一种相似产品剩余寿命预测方法及系统与流程
本发明涉及相似产品预测技术领域,尤其涉及一种预测相似产品剩余使用寿命的方法、系统和装置。
背景技术:
随着储能技术和能源产业的发展,锂离子电池因其质量轻、低放电率和长寿命等优点,广泛应用于军事电子产品、航空电子器件、电动汽车以及各种便携式电子装置(例如笔记本电脑、数码相机、平板电脑、手机等)的主要储能器件。循环寿命是锂电池产品的重要设计性能。在锂电池的设计开发过程中,为了准确的获得设计矩阵中不同配方电池的寿命情况,并为配方选择和设计优化提供反馈,需要针对设计矩阵中各个配方的电池开展循环寿命测试。该项测试需要持续进行到电池容量保持率达到规定的阈值,即锂电池的寿命终止点。然而,由于设计矩阵中的锂电池配方数量众多,导致现有的循环寿命测试时间和资金成本太高,尤其对寿命周期长达多年的动力锂电池的而言,其设计开发效率过低,企业难以承受。
技术实现要素:
为解决现有技术存在的问题,本发明利用短期实测数据及迁移学习预测方法提供了一种更适用于电池设计开发过程中不同配方间的电池寿命预测方法,本发明方法能有效避免由于长期测试所产生的能耗及资源浪费,预测准确度高,普适性强。
为实现本发明的技术目的,本发明一方面提供相似产品寿命预测方法,包括:
对待预测的不同配方相似产品进行短期循环寿命测试,获得短期测试样本数据;
对获得的短期测试样本数据以及其他配方电池的全寿测试容量数据库中的数据进行处理后,得到目标样本数据和训练测试数据;
在训练测试数据中截取与目标样本数据同样长度的数据进行可迁移样本挖掘,并将其中具有较高迁移度的数据作为可迁移样本数据;
通过前向网络训练学习可迁移样本数据至目标样本数据的迁移关系,获得相似产品测试数据迁移与剩余寿命预测的神经网络模型;
应用训练测试数据中剩余长度的数据在神经网络模型进行跨配方电池的剩余寿命预测,获得待预测的不同配方相似产品的剩余寿命预测结果。
其中,所述短期循环寿命测试是指在对相似产品进行循环寿命测试时,在试验早期即停止在一个预先设定的测试停止阈值。
其中,所述测试停止阈值为大于全寿测试停止阈值。
其中,所述停止阈值是指电池容量衰退到初始容量的某个百分比值。
其中,所述测试停止阈值大于85%。
优选的,所述测试停止阈值不小于87%。
进一步优选的,所述测试停止阈值不小于90%。
特别是,相似产品为锂电池。
特别是,所述对获得的短期测试样本数据以及其他配方电池的全寿测试容量数据库中的数据进行处理包括:
剔除短期测试样本数据和全寿测试容量数据库中不稳定的起始数据和未体现退化趋势的数据;
对剔除后的短期测试样本数据和全寿测试容量数据库中的数据进行平滑处理,得到目标样本数据和预测训练测试数据。
尤其是,所述平滑处理采用局部加权回归法。
特别是,所述在训练测试数据中截取与目标样本数据同样长度的数据是根据目标样本数据的充放电循环数在预测训练测试数据中进行截取获得的数据。
特别是,所述可迁移样本挖掘是多维评估训练测试数据与目标样本数据的相似度,并对评估的相似度结果进行可迁移度计算,将可迁移度较高的训练测试数据作为可迁移样本数据。
尤其是,所述可迁移度较高的训练测试数据为可迁移度升序排名靠前的20%的训练测试数据。
特别是,所述多维评估训练测试数据与目标样本数据的相似度包括:
每个训练测试数据和目标样本数据之间的切比雪夫距离的维度评估;
每个训练测试数据和目标样本数据之间的差值均值的维度评估;
每个训练测试数据和目标样本数据之间差值末点变化率的维度评估。
为实现本发明的技术目的,本发明另一方面提供一种相似产品寿命预测系统,包括:
数据单元、数据处理单元、数据挖掘单元、模型训练单元以及寿命预测单元,其中:
数据单元,用于采集并存储预测的不同配方相似产品循环寿命数据;
数据处理单元,用于处理短期测试样本数据得到目标样本数据,处理对其他配方电池的全寿测试容量数据库中的数据得到训练测试数据;
数据挖掘单元,用于在训练测试数据中截取与目标样本数据同样长度的数据进行可迁移样本挖掘,并将挖掘的可迁移样本中具有较高迁移度的数据作为可迁移样本数据;
模型训练单元,用于通过前向网络训练学习可迁移样本数据至目标样本数据的迁移关系,获得相似产品测试数据迁移与剩余寿命预测的神经网络模型;
寿命预测单元,用于利用训练测试数据中剩余长度的数据在神经网络模型进行跨配方电池的剩余寿命预测,获得待预测的不同配方相似产品的剩余寿命预测结果。
为实现本发明的技术目的,本发明还提供一种将上述的方法或系统用于电池配方设计优化的用途。
有益效果:
1、本发明仅利用现有的已知电池的全寿数据和待测的不同配方电池的短期循环寿命测试数据即可预测待测电池的剩余寿命,方法简单,成本低,仅需要对电池做短期循环寿命测试即可。
2、本发明提供的方法和系统预测精度高,最高可达99%以上,节约了分析电池配方性能的成本,加快了电池研发阶段的进度。
3、本发明方法和系统节约了大量试验成本,实现有效的数据共享,为电池循环寿命试验带来了新的选择,具有很好的经济性和实用性。
附图说明
图1是本发明实施例1提供的本发明方法流程图;
图2是本发明实施例2提供的本发明系统流程图;
图3是本发明应用实施例中提供的25dc平滑处理前后的退化曲线图;
图4是本发明应用实施例中提供的45dc平滑处理前后的退化曲线图;
图5是本发明应用实施例中提供的60dc平滑处理前后的退化曲线图;
图6是本发明应用实施例中提供的可迁移度变化曲线;
图7是本发明应用实施例中提供的25dc相似样本与目标样本退化趋势对比图;
图8是本发明应用实施例中提供的45dc相似样本与目标样本退化趋势对比图;
图9是本发明应用实施例中提供的60dc相似样本与目标样本退化趋势对比图;
图10是本发明应用实施例中所使用的bpnn结构示意图。
具体实施方式
下面将结合示意图对本发明方法和系统进行更详细的描述,其中表示了本发明的优选实施例,应该理解本领域技术人员可以修改在此描述的本发明,而仍然实现本发明的有利效果。因此,下列描述应当被理解为对于本领域技术人员的广泛知道,而并不作为对本发明的限制。
在下列段落中参照附图以举例方式更具体地描述本发明。根据下面说明和权利要求书,本发明的优点和特征将更清楚。需说明的是,附图均采用非常简化的形式且均使用非精准的比例,仅用以方便、明晰地辅助说明本发明实施例的目的。
下述实施例中所使用的实验方法如无特殊说明,均为常规方法。下述实施例中所用的结构、材料等,如无特殊说明,均可从商业途径得到。
实施例1
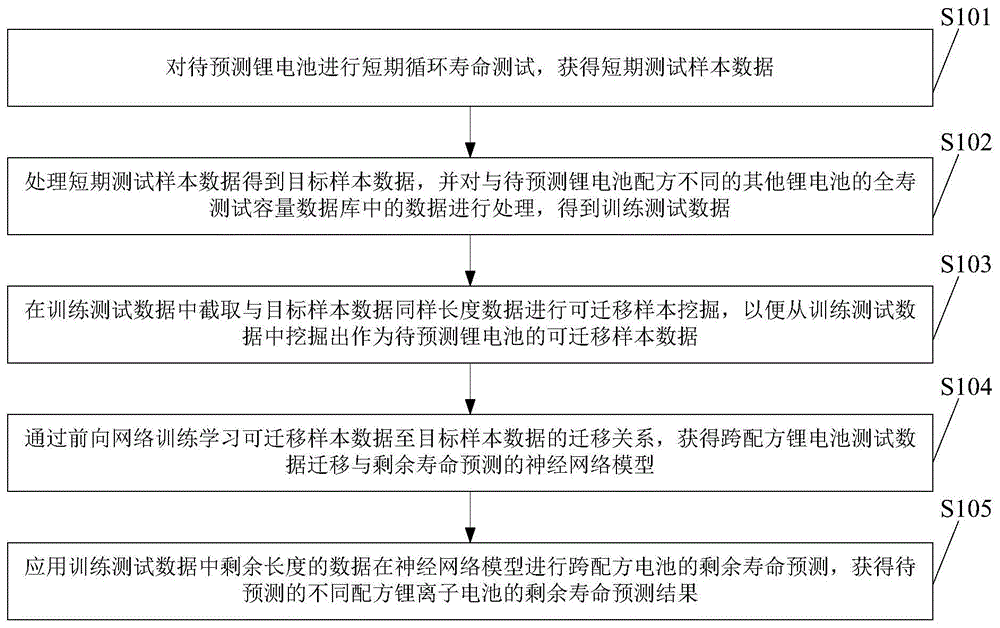
如图1所示,本发明提供的跨配方相似产品(如锂离子电池)剩余寿命预测方法包括:
步骤s101对待预测的不同配方相似产品进行短期循环寿命测试,获得短期测试样本数据。
其中,所述短期循环寿命测试是指在对相似产品进行循环寿命测试时,在试验早期即停止在一个预先设定的测试停止阈值。
其中,所述测试停止阈值大于全寿测试停止阈值。
其中,所述测试停止阈值和全寿测试停止阈值均指电池容量衰退到初始容量的某个百分比值。
其中,所述测试停止阈值大于85%。
优选的,所述测试停止阈值不小于87%。
进一步优选的,所述测试停止阈值不小于90%。
具体的,所述的电池是指电池产品设计阶段的电池软包,也可以是不同配方的成品电池。
具体的,所述不同配方是待测的电池与已经完成全寿测试的电池具有相同的阴极和分隔材料,但电池阳极材料和电解质溶液各不相同。
需要说明的是,本发明所称的电池循环寿命测试可以采用相似产品常用的试验标准进行,例如gb/t18287标准,也可以采用本领域常用的试验方法进行,为了减少误差,本发明所称的数据均来自同一试验条件下测得的数据。
步骤s102对获得的短期测试样本数据以及其他配方电池的全寿测试容量数据库中的数据进行处理后,得到目标样本数据和训练测试数据。
进一步的,所述其他配方电池的全寿测试容量数据库为现有的不同配方电池的历史全寿测试数据的总和,即现有的电池库中每个电池试验运行至电池容量保持率退化到国家标准到寿阈值tsfailture的容量保持率数据总和。
具体的,所述对获得的短期测试样本数据以及其他配方电池的全寿测试容量数据库中的数据进行处理包括:
剔除短期测试样本数据及全寿测试容量数据中不稳定的起始数据和未体现退化趋势的数据;
对剔除后的目标样本数据及全寿测试容量数据进行平滑处理,得到去除随机噪声的目标样本数据及预测训练测试数据。
进一步的,所述平滑处理是对剔除后的目标样本数据及全寿测试容量数据进行局部加权回归,去除随机噪声的影响,保留容量保持率的退化趋势。
由于试验条件的波动、测量误差、交叉测试等因素,相似产品试验数据存在一定的波动,但在大尺度下对电池退化趋势不构成影响。如果保留噪声,会使预测模型面临过拟合的风险。为提高预测鲁棒性,本发明利用局部加权回归算法对数据进行平滑处理,从而保留容量保持率退化趋势,去除随机噪声的影响。
本发明所用的局部加权回归算法,是一种对于普通回归算法实现效果提升的一种回归算法。其原理就是对局部观测数据进行多项式加权拟合,并用最小二乘法进行估计,最终得到需要拟合的点。具体步骤如下:
对于每一个数据qi,确定一个窗口范围(即数据长度),在窗口内所有的qk上,k=1,2,…,n,由权值函数可以得到权值ωk(qi),使用带有权值ωk(qi)的加权最小二乘法对qi进行d阶多项式拟合,得到拟合值pi。利用ωk(qi)得到pi就称为局部加权回归。
其中,α0(qi),α1(qi),…,αm(qi)为相对于qi未知的参数,εi,i=1,2,…,n为独立同分布的随机误差项。β值是根据实验目的和要求进行设定,其值越大,曲线的平滑程度越高,其值越小,曲线的平滑程度越低。
步骤s103在训练测试数据中截取与目标样本数据同样长度的数据进行可迁移样本挖掘,并将其中具有较高迁移度的数据作为可迁移样本数据。
具体的,所述在训练测试数据中截取与目标样本数据同样长度的数据是根据目标样本数据的充放电循环数在预测训练测试数据中进行截取获得的数据。
具体的,所述可迁移样本挖掘是多维评估训练测试数据与目标样本数据的相似度,并对评估的相似度结果进行可迁移度计算,将可迁移度较高的训练测试数据作为可迁移样本数据。
进一步的,所述多维评估训练测试数据与目标样本数据的相似度包括:
每个训练测试数据和目标样本数据之间的切比雪夫距离的维度评估;
每个训练测试数据和目标样本数据之间的差值均值的维度评估;
每个训练测试数据和目标样本数据之间差值末点变化率的维度评估。
具体的,所述每个训练测试数据和目标样本数据之间的切比雪夫距离的维度评估是计算每个截取的数据和目标样本数据之间的切比雪夫距离,并对所得的切比雪夫距离值进行升序排名,标记顺序号,作为第一判据;
即,
其中,dischebychev表示切比雪夫距离值,
具体的,所述每个训练测试数据和目标样本数据之间的差值均值的维度评估是计算每个截取的数据和目标样本数据之间的差值均值,并对所得的差值均值进行升序排名,标记顺序号,作为第二判据;
即discapacity=mean(|ds-dt|);
其中,
其中,discapacity表示切比雪夫距离值,
具体的,所述每个训练测试数据和目标样本数据之间差值末点变化率的维度评估是计算每个截取的数据和目标样本数据之间的差值末点变化率,并对所得的差值末点变化率值进行升序排名,标记顺序号,作为第三判据。
即disgradient=diff(ds-dt)r;
其中,
其中,disgradient表示切比雪夫距离值,
进一步的,所述对评估的相似度结果进行可迁移度计算是将切比雪夫距离的维度评估结果、差值均值的维度评估结果和差值末点变化率的维度评估结果进行权重计算,得到每个训练测试数据与目标样本数据的可迁移度值。
具体的,所述将切比雪夫距离的维度评估结果、差值均值的维度评估结果和差值末点变化率的维度评估结果进行权重计算是将得到的第一判据、第二判据、第三判据进行按照设定的权重值进行计算,所的结果即为每个训练测试数据与目标样本数据的可迁移度值。
即ranks=rank·wft
其中,ranks表示可迁移度值,rank是各判据得到的位置序号,本发明实例中rank=(rankchebychev,rankcapacity,rankgradient),wf是各判据得到的排序在相似度综合判断中所占权重,t表示转置。
进一步的,所述可迁移度较高的训练测试数据为可迁移度值升序排名靠前的20%的训练测试数据。
步骤s104通过前向网络训练学习可迁移样本数据至目标样本数据的迁移关系,获得相似产品测试数据迁移与剩余寿命预测的神经网络模型。
进一步的,所述前向网络训练是以相似样本数据作为输入,以目标样本数据作为输出进行前向网络训练。
其中,本发明采用的神经网络类型为bpnn(backpropagationneuralnetwork,bpnn)类神经网络。bpnn是一种前向结构的神经网络,映射一组输入向量到一组输出向量。bpnn除了输入层,每一层的神经元都带有激活函数。同时,bpnn的每一层都是全连接层,采用反向传播算法来训练。
不同配方的电池之间有着一定的相似性,每个配方的电池可以看做一个任务域,要实现某个任务域(即目标样本数据)电池容量的预测,在目标域样本不足以支撑预测任务时,通过基于样本的迁移,就能够实现利用相似样本(源域)的知识解决目标域电池容量预测任务。
本发明中采用神经网络实现相应的迁移,使用目标域和源域长度为r的样本数据训练神经网络,从而确定神经网络迁移权重。
在预测任务中,目标电池在循环数cj处的容量保持率
用于bpnn训练的训练样本为[dck,1,dck,2,…,dck,i,dck,t],k=1,2…r,i个样本的每个循环数对应的电池容量保持率和目标电池每个循环数对应的电池容量保持率组成一个训练样本。
假设神经网络有t层结构,其中第1层为输入层,第t层为输出层,第2到第t-1层为隐藏层,第t与第t+1层之间的连接权值矩阵为
bp算法使用梯度下降算法对网络中的各权值进行更新,获得目标函数极小值。使用批量更新算法,设batch的大小为p,采用均方误差和计算公式,那么一次batch的总误差为:
式中的
按照梯度下降公式,每一次batch对各层之间的连接权值与偏置的更新方程为:
其中α∈(0,+∞)为学习速率,i表示第t层的第i个节点,j表示第t+1层的第j个节点。每一层的权重梯度都等于这一层权重所连接的前一层的输入乘以所连接后一层的反向输出。
在bpnn训练结束后,训练成熟的网络即可拿来进行电池寿命的预测。
步骤s105应用训练测试数据中剩余长度的数据在神经网络模型进行跨配方电池的剩余寿命预测,获得待预测的不同配方相似产品的剩余寿命预测结果。
具体的,所述训练测试数据中剩余长度的数据为根据目标样本数据的充放电循环数在预测训练测试数据中进行截取后,所剩余的数据。
实施例2相似产品预测系统
如图2所示,本发明提供的跨配方相似产品剩余寿命预测系统包括:数据单元1、数据处理单元2、数据挖掘单元3、模型训练单元4以及寿命预测单元5。
进一步的,所述数据单元1,用于采集并存储待预测的不同配方的相似产品的短期循环寿命数据;数据处理单元2,用于处理短期测试样本数据得到目标样本数据,并对与待预测相似产品配方不同的其他相似产品的全寿测试容量数据库中的数据进行处理,得到训练测试数据;数据挖掘单元3,用于在训练测试数据中截取与目标样本数据同样长度数据进行可迁移样本挖掘,以便从训练测试数据中挖掘出作为待预测相似产品的可迁移样本数据;模型训练单元4,用于通过前向网络训练学习可迁移样本数据至目标样本数据的迁移关系,获得相似产品测试数据迁移与剩余寿命预测的神经网络模型;寿命预测单元5,用于应用训练测试数据中剩余长度的数据在神经网络模型进行跨配方电池的剩余寿命预测,获得待预测的不同配方相似产品的剩余寿命预测结果。
应用实施例跨配方相似产品剩余寿命预测
1、数据收集
为验证本发明在不同配方电池之间的寿命迁移预测能力,本发明从已经完成电池寿命测试的相同电池平台不同配方的相似产品中筛选十组不同配方的电池样本数据,进行跨配方电池剩余寿命预测,每组样本数据包括了25℃、45℃及60℃三种不同温度下的试验数据,并将其中一组样本进行长度r截取,该长度为试验运行至电池容量保持率退化到90%的停止阈值tsfailture的容量保持率数据,以此作为待预测样本,其他九组样本作为电池库,即全寿测试容量数据库。,对截取长度的一组电池进行预测。将待预测样本中25℃温度下的待测电池命名为:25dc;45℃温度下的待测电池命名为:45dc;60℃温度下的待测电池命名为:60dc,
上述数据均在同一实验条件下测得,例如采用标准的恒流/恒压方式,在电压达到4.2v之前均为1c恒定电流速率,随后保持电压值4.2v直至充电电流降至0.1a以下,循环放电过程以恒定放电电流2a进行,放电截止电压为2.78v,全寿循环测试数据为试验运行至电池容量保持率退化到80%的到寿阈值tsfailture的所有配方的容量保持率数据,即电池容量保持率下降至初始容量的80%时,认为电池到达寿终点。也可以根据国家相似产品测试标准进行,例如gb/t18287标准的试验条件进行。
2、数据处理
2.1数据剔除
去除待测样本以及样本库中起始一小段不稳定、未体现退化趋势的部分,获得目标样本数据
2.2平滑处理
本发明利用局部加权回归算法对数据进行平滑处理,使退化曲线能保留整体趋势,对目标样本数据25dc、45dc以及60dc进行平滑处理后,其结果如图2-4所示。
其中,图3是样本25dc进行平滑处理前后的退化曲线图,图4是样本45dc进行平滑处理前后的退化曲线图,图5是样本60dc进行平滑处理前后的退化曲线图,图中,横坐标表示循环数,纵坐标表示容量数据,根据图3-5可以看出,经过平滑处理后,电池退化曲线的整体趋势更加明显。
采用同样方法对训练测试数据进行平滑处理,获得整体趋势更加明显的训练测试数据。
3、可迁移样本挖掘
在训练测试数据中截取与目标样本数据25dc、45dc以及60dc同样长度的数据,将25dc、45dc以及60dc中的每个容量数据在训练测试数据中进行可迁移样本挖掘,以25dc的电池数据为例,对应的长度为第1至1503个充放电循环。对训练测试数据中25℃温度数据所有满足长度要求的不同配方电池(共29个)退化数据截取至1503次循环之间的容量退化数据,平滑去噪后得到29个与目标电池同维度的1503维向量,分别计算其与目标样本数据之间的各判据,并转化为相似度、排序,得到相似度排名如表1所示。
最终得到如表1所示的迁移度结果和如图6所示的可迁移度变化曲线。
表1迁移度结果
根据表1和图6可知,相似曲线相似度呈现阶梯状分布,为保证所选取的相似曲线尽可能对预测作出积极贡献,选取相似度变化平稳的排名前20%的相似曲线用于预测。同时,为避免由于偶然误差引起的异常相似曲线,采用容量保持率0.9的循环数做进一步排除,保证所选取的相似曲线容量保持率0.9的循环数不偏离第1名15%以上,即电池1、2、4、5作为相似样本。相似样本与目标样本全寿命退化曲线如8。可以看出,四个相似样本在参考段与目标样本退化趋势基本一致,可以用来对目标样本缺失数据进行预测。45℃和60℃下(即45dc、60dc)的筛选结果如图7-9所示。
4、神经网络学习
以25℃电池(即25dc)为例,截取电池1、2、4、5四个相似样本的第1至1503次循环的1503个容量保持率数据作为训练输入数据25dc数据作为训练输出数据,训练bpnn神经网络。
在本发明的一个实施例中选用的bpnn结构如图10所示。
网络训练损失函数选择均方误差(mse),adam优化器具有较快的收敛速度,能在最短时间使目标函数收敛到最优点附近,因此首先采用adam优化器优化30个epochs,使目标函数迅速到达最优点附近。sgd优化器虽然收敛速度较慢,但其极其稳定,因此适合在目标函数到达最优点附近后使用,在使用adam优化器后,选用sgd优化器再训练50个epochs,使当前bpnn网络损失值收敛至理想状态。
训练得到的bpnn神经网络,已经具备了迁移相似样本知识到目标样本上的能力,使用训练得到的网络迁移权重,就可以用来预测目标样本的寿命。
5、剩余寿命预测及结果分析
根据步骤4得到的神经网络对相似样本数据进行迁移,对容量保持率退化至0.9以下的数据进行预测,25℃(即25dc)、45℃下(即45dc)和60℃下(即60dc)电池得到如图7-9所示退化曲线。
图7-9中,黑色竖直虚线右侧部分灰色曲线均为预测结果。
从图7中可以看出25℃下(即25dc)预测结果基本与真实曲线吻合。查找预测曲线、真实曲线与失效阈值的交点,得到预测寿命为2370个循环,真实寿命为2365个循环,预测准确度为99.79%。
从图8中可以看出,45℃下(即45dc)的其中3个样本的预测结果基本与真实曲线吻合。查找预测曲线、真实曲线与失效阈值的交点,得到预测寿命为718个循环,真实寿命为757个循环,预测准确度为94.85%。
从图9中可以看出,60℃下(即60dc)其中5个样本的预测结果基本与真实曲线吻合。查找预测曲线、真实曲线与失效阈值的交点,得到预测寿命为791个循环,真实寿命为778个循环,预测准确度为98.33%。
综上可见,本发明提出的预测算法性能良好,同时从数据驱动的角度出发,节约了分析电池配方性能的成本,由不同配方电池的数据相似性分析,可以节约大量试验成本,实现有效的数据共享。为电池循环寿命试验带来了新的选择,具有很好的经济性和实用性。
尽管上文对本发明进行了详细说明,但是本发明不限于此,本技术领域技术人员可以根据本发明的原理进行各种修改。因此,凡按照本发明原理所作的修改,都应当理解为落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!