分类器,利用深度学习分类器对功能描述进行处理得到app的功能描述短语,再利用相关度分类器,将功能描述短语和目标短句进行匹配,获得与功能描述短语相关和不相关的短句,收集与功能描述短语相关的短句,得到该功能描述短语的相关评论集和所有功能描述短语的集合,再利用功能描述短语的相关评论集和所有功能描述短语的集合构建回归模型,来识别app的关键功能,以供app开发者进行参考,获取app下一步更新的需求。在本方法及装置中关键功能在评分上升版本的命中率和ndcg均大于评分下降版本的对应值,表明提升关键功能将会有更大的机会使得app的评分上升。本方法及装置能够从app的描述中抽取出app的功能描述短语,然后根据功能描述短语和用户评论识别出app的关键功能,提升这些关键功能能够有效提升app的评分。附图说明图1为本发明方法的流程示意图;图2为本发明方法中s200)具体的流程示意图;图3为本发明方法中s300)具体的流程示意图;图4为本发明方法中s500)具体的流程示意图;图5为本发明方法中s1200)具体的流程示意图;图6为本发明装置的结构框图;图7为本发明装置中第一预处理模块具体的结构框图;图8为本发明装置中第一构建模块具体的结构框图;图9为本发明装置中第二预处理模块具体的结构框图;图10为本发明装置中第四获取模块具体的结构框图;图11为本发明识别app关键功能时的流程图;图12为本发明中对app描述进行处理时的流程图;图13为本发明中对获取功能描述功能的语法解析树的示意图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。作为本发明的一个优选实施例,提供一种基于用户评论识别app关键功能的方法,包括以下步骤:收集app,获取app描述,并将app描述存储到数据库;根据app描述,去除app描述中的非功能描述,获得与app功能相关的功能描述;根据app的功能描述,构建深度学习分类器;获取app在单位时间m内的用户评论,其中,单位时间m为180天;对用户评论进行纠错处理,过滤纠错后的用户评论中噪声数据,分割过滤后的用户评论,得到与用户评论相关的短句,对短句进行分词处理,去除短句中与app功能无关的词汇,获得与app功能相关的目标短句;构建相关度分类器;确定待挖掘用户评论的app,获取待挖掘用户评论的app的描述和单位时间m内用户评论;对待挖掘用户评论的app的描述和在单位时间m内用户评论进行预处理,获得待挖掘用户评论的app的功能描述和目标短句;根据待挖掘用户评论的app的类别,调取同类别若干app搭建的深度学习分类器和相关度分类器,获得同类别深度学习分类器和同类别相关度分类器;根据同类别深度学习分类器,获得待挖掘用户评论的app的功能描述短语;根据同类别相关度分类器,将待挖掘用户评论的app的功能描述短语和从评论中获取的目标短句进行匹配,获得待挖掘用户评论的app的与功能描述短语相关和不相关的短句,收集与功能描述短语相关的短句,得到功能描述短语的相关评论集和功能描述短语的集合;根据待挖掘用户评论的app的单条功能描述短语的相关评论集(,n为功能描述短语的个数)和功能描述短语的集合构建回归模型,通过回归模型获得关键功能。进一步的,还提供一种基于用户评论识别app关键功能的装置,包括:app获取模块,用于收集app,获取app描述,并将app描述存储到数据库;第一预处理模块,用于根据app描述,去除app描述中的非功能描述,获得与app功能相关的功能描述;第一构建模块,用于根据app的功能描述,构建深度学习分类器;用户评论获取模块,用于获取app在单位时间m内的用户评论,其中,单位时间m为180天;第二预处理模块,用于对用户评论进行纠错处理,过滤纠错后的用户评论中噪声数据,分割过滤后的用户评论,得到与用户评论相关的短句,对短句进行分词处理,去除短句中与app功能无关的词汇,获得与app功能相关的目标短句;第二构建模块,用于构建相关度分类器;app确定模块,用于确定待挖掘用户评论的app,获取待挖掘用户评论的app的描述和单位时间m内用户评论;第一获取模块,用于待挖掘用户评论的app的描述和在单位时间m内用户评论预处理,获得待挖掘用户评论的app的功能描述和目标短句;调取模块,用于根据待挖掘用户评论的app的类别,调取同类别若干app搭建的深度学习分类器和相关度分类器,获得同类别深度学习分类器和同类别相关度分类器;第二获取模块,用于根据同类别深度学习分类器,获得待挖掘用户评论的app的功能描述短语;第三获取模块,用于根据同类别相关度分类器,将待挖掘用户评论的app的功能描述短语和从评论中获取的目标短句进行匹配,获得待挖掘用户评论的app的与功能描述短语相关和不相关的短句,收集与功能描述短语相关的短句,得到功能描述短语的相关评论集和功能描述短语的集合;第四获取模块,用于根据待挖掘用户评论的app的单条功能描述短语的相关评论集(,n为功能描述短语的个数)和功能描述短语的集合构建回归模型,通过回归模型获得关键功能。通过该方法及装置的设计,预先对app描述和用户评论进行处理,去除其中的噪声信息,得到功能描述和目标短句,并构建深度学习分类器和相关度分类器,利用深度学习分类器对功能描述进行处理得到app的功能描述短语,再利用相关度分类器,将功能描述短语和目标短句进行匹配,获得与功能描述短语相关和不相关的短句,收集与功能描述短语相关的短句,得到该功能描述短语的相关评论集和所有功能描述短语的集合,再利用功能描述短语的相关评论集和所有功能描述短语的集合构建回归模型,来识别app的关键功能,以供app开发者进行参考,获取app下一步更新的需求。关键功能在评分上升版本的命中率和ndcg均大于评分下降版本的对应值,表明提升关键功能将会有更大的机会使得app的评分上升。能够从app的描述中抽取出app的功能描述短语,然后根据功能描述短语和用户评论识别出app的关键功能,提升这些关键功能能够有效提升app的评分。下面结合附图对本发明的较佳实施例进行说明。功能是app的重要组成部分,app所具有的这些功能的实际表现在很大程度上影响着用户对整个app的评价,app开发者不仅要为用户提供有吸引力的新功能,还要根据用户的反馈对现有功能进行精心维护和改进,以提升app的竞争力。近些年,无论是媒体、社交、电商、音乐、视频,移动应用的社交化越来越成熟,都在培养用户间或强或弱的社交关系和粘性程度,各种app中的评论功能已成为其不可或缺的一部分,评论不再以用户发表意见为唯一目的,还营造出了一种隐藏在屏幕背后的社群关系,易于app培养具有高粘度的核心用户,以及引流有同样兴趣、共鸣的新用户。在很多app中,依靠这种社群关系,涌现出无限的产品智慧。经过长期的研究与分析,总的来说,用户写评论的动机可分为三大类:沟通感情、表达见解和求助。其中,用户为了沟通感情做出的评论多出现在强关系社交app中,例如微信朋友圈,具有很强的针对性、有即时性。用户为了表达见解做出的评论可分为依次递进的三个层次,一般见解、有态度的评判、深度探讨,具体的,一般见解包括对自媒体、音乐、新闻等内容的评价,对反馈期望不高,但是这些评论简洁快速、有即时性;有态度的评判通常在消费,或体验过后进行评价,具有非即时性的特点,需要体验的时间,例如网购、打车、看电影等等;深度讨论一个问题,用户的表达欲比较强烈,对反馈期望很高,因此这些评论篇幅可能较长、有即时性,但是通常更能表达用户的意图信息。用户为了求助做出的评论,在评论中提问,通常会得到其他人的解答,同样这类评论也是简洁快速、有即时性。因此,如何自动地提取评论中的有效信息变得尤为重要,成功挖掘出用户评论中的对app开发者有用的信息并将热点评论信息推荐给开发者成为软件开发中面临的一个重要问题,能够有效地帮助app开发者获取下一步更新的需求。请参阅图1,该方法包括以下步骤:s100)收集app,获取app描述,app描述即一个正式的文本,用于描述app能够做什么和用户能通过该app完成哪些操作,并将app描述存储到数据库。收集的app包含各种类别,包括但不局限于媒体、社交、电商、音乐、视频类等等。由于在移动应用开发中,app版本的更新是很常见的事情,因此在本实施例中,收集的某款app可以包含其当前的最新版本和之前的历史版本。之后获取收集到的app它们自身提供的描述以及在以往更新中发布的更新日志,app当前的描述包含该款app当前所能包含或者能提供的功能,app每次更新时,app的发布者会发布更新日志,来说明新版本所做出的主要改变,这部分说明通常是对于app主要修改的说明,或者重点突出的功能进行说明,之后将获取的app描述存储到数据库中,构建app描述的数据库。s200)app描述预处理:根据app描述,去除app描述中的非功能描述,获得与app功能相关的功能描述,app功能即该app的基本功能或者该app为用户提供的服务。对于一个app开发并上线后发布者提供的自身描述,去除一些与功能明显无关的句子和不相关的符号,以提升后续处理的效率。具体的,请参阅图2,包括以下步骤:s201)去除对联系方式和订阅信息进行描述的句子以及其后面的句子,获得第一预处理描述,例如电子邮件地址、电话号码和会员订阅等等,这样的句子通常出现在描述的末尾而并不描述功能;s202)获得第一预处理描述,去除第一预处理描述中冗余的标点符号、特殊符号、表情符号和除中文和英文以外的其他字符,得到功能描述。冗余的标点符号例如%、#、@等,由于在中文appleappstore或者安卓应用商店中,app的一些功能可能会用英文短语进行描述,因此在该方法中保留英文字符。s300)根据app的功能描述,构建深度学习分类器。具体的,请参阅图3,包括以下步骤:s301)通过pyltp工具对功能描述进行分词、词性标注和依存句法解析,获得功能描述的语法解析树,即该功能描述句子的语法解析树。请参阅图13,以“用户可以发文字信息、图片和视频”为例,通过pyltp工具。先将“用户可以发文字信息、图片和视频”进行分词,得到若干词汇“用户”、“可以”、“发”、“文字”、“消息”、“图片”、“和”、“视频”,之后对这些词汇进行词性标注,“用户”、“文字”、“消息、“图片”、“视频”属于noun(名词),“可以”、“发”属于verb(动词),“和”属于conjunction(连词),之后根据分词结果和词汇的词性,对词汇进行依存句法解析。s302)根据功能描述的语法解析树,抽选出候选短语。该语法解析树反映了该句子中词汇与词汇之间的关系,如vob表示对应的两个词之间是动宾关系。语法解析树中某些关系或者某些关系之间的组合能够表示app功能,本发明中利用识别出的关系和关系之间的组合,在表1中称为模式,来抽取出候选短语,这些模式和对应的例子如表1所示。表1s303)对候选短语进行分类,分类为功能描述短语和非功能描述短语,存储功能描述短语和非功能描述短语到数据库,并基于功能描述短语和非功能描述短语训练深度学习分类器。在本方法中,借助以手动标记后的数据集微调bert(bidirectionalencoderrepresentationsfromtransformers)模型来构建深度学习分类器,特别地,使用了bert的基于中文的预训练模型的单文本分类应用。功能描述短语即能够表示app功能的短语,可以理解的是,非功能描述短语即无法表示app功能的短语。s304)获得深度学习分类器。s400)获取app在单位时间m内的用户评论,在本实施例中,单位时间m为180天。在线跟踪用户评论,在版本更新的时间节点,识别出用户评论中多次提到的功能上的问题,可以得出软件中备受关注的新问题,从而有效地帮助app开发者获取下一步更新的需求,但是由于用户评论具有一定的即时性,经过实验表明,在过去180天内的用户评论的反映效果最好,若app的发布时间小于180天,则收集的评论为该app发布时间内所有的用户评论。s500)用户评论预处理:对用户评论进行纠错处理,过滤纠错后的用户评论中噪声数据,分割过滤后的用户评论,得到用户评论对应的短句,对短句进行分词处理,去除短句中与app功能无关的词汇,获得与app功能相关的目标短句。对于一条用户评论,由于用户评论中一般包含许多噪声数据,例如拼错的单词、非中文也非英文的字符等,这些会影响对数据处理的结果,因此,需要对收集到的用户评论进行数据预处理。具体的,请参阅图4,包括以下步骤:s501)通过百度ai开放平台,对用户评论进行纠错处理(在本实施例中,借助了百度ai开放平台(https://ai.baidu.com/tech/nlp/text_corrector)来进行纠错处理,可以理解的是,该方法中也可以使用其他的与数据集契合的纠错平台/工具,例如国内的黑马校对、腾讯的中文查询纠错框架和国外的grammarly等),得到纠错后用户评论,以减少对未来分析的潜在干扰;s502)获取纠错后用户评论,去除纠错后用户评论中的非中文和非英文字符,过滤噪声数据,得到过滤后用户评论;s503)获取过滤后用户评论,通过pyltp工具,将过滤后用户评论进行分句处理,分割成若干短句;s504)通过pyltp工具对短句进行分词,通过停用词表工具,根据停用词表去除短句中停用词,得到目标短句,在本实施例中,停用词表是在一个中文标准停用词表(https://github.com/goto456/stopwords)的基础上扩展而来的,加入了近万个在用户评论中常见但与app功能明显无关的单词,因此去除的是短句中中文停用词。若用户评论的短句在去除停用词后没有词剩下,即该短句完全由停用词组成,则该短句将被整体去除。s600)构建相关度分类器。本方法中通过另一个分类器来匹配与功能描述短语相关的目标短句(评论),对一个功能描述短语和一条目标短句组成的数据,该分类器返回两者是否相关的结果,即相关/不相关,在本实施例中,使用了bert模型的双文本分类应用,同样是以手动标记后的数据集来对bert进行微调从而获得该分类器。s700)确定待挖掘用户评论的app,获取待挖掘用户评论的app的描述和单位时间m内用户评论。以支付宝app为例,其描述为“蚂蚁金服旗下的支付宝,是服务全球12亿用户的数字生活开放平台。支付宝上有支付、理财、生活服务、政务服务、公益等多个场景与行业的服务,服务类别超过一千种。除提供安全便捷的支付、转账、收款等基础功能外,还能快速完成信用卡还款、充话费、缴水电煤等。各种服务,上支付宝搜,可一键直达。生活好,支付宝!”,本方法通过该描述和支付宝app180天内的所有评论为输入来识别其关键功能。s800)待挖掘用户评论的app的描述和在单位时间m内用户评论预处理,获得待挖掘用户评论的app的功能描述和目标短句:采用上述的s200)和s400)分别对待挖掘用户评论的app的描述和在单位时间m内用户评论进行处理,在此不作过多阐述。如支付宝app的用户评论“好好好!”会被直接去除,从支付宝app描述中抽取出候选短语。s900)根据待挖掘用户评论的app的类别,调取同类别若干app搭建的深度学习分类器和相关度分类器,获得同类别深度学习分类器和同类别相关度分类器。s1000)根据同类别深度学习分类器,获得待挖掘用户评论的app的功能描述短语。s1100)根据同类别相关度分类器,将待挖掘用户评论的app的功能描述短语和从评论中获取的目标短句进行匹配,获得待挖掘用户评论的app的与功能描述短语相关和不相关的短句,收集与功能描述短语相关的短句,得到功能描述短语的相关评论集和功能描述短语的集合。即通过相关度分类器,将app功能与用户评论进行间接性的匹配,获得与app功能相关和不相关的评论。采用上述的s300),使用该深度学习分类器来对这些候选短语进行分类,从而获得支付宝的功能描述短语,在此不做过多阐述。例如,从支付宝app所属类别中选择10个app,之前已经对它们的描述按照本方法进行预处理和抽取候选短语,手工标注每条候选短语是否为功能描述短语,得到功能描述短语和非功能描述短语的数据集,并根据该数据集来训练bert模型,得到了它们的深度学习分类器,调取该深度学习分类器,经预处理和深度学习分类器分类后,获得的支付宝app的功能描述短语如下:支付、理财、生活服务、政务服务、公益、转账、收款、信用卡还款、充话费、缴水电煤。同时,之前已经对上述10个app其对应评论库中各随机抽取出3000条用户评论,将这些用户评论经过预处理得到目标短句,每个app的功能描述短语和每条目标短句组成一条数据,手工对这些数据进行标注,将其标注为数据中的功能和评论相关或者不相关,利用标注好的数据集来训练bert模型,得到了它们的相关度分类器。接下来根据该相关度分类器,将待挖掘用户评论的app的功能描述短语和目标短句进行匹配,获得待挖掘用户评论的app的与各个功能描述短语相关和不相关的短句,收集与待挖掘用户评论的app的各个功能描述短语相关的短句,得到这些功能描述短语的相关评论集。s1200)根据待挖掘用户评论的app的单条功能描述短语的相关评论集(,n为功能描述短语的个数)和功能描述短语的集合构建回归模型,通过回归模型获得关键功能,该关键功能可以供app开发者进行参考,获取app下一步更新的需求。具体的,请参阅图5,包括以下步骤:s1201)计算待挖掘用户评论的app的每条功能描述短语(,n为功能描述短语个数)在单位时间m内每天收到的情感倾向性评分数目,分别记为和,在本实施例中,情感倾向性评分数目为差评/好评。s1202)将作为因变量,所有()作为自变量来构建如下回归模型:其中,是一个常数(该常数在不同情况下会产生不同的值,而不是一个固定值),是()对应的相关系数。本方法使用python的statsmodel包构建回归模型,它在构建回归模型时会对每个自变量产生一个p值,表示当前构建的模型中该自变量与因变量之间是否具有显著关系,当p值小于0.05表示对应的自变量和因变量是显著相关的,当p值大于0.05则无法说明两者显著相关,此时表明该变量并不适合作为自变量。s1203)采用后向消除法迭代地过滤出p值最大且大于0.05的自变量并重新建立模型,直到所有剩余自变量的p值都小于0.05为止,与最终剩下的自变量相关的功能即关键功能,并将关键功能按照最终生成模型的相关系数进行排序。即本方法通过多元线性回归来识别与app评分具有显著关系的关键功能,这一步骤的输入的功能描述短语集合,和每个功能对应的用户评论集合,输出为关键功能及其排序列表。与本发明提出的方法较为接近的方法有ehsan等人提出的识别关键主题的方法(参考文献:ehsannoei,fengzhang,andyingzou.2019.toomanyuser-reviews,whatshouldappdeveloperslookatfirst,ieeetransactionsonsoftwareengineering(2019))和timo等人提出的从描述和评论中抽取出app功能并将两者相互匹配的方法(参考文献:timojohann,christophstanik,walidmaalej,etal.2017.safe:asimpleapproachforfeatureextractionfromappdescriptionsandappreviews.ininternationalrequirementsengineeringconference(re).ieee,21–30)。在ehsan的方法中,通过主题建模技术从一类app的评论中识别该类别app的共同主题,然后设计了主题的27个度量,最后使用pmvd方法和27个度量来识别出与该类别app评分高度相关的功能。该方法的缺陷在于其只能根据类别识别出有限的几个主题,对单个app的实用性较低。而在timo的方法中,通过词性和词性的组合模式来从描述和评论中抽取出app的功能,然后通过单词匹配、同义词匹配和语义相似度来获取在描述和评论中都被提及的功能。该方法的缺陷在于其效率较低,在召回率、精准率、f值上均不理想,且方法得出的结果比较简单,难有实际作用。在本方法中,预先对app描述和用户评论进行处理,去除其中的噪声信息,得到功能描述和目标短句,并构建深度学习分类器和相关度分类器,利用深度学习分类器对功能描述进行处理得到app的描述短语,再利用相关度分类器,将功能描述短语和目标短句进行匹配,获得与功能描述短语相关和不相关的短句,收集与功能描述短语相关的短句,得到该功能描述短语的相关评论集和所有功能描述短语的集合,再利用功能描述短语的相关评论集和所有功能描述短语的集合构建回归模型,来识别app的关键功能,以供app开发者进行参考,获取app下一步更新的需求。在本方法中关键功能在评分上升版本的命中率和ndcg(normalizeddiscountedcumulativegain)均大于评分下降版本的对应值,表明提升关键功能将会有更大的机会使得app的评分上升。本方法能够从app的描述中抽取出app的功能描述短语,然后根据功能描述短语和用户评论识别出app的关键功能,提升这些关键功能能够有效提升app的评分。我们首先从appleappstore中随机选择了10个分类,然后每个分类随机选择了5个app,然后运用我们的方法从上述50个app的描述中抽取功能,表1给出了我们的方法和已有方法在功能抽取的性能的比较,由于本方法是第一个从中文抽取出app功能的方法,表2比较了本方法和对英文进行处理的方法的性能,结果表明本方法能达到它们的程度甚至在精准率、f值和准确率上都有显著提升。其中,准确率表示预测正确的样本数占总样本书的比例,精确率表示预测为正样本的样本中正确预测为正样本的概率,召回率表示正确预测出正样本占实际正样本的概率。f值(f1score)折中了召回率与精确率。表2精准率召回率f值准确率本方法82.7%72.44%76.75%86.82%对比例155.9%43.40%45.60%na对比例261.79%80.27%69.11%69.57%注:对比例1采用的是定义为safe的处理方法(参阅链接:https://ieeexplore.ieee.org/document/8048887),此方法从单个app页面、单个评论中提取app的特征,将户评论中提取的功能与从应用程序描述中提取的功能进行匹配。对比例2采用的是定义为safer的处理方法,此方法来从app描述中提取特征,建立一个模型,然后利用建立的模型根据提取的特征和app的api名称来识别相似的应用程序,将识别出的相似应的app的特征并推荐给指定的app(参阅链接:https://dl.acm.org/doi/abs/10.1145/3344158)。然后,我们随机选择了5个app来验证关键功能和app评分变化的关系,验证了在评分上升版本和评分下降版本中,关键功能的命中率和ndcg。从表中可以看出,关键功能在评分上升版本的命中率和ndcg均大于评分下降版本的对应值,表明提升关键功能将会有更大的机会使得app的评分上升,如表3所示。表3请参阅图6,该装置包括:app获取模块,用于收集app,获取app描述,app描述即一个正式的文本,用于描述app能够做什么和用户能通过该app完成哪些操作,并将app描述存储到数据库。收集的app包含各种类别,包括但不局限于媒体、社交、电商、音乐、视频类等等。由于在移动应用开发中,app版本的更新是很常见的事情,因此在本实施例中,收集的某款app可以包含其当前的最新版本和之前的历史版本。之后获取收集到的app它们自身提供的描述以及在以往更新中发布的更新日志,app当前的描述包含该款app当前所能包含或者能提供的功能,app每次更新时,app的发布者会发布更新日志,来说明新版本所做出的主要改变,这部分说明通常是对于app主要修改的说明,或者重点突出的功能进行说明,之后将获取的app描述存储到数据库中,构建app描述的数据库。第一预处理模块,用于进行app描述预处理,根据app描述,去除app描述中的非功能描述,获得与app功能相关的功能描述,app功能即该app的基本功能或者该app为用户提供的服务。对于一个app开发并上线后发布者提供的自身描述,去除一些与功能明显无关的句子和不相关的符号,以提升后续处理的效率。具体的,请参阅图7,第一预处理模块包括:第一预处理单元,用于去除对联系方式和订阅信息进行描述的句子以及其后面的句子,获得第一预处理描述,例如电子邮件地址、电话号码和会员订阅等等,这样的句子通常出现在描述的末尾而并不描述功能;第二预处理单元,用于获得第一预处理描述,去除第一预处理描述中冗余的标点符号、特殊符号、表情符号和除中文和英文以外的其他字符,得到功能描述。冗余的标点符号例如%、#、@等,由于在中文appleappstore或者安卓应用商店中,app的一些功能可能会用英文短语进行描述,因此在该装置中保留英文字符。第一构建模块,用于根据app的功能描述,构建深度学习分类器。具体的,请参阅图3,第一构建包括:第一构建单元,用于通过pyltp工具对功能描述进行分词、词性标注和依存句法解析,获得功能描述的语法解析树,即该功能描述句子的语法解析树。请参阅图13,以“用户可以发文字信息、图片和视频”为例,通过pyltp工具。先将“用户可以发文字信息、图片和视频”进行分词,得到若干词汇“用户”、“可以”、“发”、“文字”、“消息”、“图片”、“和”、“视频”,之后对这些词汇进行词性标注,“用户”、“文字”、“消息、“图片”、“视频”属于noun(名词),“可以”、“发”属于verb(动词),“和”属于conjunction(连词),之后根据分词结果和词汇的词性,对词汇进行依存句法解析。第二构建单元,用于根据功能描述的语法解析树,抽选出候选短语。该语法解析树反映了该句子中词汇与词汇之间的关系,如vob表示对应的两个词之间是动宾关系。语法解析树中某些关系或者某些关系之间的组合能够表示app功能,本发明中利用识别出的关系和关系之间的组合,在表1中称为模式,来抽取出候选短语,这些模式和对应的例子如表4所示。表4第三构建单元,用于对候选短语进行分类,分类为功能描述短语和非功能描述短语,存储功能描述短语和非功能描述短语到数据库,并基于功能描述短语和非功能描述短语训练深度学习分类器。在本装置中,借助以手动标记后的数据集微调bert(bidirectionalencoderrepresentationsfromtransformers)模型来构建深度学习分类器,特别地,使用了bert的基于中文的预训练模型的单文本分类应用。功能描述短语即能够表示app功能的短语,可以理解的是,非功能描述短语即无法表示app功能的短语。第四构架尿胆原,用于获得深度学习分类器。用户评论获取模块,用于获取app在单位时间m内的用户评论,在本实施例中,单位时间m为180天。在线跟踪用户评论,在版本更新的时间节点,识别出用户评论中多次提到的功能上的问题,可以得出软件中备受关注的新问题,从而有效地帮助app开发者获取下一步更新的需求,但是由于用户评论具有一定的即时性,经过实验表明,在过去180天内的用户评论的反映效果最好,若app的发布时间小于180天,则收集的评论为该app发布时间内所有的用户评论。第二预处理模块,用于对用户评论进行预处理,对用户评论进行纠错处理,过滤纠错后的用户评论中噪声数据,分割过滤后的用户评论,得到用户评论对应的短句,对短句进行分词处理,去除短句中与app功能无关的词汇,获得与app功能相关的目标短句。对于一条用户评论,由于用户评论中一般包含许多噪声数据,例如拼错的单词、非中文也非英文的字符等,这些会影响对数据处理的结果,因此,需要对收集到的用户评论进行数据预处理。具体的,请参阅图4,第二预处理模块包括:第三预处理模块,用于通过百度ai开放平台,对用户评论进行纠错处理(在本实施例中,借助了百度ai开放平台来进行纠错处理,可以理解的是,不仅仅可以时百度ai开放平台(https://ai.baidu.com/tech/nlp/text_corrector),该装置中也可以使用其他的与数据集契合的纠错平台/工具,例如国内的黑马校对、腾讯的中文查询纠错框架和国外的grammarly等),得到纠错后用户评论,以减少对未来分析的潜在干扰;第四预处理模块,用于获取纠错后用户评论,去除纠错后用户评论中的非中文和非英文字符,过滤噪声数据,得到过滤后用户评论;第五预处理模块,用于获取过滤后用户评论,通过pyltp工具,将过滤后用户评论进行分句处理,分割成若干短句;第六预处理模块,用于通过pyltp工具对短句进行分词,通过停用词表工具,根据停用词表去除短句中停用词,得到目标短句,在本实施例中,停用词表是在一个中文标准停用词表(https://github.com/goto456/stopwords)的基础上扩展而来的,加入了近万个在用户评论中常见但与app功能明显无关的单词,因此去除的是短句中中文停用词。若用户评论的短句在去除停用词后没有词剩下,即该短句完全由停用词组成,则该短句将被整体去除。第二构建模块,用于构建相关度分类器。本装置中通过另一个分类器来匹配与功能描述短语相关的目标短句(评论),对一个功能描述短语和一条目标短句组成的数据,该分类器返回两者是否相关的结果,即相关/不相关,在本实施例中,使用了bert模型的双文本分类应用,同样是以手动标记后的数据集来对bert进行微调从而获得该分类器。app确定模块,用于确定待挖掘用户评论的app,获取待挖掘用户评论的app的描述和单位时间m内用户评论。以支付宝app为例,其描述为“蚂蚁金服旗下的支付宝,是服务全球12亿用户的数字生活开放平台。支付宝上有支付、理财、生活服务、政务服务、公益等多个场景与行业的服务,服务类别超过一千种。除提供安全便捷的支付、转账、收款等基础功能外,还能快速完成信用卡还款、充话费、缴水电煤等。各种服务,上支付宝搜,可一键直达。生活好,支付宝!”,本装置通过该描述和支付宝app180天内的所有评论为输入来识别其关键功能。第一获取模块,用于对待挖掘用户评论的app的描述和在单位时间m内用户评论进行预处理,获得待挖掘用户评论的app的功能描述和目标短句:采用上述的s200)和s400)分别对待挖掘用户评论的app的描述和在单位时间m内用户评论进行处理,在此不作过多阐述。如支付宝app的用户评论“好好好!”会被直接去除,从支付宝app描述中抽取出候选短语。调取模块,用于根据待挖掘用户评论的app的类别,调取同类别若干app搭建的深度学习分类器和相关度分类器,获得同类别深度学习分类器和同类别相关度分类器。第二获取模块,用于根据同类别深度学习分类器,获得待挖掘用户评论的app的功能描述短语。第三获取模块,用于根据同类别相关度分类器,将待挖掘用户评论的app的功能描述短语和从评论中获取的目标短句进行匹配,获得待挖掘用户评论的app的与功能描述短语相关和不相关的短句,收集与功能描述短语相关的短句,得到功能描述短语的相关评论集和功能描述短语的集合。即通过相关度分类器,将app功能与用户评论进行间接性的匹配,获得与app功能相关和不相关的评论。采用上述的第一构成模块,使用该深度学习分类器来对这些候选短语进行分类,从而获得支付宝的功能描述短语,在此不做过多阐述。例如,从支付宝app所属类别中选择10个app,之前已经对它们的描述按照本装置进行预处理和抽取候选短语,手工标注每条候选短语是否为功能描述短语,得到功能描述短语和非功能描述短语的数据集,并根据该数据集来训练bert模型,得到了它们的深度学习分类器,调取该深度学习分类器,经预处理和深度学习分类器分类后,获得的支付宝app的功能描述短语如下:支付、理财、生活服务、政务服务、公益、转账、收款、信用卡还款、充话费、缴水电煤。同时,之前已经对上述10个app其对应评论库中各随机抽取出3000条用户评论,将这些用户评论经过预处理得到目标短句,每个app的功能描述短语和每条目标短句组成一条数据,手工对这些数据进行标注,将其标注为数据中的功能和评论相关或者不相关,利用标注好的数据集来训练bert模型,得到了它们的相关度分类器。接下来根据该相关度分类器,将待挖掘用户评论的app的功能描述短语和目标短句进行匹配,获得待挖掘用户评论的app的与各个功能描述短语相关和不相关的短句,收集与待挖掘用户评论的app的各个功能描述短语相关的短句,得到这些功能描述短语的相关评论集。第四获取模块,用于根据待挖掘用户评论的app的单条功能描述短语的相关评论集(,n为功能描述短语的个数)和功能描述短语的集合构建回归模型,通过回归模型获得关键功能,该关键功能可以供app开发者进行参考,获取app下一步更新的需求。具体的,请参阅图5,包括以下步骤:计算单元,用于计算待挖掘用户评论的app的每条功能描述短语(,n为功能描述短语个数)在单位时间m内每天收到的情感倾向性评分数目,分别记为和,在本实施例中,情感倾向性评分数目为差评/好评。模型建立单元,用于将作为因变量,所有()作为自变量来构建如下回归模型:其中,是一个常数(该常数在不同情况下会产生不同的值,而不是一个固定值),是()对应的相关系数。本装置使用python的statsmodel包构建回归模型,它在构建回归模型时会对每个自变量产生一个p值,表示当前构建的模型中该自变量与因变量之间是否具有显著关系,当p值小于0.05表示对应的自变量和因变量是显著相关的,当p值大于0.05则无法说明两者显著相关,此时表明该变量并不适合作为自变量。滤出单元,用于采用后向消除法迭代地过滤出p值最大且大于0.05的自变量并重新建立模型,直到所有剩余自变量的p值都小于0.05为止,与最终剩下的自变量相关的功能即关键功能,并将关键功能按照最终生成模型的相关系数进行排序。即本装置通过多元线性回归来识别与app评分具有显著关系的关键功能,这一步骤的输入的功能描述短语集合,和每个功能对应的用户评论集合,输出为关键功能及其排序列表。在本装置中,预先对app描述和用户评论进行处理,去除其中的噪声信息,得到功能描述和目标短句,并构建深度学习分类器和相关度分类器,利用深度学习分类器对功能描述进行处理得到app的描述短语,再利用相关度分类器,将功能描述短语和目标短句进行匹配,获得与功能描述短语相关和不相关的短句,收集与功能描述短语相关的短句,得到该功能描述短语的相关评论集和所有功能描述短语的集合,再利用功能描述短语的相关评论集和所有功能描述短语的集合构建回归模型,来识别app的关键功能,以供app开发者进行参考,获取app下一步更新的需求。在本装置中关键功能在评分上升版本的命中率和ndcg(normalizeddiscountedcumulativegain)均大于评分下降版本的对应值,表明提升关键功能将会有更大的机会使得app的评分上升。本装置能够从app的描述中抽取出app的功能描述短语,然后根据功能描述短语和用户评论识别出app的关键功能,提升这些关键功能能够有效提升app的评分。我们首先从appleappstore中随机选择了10个分类,然后每个分类随机选择了5个app,然后运用我们的装置从上述50个app的描述中抽取功能,表1给出了我们的装置和已有装置在功能抽取的性能的比较,由于本装置是第一个从中文抽取出app功能的装置,表5比较了本装置和对英文进行处理的装置的性能,结果表明本装置能达到它们的程度甚至在精准率、f值和准确率上都有显著提升。其中,准确率表示预测正确的样本数占总样本书的比例,精确率表示预测为正样本的样本中正确预测为正样本的概率,召回率表示正确预测出正样本占实际正样本的概率。f值(f1score)折中了召回率与精确率。表5精准率召回率f值准确率本装置82.7%72.44%76.75%86.82%对比例155.9%43.40%45.60%na对比例261.79%80.27%69.11%69.57%注:对比例1采用的是定义为safe的处理方法(参阅链接:https://ieeexplore.ieee.org/document/8048887),此方法从单个app页面、单个评论中提取app的特征,将户评论中提取的功能与从应用程序描述中提取的功能进行匹配。对比例2采用的是定义为safer的处理方法,此方法来从app描述中提取特征,建立一个模型,然后利用建立的模型根据提取的特征和app的api名称来识别相似的应用程序,将识别出的相似应的app的特征并推荐给指定的app(参阅链接:https://dl.acm.org/doi/abs/10.1145/3344158)。然后,我们随机选择了5个app来验证关键功能和app评分变化的关系,验证了在评分上升版本和评分下降版本中,关键功能的命中率和ndcg。从表中可以看出,关键功能在评分上升版本的命中率和ndcg均大于评分下降版本的对应值,表明提升关键功能将会有更大的机会使得app的评分上升,如表2所示。表6当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1