一种广域网环境中分布式系统的计算任务分配方法与流程
本发明属于分布式系统高性能计算技术领域,涉及一种分布式计算系统中的任务分配方法,具体涉及部署在广域网环境的计算系统中进行去中心化任务量调节的方法。
背景技术:
广域网环境通常跨接非常大的物理范围,超过了集线器所连接的距离,节点间的通信往往会经历复杂的路由。广域网环境的分布式计算任务通常包含网络边缘大量的数据的源点和汇点,前者产生持续的数据流入广域网,后者需要从广域网中获取所需数据。广域网的部分路由节点处部署着有一定计算能力的服务器或数据中心,负责处理和暂存数据。
当分布式系统的计算节点分散在广域网各处时,需要考虑如何将分布式计算任务合理地分配到各个计算节点上,以增加系统的可扩展性,降低计算和数据传输过程的延迟。该过程一般是动态的,即系统应综合考虑当前各个节点的负载和网络拥堵情况等因素,实时调整任务在这些节点上的分配。
传统的分配算法存在以下不足之处:
(1)传统的资源分配方法一般依托于数据中心。在这种场景下,各个计算节点之间高速互联,在这些节点间分配、迁移计算任务代价并不高。然而在基于广域网中的分布式计算系统中,计算节点之间的连接关系并不对称:路由距离较近的节点之间的数据传输速率更高,路由距离较远的节点之间数据传输有显著的延迟,靠近数据源的计算节点会更加适合执行这些计算任务。不考虑这一特性的资源分配方法会显著影响系统的执行效率。
(2)传统的资源分配方法需要实时获取系统中各个计算节点的负载状况,并据此做出合理的任务分配。然而,广域网中的分布式计算系统的节点通信代价不可忽略,很难实时地将所有节点的状态汇聚到同一个中心节点。因此,中心化的资源分配算法很难对系统中的突发状况做出及时反应,如数据源的突发流量、计算节点的可用资源变化等。
(3)在分布式系统的计算节点增加时,负责资源分配的专门节点容易成为系统的瓶颈。该节点需要与大量的计算节点通信,以获取它们的运行状态并发送调度信息;需要维护相应的数据结构,记录所有计算节点的各类属性;需要运行资源分配算法,将任务分配到合适的计算节点上。这些可扩展性问题在广域网中更加突出:各节点间的通信延迟更高、计算节点的异构性导致其属性更丰富、网络中可用的计算节点的数目更加庞大。
综上所述,现有传统的计算任务分配算法无法迁移到广域网环境的分布式计算场景,难以解决广域网环境的分布式计算系统的可扩展性问题,从而导致系统整体不可用。
技术实现要素:
为了克服上述现有技术的不足,本发明了提供一种广域网中的去中心化计算任务分配方法,可以在无需引入中心化调度节点的前提下,通过相邻计算节点之间的任务交换,自动调节系统中各个节点的任务量分配。这种方法避免了因少数调度节点故障而导致的系统整体不可用问题,同时提高了广域网环境的分布式计算系统的可扩展性。
在本发明中,广域网环境的分布式计算系统包含三类节点:数据源节点,数据汇节点,中间节点。数据源节点负责产生数据流输入计算系统,数据汇节点从计算系统中接收所需要的数据流,中间节点负责数据流的转发和计算过程。这些节点连接成网络,数据源和数据汇节点分布在该网络的边缘,通常只有一个中间节点与之相连;中间节点分布在网络内部,通常有两个或以上的节点与之相连。
系统中的计算任务以数据流为核心。数据流指代连续不断的数据序列,用户可以在数据流上定义计算方案,该计算方案以这个序列中的每一条数据为输入,遵循用户给定的计算逻辑,产生不定量的新数据条目。这些新的数据条目组成了新的数据流。每个数据源节点提供一个数据流,一个数据汇节点可以接收一个或多个数据流,同一个数据流可能流入多个数据汇节点。在到达数据汇节点之前,数据流上的计算必须全部完成。本发明通过相邻中间节点的计算任务调整,动态分配各个中间节点所执行的计算量,降低计算和传递的延迟。
本发明的技术方案是:
一种广域网环境中分布式系统的计算任务分配方法,系统包括多个数据源节点、数据汇节点、数据源节点与数据汇节点之间的中间节点;数据流由数据源节点产生,在中间节点完成计算,最后流入到数据汇节点;本发明通过对相邻节点的计算任务进行调整与分配,使得同一数据流中各个数据条目从生成到完成使用的计算时间尽可能接近,通过动态分配各个节点所承载的计算量降低计算和传递的延迟;包含以下步骤:
a.获取数据传输路径;
系统中由数据汇节点发起新任务。首先找到任务所涉及到的所有数据源节点,确定每个数据源节点到数据汇节点之间的路径。该路径上的中间节点需要共同完成该新任务的所有计算。然后,该路径上的每一个中间节点为该新任务设置多个统计量,包括设定计算比率,代表当处理来自该新任务的数据流时,在本中间节点完成计算的数据条目数量的占比(占新任务的数据流的数据条目总数量的比例)。对各个统计量进行初始化。
b.初始化过程完成后,数据传输开始。
数据源节点生成数据流中的条目,并通过数据传输路径发送到数据汇节点。当数据流的条目传输到中间节点时,首先会被放置在一个数据缓冲区,等待执行。如果当前中间节点执行的数据条目占比超过了计算比率,则将生成时间最早的部分条目(设定条目数量)发送到路径上的下一个节点。当当前中间节点的计算资源空闲时,它将按生成时间从旧到新,依次执行各个数据流中条目的计算任务。
c.中间节点定期发起与所有相邻节点的同步,对比同数据流的各个数据条目从生成到完成计算的时间的平均值。值较大的一方降低其计算比率,较小的一方增大其计算比率。
通过上述步骤,实现广域网环境计算系统中的任务量调节,实现广域网环境中分布式系统的计算任务分配。
与现有技术相比,本发明的有益效果是:
本发明提供一种广域网环境计算系统中的任务量去中心化调节方法。该方法通过相邻节点的计算任务调整,动态分配系统中各个节点所执行的计算量,降低计算和传递的延迟。这种方法的技术优势在于:
本发明没有任何中心化的调度节点,避免了因少数调度节点故障而导致的系统整体不可用问题,同时提高了广域网环境的分布式计算系统的可扩展性。
附图说明
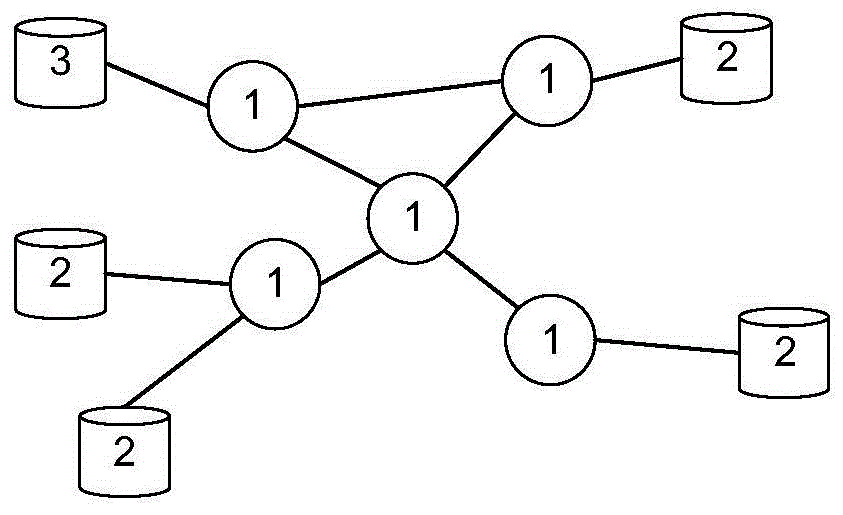
图1为本发明具体实施采用的广域网环境分布式计算系统的底层结构示意图;
其中,1为中间节点,2为数据源节点,3为数据汇节点。
图2为本发明中计算任务的初始化流程框图。
图3为本发明中中间节点执行计算的流程框图。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种广域网环境中分布式系统的计算任务分配方法,广域网环境中分布式系统包括多个数据源节点、数据汇节点和中间节点;数据流由数据源节点产生,在中间节点完成计算,最后流入到数据汇节点;本发明通过相邻节点的计算任务调整,使得同数据流中各个数据条目从生成到完成计算的时间尽可能接近,通过动态分配各个节点所承载的计算量降低计算和传递的延迟。本发明方法包含以下步骤:
a.系统中由数据汇节点发起新任务。
首先找到任务所涉及到的所有数据源节点,确定每个数据源节点到数据汇节点之间的路径。路径上的中间节点需要共同完成该任务的所有计算。然后,中间节点为该任务设定计算比率,代表当处理来自该任务的数据流时,在本节点完成计算的数据条目数量占比。
b.初始化过程完成后,数据传输开始。
数据源节点生成数据流中的条目,并通过前述路径发送到数据汇节点。当数据流的条目传输到中间节点时,首先会被放置在一个数据缓冲区,等待执行。如果当前执行的数据条目占比超过了计算比率,则将生成时间最早的部分条目发送到路径上的下一个节点。当中间节点的计算资源空闲时,它将按生成时间从旧到新,依次执行各个数据流中条目的计算任务。
c.中间节点定期发起与所有相邻节点的同步,对比同数据流的各个数据条目从生成到完成计算的时间的平均值。值较大的一方降低其计算比率,较小的一方增大其计算比率。
图1为本发明具体实施采用的广域网环境分布式计算系统的底层结构示意图,其中1为中间节点,2为数据源节点,3为数据汇节点。某些节点之间有通路连接,表示二者之间可以进行数据传输;没有相连的节点间无法直接传输数据,只能通过其他节点中转。
具体实施包含以下步骤:
a.系统中由数据汇节点d发起新任务。首先,通过传统路由算法找到新任务所涉及到的所有数据源节点{si}i=1…r,并确定每个数据源节点到数据汇节点之间的路径,r为数据源节点的数量;以数据源节点si与数据汇节点d之间的路径sin1n2…nkd为例。该路径共包含n1~nk共k个中间节点,这些节点需要共同完成该新任务的所有计算。
b.每一个中间节点nj(1≤j≤k),为该新任务设定计算比率αj(αj<1)。
αj代表当本节点处理来自该新任务的数据流时,每k个数据条目中有αjk个条目在本节点完成计算。新任务开始时,所有中间节点的计算比率均设置为1。该节点nj也会为该任务分配两个统计量mj和nj,前者表示已经执行的条目数,后者表示遇到的所有该任务的条目数,二者均初始化为0。同时,使用pj代表当前节点处理的该数据流中,每个数据条目从生成到完成计算的总时间;使用qj代表当前周期内已执行的条目数,二者均初始化为0。初始化过程如附图2所示。
c.初始化过程完成后,数据传输开始。数据源节点si生成数据流中的条目,并通过路径sin1n2…nkd发送到数据汇节点,每个条目附带生成时间τ。
d.当数据流的条目传输到中间节点nj时,首先会被放置在一个数据缓冲区,等待执行。该任务在本节点的统计量nj自增1。如果
e.当中间节点nj的计算资源空闲时,它将按生成时间从旧到新,依次执行各个数据流中条目的计算任务。在当前节点完成某任务中一个条目的计算时,对应的统计量mj自增1。同时记录当前时间t,统计量pj自增t-τ(即该条目从生成到完成计算的时长),qj自增1。中间节点执行计算的流程如附图3所示。
f.当前中间节点以p为更新周期定期发起与所有相邻节点的同步:
与每一个相邻的中间节点对比同一数据流的
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的,包括但不限于:计算比率αj的调整方式、更新周期p的动态调整等。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!