一种基于波动率的通勤出行模式识别方法与流程
本发明涉及od区域客流预测的lstm网络数据预处理方法,特别涉及一种基于波动率的通勤出行模式识别方法。
背景技术:
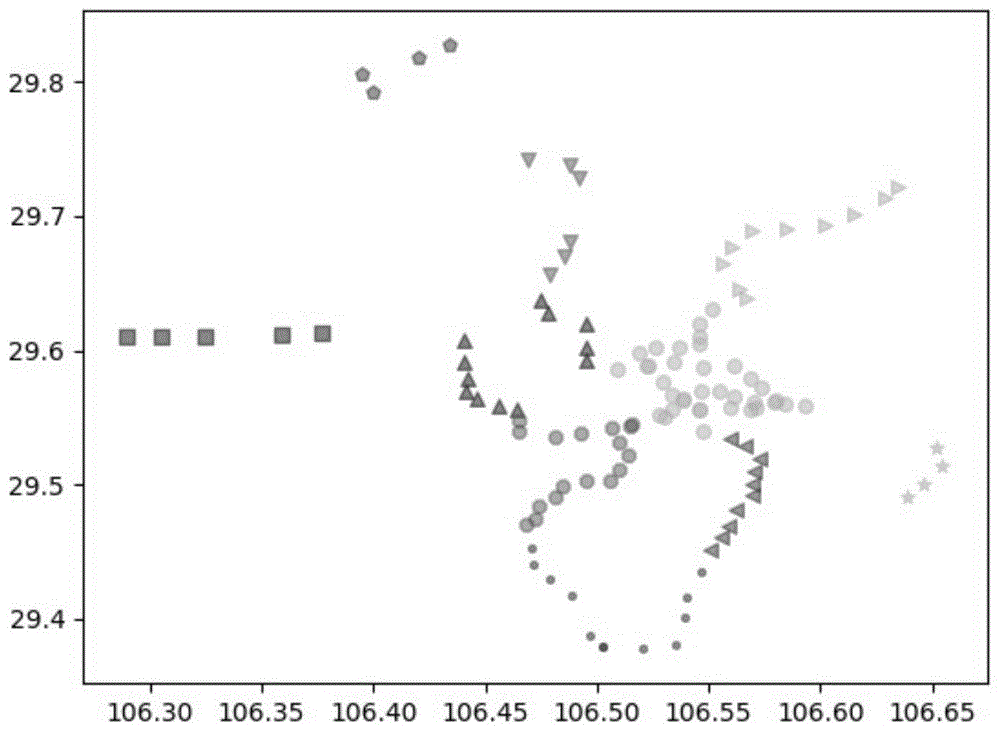
:随着世界城市现代化进程的发展,以及城市内各种商圈的逐渐兴起与发展,使得城市经济不断繁荣,与此同时,城市居民数量也在迅速的增加,道路机动车的数量日益增长,为城市道路交通带来非常巨大的压力。由于固有的城市道路数量并不能跟的上城市居民的出行需求,导致城市道路拥堵状况愈发严重。而道路交通的拥堵严重制约城市经济发展,成为制约城市现代化发展的重要问题。由于近年来,城市内文化交流频繁,包括各种大型活动的举办,以及节假日导致的居民城市居民出行量在不断增加,非常容易造成短时间内客流的突发增长。城市居民生活质量不断提升,对出行的舒适度、便捷度要求也在不断增长。城市轨道交通以其方便、快捷、准时、客运量大的优点成为解决城市道路拥堵的重要交通工具之一。现在重庆市居民的出行以轨道交通作为重要的出行方式,所以对于重庆市来说轨道交通已经成为城市交通的主动脉,成为缓解客流拥堵状况的重要方式。在重庆,每天有超过200万人的客流量进出城市轨道交通。城市轨道交通的网络化复杂程度不断增加,未来交通趋势分析越来越受到重视,基于区域od客流预测的分析结果,我们可以制定交通运营计划,做出拥堵或异常的预警,来改善轨道交通的运营效率和服务质量,所以它已成为智能交通系统(its)的关键技术之一。区域od的客流预测以历史客流作为切入点进行研究,对城市轨道交通进行站点区域划分、区域客流出行模式进行识别,从而可以有效给予拥堵或异常的预警。技术实现要素:针对现有技术存在的上述问题,本发明要解决的技术问题是:提供一种可以有效识别通勤出行模式的方法。为解决上述技术问题,本发明采用如下技术方案:一种基于波动率的通勤出行模式识别方法,包括如下步骤:s10:进行城市区域划分;s11:通过城市现有的行政和功能区域划分规划区域划分聚类个数和聚类范围:取所有n个研究对象站点x作为聚类数据集ω,ω={x1,x2,x3……xn};将所有研究对象站点分别归类到k个站点区域集合θi中,θi={xi,1,xi,2,xi,3……},i∈{1,2,3,4…,k};s12:使用k-means算法进行聚类,随机选择聚类中心,针对聚类数据集ω中的每个站点,计算每个站点到各个聚类中心点的影响距离确定站点xi到哪个聚类中心的影响距离最小,就将站点xi划分到该聚类中心的类中,输出聚类中心和各个类中的所有站点;s20:通勤出行模式识别;s21:每个聚类中心和该聚类中心的所有站点构成一个研究对象区域,两个研究对象区域组成的一组研究对象区域;对一组研究对象区域随机抽取若干个工作日的每小时客流统计数据ai,24个小时的客流数据组成数据集ψ,ψ={a1,a2,a3…a24};s22:分别计算24-n个客流波动率si,检索24-n个客流波动率si,计数大于阈值的波动率个数q:若q=4且四个波动率峰值分别对应早高峰和晚高峰的起止时间点,那么这一对研究对象区域被识别为通勤出行模式。作为改进,所述s12随机选择聚类中心的方法为:1)从聚类数据集ω中随机选取一个站点作为初始聚类中心c1,通过公式(1)计算站点xi与聚类中心点cj的欧氏距离用通过公式(2)计算站点xi被选为下一个聚类中心点的概率其中,k是坐标参数维度,xik和cjk分别表示站点xi与聚类中心点c1的第k维数据;2)按照每一个站点xi的的大小确定每一个站点的轮盘面积,再使用轮盘法选取下一个聚类中心,每次选取下一个聚类中心后将同属于一个θi的xi从轮盘中删除,,依次选出k个聚类中心作为聚类中心点集φ,φ={c1,c2,c3…ct…ck}。作为改进,所述s12中计算每个站点到各个聚类中心点的影响距离的方法为:ⅰ)使用公式(3)计算每个非聚类中心站点到聚类中心的欧氏距离均值si作为欧氏距离特征值;使用公式(4)计算每个非聚类中心站点对研究聚类中心预设区域的所属特征值ri;ⅱ)分别使用公式(5)和公式(6)对求得的si和ri进行归一化计算得到s′i和r′i;ⅲ)分别使用公式(7)和公式(8)计算当前研究聚类中心s和r的熵值es和er;其中,s″i和r″i是两个计算中间值,无实际含义,s″i和r″i分别通过公式(9)和公式(10)计算得到;ⅳ)分别使用公式(11)和公式(12)计算当前研究聚类中心s和r的信息熵冗余度ds和dr;ds=1-es(11);dr=1-er(12);ⅴ)分别使用公式(13)和公式(14)计算当前研究聚类中心s和r的信息熵权重ws和wr;ⅴ)重复ⅰ)-ⅴ)的计算过程求得k个聚类中心的信息熵权重ws,i和wr,i;ⅵ)使用k-means聚类算法进行聚类操作,使用公式(15)计算每个站点到各个聚类中心点的影响距离作为改进,所述s12输出聚类中心和各个类中的所有站点为:a)计算每个站点到各个聚类中心点的影响距离确定站点xi到哪个聚类中心的影响距离最小,就将站点xi划分到该聚类中心的类中;b)针对a)中重新划分后的每个类别i,使用公式(16)计算该类别的新聚类中心ci;c)重复随机选择聚类中心和计算每个站点到各个聚类中心点的影响距离直到每个类别的聚类中心的位置不再发生变化,区域站点划分完成,输出聚类中心和各个类中的所有站点。作为改进,所述s22中客流波动率si的计算的方法为:s221:使用公式(17)计算23个客流时刻对数参数bi,s222:使用公式(18)计算24-n个客流波动率si,其中n为波动观察范围,s1表示的是1+(n-1)/2点时刻的波动率;其中使用公式(19)计算作为改进,所述s22中计数大于阈值的波动率个数q的方法为:使用公式(20)计算24-n个客流波动率si的均值和标准差ds;其中使用公式(21)计算检索24-n个客流波动率si,计数大于阈值的波动率个数q:相对于现有技术,本发明至少具有如下优点:本发明通过结合城市行政和功能区域划分以及站点地理位置两个因素,使用熵权的计算方法来进行城市轨道交通站点区域划分。并在区域划分成熟之后引入波动率来识别区域客流的早晚高峰以识别通勤出行模式。最后上述所有预处理操作使得被识别为通勤出行模式的区域对,可以采用排除节假日的工作日数据作为历史同期数据序列进行计算预测以达到更为准确的区域od客流预测效果。附图说明图1为本发明中k-mean聚类结果。图2为本发明方法得到的区域划分图。具体实施方式下面对本发明作进一步详细说明。根据城市轨道交通进行城市区域划分是城市轨道交通旅客出行模式提取的基础。为了能够进行城市区域的划分,本文在分析轨道交通线网结构以及城市行政和功能区域划分的基础上,应用了k-mean聚类算法。一种基于波动率的通勤出行模式识别方法,包括如下步骤:s10:进行城市区域划分;s11:通过城市现有的行政和功能区域划分规划区域划分聚类个数和聚类范围:取所有n个研究对象站点x作为聚类数据集ω,ω={x1,x2,x3……xn};将所有研究对象站点分别归类到k个站点区域集合θi中,θi={xi,1,xi,2,xi,3……},i∈{1,2,3,4…,k};s12:使用k-means算法进行聚类,随机选择聚类中心,针对聚类数据集ω中的每个站点,计算每个站点到各个聚类中心点的影响距离确定站点xi到哪个聚类中心的影响距离最小,就将站点xi划分到该聚类中心的类中,输出聚类中心和各个类中的所有站点;s20:通勤出行模式识别;s21:每个聚类中心和该聚类中心的所有站点构成一个研究对象区域,两个研究对象区域组成的一组研究对象区域;对一组研究对象区域随机抽取若干个工作日的每小时客流统计数据ai,24个小时的客流数据组成数据集ψ,ψ={a1,a2,a3…a24};s22:分别计算24-n个客流波动率si,检索24-n个客流波动率si,计数大于阈值的波动率个数q:若q=4且四个波动率峰值分别对应早高峰和晚高峰的起止时间点,本例中为上午7点和9点,下午6点和8点,那么这一对研究对象区域被识别为通勤出行模式。作为改进,所述s12随机选择聚类中心的方法为:1)从聚类数据集ω中随机选取一个站点作为初始聚类中心c1,通过公式(1)计算站点xi与聚类中心点cj的欧氏距离用通过公式(2)计算站点xi被选为下一个聚类中心点的概率其中,k是坐标参数维度,xik和cjk分别表示站点xi与聚类中心点c1的第k维数据;2)按照每一个站点xi的的大小确定每一个站点的轮盘面积,再使用轮盘法选取下一个聚类中心,每次选取下一个聚类中心后将同属于一个θi的xi从轮盘中删除,以保证最后的k个聚类中心分别位于不同的预设θi中,依次选出k个聚类中心作为聚类中心点集φ,φ={c1,c2,c3…ct…ck}。为了使最终区域划分的结果包含城市行政和功能区域的特征,本文引入熵权来确定欧氏距离和预设区域所属情况的权值,影响距离则是二者与权值乘积的和。首先因为影响距离的值是欧氏距离特征值与预设区域的所属特征值分别与权值乘积的和,所以首先我们需要获取每一个聚类中心关于这两个特征值的信息熵权重。以下是求某一聚类中心信息熵权值的过程(对每一个聚类中心对需要计算熵权值):作为改进,所述s12中计算每个站点到各个聚类中心点的影响距离的方法为:ⅰ)使用公式(3)计算每个非聚类中心站点到聚类中心的欧氏距离均值si作为欧氏距离特征值;使用公式(4)计算每个非聚类中心站点对研究聚类中心预设区域的所属特征值ri;ⅱ)分别使用公式(5)和公式(6)对求得的si和ri进行归一化计算得到s′i和r′i;ⅲ)分别使用公式(7)和公式(8)计算当前研究聚类中心s和r的熵值es和er;其中,s″i和r″i是两个计算中间值,无实际含义,s″i和r″i分别通过公式(9)和公式(10)计算得到;ⅳ)分别使用公式(11)和公式(12)计算当前研究聚类中心s和r的信息熵冗余度ds和dr;ds=1-es(11);dr=1-er(12);ⅴ)分别使用公式(13)和公式(14)计算当前研究聚类中心s和r的信息熵权重ws和wr;ⅴ)重复ⅰ)-ⅴ)的计算过程求得k个聚类中心的信息熵权重ws,i和wr,i;ⅵ)使用k-means聚类算法进行聚类操作,使用公式(15)计算每个站点到各个聚类中心点的影响距离作为改进,所述s12输出聚类中心和各个类中的所有站点为:a)计算每个站点到各个聚类中心点的影响距离确定站点xi到哪个聚类中心的影响距离最小,就将站点xi划分到该聚类中心的类中;b)针对a)中重新划分后的每个类别i,使用公式(16)计算该类别的新聚类中心ci;c)重复随机选择聚类中心和计算每个站点到各个聚类中心点的影响距离直到每个类别的聚类中心的位置不再发生变化,区域站点划分完成,输出聚类中心和各个类中的所有站点。在完成区域划分之后,为了通过提取历史同期数据来优化预测效果,进行客流出行模式的识别,主要针对通勤出行模式进行识别。因为此处我们讨论的是通勤出行模式,所以需要重点考虑早高峰和晚高峰,对应地我们提出了基于波动率的通勤出行模式识别。根据通勤出行模式定义,通勤模式的识别必须是在工作日之内。而且具有早高峰和晚高峰两个客流高峰,我们根据数据统计早高峰大概时间段为上午7点到9点,晚高峰时间段为下午6点到8点。这种区域od客流情况我们就称为通勤出行模式。作为改进,所述s22中客流波动率si的计算的方法为:s221:使用公式(17)计算23个客流时刻对数参数bi,b1代表的是1点时刻的对应参数,以此类推s222:使用公式(18)计算24-n个客流波动率si,其中n为波动观察范围,s1表示的是1+(n-1)/2点时刻的波动率;其中使用公式(19)计算所述s22中计数大于阈值的波动率个数q的方法为:使用公式(20)计算24-n个客流波动率si的均值和标准差ds;其中使用公式(21)计算检索24-n个客流波动率si,计数大于阈值的波动率个数q:实验验证:本实验以重庆市为例,将重庆市区轨道交通数据作为实验原始数据集。从实验结果中可以很明确地看出优化后的聚类算法具有更强大的环境适应力,划分效果很好,避免了地理位置接近但是轨道距离较远的错误分类情况。本发明在对轨道站点进行空间聚类的时候使用的是站点的gps定位数据,表1中的属性依次是:卡id、站点编号、站点名称、经度、纬度。表1gps定位数据idostationstationnameolongitudeolatitude1101朝天门106.584429.559762102小什字106.579129.561673103较场口106.568629.55644104七星岗106.559629.557975105两路口106.545729.555576106鹅岭106.530229.55087107大坪106.514929.543468108石油路106.506329.541999109歇台子106.492829.537910110石桥铺106.481329.5355311111高庙村106.46529.5391712112马家岩106.464829.54813113小龙坎106.464329.55621……………通过使用基于熵权的站点区域划分方法,本发明以重庆为例结果分为以下10个聚类区域:区域0为以红旗河沟换乘站为代表的商业旅游区。区域1是以鱼洞为代表巴南区,景区、古镇院落众多。区域2为以国博中心方向的西北区,文化交流中心。区域3为以大学城为中心的大学城校园片区。区域4是以大坪、袁家岗为代表的渝中西部通讯产业片区。区域5为中梁山区域。区域6为铜锣山区域。区域7为江北机场方向的重庆北站—江北机场片区,包含火车站与机场。区域8为以沙坪坝为中心的沙坪坝片区科教文化区域。区域9为以两路口、南坪为代表的嘉陵江长江汇集区域。图1是基于时空影响距离的k-means聚类算法的实验结果图,从图中可以明显的看到两点:首先聚类划分的地理因素影响依旧很明显,划分结果中每一个同聚类站点的地理位置距离都相对较近,不会出现为了满足时间维度影响而出现地理差距较大的聚类情况;其次聚类站点的分布并不完全依赖直线地理距离,从站点的分布来看都是处于轨道交通线路的相近位置。本发明中城市区域划分的步骤和通勤出行模式识别步骤相辅相成,下面给出一组对比例,对比结果如表2:表2预处理前后区域od的通勤出行模式客流预测准确率对比网络模型本发明方法对比例lstm95.6%89.2%对比例与本发明方法唯一的区别在于,本发明方法通过城市区域划分对获取的研究对象站点数据进行预处理,而对比例则没有。通过表格可以看出本发明所述方法通过熵权的方法对城市区域划分大大提到了通勤出行模式客流预测的准确率。最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1